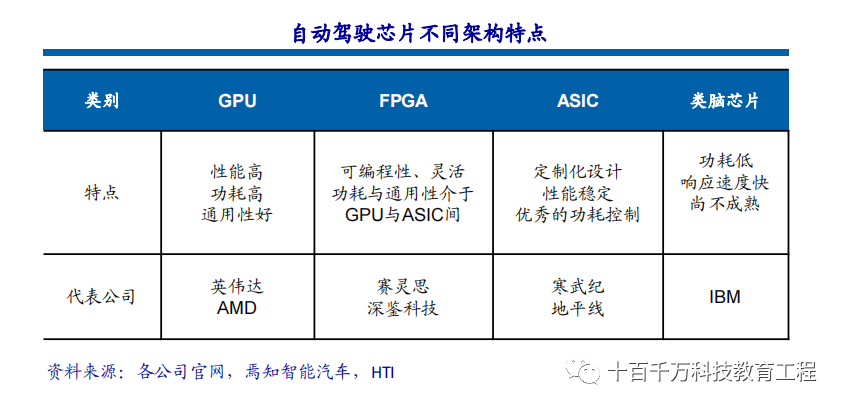
The current mainstream AI chips can be divided into three categories: GPU, FPGA, ASIC. Both GPU and FPGA are relatively mature chip architectures and belong to general-purpose chips. ASICs are chips customized for specific AI scenarios. The industry has confirmed that CPU is not suitable for AI computing, but it is still indispensable in the AI application field.
GPU Solutions
Comparison of GPU and CPU Architectures
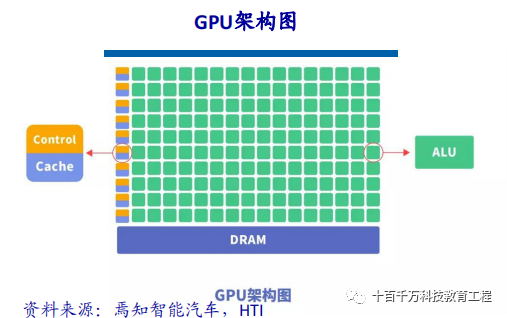
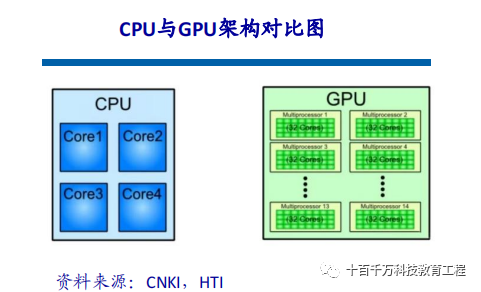
CPUs follow the von Neumann architecture, which is centered around storing programs/data and executing them sequentially. Therefore, a CPU architecture requires a lot of space to accommodate storage units (Cache) and control units (Control), while the computational units (ALU) occupy a much smaller portion. This limits the CPU’s ability to perform large-scale parallel computations, making it more adept at handling logical control. The GPU (Graphics Processing Unit) is a large-scale parallel computing architecture composed of numerous computational units, originally derived from CPUs to specifically handle image parallel computation data, designed for simultaneously processing multiple parallel computation tasks. GPUs also contain basic computational units, control units, and storage units, but their architecture is significantly different from that of CPUs, as shown in the architecture diagram below. Compared to CPUs, less than 20% of CPU chip space is ALU, while over 80% of GPU chip space is ALU. This means GPUs have more ALUs for data parallel processing.
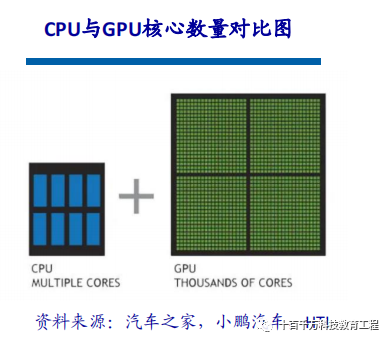
Differences Between GPU and CPU CPUs consist of several cores optimized for sequential processing, while GPUs have a large-scale parallel computing architecture composed of thousands of smaller, more efficient cores, designed for simultaneously processing multiple tasks. The significant differences between CPUs and GPUs arise from their design goals, targeting two different application scenarios. CPUs require strong versatility to handle various data types while also performing logical judgments that introduce numerous branching and interrupt handling, leading to a complex internal structure. In contrast, GPUs deal with highly uniform, independent large-scale data and a pure computing environment that does not require interruptions.
