Background of Agentic AI
The initial product form of LLM was the ChatBot led by OpenAI, supported by the Transformer architecture large language model, which initially focused on AI applications in the field of language text.
LLM ChatBots have profoundly changed our work and life. With the popularization of LLM technology in toC and toB application scenarios, more and more limitations have been discovered, such as the following:
- Lack of Proactivity: They do not actively perceive their surroundings and respond.
- Poor Goal Awareness: They may forget the initial goal during multi-turn interactions.
- No Persistent Memory: They can only associate limited non-persistent contextual information.
- Inability to Interact with External Systems: They can only chat and do not have the ability to change their surroundings.
Agentic AI is the design concept and architectural paradigm of AI systems in the LLM era, aiming to break through the limitations of LLMs and transition from “content generation” to “task execution.” Furthermore, Agentic AI aims to build AI systems with autonomous capabilities, that is, the ability to perceive the environment, plan decisions, execute actions, and ultimately achieve specific goals, similar to humans or biological entities.
- Autonomous Perception of the Environment (Perception): The ability to obtain information about the external environment from various data sources, not just the chat window.
- Goal-Oriented: Understanding user intentions and setting clear goals, with all actions centered around the goals.
- Planning Decisions: Generating a series of plans autonomously towards the goal based on perceived information and clear objectives.
- Executing Actions: The ability to operate various tools to affect the external environment and execute specific actions, thereby changing the environment.
- Environmental Interaction: Observing/obtaining feedback from the environment after actions and adjusting subsequent decisions based on that feedback.
- Adaptive Loop: Forming a new round of “planning, executing, observing” loop as needed based on feedback, ultimately achieving the goal.
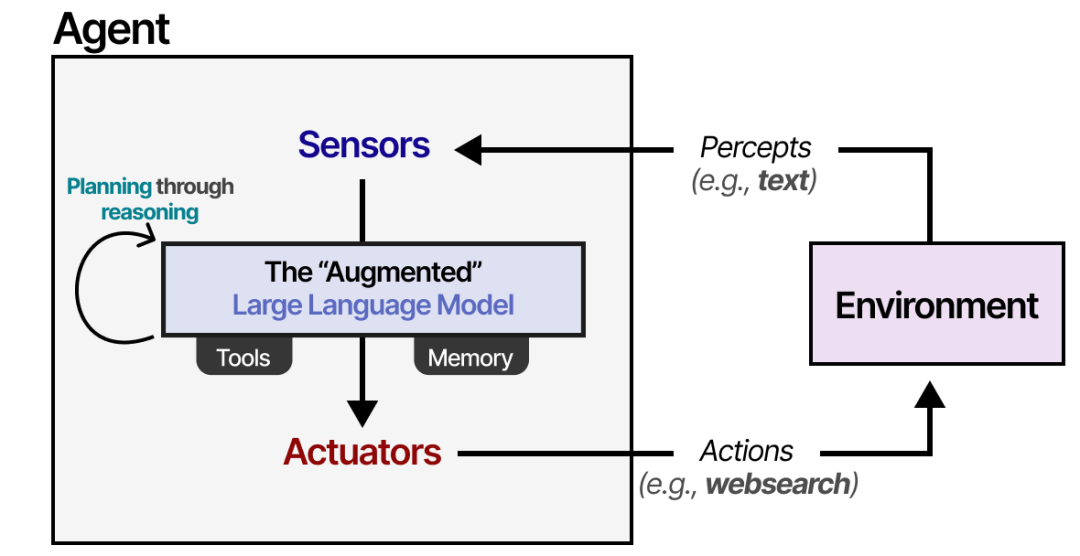
AI Agents are the concrete implementation of Agentic AI. An agent is an entity that perceives the environment through sensors and acts on the environment through actuators. — Russell & Norvig, “Artificial Intelligence: A Modern Approach” (2016)
- Environment: The object of interaction for the agent
- Sensors: Used to observe the environment
- Actuators: Tools for interacting with the environment
- LLM: The intelligent brain that decides how to act based on observations
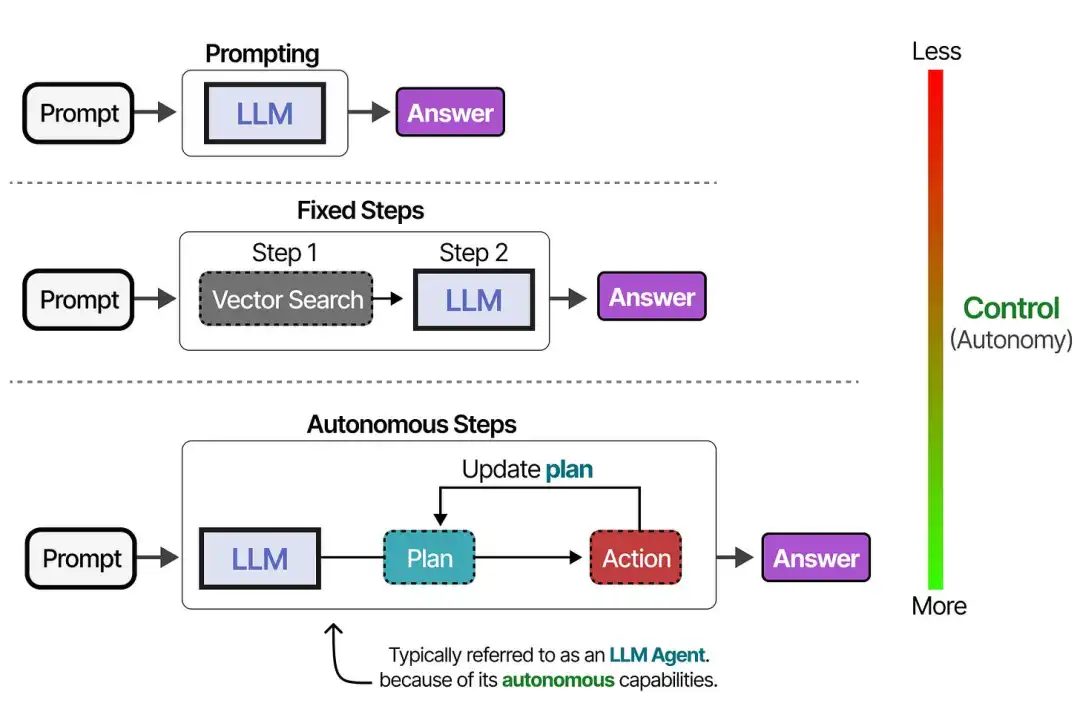
After four years of rapid development, AI Agents have become an important means of exploring, mining, and expanding the capabilities of LLMs. At the same time, the decision-making control of system behavior by LLMs is also increasing, and their “agent characteristics” are becoming stronger.
