Deep Reinforcement Learning Laboratory
Official Website:http://www.neurondance.com/Forum:http://deeprl.neurondance.com/This article is reproduced from: Machine Heart
Researchers from Tsinghua University and UC Berkeley found that without any changes to the algorithm or network architecture, using MAPPO (Multi-Agent PPO) achieved performance comparable to SOTA algorithms on three representative multi-agent tasks (Multi-Agent Particle World, StarCraft II, Hanabi).
In recent years, multi-agent reinforcement learning (MARL) has made breakthrough progress. For example, DeepMind’s AlphaStar defeated professional StarCraft players, surpassing 99.8% of human players; OpenAI Five repeatedly defeated world champion teams in DOTA2, becoming the first AI system to defeat champions in esports; and agents trained in the simulated physics environment hide-and-seek can use tools like humans. Most of these agents were trained using on-policy algorithms (e.g., IMPALA[8]), which require high parallelism and substantial computational power. For instance, OpenAI Five consumed 128,000 CPUs and 256 P100 GPUs to collect data samples and train networks.However, most academic institutions find it challenging to equip such a level of computational resources. Therefore, there is almost a consensus in the MARL field:Compared to on-policy algorithms (e.g., PPO[3]), off-policy algorithms (e.g., MADDPG[5], QMix[6]) are more suitable for training agents under limited computational resources due to their higher sampling efficiency, and have evolved a series of SOTA algorithms that solve specific problems (domain-specific) (e.g., SAD[9], RODE[7]).However, researchers from Tsinghua University and UC Berkeley presented a different perspective in a paper: MARL algorithms need to consider both data sample efficiency and algorithm runtime efficiency.Under limited computational resources, on-policy algorithms — MAPPO (Multi-Agent PPO) have significantly higher algorithm runtime efficiency and comparable (or even higher) data sample efficiency compared to off-policy algorithms.Interestingly, researchers found that only minimal hyperparameter search is needed for MAPPO to achieve performance comparable to SOTA algorithms without any changes to the algorithm or network architecture. Furthermore, they provided five important suggestions to enhance MAPPO’s performance and open-sourced a set of optimized MARL algorithm source code (code address: https://github.com/marlbenchmark/on-policy).So, if your MARL algorithm is not working, you might want to refer to this research; it could be that you are not using the right algorithm. If you focus on researching MARL algorithms, consider using MAPPO as a baseline, as it may improve task benchmarks. If you are at the beginner stage of MARL research, this source code is worth having, as it is reportedly well-developed and easy to use. This paper was completed by Wang Yu, Wu Yi, and other researchers from Tsinghua University in collaboration with researchers from UC Berkeley. The researchers will continue to open-source more optimized algorithms and tasks (repository link: https://github.com/marlbenchmark)

Paper link: https://arxiv.org/abs/2103.01955What is MAPPOPPO (Proximal Policy Optimization)[4] is a currently very popular single-agent reinforcement learning algorithm and is also the preferred algorithm for OpenAI during experiments, indicating its wide applicability. PPO adopts a classic actor-critic architecture. The actor network, also known as the policy network, receives local observations (obs) and outputs actions (action); the critic network, also known as the value network, receives states (state) and outputs action values (value) to evaluate the quality of the actions output by the actor network. It can be intuitively understood as the judge (critic) scoring the performance (action) of the actor.MAPPO (Multi-agent PPO) is a variant of the PPO algorithm applied to multi-agent tasks, also adopting the actor-critic architecture. The difference is that the critic now learns a centralized value function (centralized value function), meaning that the critic can observe global information (global state), including information from other agents and the environment.Experimental EnvironmentNext, let’s introduce the experimental environments in the paper. The paper selected three representative cooperative multi-agent tasks, and one important reason for choosing cooperative tasks is that they have clear evaluation metrics, making it easier to compare different algorithms.The first environment is the Multi-agent Particle World (MPE) task open-sourced by OpenAI (source code link: https://github.com/openai/multiagent-particle-envs)[1]. The lightweight environment and diverse task settings make it the preferred testing platform for quickly validating MARL algorithms. In MPE, there are three cooperative tasks: Spread, Comm, and Reference, as shown in Figure 1.
