In the design of CPU cores, SIMD (Single Instruction Multiple Data) is a commonly used data parallel processing method that operates on multiple data elements simultaneously through a single instruction to enhance the computational efficiency and speed of the processor. SIMD has a wide range of applications, such as image processing, scientific computing, encryption and decryption, machine learning, and artificial intelligence. As the demand for computational power continues to rise, the data parallel capabilities of processors have also increased (for example, the evolution of Intel’s SIMD ISA, with registers evolving from 64-bit MMX to the current 512-bit AVX). However, the programming model of traditional SIMD instructions determines that the register length (i.e., degree of parallelism) is embedded in the instruction, leading to a high coupling between hardware and software. Each hardware upgrade in parallelism requires corresponding adaptations in software, resulting in additional software workload.
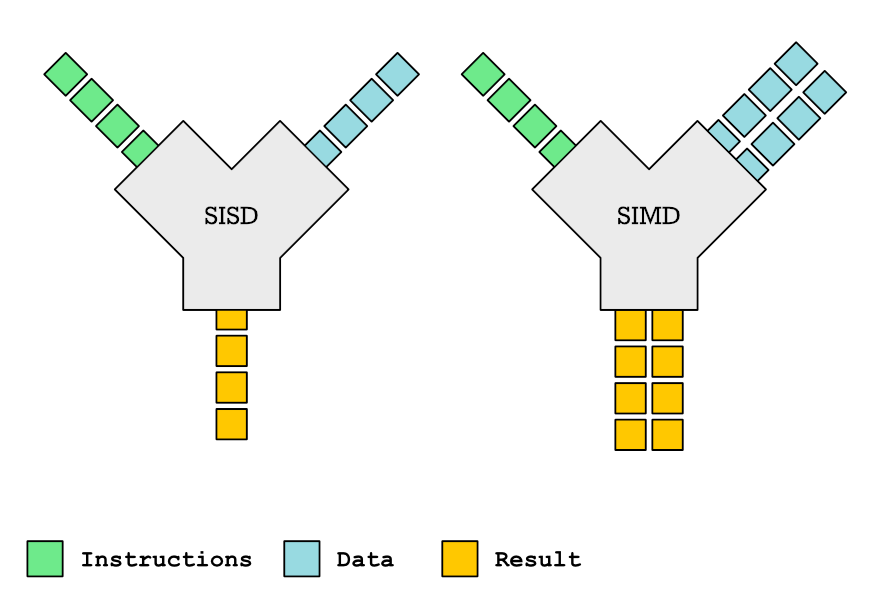
Compared to traditional SIMD instructions, the RISC-V instruction set vector extension, RISC-V Vector, adopts a more flexible programming model, providing single instruction multiple data parallel processing while offering developers a higher level of abstraction. This decouples hardware and software, allowing software to adapt directly to different hardware configurations without needing to be aware of changes in hardware parallelism.

Taking the RISC-V Vector 1.0 instruction set as an example, we can see from the figure that for hardware with different vector register widths (VLEN), the same program can run directly, with the only difference being that processors with larger VLEN can process more elements per iteration, thus requiring fewer loop iterations. Additionally, due to the element mask functionality defined by the instruction set, excess elements in the last iteration will be invalidated without the need for additional special handling of the loop’s tail elements, as is required with SIMD instructions.

Practical Implementation of RISC-V Vector Technology
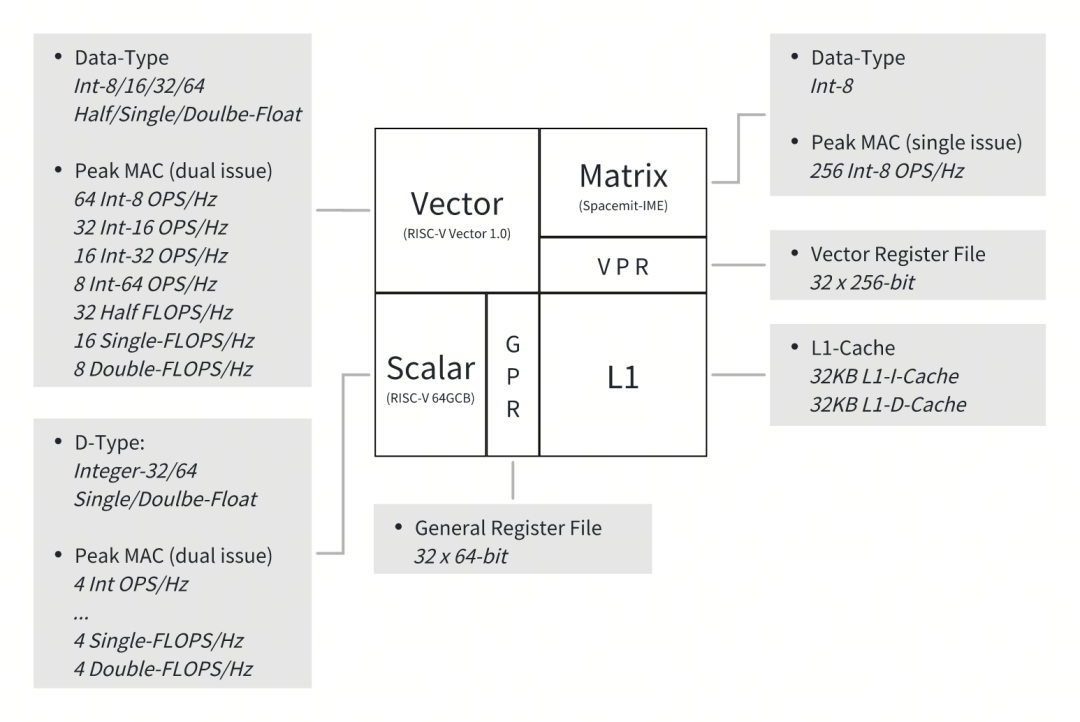