- In 2021, Prompt Engineering
- In October 2022, ReAct reasoning technology
- In March 2023, AutoGPT, the first agent
- In June 2023, OpenAI Function Calling
- In June 2023, OpenAI Agent architectural paradigm
- In 2024, Multi-Agent
Development of AI Agents
In 2021, Prompt Engineering
Prompt Engineering is a method of carefully designing and optimizing input prompts for LLMs to guide them in generating high-quality and expected output results. Prompt Engineering allows LLMs to better understand user intentions and return expected results more accurately. Therefore, Prompt Engineering is often referred to as “magic spells,” an art of translating human intentions into executable instructions for LLMs.
Prompt Engineering mainly studies two directions: System Prompt and User Prompt. LLM service providers define general prompts as system-level System Prompts to constrain the baseline of LLM input and output. Users can customize optimized prompts, referred to as User Prompts.
Helping LLM Better Understand User Intentions
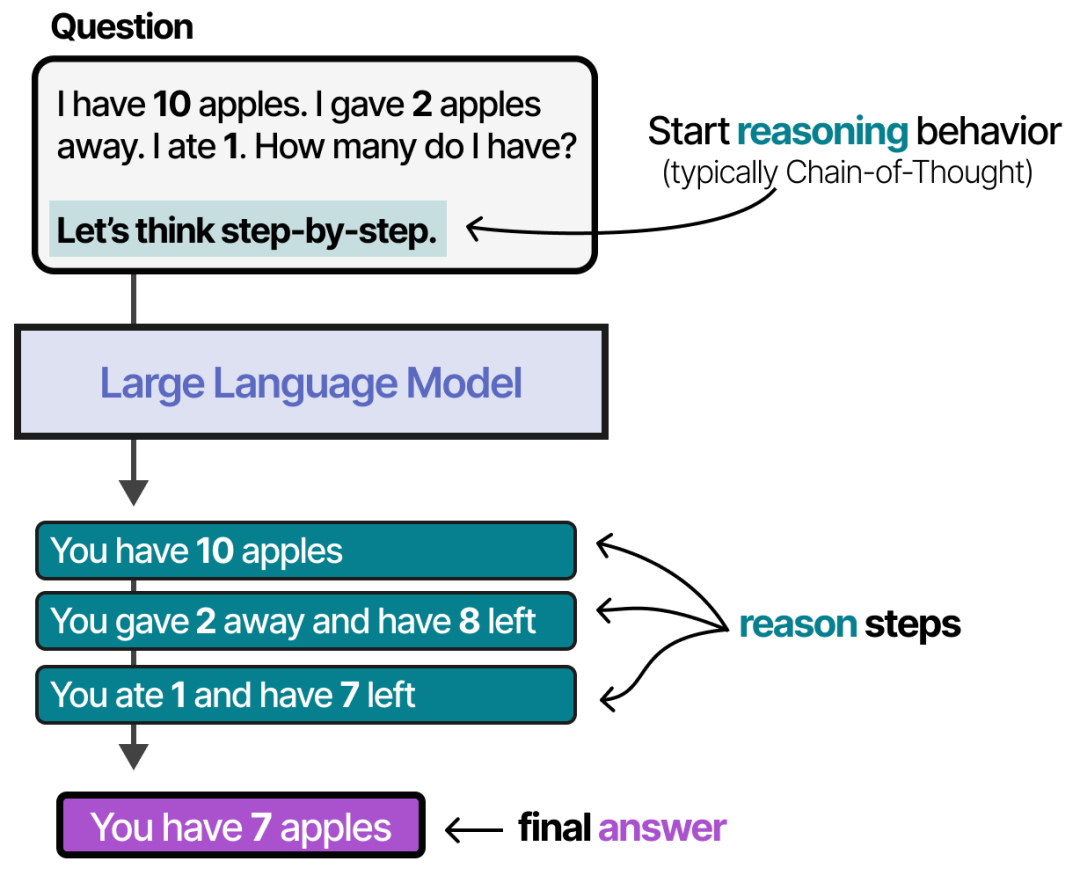
- Insufficient task generalization ability: LLMs have difficulty understanding complex problems, such as user questions that require multi-step reasoning to solve.
- Solution: Use Chain-of-Thought prompts to guide reasoning and answering step by step.
Helping LLM Return Expected Results
-
Output format uncontrollability issue: Different expressions of the same question may lead to significantly different answers from LLMs.
-
Solution: Use clearly designed and structured prompts to constrain the output range, such as format, tone, length, etc.
-
Output containing bias and safety risk issues: LLMs may output implicit biases or harmful answers.
-
Solution: Use ethical constraint prompts, such as analyzing from a neutral standpoint, avoiding discriminatory expressions, etc.
-
Output hallucination issue: LLMs may generate false information or fabricated facts, which can severely impact business operations.
-
Solution: Use hallucination suppression prompts, such as explicitly requiring answers based on known information, marking uncertain content, etc.
Output Standardization Application Examples
Standardized User Prompts for ensuring LLM outputs meet expected formats.
- Role Playing: Let LLM play a specific role, such as: you are a senior nutritionist designing meal plans for fitness enthusiasts.
- Reference Text: Provide reference text for output in the prompt, such as: answer the question based on the following contract terms: [Reference Text].
- Sample Learning: Provide input and output samples in the prompt.
- Formatted Output: Require output in formats such as Markdown, JSON, YAML, etc.
Formatted output example:
Extract all to-dos from the following meeting notes, with the requirements: 1. Each task should be output in the format "Responsible Person: Task Content (Deadline)" 2. Only output the items, no explanations. 3. If there is no clear time, mark as "To be confirmed." Meeting notes: [Paste record text]Output Credibility Application Examples
Credibility User Prompts to ensure LLM outputs are reliable.
- Constraint Mechanism: If the question cannot be answered, return “Insufficient information.”
- Verification Mechanism: For example, verify output results through external search content.
- Tolerance Mechanism: For example, generate answers to the same question multiple times and vote for the best answer.
- Cross-Validation Points: Insert human checkpoints at critical steps for verification.
- Explainability Enhancement: Let LLM output reasoning logic, such as: “Explain the basis for your answer.”
- Precision Enhancement: Ensure numerical calculations are accurate through multiple methods.
Credibility example:
Validate reliability through multiple methods, please solve the equation: 2x + 4 = 10 using three different methods: 1. Method 1: Algebraic rearrangement 2. Method 2: Graphical method 3. Method 3: Backward verification method After completion, check: Are the results of the three methods consistent? If consistent, output the final solution; otherwise, mark the contradictions.Chain-of-Thought Guided Complex Steps Application Examples
Chain-of-Thought User Prompts to guide LLM to follow a series of reasoning steps to solve complex problems. For example: “Please reason step by step: first… then… therefore…”.