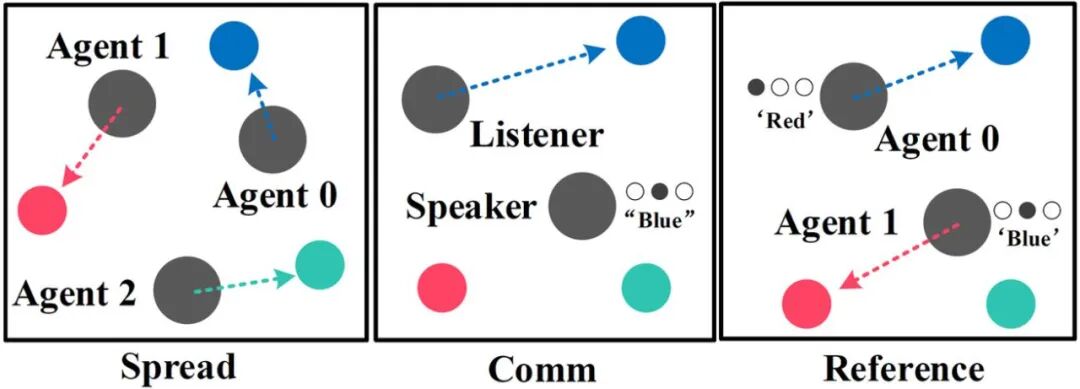
Figure 1: The three sub-tasks in the MPE environment: Spread, Comm, and ReferenceThe second environment is the famous StarCraft II task in the MARL field (source code: https://github.com/oxwhirl/smac), as shown in Figure 2. This task was initially proposed by M. Samvelyan et al. [2] and provides 23 experimental maps, with the number of agents ranging from 2 to 27. Our agents need to cooperate to defeat enemy agents to win the game. Since the release of this task, many researchers have conducted algorithm research based on its characteristics, such as the classic algorithm QMix[6] and the recently published RODE[7]. It is worth noting that this paper uses the latest version SC2.4.10 due to version iterations of StarCraft II, which have performance differences between different versions.

Figure 2: Two representative maps in the StarCraft II environment: Corridor and 2c vs. 64zgThe third environment is a pure cooperative task called Hanabi proposed by Nolan Bard et al. [3] in 2019 (source code: https://github.com/deepmind/hanabi-learning-environment). Hanabi is a turn-based card game, where only one player can play a card each round. Compared to previous multi-agent tasks, an important feature of Hanabi is pure cooperation, where each player needs to infer the intentions of other players to complete cooperation and score points. The number of players in Hanabi can be 2-5, and Figure 3 shows a task diagram for 4 players. Interested readers can try playing it themselves.
