Author | Sanhe Factory Girl
Source | See “Read the Original” at the end
Concept
When optimizing more than one objective function in a single task, it is referred to as multi-task learning.
Some Exceptions
- “Multi-task of a single objective function”: In many tasks, the losses are combined and backpropagated, effectively optimizing a single objective function while optimizing multiple tasks. The summation of losses acts as a regularization strategy for multi-task learning, imposing a mean-like constraint on the parameters of multiple tasks, hence also called multi-task.
- “Single-task with multiple objective functions”: In some NLP scenarios, main tasks and auxiliary tasks are used, where many auxiliary task losses are not significant. I believe that although there are multiple losses, they are primarily for the main task and should not be considered multi-task.
Motivation
- Resource savings in applications, where a single model runs multiple tasks, resulting in double the happiness in the same time.
- It feels very intuitive; after spending 30 minutes to get out, one would definitely visit more shopping malls, and perhaps get a haircut and manicure.
- From the model’s perspective, the underlying probability distributions learned are usually effective for multiple tasks.
Two Common Approaches
- Hard parameter sharing mechanism: This method has been popular since decades ago (Multitask Learning. Autonomous Agents and Multi-Agent Systems). It is generally believed that the more tasks in a model, the lower the risk of overfitting due to noise reduction through parameter sharing. In the hard parameter sharing mechanism, the direct summation of losses is the simplest form of mean constraint.
- Soft parameter sharing mechanism: Each task has its own model and parameters. Regularization is applied to the distance between parameters of different models to ensure similarity in parameter space.
- Hybrid approach: A combination of the first two methods.
Why It Works
1. Better Generalization from Different Task Noises
Since all tasks have some noise to varying degrees, for example, when training a model on task A, our goal is to obtain a good representation for task A while ignoring data-related noise and generalization performance. Different tasks have different noise patterns, and learning two tasks simultaneously can yield a more generalized representation.
2. Auxiliary Feature Selection
If the main task is one where noise is severe, the data volume is small, and the data dimensions are high, it becomes difficult for the model to distinguish between relevant and irrelevant features. Other auxiliary tasks help focus the model’s attention on those features that truly have an impact.
3. Feature Interaction Mechanism
Feature interactions between different tasks can allow task B to easily learn certain features G, which may be difficult for task A to learn. This could be due to the complexity of the interaction between task A and feature G, or because other features hinder the learning of feature G.
4. Mutual Emphasis (Supervision) Mechanism
Multi-task learning tends to learn parts that most models emphasize. The learned space is more generalized, satisfying different tasks. Since a hypothesis space that performs well on a sufficient number of training tasks will also perform well on new tasks from the same environment, this helps the model demonstrate its generalization ability for new tasks (Deep Multi-Task Learning with Low Level Tasks Supervised at Lower Layers, Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts), making it very suitable for transfer learning scenarios.
5. Representation Bias Mechanism
Reduction transfer improves the model by introducing reduction bias, making the model more inclined towards certain hypotheses, which can act as a regularization effect. A common form of reduction bias is L1 regularization, which makes the model favor sparse solutions. In multi-task learning scenarios, this leads the model to prefer solutions that can explain multiple tasks simultaneously.
Why It May Not Work
First, let’s clarify whether it works, then explore why.
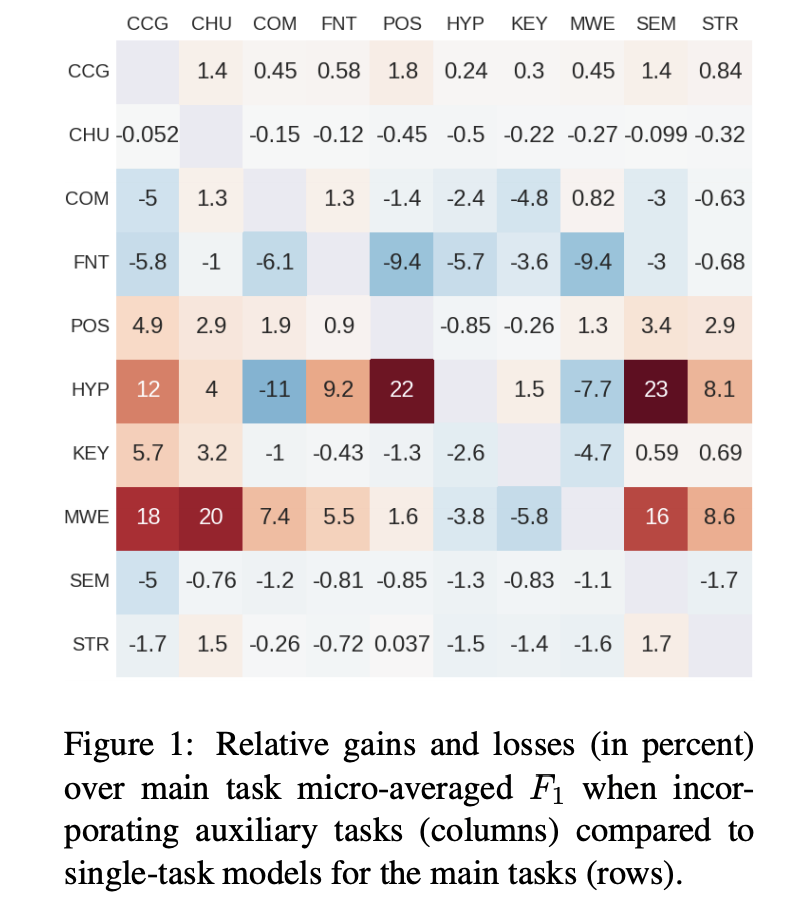
In Identifying beneficial task relations for multi-task learning in deep neural networks, the authors investigate what makes multi-task learning effective. They conducted comparative experiments using strictly identical parameters on NLP tasks. The results show that most multi-task approaches do not outperform single-task approaches. The authors conclude that the main features of single-task learning are at play, and that good multi-task performance occurs when “the main task is difficult to learn (slow gradient descent), while the auxiliary task is easier to learn, multi-task learning can yield good results”.