- Atomic Decomposition: Break complex problems into indivisible sub-steps.
- Explicit Placeholders: Use placeholders ___ to command LLM to think and answer.
Chain-of-Thought application example:
Predict the CPU/memory usage demand for AWS EC2 over the next 6 months. Develop a scaling plan based on historical data: 1. **Data Extraction**: - Source: CloudWatch metrics → Key metrics: `CPUUtilization`, `MemoryUsage` - Time range: past 3 months, granularity: weekly average 2. **Trend Calculation**: - Monthly average CPU growth rate: (this month's average - average from 3 months ago) / 3 = ___% - Memory usage linear regression: `y = [slope]x + [intercept]` (x is the month) 3. **Peak Reservation**: - Historical peak CPU: ___% (occurrence time: ___) → Safety margin setting: ___% - Burst traffic tolerance: Should Auto Scaling be enabled? □ Yes □ No 4. **Instance Selection**: - Current configuration: m5.xlarge (4vCPU/16GB) - Demand forecast in 6 months: CPU = __ vCPU, Memory = __ GB → Recommended model: _____ 5. **Cost Optimization**: - Reserved instance coverage calculation: ___% → Recommended number of new reserved instances: ___ - Spot instance applicable scenarios: _____ (e.g., batch processing tasks)In October 2022, ReAct Reasoning Technology
In October 2022, Princeton University and Google Research jointly published the paper “ReAct: Synergizing Reasoning and Acting in Language Models,” proposing a groundbreaking “Reasoning-Acting Synergy Framework” that discusses how to synergize reasoning and acting in LLMs, that is, using LLMs to influence the surrounding environment.
- Paper: https://arxiv.org/abs/2210.03629
- Code: https://github.com/ysymyth/ReAct
The paper points out a new idea for executing actions through LLMs and changing the environment, laying the theoretical foundation for the subsequent birth of the first batch of AI Agent systems such as AutoGPT and LangChain. The key innovation of ReAct is that it allows LLMs to break spatial constraints, enabling them to operate in the real world.
The core idea of ReAct is called the “Triadic Synergy Loop”:
- Thought (Thinking, Analyzing Problems): Thinking about the strategic path to achieve goals. Drawing on the Chain-of-Thought reasoning model, LLMs analyze problems through self-decomposition and self-questioning. The core capability of the Reason module is contextual understanding and strategic planning. More importantly, it can correct erroneous content based on feedback and adjust strategies for actions.
- Action (Acting, Environmental Interaction): Executing operations (such as API, database, calculator, search) based on reasoning results.
- Observation (Observing, Obtaining Feedback): Checking the results of actions and entering the next round of reasoning or action. The core capability lies in collecting and analyzing results, as well as filtering and extracting information.
The ReAct loop (reasoning, acting, observing) can be simply understood as a variant of control theory in the AI field, serving as the foundation for influencing the external world and achieving objectives.
In March 2023, AutoGPT Experimental Project
AutoGPT is known as the world’s first AI Agent, an experimental project that references the ReAct paper, aiming to verify the execution capability of LLMs interacting with the external world.
- https://github.com/Significant-Gravitas/AutoGPT
The specific implementation of the ReAct triadic synergy loop includes:
- Reasoning: Calling ChatGPT.
- Action: The Agent Tools toolkit provides tools such as Python, browser, API, etc.
- Observation: By introducing a caching unit, it can automatically generate and optimize subsequent prompts based on historical records.
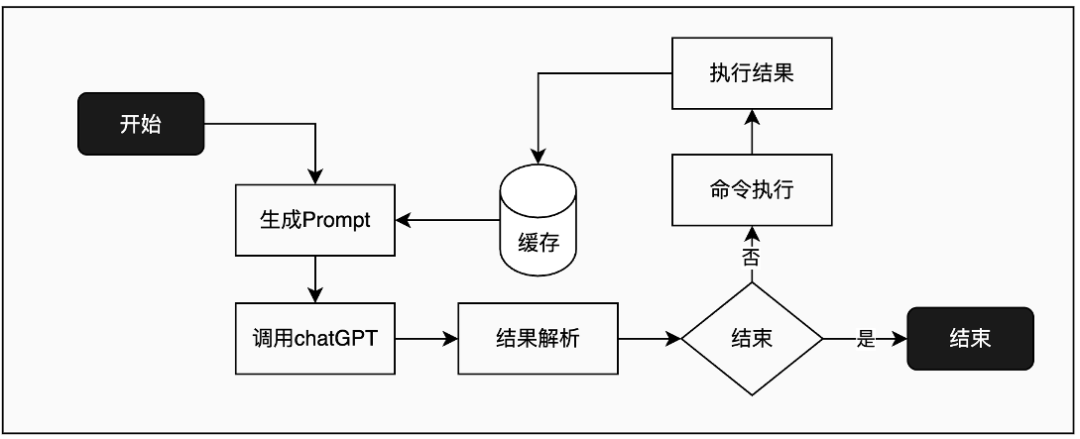
In June 2023, OpenAI Function Calling
In June 2023, OpenAI launched the Function Calling API feature, which draws on the Tools Routing mechanism of ReAct. The differences between ReAct and Function Calling are shown in the figure below.
Function Calling Application is the specific implementation of ReAct Tools Routing. This App provides an API that allows users to define their own Tools list while enabling LLMs to recognize the user’s Tools list, allowing LLMs to execute appropriate Function Calls based on User Prompts, that is, to identify when to call a specific function from the Tools list and pass parameters in a structured manner.
Technical details reference: https://www.cursor-ide.com/blog/openai-function-call-choice
In June 2023, OpenAI Agent Paradigm
The core idea of OpenAI Agent still comes from the ReAct triadic synergy loop. Unlike AutoGPT, which is a research project, OpenAI Agent is a software architectural paradigm aimed at production. Therefore, in addition to the triadic synergy loop of “planning, acting, observing,” OpenAI Agent systematically designs four major modules: Memory, Planning, Action, and Tools, as well as their collaborative relationships, thereby increasing the capability of reliable output and prompt sub-iteration optimization required in production environments.
- Planning: Understanding input and breaking down complex tasks into sub-tasks. It has sub-modules such as Chain-of-Thought, reflection, introspection, and sub-task decomposition. Through the Chain-of-Thought reasoning model, the Agent can plan necessary action steps.
- Action (Action + Tools): The ability of the Agent to execute specific actions and affect the external environment. Separating the actuator and toolkit makes it easier to expand.
- Memory: Providing LLM with an external memory storage unit to compensate for the long text limitations of LLMs. It is divided into short-term memory and long-term memory.