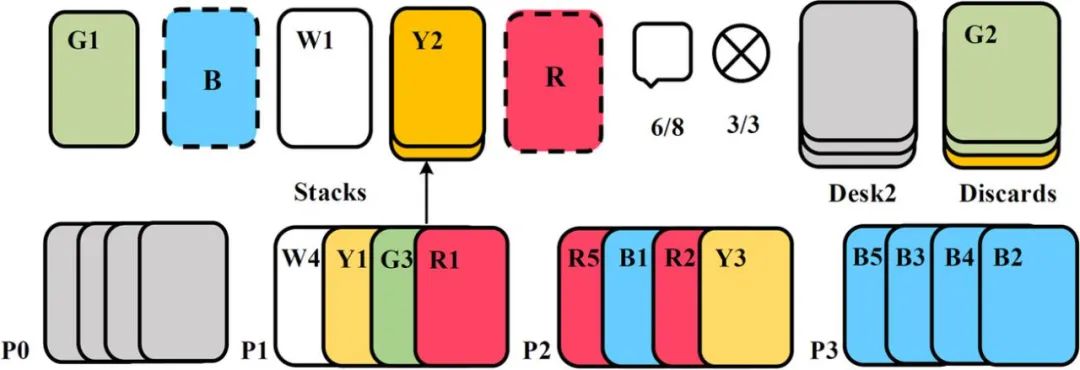
Figure 3: Task diagram for 4 players in Hanabi-FullExperimental ResultsFirst, let’s take a look at the experimental results provided in the paper. It is important to note that all experiments in the paper were completed on a single host with a configuration of 256 GB of memory, a 64-core CPU, and a GeForce RTX 3090 24GB graphics card. Additionally, the researchers stated that all algorithms in this paper were fine-tuned, so some experimental results reproduced in this paper may outperform the original paper.(1) MPE EnvironmentFigure 4 shows the comparison of data sample efficiency and algorithm runtime efficiency of different algorithms in MPE, where IPPO (Independent PPO) indicates that the critic learns a distributed value function (decentralized value function), meaning that both the critic and actor’s inputs are local observations, and IPPO and MAPPO maintain consistent hyperparameters; MADDPG[5] is a very popular off-policy algorithm in the MARL field and is an algorithm developed for MPE, while QMix[6] is a MARL algorithm developed for StarCraft II and is a commonly used baseline in StarCraft II.From Figure 4, it can be seen that compared to other algorithms, MAPPO not only has comparable data sample efficiency and performance (performance) (Figure (a)), but also has significantly higher algorithm runtime efficiency (Figure (b)).