Overview of GPU Acceleration Technology
For deep learning, hardware acceleration currently relies heavily on using graphics processing units. Compared to traditional CPUs, GPUs have several orders of magnitude more core computational power and are much easier to parallelize.
The multi-core architecture of GPUs includes thousands of stream processors that can execute computations in parallel, significantly reducing model computation time. As companies like NVIDIA and AMD continue to advance their GPU large-scale parallel architecture support, general-purpose GPUs have become essential for accelerating parallel applications. Currently, GPUs have reached a relatively mature stage. Utilizing GPUs to train deep neural networks can fully leverage the efficient parallel computing capabilities of thousands of computational cores, drastically reducing time spent in scenarios with massive training data and requiring fewer servers. With appropriate optimization for suitable deep neural networks, a single GPU card can equate to the computational power of dozens or even hundreds of CPU servers, making GPUs the preferred solution in the industry for training deep learning models.
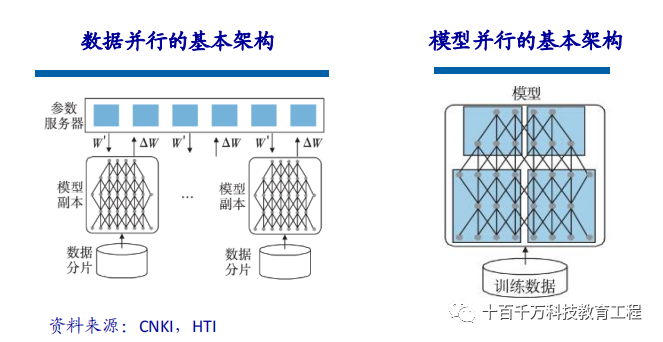
When the scale of the trained model is relatively large, model training can be accelerated using data parallelism, which involves splitting the training data and using multiple model instances to train multiple chunks of data simultaneously. In the implementation of data parallelism, since the same model is trained on different data, the bottleneck affecting model performance lies in the parameter exchange between multiple CPUs or GPUs. According to the parameter update formula, all gradients calculated by the models need to be submitted to the parameter server and updated to the corresponding parameters, so the partitioning of data shards and the bandwidth with the parameter server may become bottlenecks limiting data parallel efficiency. In addition to data parallelism, model parallelism can also be used to accelerate model training. Model parallelism refers to splitting a large model into several fragments held by multiple training units, which cooperate to complete the training of the large model.
GPU Acceleration Computing
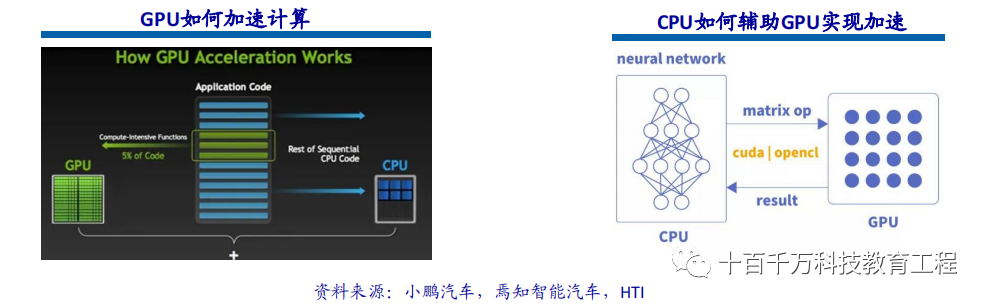
GPU acceleration computing refers to the simultaneous utilization of graphics processors (GPUs) and CPUs to speed up the execution of scientific, analytical, engineering, consumer, and enterprise applications. GPU accelerators were first introduced by NVIDIA in 2007 and now support high-efficiency data centers for government labs, universities, companies, and small to medium-sized enterprises worldwide. GPUs can accelerate applications running on platforms ranging from cars, smartphones, and tablets to drones and robots. GPU acceleration computing can provide extraordinary application performance by offloading the compute-intensive portions of application workloads to the GPU while allowing the CPU to run the remaining program code. From the user’s perspective, the speed of application execution is significantly improved. Currently, GPUs are solely performing parallel matrix multiplication and addition, while the construction of neural network models and data flow transmission still occurs on the CPU. The interaction process between CPU and GPU includes: obtaining GPU information, configuring GPU id, loading neuron parameters to GPU, GPU-accelerated neural network computation, and receiving GPU computation results.