Why might it be ineffective? Because all effective reasons have their negative effects.
- The noise from different tasks enhances generalization, but when the model capacity is small, the introduced noise cannot be ignored.
- Feature selection and interaction mechanisms can lead to negative transfer, where shared information becomes misleading.
- …
Some Ideas for Multi-task Learning
1. Adding Sparse Regularization Constraints with Different Strengths Between Tasks
For example, block sparse regularization, applying L1 regularization to parameters of different tasks, or L1/Lx, where x>1, allows the model to automatically select which parameters to share. In Keras’s multi-task framework, this is achieved by summing the losses of multiple tasks and optimizing with a single optimizer.
2. Adding Matrix Priors to Intermediate Layers to Learn Task Relationships
3. Sharing Appropriate Related Structures
- High-level supervision: sharing most structures, with direct output branching (this is the approach most people take for multi-task learning). I believe that unless there are very refined adjustments, it is difficult to outperform multiple single-tasks.
- Low-level supervision: In Deep Multi-Task Learning with Low Level Tasks Supervised at Lower Layers, the authors model each task separately starting from lower layers using deep bi-RNNs, where the non-shared parts of the model are not influenced by other tasks, yielding good results.
4. Modeling Relationships Between Tasks
- There are many ways to model relationships between tasks, such as adding various constraint terms that encourage the parameter spaces of different tasks to be as similar as possible. There are many creative ways to expand this, and regularization is also a form of constraint. Summing losses is another way to establish relationships between tasks, as seen in Learning Multiple Tasks with Kernel Methods, where the model clusters tasks, and a represents the task parameters, encouraging the parameter spaces of various tasks to be close.
a represents the parameters of each task.
- Feature Interaction: In Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts, the authors achieve both sentiment judgment and cause extraction through high-level feature interactions across different tasks, which is similar to some multi-modal feature fusion methods.
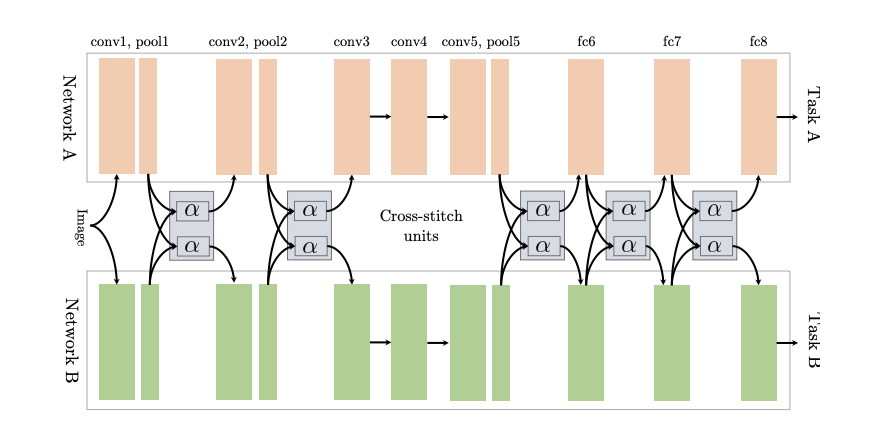
Cross-Stitch Networks for Multi-Task Learning connects two independent networks using a soft parameter sharing method, utilizing so-called cross-stitch units to determine how to leverage knowledge learned from other tasks and linearly combine it with outputs from earlier layers.