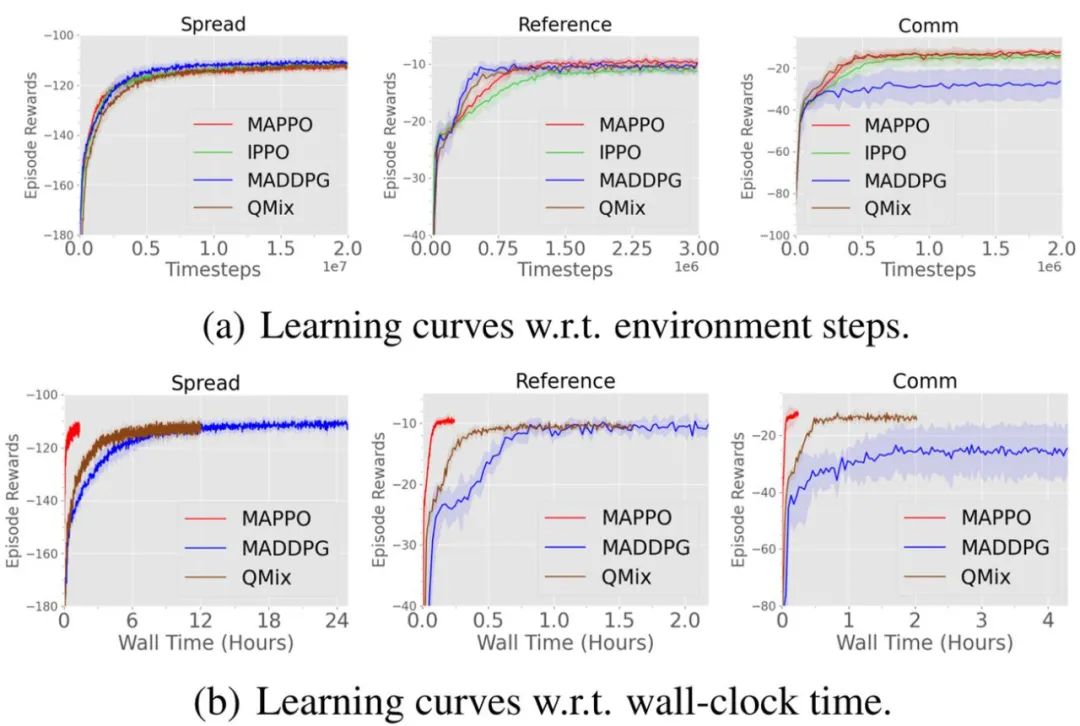
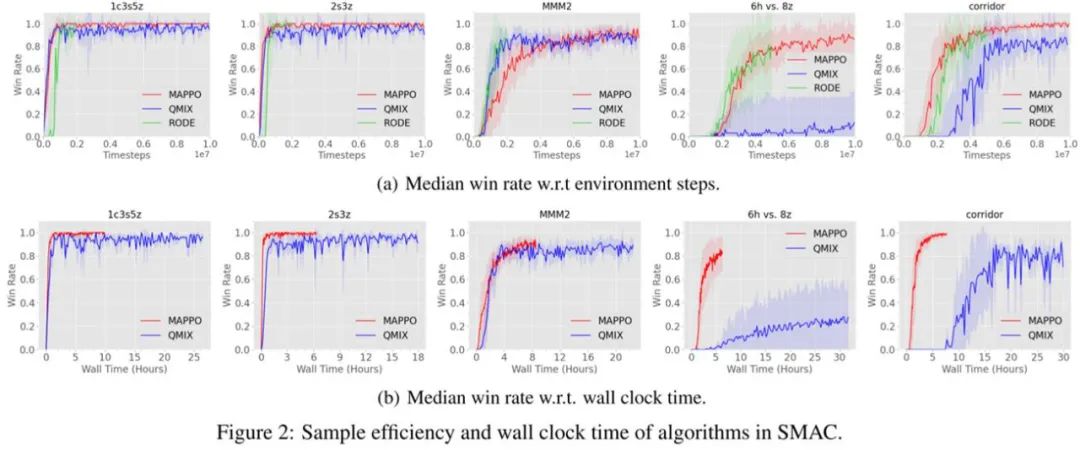
Figure 4: Comparison of data sample efficiency and algorithm runtime efficiency of different algorithms in MPE(2) StarCraft II EnvironmentTable 1 shows the win rate comparison of MAPPO with IPPO, QMix, and the SOTA algorithm RODE developed for StarCraft II. In the case of truncating to 10M data, MAPPO achieved SOTA win rates on 19 out of 23 maps. Except for 3s5z vs. 3s6z, the difference between other maps and SOTA algorithms is less than 5%, while 3s5z vs. 3s6z did not fully converge when truncated to 10M; if truncated to 25M, it can achieve a win rate of 91%.Figure 5 shows the comparison of data sample efficiency and algorithm runtime efficiency of different algorithms in StarCraft II. It can be seen that MAPPO actually has comparable data sample efficiency to QMix and RODE, as well as faster algorithm runtime efficiency. Since only 8 parallel environments were used during the actual training of the StarCraft II task, while 128 parallel environments were used in the MPE task, the algorithm runtime efficiency in Figure 5 is not as large as in Figure 4. However, even so, MAPPO’s impressive performance and runtime efficiency can still be observed.