Why GPUs Are So Important in the Field of Autonomous Driving
One of the most important technical areas in autonomous driving technology is deep learning, and AI based on deep learning architectures is now widely applied in various fields of the automotive industry, including computer vision, natural language processing, sensor fusion, target recognition, and autonomous driving. From autonomous driving startups and internet companies to major OEM manufacturers, all are actively exploring the use of GPUs to build neural networks for achieving ultimate autonomous driving. Since the birth of GPU acceleration computing, it has provided enterprises with a multi-core parallel computing architecture that supports data sources that previous CPU architectures could not handle. In comparison, to complete the same deep learning training tasks, the cost of using GPU computing clusters is only one two-hundredth of that of CPU computing clusters.
GPUs Are Key to Autonomous Driving and Deep Learning
Whether it is enabling cars to perceive their surrounding environments in real-time or quickly planning driving routes and actions, these all rely on the rapid response of the car’s brain, which poses a significant challenge to computer hardware manufacturers. During the autonomous driving process, deep learning or AI algorithms must constantly cope with infinite possible situations. The vigorous development of AI, deep learning, and autonomous driving has ushered in a golden age for GPU computing. Another important parameter of GPUs is floating-point computing capability. Floating-point counting uses different lengths of binary to represent a number with floating-point notation, in contrast to fixed-point numbers. During the iteration of autonomous driving algorithms, high precision is required, necessitating support for floating-point operations.
FPGA Solutions
Definition and Structure of FPGA Chips
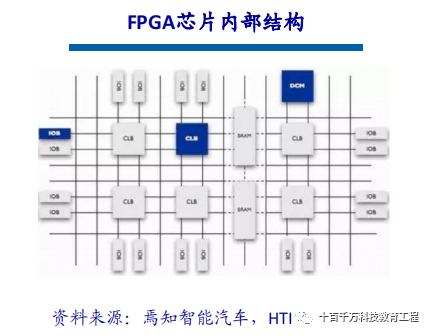
FPGA (Field-Programmable Gate Array) is a product developed on the basis of programmable devices such as PAL, GAL, and CPLD. It appears as a semi-custom circuit in the field of application-specific integrated circuits, solving the shortcomings of custom circuits and overcoming the previous limitations of programmable devices with a limited number of gate circuits. FPGA chips mainly consist of six parts: programmable input/output units, basic programmable logic units, complete clock management, embedded block RAM, rich wiring resources, embedded low-level functional units, and embedded dedicated hardware modules. Currently, mainstream FPGAs are still based on lookup table technology, which far exceeds the basic performance of earlier versions and integrates commonly used functions (such as RAM, clock management, and DSP) into hard (ASIC-type) modules.