- Reliable Output (Memory + Reflection): The ability to evaluate outputs (constraints, verification, tolerance, explanation) and perform other operations.
- Self-Iterative Optimization (Memory + Planning): Automatically optimizing subsequent prompts based on output evaluations in historical records until validated by results.
It is evident that the OpenAI Agent framework organically integrates five capabilities: task decomposition, tool invocation, persistent context storage, result verification, and iterative loops.
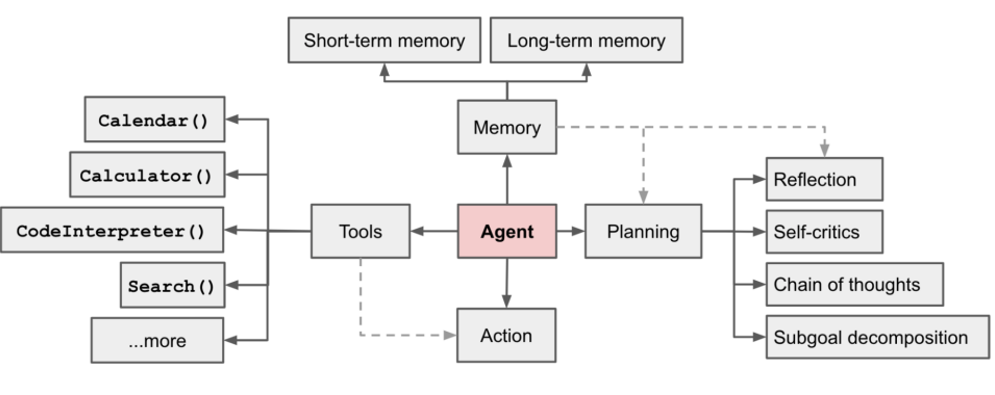
The execution process of the OpenAI Agent paradigm is as follows:
- LLM: Understand user intentions
- Planning: Plan the next action
- Agent + Tools: Execute specific operations
- Memory: Record historical actions (memory)
AI Agent software based on the OpenAI Agent software architecture paradigm can possess the following capabilities, allowing it to surpass traditional automation scripts, no longer relying on fixed processes (dynamic iterative planning), and exhibiting a certain degree of environmental adaptability and intelligent behavior. More specifically, its intelligence is reflected in:
- Autonomy: AI Agents can autonomously plan and execute tasks based on preset goals without requiring direct human control at every step.
- Intelligence: AI Agents possess certain learning, reasoning, decision-making, and problem-solving abilities.
- Reactivity & Adaptation: AI Agents can “perceive” their environment in various ways and respond dynamically, continuously learning and optimizing their behavior in complex environments.
In 2024, Multi-Agent Paradigm
Although the OpenAI Agent architectural paradigm has achieved breakthroughs in specific scenarios, its scalability in complex, multi-step, or collaborative scenarios is still limited, leading to the emergence of the Multi-Agent architectural paradigm.
- Too many tools may complicate choices
- Context becomes overly cumbersome
- Vertical specialization requirements are becoming deeper
- Collaboration logic among multiple business departments is difficult
As shown in the figure below, Multi-Agent emphasizes collaboration among multiple agents, each with a dedicated toolkit, and a Supervisor is responsible for distributing specific tasks to agents and coordinating communication between them.
The main differences between Multi-Agent and Single-Agent are as follows:
- Ensemble of Specialized Agents: Each agent is responsible for different functions and communicates through message queues, shared memory, etc. For example, MetaGPT constructs agents by simulating company departments (such as CEO, CTO, engineers), with modular roles, reusability, and clear responsibilities.
- Orchestration Layers / Meta-Agents: A key innovation of Multi-Agent is the introduction of meta-agents responsible for unified orchestration, coordinating the lifecycle of sub-agents, managing dependencies, assigning roles, and resolving conflicts. For example, in the ChatDev system, a CEO meta-agent assigns sub-tasks to different departmental agents and integrates their outputs into a unified strategic response.
- Advanced Reasoning and Planning: Multi-Agent systems embed recursive reasoning mechanisms, such as ReAct, Chain-of-Thought, and Thought Trees. These mechanisms allow agents to decompose complex tasks into multiple reasoning stages, evaluate intermediate results, and dynamically adjust action plans, thereby enhancing the system’s ability to cope with uncertainty or task failures.
- Persistent Memory Architectures: Multi-Agent can share knowledge across multiple task cycles or agents through a persistent memory system.
It is evident that Single-Agent is more suitable for the automation of single tasks, such as intelligent customer service, while Multi-Agent is closer to human organizational intelligence, such as multi-robot coordination systems.
The concept of Multi-Agent has been widely disseminated due to the Stanford paper “Generative Agents: Interactive Simulacra of Human Behavior.” In the paper, researchers constructed a virtual town Simulacra and placed 25 role-playing agents.
- https://arxiv.org/abs/2304.03442
Each agent is equipped with memory, planning, and reflection modules, and they share memory, storing planning, reflection behaviors, and all historical events. For any next action or question, the system retrieves memory and scores it based on “recency, importance, relevance” (triple-weight Retrieve memory retrieval algorithm), providing the highest-scoring memory to the agent.
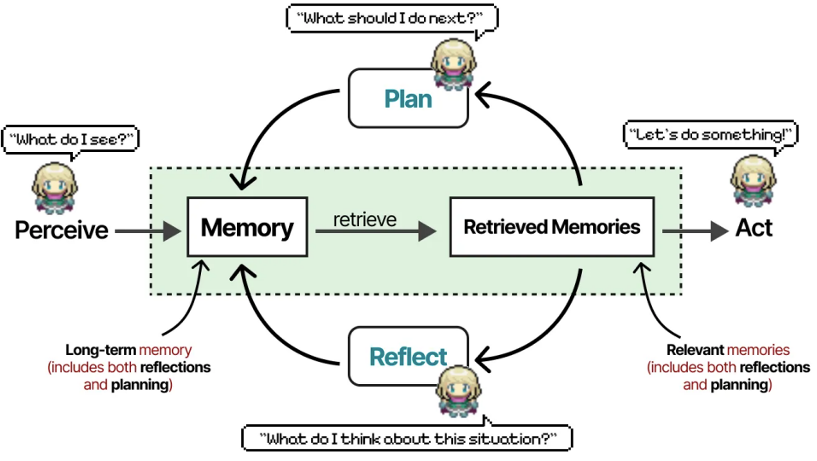
The interactive experiment in the virtual town yielded the following key conclusions:
- If any one of the functions of “memory, reflection, planning” is removed, the agent’s behavior becomes foolish (e.g., repeatedly having lunch or forgetting what was just discussed). This confirms that the abilities of “observation, planning, reflection” are crucial for agent performance. Planning without reflection is incomplete.