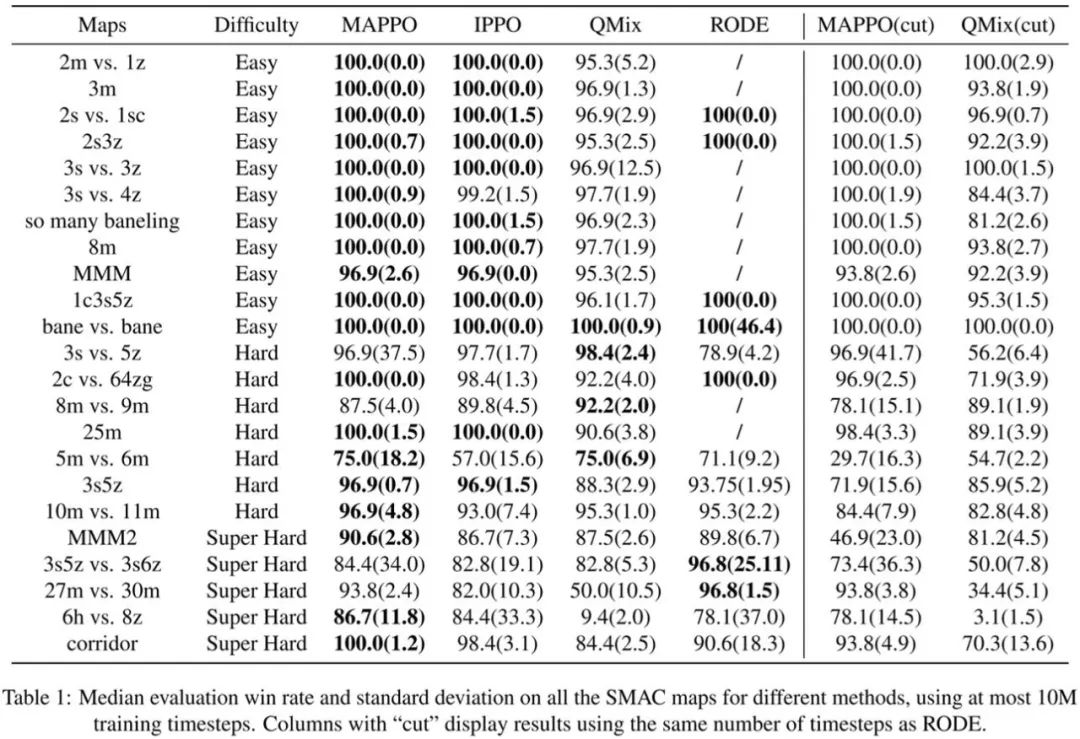
Table 1: Win rate comparison of different algorithms in 23 maps of StarCraft II, where the cut mark indicates that MAPPO and QMix were truncated to the same number of steps as RODE for a fair comparison with SOTA algorithms.
(3) Hanabi EnvironmentSAD is a SOTA algorithm developed for the Hanabi task. It is worth noting that the score of SAD is taken from the original paper, where the original authors ran 13 random seeds, each requiring about 10B data. Due to time constraints, MAPPO only ran 4 random seeds, each with about 7.2B data. From Table 2, it can be seen that MAPPO can still achieve scores comparable to SAD.
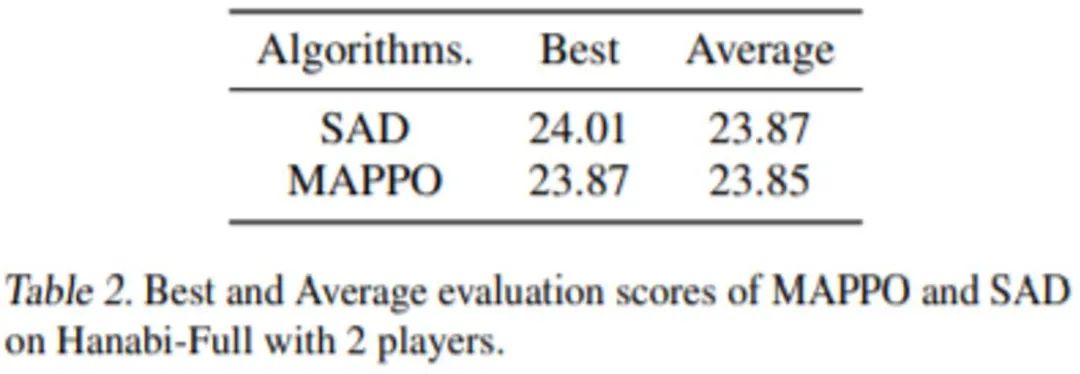
Table 2: Score comparison of MAPPO and SAD in the 2-player Hanabi-Full task.Five SuggestionsAfter reviewing the experimental results provided in the paper, let’s return to the initial question: Are you using MAPPO correctly?Researchers found that even though multi-agent tasks differ significantly from single-agent tasks, the PPO implementation suggestions previously given for other single-agent tasks are still very useful, such as input normalization, value clipping, max gradient norm clipping, orthogonal initialization, GAE normalization, etc. However, in addition to these, the researchers provided five additional suggestions for the MARL field and other easily overlooked factors.