Working Principle of FPGA
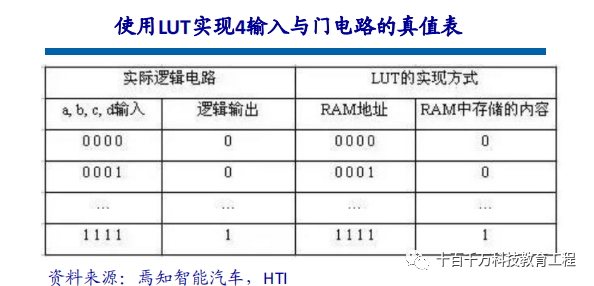
Because FPGAs need to be reprogrammed repeatedly, their basic structure for implementing combinational logic cannot be completed like ASICs using fixed NAND gates, but must adopt a structure that is easy to reconfigure. Lookup tables can meet this requirement well. Currently, mainstream FPGAs use lookup table structures based on SRAM technology, while some military and aerospace-grade FPGAs use lookup table structures based on Flash or fuse and antifuse technology. The method of changing the content of the lookup table by writing files is used to achieve reconfiguration of the FPGA. A lookup table (LUT) is essentially a RAM. Most FPGAs currently use 4-input LUTs, so each LUT can be seen as RAM with 4 address lines. After the user describes a logic circuit using schematics or HDL language, the PLD/FPGA development software automatically calculates all possible results of the logic circuit and writes the truth table (i.e., results) into RAM in advance. Thus, each time a signal is input for logical operations, it is equivalent to inputting an address to look up the table, find the content corresponding to the address, and output it.
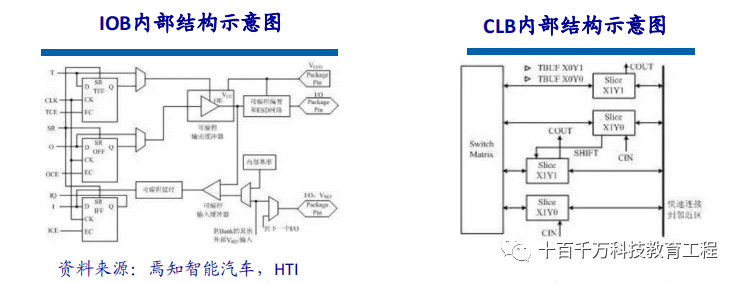
The programmable input/output unit, referred to as the I/O unit, is the interface part between the chip and external circuits, fulfilling the driving and matching requirements for input/output signals under different electrical characteristics. The I/Os inside the FPGA are classified into groups, with each group able to independently support different I/O standards. Through flexible software configuration, it can adapt to different electrical standards and I/O physical characteristics, adjusting the size of the driving current and changing pull-up and pull-down resistors. Currently, the frequency of I/O ports is also increasing, with some high-end FPGAs supporting data rates of up to 2Gbps through DDR registers. CLB is the basic logic unit within the FPGA. The actual number and characteristics of CLBs vary depending on the device, but each CLB contains a configurable switch matrix, which consists of 4 or 6 inputs, some selection circuits (such as multiplexers), and flip-flops. The switch matrix is highly flexible and can be configured to handle combinational logic, shift registers, or RAM. In Xilinx FPGA devices, CLBs are composed of multiple (generally 4 or 2) identical slices and additional logic.
The “Killer” Chip for Autonomous Driving
The autonomous driving and advanced driver-assistance systems (ADAS) market is undergoing a transformation, presenting new complex demands for computing and sensor functions. FPGAs possess unique advantages that other chip solutions cannot match, making them an excellent choice to meet the evolving needs of the autonomous driving industry. FPGAs are a special technology in the chip field that can be repeatedly configured through software tools while also having rich I/O interfaces and computational units. Therefore, FPGAs can simultaneously handle pipeline parallelism and data parallelism according to the specific needs of application scenarios, naturally possessing advantages such as high computational performance, low latency, and low power consumption. FPGAs offer multiple benefits, such as high throughput, high energy efficiency, and real-time processing, which are very much in line with the technical demands of autonomous driving. The standards and requirements for advanced driver assistance systems (ADAS) and in-vehicle experience (IVE) applications are rapidly evolving, and system designers are primarily concerned with excellent flexibility and faster development cycles while maintaining higher performance-to-power ratios. By combining reprogrammable FPGAs with an increasing number of automotive-grade products, they support automotive designers in meeting design requirements and staying ahead in the ever-changing automotive industry.