- Hierarchical memory architecture is key to behavioral coherence. Instant memory: stores current perceptions (what is seen and heard); short-term memory: retains recent key events (e.g., appointments); long-term memory: core beliefs of personality (e.g., I hate coffee).
- LLM + memory + environmental feedback agents can generate highly anthropomorphic behaviors, such as remembering friends, spreading news (e.g., who is running for mayor, soon the whole town knows), and forming new interpersonal relationships.
- The emergence mechanism of social relationships: agents autonomously construct social structures through information exchange.
The Simulacra virtual town has revealed the potential of the Multi-Agent paradigm in building “social agents.” The autonomy of Multi-Agent systems is higher than that of Single-Agent systems, enabling them to handle tasks requiring complex collaboration. At the same time, the information sharing among Multi-Agents allows them to learn and adapt in a broader range of tasks and environments.
Core Technical Principles of AI Agents
Memory
LLMs are stateless systems that do not persistently store user data; they only temporarily hold conversation context, referred to as “short-term memory.” Therefore, after multiple rounds of dialogue, LLMs may forget the content of previous conversations. However, in actual agent applications, LLMs often need to track the execution results of dozens or even hundreds of steps, not just recent operations. Thus, agents need to provide “long-term memory” functionality.
The hierarchical memory system allows agents to store and call different memory modules as needed, demonstrating human-like continuous learning capabilities in complex task processing.
Short-Term Memory
Short-term memory can be simulated by embedding the complete dialogue history into the flattened prompt. The length of short-term memory is related to the token length of the LLM. Currently, advanced LLMs support token lengths of hundreds of thousands. For example, Claude Sonnet 4 supports a context length of about 1 million tokens.
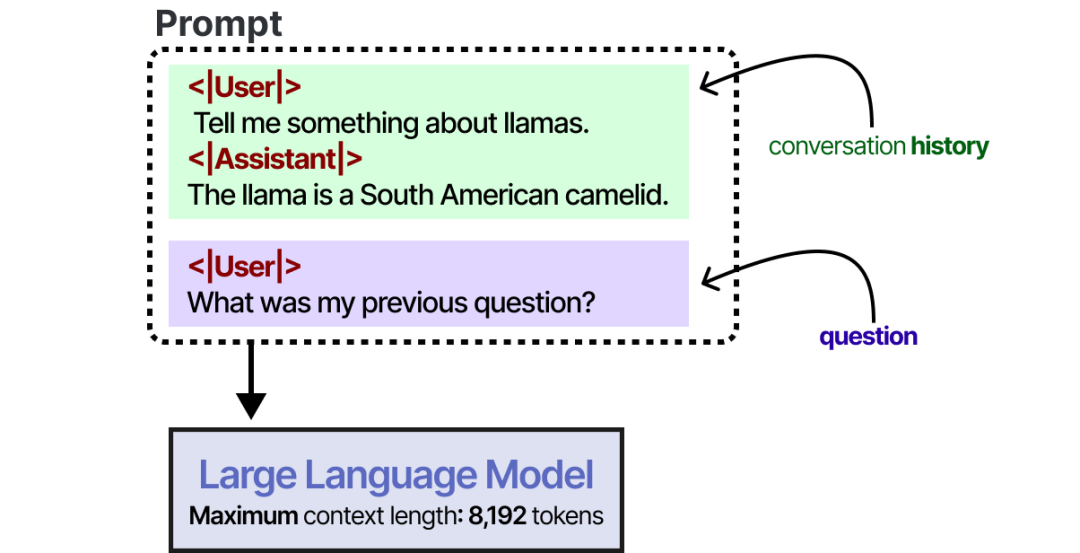
For particularly long dialogue histories, the commonly used History Summarize technique allows LLMs to summarize the dialogue history themselves. By continuously summarizing the dialogue, the scale of the dialogue records can be kept small. This reduces the number of tokens and allows tracking of only the most important information.
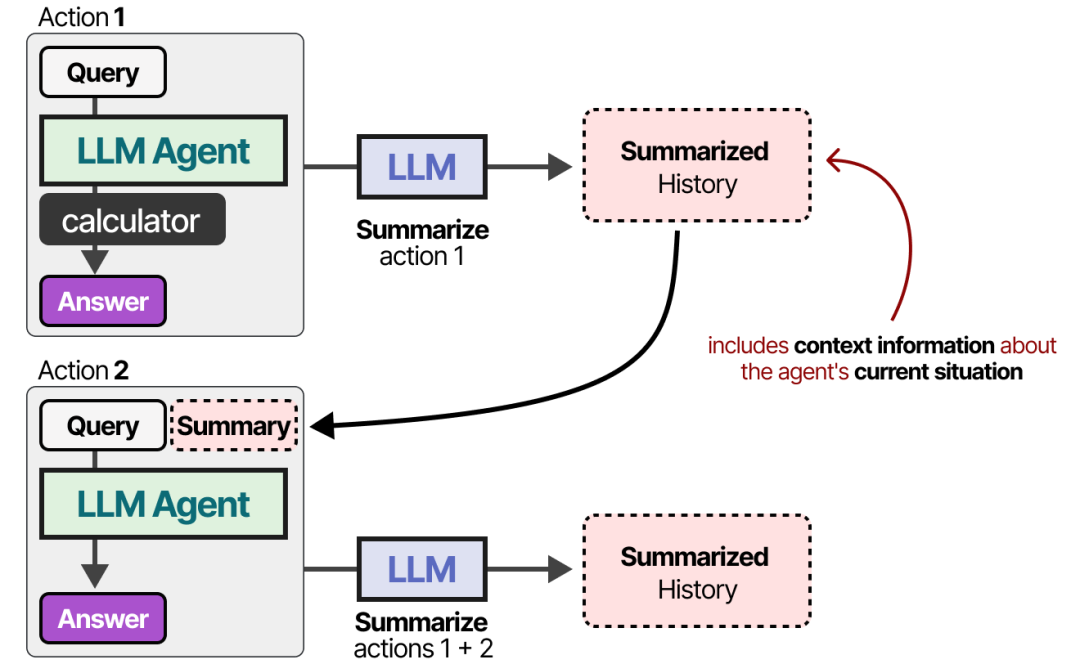
Long-Term Memory
A common technique for agents to achieve long-term memory is to use an external vector database to persistently store all dialogues, actions, and results.
When using long-term memory, first retrieve relevant information from the retrieval vector database based on the user query, then combine the query and relevant information into a new prompt, and finally input the augmented prompt into the LLM for generation. This is the basic principle of RAG technology.