-
Value normalization: Researchers used PopArt for value normalization and pointed out that using PopArt is beneficial and harmless.
-
Agent Specific Global State: Use agent-specific global information to avoid missing global information and high dimensionality. It is worth mentioning that researchers found that the existing global information in StarCraft II has information omissions, and even the information it contains is less than the local observations of agents, which is also an important reason for MAPPO’s poor performance when directly applied to StarCraft II.
-
Training Data Usage: For simple tasks, it is recommended to use 15 training epochs, while for more difficult tasks, try 10 or 5 training epochs. Additionally, try to use a complete set of training data rather than splitting it into many small batches for training.
-
Action Masking: In multi-agent tasks, it is common for agents to be unable to perform certain actions. It is recommended to mask these invalid actions during both forward execution and backpropagation, so they do not participate in action probability calculations.
-
Death Masking: In multi-agent tasks, it is also common for certain agents or some agents to die midway (e.g., in StarCraft II). When an agent dies, only retain its agent ID and mask other information to learn a more accurate state value function.
More experimental details and analyses can be found in the original paper.Reference links:[1] Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., and Mor-datch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Neural Information Processing Systems (NIPS), 2017.[2] M. Samvelyan, T. Rashid, C. Schroeder de Witt, G. Farquhar, N. Nardelli, T.G.J. Rudner, C.-M. Hung, P.H.S. Torr, J. Foerster, S. Whiteson. The StarCraft Multi-Agent Challenge, CoRR abs/1902.04043, 2019.[3] Bard, N., Foerster, J. N., Chandar, S., Burch, N., Lanctot, M., Song, H. F., Parisotto, E., Dumoulin, V., Moitra, S., Hughes, E., et al. The Hanabi challenge: A new frontier for AI research. Artificial Intelligence, 280:103216, 2020.[4] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. CoRR, abs/1707.06347, 2017.[5] Lowe, R., Wu, Y., Tamar, A., Harb, J., Abbeel, P., and Mor-datch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Neural Information Processing Systems (NIPS), 2017.[6] Rashid, T., Samvelyan, M., Schroeder, C., Farquhar, G., Foerster, J., and Whiteson, S. QMIX: Monotonic value function factorization for deep multi-agent reinforcement learning. volume 80 of Proceedings of Machine Learning Research, pp. 4295–4304. PMLR, 10–15 Jul 2018.[7] Wang, T., Gupta, T., Mahajan, A., Peng, B., Whiteson, S., and Zhang, C. RODE: Learning roles to decompose multi-agent tasks. In International Conference on Learning Representations, 2021.[8] Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V., Ward, T., Doron, Y., Firoiu, V., Harley, T., Dunning, I., et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In International Conference on Machine Learning, pp. 1407–1416, 2018.[9] Hu, H. and Foerster, J. N. Simplified action decoder for deep multi-agent reinforcement learning. In International Conference on Learning Representations, 2020.Reproduced from: https://mp.weixin.qq.com/s/KPS6RWtmeawR_vPAY4Bh1A
End
Summary 1:Zhou Zhihua || How to Conduct Research in AI – Writing High-Quality Papers
Summary 2:The Most Comprehensive Deep Reinforcement Learning Resources on the Internet (Forever Updated)
Summary 3:Complete Code/Exercise Answers for “Introduction to Reinforcement Learning”
Summary 4:30+ Must-Know AI Conference Lists
Summary 5:Summary of 57 Deep Reinforcement Learning Papers from 2019
Summary 6: Ten Thousand Words Summary || The Path of Reinforcement Learning
Summary 7:Ten Thousand Words Summary || Comprehensive Summary of Multi-Agent Reinforcement Learning (MARL)
Summary 8:Deep Reinforcement Learning Theory, Models, and Tuning Techniques
End
The 101st article: OpenAI scientists propose a new reinforcement learning algorithm
The 100th article: Alchemy: Meta-Reinforcement Learning Benchmark Environment
The 99th article: NeoRL: Offline Reinforcement Learning Benchmark Close to the Real World
The 98th article: Comprehensive Summary of Estimation Methods for Value Functions and Advantage Functions
The 97th article: Detailed Interpretation of the MuZero Algorithm Process
The 96th article: Summary of Distributional Reinforcement Learning
The 95th article: How to Improve the Generalization Ability of Reinforcement Learning Algorithm Models?
