Understanding Multi-Task Learning in AI Applications

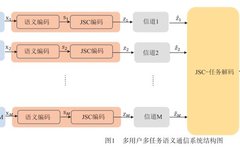
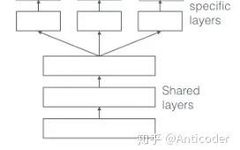
[Introduction to Large Model Industry Applications Series] NO.9 [Abstract] Single-task training often overlooks valuable information hidden in related tasks. The emergence of Multi-Task Learning (MTL) provides a new approach to this problem.Author Li Jie, focused on exploring and researching Java Virtual Machine technology and cloud-native technologies. *This article is the 9th in the [Introduction to … Read more