Currently, researchers are subdividing long-term memory into various subclasses for different use cases based on actual business scenarios, including:
- Semantic Memory: Storing world knowledge
- Vector Memory: Recording dialogue history context
- Episodic Memory: Saving details of specific events
- Procedural Memory: Storing operational rules
- Etc.
Tools and Actions
Typically, LLMs themselves do not have tool execution capabilities, so agents need to provide actuator modules. However, LLMs can instruct agents on when to execute which tool and what parameter format to pass, such as JSON or YAML, so agents need to provide a tool list for LLMs to select based on task context.
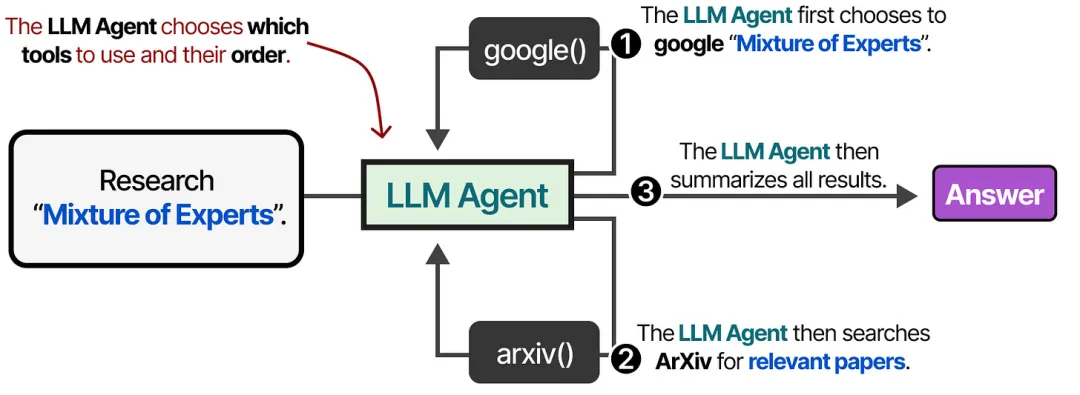
Currently, some LLMs have begun to integrate tool lists to compensate for their shortcomings. For example, the precision issue of LLM mathematical operations can be resolved through built-in mathematical operation tools. This is also a hot research direction known as Toolformer.
Planning
Reasoning LLM
Based on reasoning methods, LLMs can be classified into conventional LLMs and reasoning LLMs. The latter presents the reasoning process and steps to the user before answering questions. It is evident that reasoning LLMs are more suitable for AI Agent scenarios, and the main ways to implement reasoning LLMs are:
- Using Chain-of-Thought prompts to guide LLMs in executing reasoning.
- LLMs themselves have built-in reasoning processes of “deep thinking.” For example, DeepSeek-R1 guides the model to use reasoning processes through a reward mechanism.
ReAct Prompt
As mentioned earlier, when an agent has both Reasoning LLM and Tools & Action, it can achieve the ReAct = Reasoning + Action model. Here we mainly focus on how agents use ReAct prompts as system prompts to activate LLM ReAct mode.
After activating the LLM ReAct mode, inputting user queries will more accurately conduct the “think-act-observe” loop until an action achieves the goal and returns results.
Reflection
Reflection is key for agents to achieve “self-iterative optimization” and “reliable output.” No LLM can perfectly execute tasks; the key is to reflect on failures (learn and optimize action strategies). Common reflection techniques include Reflexion and Self-refine.
The Reflexion technique guides agents to include the following custom modules:
- Executor (Actor): Supported by ReAct and CoT for planning and action.
- Evaluator: Scores the output of the Actor in a short-term environment.
- Reflector (Self-reflection): Combines the Actor’s output and the Actor’s score for self-reflection, deciding how to optimize or exit the next round of prompts.
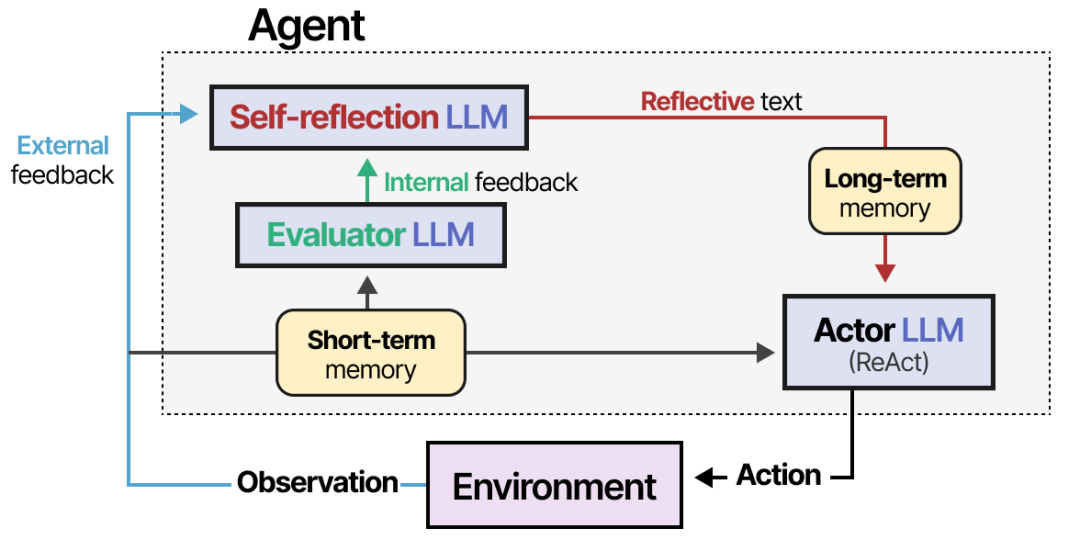
Self-refine, on the other hand, uses built-in intelligence from LLMs to perform “reflection,” where the same LLM provides feedback and refines the output.
Product Forms and Technical Schools of AI Agents
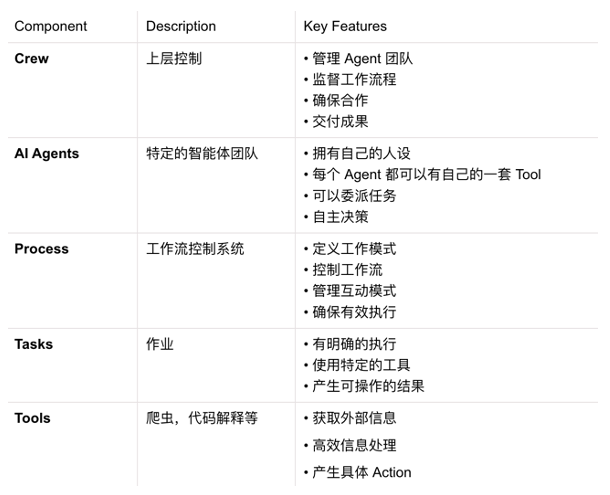
General Modules of Agents
Through the above analysis, we know that an AI Agent software architecture needs to have the following general modules, and additionally, depending on the specific product form, it will have its own characteristics and modules.