The 94th article: Multi-Agent Reinforcement Learning Research on “StarCraft II”
The 93rd article: MuZero Achieves New SOTA on Atari Benchmarks
The 92nd article: Google AI Head Jeff Dean Awarded the von Neumann Medal
The 91st article: Detailed Explanation of Using TD3 Algorithm to Complete BipedalWalker Environment
The 90th article: Top-K Off-Policy RL Paper Reproduction
The 89th article: Tencent Open Sources Distributed Multi-Agent League Framework
The 88th article: Comprehensive Summary of Hierarchical Reinforcement Learning (HRL)
The 87th article: Summary of 165 Accepted Papers from CoRL2020
The 86th article: Summary of 287 Deep Reinforcement Learning Papers from ICLR2021
The 85th article: Summary of 279 Pages on “Model-Based Reinforcement Learning Methods”
The 84th article: Alibaba Reinforcement Learning Research Assistant/Intern Recruitment
The 83rd article: Summary of 180 Top Conference Reinforcement Learning Papers from NIPS2020
The 82nd article: Does Reinforcement Learning Need Batch Normalization?
The 81st article: Review of Theoretical Research on Multi-Agent Reinforcement Learning Algorithms
The 80th article: Detailed Explanation of Reinforcement Learning “Reward Function Design”
The 79th article: Noah’s Ark Open Sources High-Performance Reinforcement Learning Library “Xingtian”
The 78th article: How Does Reinforcement Learning Trade Off “Exploration” and “Exploitation”?
The 77th article: Deep Reinforcement Learning Engineer/Researcher Interview Guide
The 76th article: DAI2020 Autonomous Driving Challenge (Reinforcement Learning)
The 75th article: Distributional Soft Actor-Critic Algorithm
The 74th article: 【Public Welfare Open Class】 RLChina2020
The 73rd article: Tensorflow2.0 Implementation of 29 Deep Reinforcement Learning Algorithms
The 72nd article: 【Ten Thousand Words Long Article】 Solving the “Sparse Reward” Problem
The 71st article: 【Open Class】 Advanced Reinforcement Learning Topics
The 70th article: DeepMind Releases “Offline Reinforcement Learning Benchmark”
The 69th article: Deep Reinforcement Learning 【Seaborn】 Plotting Methods
The 68th article: 【DeepMind】 Multi-Agent Learning 231 Page PPT
The 67th article: Summary of 126 Reinforcement Learning Papers from ICML2020 Conference
The 66th article: Distributed Reinforcement Learning Framework Acme, Enhanced Parallelism
The 65th article: DQN Series (3): Prioritized Experience Replay (PER)
The 64th article: UC Berkeley Open Sources RAD to Improve Reinforcement Learning Algorithms
The 63rd article: Huawei Noah’s Ark Recruitment || Reinforcement Learning Research Intern
The 62nd article: ICLR2020- 106 Deep Reinforcement Learning Top Conference Papers
The 61st article: David Silver Personally Explains AlphaGo and AlphaZero
The 60th article: Didi Hosts Reinforcement Learning Challenge: KDD Cup-2020
The 59th article: Agent57 Dominates All Classic Atari Games Against Humans
The 58th article: Tsinghua Open Sources “Tianshou” Reinforcement Learning Platform
The 57th article: Google Releases “Reinforcement Learning” Framework “SEED RL”
The 56th article: RL Father Sutton on the Difficulty of Implementing Strong AI Algorithms
The 55th article: Internal Recommendation || Alibaba 2020 Reinforcement Learning Intern Recruitment
The 54th article: Top Conference || 65 “IJCAI” Deep Reinforcement Learning Papers
The 53rd article: John Schulman Talks About Research in TRPO/PPO
The 52nd article: How to Solve Reproducibility and Robustness in “Reinforcement Learning”?