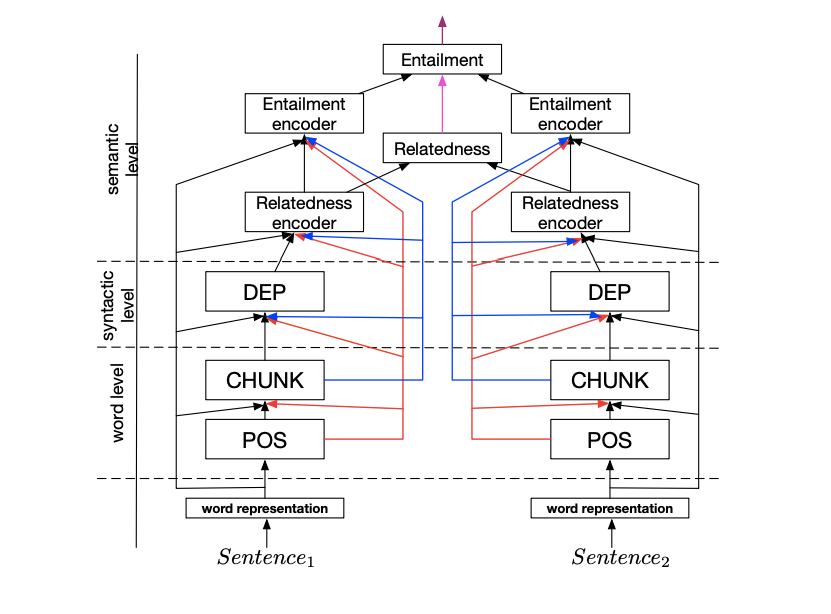
- Serial Joint Multi-Task Model
In the NLP field, tasks often have hierarchical relationships. In A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks, a serial structure is added while performing multi-tasking in parallel. For example, specific tasks: Part-of-Speech tagging (POS) -> Chunking -> Dependency Parsing -> Text Semantic Relatedness -> Text Entailment, where each sub-task has its own loss and also serves as input for other tasks.
5. Adjusting Task Relationships Using Loss
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics uses homoscedastic uncertainty to weight losses. The authors argue that optimal weights are related to the scale and noise of different tasks, and that noise includes cognitive uncertainty and heteroscedastic uncertainty, which depend on data uncertainty. The authors optimize weights in multi-task learning based on noise, adjusting each task’s relative weight in the cost function based on the level of noise.
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks dynamically adjusts weights based on the rate of decrease of different task losses. The authors define a specialized optimization function for weights, which is the optimization degree of each task’s loss relative to the first step loss, and if a task’s optimization degree is low, this loss will be increased to adjust the weight for that task, achieving a balance in learning degrees of losses.
Applications | Suitable Tasks
Auxiliary tasks, related tasks, adversarial tasks, etc.
Let’s Communicate
Highly recommended! NewBeeNLP has established multiple discussion groups in various directions (such as Machine Learning / Deep Learning / Natural Language Processing / Search Recommendations / Interview Discussions / etc.), with limited spots available. Hurry and add the WeChat below to join the discussion and learning! (Please make sure to note your information to be accepted)

References
[1]
An Overview of Multi-task Learning in Deep Neural Networks: https://arxiv.org/abs/1706.05098
[2]
Identifying beneficial task relations for multi-task learning in deep neural networks: https://www.aclweb.org/anthology/E17-2026/
[3]
Multitask Learning. Autonomous Agents and Multi-Agent Systems: https://www.cs.cornell.edu/~caruana/mlj97.pdf
[4]
Deep Multi-Task Learning with Low Level Tasks Supervised at Lower Layers: https://www.aclweb.org/anthology/P16-2038/
[5]
Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts: https://www.aclweb.org/anthology/P19-1096/
[6]
Identifying beneficial task relations for multi-task learning in deep neural networks: https://www.aclweb.org/anthology/E17-2026/
[7]
Learning Multiple Tasks with Kernel Methods: https://jmlr.org/papers/v6/evgeniou05a.html
[8]
Cross-Stitch Networks for Multi-Task Learning: https://arxiv.org/abs/1604.03539
[9]
A Joint Many-Task Model: Growing a Neural Network for Multiple NLP Tasks: https://arxiv.org/abs/1611.01587
[10]
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics: https://arxiv.org/abs/1705.07115
[11]
GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks: https://arxiv.org/abs/1711.02257
[12]
Auxiliary tasks, related tasks, adversarial tasks, etc.: https://blog.csdn.net/qq280929090/article/details/79649163
– END –


BERT-Flow | New SOTA for Text Semantic Representation
2020-12-23
Your model may have learned incorrectly!! A deep dive into answer position bias
2020-12-10

Node2Vec: Everything Can Be Embedded
2020-12-03