- LLM Selector, Connector: Select different LLM models for reasoning based on different scenarios.
- Planner and Iterative Planner: Support Planning to generate a TODO list and support Reflect for iterative optimization of the TODO list.
- Action: Func Calling, Tool Calling executors and toolkits.
- Context Processor: Context optimization, context compression.
- Memory Module: Short-term memory, long-term memory, memory compression.
- Execution Environment: Sandbox, virtual machine, etc.
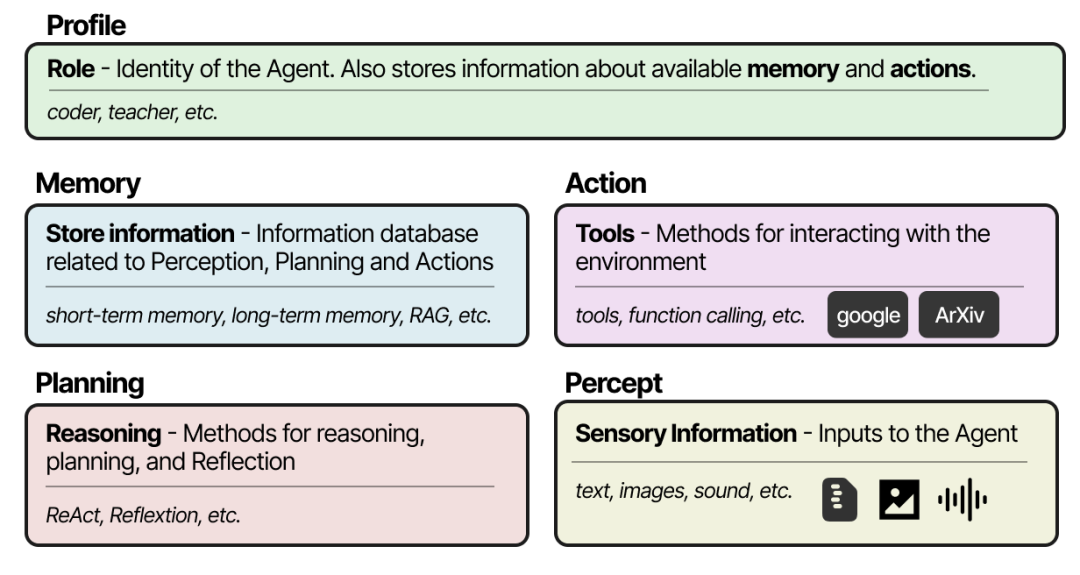
ReAct Autonomous Planning Agents
General Agents
ReAct autonomous planning agents are the main way to achieve general agents. For example, Manus itself is an agent based on the ReAct architecture, and its success lies in accumulating a wealth of tools and excellent context engineering derived from extensive engineering practice.
- Distinction Definition: The core is goal-oriented dynamic planning, where agents continuously adjust planning and actions based on feedback, following a four-step method (observe, reason, act, summarize).
- Special Modules: Memory compression module, Plan Loop module
- Application Scenarios: Complex problems with non-fixed execution paths, requiring a lot of information to replace human prompts.
DeepResearch Agents
Typical products include Perplexity, which compensates for the hallucination problem of LLMs in knowledge discovery (deep research) scenarios through search as a reference.
- Distinction Definition: Emphasizes the organization of information research themes, including collection, classification, induction, and logical structuring. However, it does not emphasize new ideas, new solutions, or new viewpoints. It mainly addresses the problem of quickly organizing old data and information.
- Special Modules: Reference searcher.
Iterative Evolution Agents
Typical products include Google AlphaEvolve, focusing on self-iterative cycles and exploring the boundaries of human unknown fields.
- Distinction Definition: An agent capable of helping humans break through knowledge boundaries, proposing new ideas and solutions for specific problems, and continuously iterating and evolving.
- Special Modules
- Agent Concurrency: Concurrently solving the same problem to obtain different answers, ensuring diversity of thought.
- Evaluator: Evaluating the more correct direction among multiple agents concurrently, continuing into the next round of concurrency.
Workflow Process Agents
Workflow agents are currently a well-implemented way for toB agents, making it easier to integrate with existing SOP workflows in enterprises. For example, LangGraph orchestrates the decision-making process of LLMs through different graph structures, achieving more complex and reliable execution paths.
- Distinction Definition: Developers artificially decompose tasks, and agents need to provide flexible orchestration capabilities for tasks/processes. Learning graph knowledge and other concepts is required, which places high demands on developers’ capabilities to create usable agents.
- Special Modules:
- Global State Persistence: Sharing information across multiple process nodes, such as state machines, variables, etc.
- Logical Control Components: if-else, do-while loops, etc.
- Process Control Components: sequential execution, parallel execution, loop execution.
- Application Scenarios: Complex but fixed processes.
From a logical perspective, Workflow is the efficiency logic of enterprise information transformation, while ReAct is the problem-solving logic oriented towards goals. As shown in the figure below, from a technical perspective, Workflow is a Router design, while ReAct is a Fully Autonomous design, with different levels of control over the problem (the degree of autonomy of the agent). Generally speaking, the higher the decision-making control of LLMs over system behavior, the stronger their “agent characteristics.”
Multi-Agent Collaborative Agents
Multi-Agent originated from “role-playing,” emphasizing “human organizational structure” and “collaboration,” with hopes of building a large “enterprise intelligent system” in this form. For example, CrewAI is one of the most well-known Multi-Agent platforms, inspired by team division in the real world, where each agent plays different roles, assigns different tasks, and shares goals. Essentially, it constructs an AI team through the organizational form of Multi-Agent, simulating human organizational division and collaboration patterns.
- Coordinating Agent: Task decomposition and scheduling (similar to a project manager)
- Expert Agent: Vertical domain execution (e.g., Stable Diffusion drawing agent)
- Validation Agent: Result reliability assessment
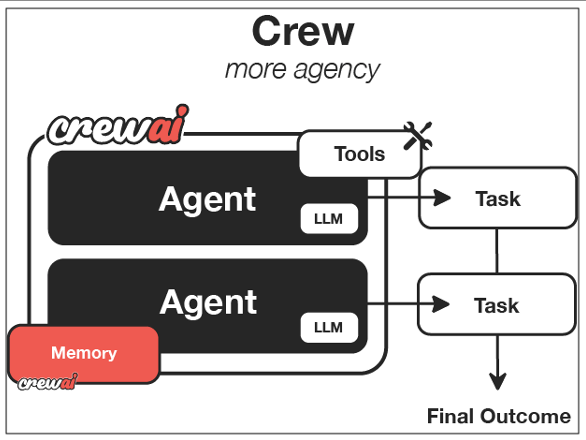
- Distinction Definition: Emphasizes autonomy, collaboration, and communication among multiple agents.