The 51st article: Ten Key Points of Reinforcement Learning and Optimal Control
The 50th article: Microsoft Global Deep Reinforcement Learning Open Source Project Open Application
The 49th article: DeepMind Releases Reinforcement Learning Library RLax
The 48th article: Detailed Notes on AlphaStar Process
The 47th article: Solutions to the Exploration-Exploitation Dilemma
The 46th article:DQN Series (2): Double DQN Algorithm
The 45th article:DQN Series (1): Double Q-learning
The 44th article: The Most Comprehensive Tool Summary in the Research Community
The 43rd article: Resurrection || How to Rebuttal Top Conference Academic Papers?
The 42nd article: Overview of Materials from Beginner to Master in Deep Reinforcement Learning
The 41st article: Call for Papers || ICAPS2020: DeepRL
The 40th article: Intern Recruitment || Huawei Noah’s Ark Laboratory
The 39th article: Didi Intern || Deep Reinforcement Learning Direction
The 38th article: AAAI-2020 || 52 Deep Reinforcement Learning Papers
The 37th article: Call For Papers# IJCNN2020-DeepRL
The 36th article: Experiences in Reproducing “Deep Reinforcement Learning” Papers
The 35th article: α-Rank Algorithm Improvements by DeepMind and Huawei
The 34th article: From Paper to Coding, DRL Challenges in 34 Types of Games
The 33rd article: DeepMind – 102 Page Deep Reinforcement Learning PPT
The 32nd article: Tencent AI Lab Reinforcement Learning Recruitment (Full-time/Intern)
The 31st article: Reinforcement Learning, Where to Go?
The 30th article: Three Examples of Reinforcement Learning
The 29th article: Framework ES-MAML: Evolutionary Strategy Meta-Learning Method
The 28th article: 138 Page “Policy Optimization” PPT–Pieter Abbeel
The 27th article: Applications and Latest Progress of Transfer Learning in Reinforcement Learning
The 26th article: In-Depth Understanding of Hindsight Experience Replay
The 25th article: 10 Items Summary of “Deep Reinforcement Learning” Competitions
The 24th article: How Many Random Seeds Are Needed in DRL Experiments?
The 23rd article: 142 Page “ICML Conference” Reinforcement Learning Notes
The 22nd article: Achieving General Quantum Control through Deep Reinforcement Learning
The 21st article: Summary of Interview Questions for “Deep Reinforcement Learning”
The 20th article: Summary of Recruitment for “Deep Reinforcement Learning” (13 Companies)
The 19th article: Solving the Sparse Feedback Problem: HER Principle and Code Implementation
The 18th article: “DeepRacer” — Top Deep Reinforcement Learning Challenge
The 17th article: AI Paper | Several Practical Tool Recommendations
The 16th article: In the AI Field: How to Conduct Excellent Research and Write High-Quality Papers?