The first generation of RISC-V CPU core X60 and RISC-V AI core A60 from Jindie Shikong fully support the RISC-V Vector 1.0 extension and are applied in the RISC-V AI CPU chip K1. This series of cores supports a vector register width of VLEN=256-bit, providing a maximum data parallel processing capability of 2×128-bit, supporting various computational precisions such as INT/FP. Additionally, the A60 has extended AI instructions compliant with the IME standard based on vector registers, providing 2 Tops of INT8 fused AI computing power.
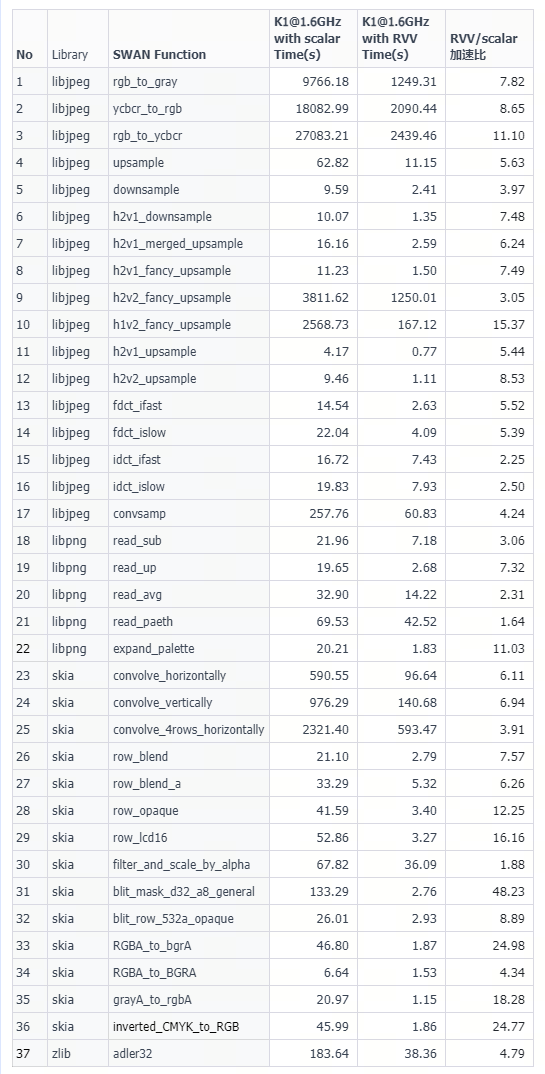
We tested and optimized the vector capabilities of K1 based on the SWAN test suite. SWAN is a benchmark suite used to test the performance of vector instructions in data-intensive applications such as multimedia and image processing, analyzing the performance of software libraries for applications like Chromium, WebRTC, and PDFium. The tests cover typical algorithms such as image encoding and decoding, convolution calculations, and color space conversions.
In all 37 tests of SWAN, vector instructions achieved significant speedup compared to scalar instructions, especially in low-precision high-parallelism tests, where the speedup of vectors can reach several tens of times.
Furthermore, compared to the SIMD instructions of Cortex-A55, under the same frequency, the performance of the K1 chip’s Vector instruction tests showed:
-
51% of the test items achieved performance over 1.5 times that of Cortex-A55 (with a maximum of 2.5 times);
-
21% of the test items achieved performance between 1 to 1.5 times that of Cortex-A55;
Due to the configuration of wider vector registers and data processing widths, K1 has gained greater benefits in programs with high data parallelism, such as typical image testing programs like ibjpeg and skia, where performance improvements can reach 50% to 100%. Additionally, software optimization is also a very important aspect of vectorization. The algorithm and instruction scheduling optimizations of the program can impact the test results, and after targeted optimization adjustments, both the degree of vectorization and overall performance have significantly improved. This is also an area where the software ecosystem of the RISC-V Vector instruction set needs to continuously accumulate optimizations in practical application scenarios.