- Autonomy: Each agent can complete a complete task in a specific domain. For example: operation and maintenance agents, R&D agents.
- Collaboration: Multiple agents can complete more complex cross-domain tasks. For example: DevOps organizational structure role-playing Multi-Agent connects multiple agents.
- Special Components: Voting/decision modules, shared memory modules, A2A communication modules.
- Application Scenarios: Large systems with complex departmental divisions, where different departments provide their own agents.
However, it is worth noting that current Multi-Agent products often fall into the trap of being flashy but impractical, emphasizing technology rather than solving business problems. In many product marketing, there is a phenomenon of doing Multi for the sake of Multi, while in reality, functions that a single agent can meet do not need to be divided into multiple agents.
Key Challenges and Solutions Facing AI Agents
Key Issues
As mentioned above, ReAct autonomous planning agents are close to the initial definition of AI Agents, aiming for “fully autonomous artificial intelligence,” currently mainly releasing toC products. In contrast, Workflow process agents have more landing cases in the toB field, but there is an objective situation of supplementing “artificial intelligence” with “human intelligence.”
The fundamental reason for this situation is that both LLMs and AI Agents are still in the early stages of rapid development, inevitably facing many problems and challenges. Some of these issues are inherited from LLMs, while others are challenges in software engineering. For example: lack of unified standard architecture, communication protocols, and verifiable mechanisms, making cross-platform integration and generalized development difficult.
Here, we return to the five aspects of AI Agents: “planning, action, memory, reliable output, optimization loop,” and summarize the key challenges that AI Agents urgently need to address around these five aspects.
- Understanding of Private Domain Knowledge: LLMs by default only possess public domain knowledge but do not understand private domain knowledge defined internally by enterprises, making it difficult for LLMs to comprehend internal enterprise scenarios.
- Real-Time Data Capability: LLMs by default only possess outdated knowledge, while agent planning often requires real-time data.
- Hallucination Suppression Capability: LLM hallucinations cannot guarantee the quality of reliable output and optimization loops for agents. For example, during iterative planning, the same question may yield completely different two plans.
- Interpretability: The reasoning process of LLMs is either a black box or too lengthy. Poor interpretability can lead users to question reasoning results, making output unreliable.
- Risk of Infinite Loops: The self-optimizing loop of agents, which is goal-oriented, carries the risk of infinite loops, meaning high-cost risks.
- Error Propagation: In Multi-Agent scenarios, there are often complex collaborative paths, which may involve multiple LLM interactions. There is a problem of cumulative errors and error propagation, for example, a task may have more than 20 steps, increasing the probability of errors.
Solution Approaches
To enable agents to achieve more contextually appropriate behaviors. For example, agents will verify retrieved data before generating summaries. In multi-agent systems, this loop is crucial for collaborative consistency. The observations of each agent need to be coordinated with the outputs of other agents. To achieve this, shared memory and consistent logging are key.
-
RAG (Retrieval-Augmented Generation): Combining “real-time dynamic data retrieval” and “private static databases,” RAG can solve issues of real-time data, private domain knowledge, and large model hallucinations. For example, in enterprise knowledge bases and intelligent customer service scenarios, RAG can ensure that output results are based on external facts. In Multi-Agent systems, RAG serves as a shared “fact base,” ensuring consistency among agents and reducing error propagation caused by inconsistent contexts.
-
Programmatic Prompt Engineering: The programmatic implementation of prompt engineering can structurally design and constrain LLM input and output, allowing different agent types (such as planners, retrievers, summarizers) to use structured prompt templates based on their functions. Combining prompt templates, RAG, and other technologies can reduce the instability of manually adjusting prompts.
-
Hierarchical Memory Architecture: In addition to short-term and long-term memory, each agent can maintain private memory (local memory) and public memory (shared memory), enabling personalized decision-making and collaborative decision-making for agents.
-
Reflection and Self-Critique: Introduce “result verification module + exception retry mechanism + confidence assessment module” to strengthen multi-round iterative testing and evaluation systems. Agents can use a secondary reasoning process to review their outputs when completing tasks, thereby improving robustness and reducing error rates. This capability can also be extended to mutual evaluation among agents. For example, a validation agent can audit the summaries of other agents’ work to ensure quality control in collaboration.
-
Monitoring, Auditing, and Interpretability: By tracking audit mechanisms that record prompt inputs, tool calls, result outputs, reasoning processes, and system logs, the interpretability capability of agents can be built. Designing a comprehensive fact-checking and answer verification process for post-analysis, performance adjustment, fault tracking, and behavior optimization of AI Agents is crucial for identifying which agent caused an error and under what conditions the error occurred.
-
Setting Human Checkpoints: Based on interpretability, set human checkpoints for secondary confirmation at critical points, introducing a human-machine collaboration mechanism to add manual review functions for low-confidence answers.
-
Role-Based Multi-Agent Orchestration: On one hand, it helps meta-agents better complete task orchestration and distribution, and on the other hand, introduces role-based access control, sandboxes, and identity resolution for AI Agents to ensure that agents act within their scope and that their decisions can be audited or revoked.
-
Setting Budget Break Mechanisms: Set maximum iteration counts, such as max_cycles=50, to avoid infinite loops. Set cost monitoring, such as OpenAI cost alerts.
-
Establishing Enterprise Data Governance Mechanisms: Internal enterprise data is often scattered across different systems, with inconsistent formats and varying quality, making it difficult to obtain and integrate high-quality data to drive AI Agents. Establishing an enterprise-level data governance strategy to break down data silos is essential. For example, initially establishing a simple data integration and data cleaning platform, which can later expand to a unified data middle platform or data lake.
The Future of Agentic AI
The ultimate goal of Agentic AI is proactive intelligence, no longer limited to passive responses, but capable of automatically perceiving the environment, adapting to it, and actively reasoning based on goals. The future of Agentic AI requires breakthroughs in both LLMs and AI Agents:
- LLM Long Text
- LLM Hallucinations and Reliable Output
- Agent Causal Reasoning and Simulated Planning
- Multi-Agent Unified Orchestration, Unified Communication Standards, Unified Integration Architecture, such as: MCP, A2A protocols, etc.
- LLM Ethical Governance
– END –
About the “AI Cyber Space” WeChat Official Account:
Welcome to follow the “AI Cyber Space” WeChat Official Account, where we focus on the development and application of AI, big data, cloud computing, and network technology. We love open source and embrace open source!
Technology is Communication
Transforming clouds into rain, landing into forests