A More Adaptable Platform The true value of autonomous driving chips lies in the utilization of the computing engine, that is, the difference between theoretical performance and actual performance. FPGAs contain numerous routing links and a large number of small storage units. The combination of these resources allows designers to create customized data feed networks for their computing engines, achieving higher levels of utilization. Programmable logic provides customers with high flexibility to adapt to the changing demands of emerging application areas such as ADAS and autonomous driving. Improved interface standards, algorithm innovations, and new sensor technologies all require adaptable platforms that can support not only software changes but also hardware changes, which is precisely the advantage of FPGA chips. FPGA chips are scalable. Scalable chips change the number of programmable logics, mostly using pin-compatible packages. This means that developers can create a single ECU platform to host low, medium, and high versions of the ADAS feature package and scale costs by selecting the minimum density chip needed.
Differentiated Solutions FPGA chips allow developers to create unique differentiated processing solutions that can be optimized for specific applications or sensors. This is unattainable with ASSP chips, even those providing dedicated accelerators, whose usage is limited and generally available to all competitors. For example, Xilinx’s long-term customers have created high-value IP libraries accessible only to them, and these functionalities can be utilized across the company’s various products. Starting from the 90nm node, Xilinx chips have already proven to be cost-effective for mass automotive applications, with over 160 million Xilinx chips applied in the industry.
ASIC Solutions
Definition and Characteristics of ASICs ASIC chips can be categorized based on terminal functions into TPU chips, DPU chips, and NPU chips. Among them, TPUs are tensor processing units specifically designed for machine learning. For example, Google developed a programmable AI accelerator for the Tensorflow platform in May 2016, whose internal instruction set can operate during changes or updates to Tensorflow programs. DPUs, or Data Processing Units, provide engines for computing scenarios such as data centers. NPUs are neural processing units that simulate human neurons and synapses at the circuit level and directly process large-scale electronic neuron and synapse data using deep learning instruction sets. ASICs can be designed in both fully custom and semi-custom ways. Fully custom designs rely on significant manpower and time costs to complete the entire integrated circuit design process autonomously. While more flexible and better performing than semi-custom ASICs, their development efficiency is significantly lower.
Significant Performance Improvement ASIC chips are very suitable for artificial intelligence application scenarios. For example, NVIDIA’s first chip designed from the ground up for deep learning, the Tesla P100, has a data processing speed 12 times that of its GPU series launched in 2014. Google’s custom chip for machine learning, TPU, has elevated hardware performance to a level equivalent to that of current chips seven years after Moore’s Law development. Just as CPUs transformed the massive computers of their day, AI ASIC chips will significantly change the landscape of today’s AI hardware devices. For instance, the infamous AlphaGo used about 170 GPUs and 1200 CPUs, requiring a dedicated server room with high-power air conditioning and multiple experts for system maintenance. If all were to use dedicated chips, it would likely only need a space the size of a regular storage box, and power consumption would significantly decrease. The ASIC technology route is limited and open, requiring chip companies to develop based on mainstream networks, models, and operators related to driving. With the same performance, chips have smaller areas, lower costs, and lower power consumption. The future potential of the ASIC technology route is substantial, and choosing the ASIC route does not mean developing different ASICs for different vehicle models or conducting different validations. This is because the functions required by different vehicle models are generally the same, and the chips are limitedly open to models and operators, ensuring that rapid algorithm iterations do not affect the chip’s support for upper-layer functions. Collaborating with chip design companies for differentiated customization may be a better choice. Even in differentiated customization, 50% of the chip’s internal components are still common. Chip design companies can perform differentiated designs based on existing versions to achieve partial differentiated functions.
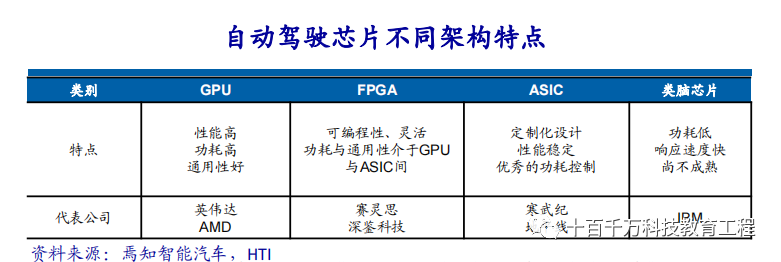
Comparison of Mainstream Architecture Solutions: Three Mainstream Architectures
FPGA is a product developed on the basis of programmable devices such as PAL and GAL. It appears as a semi-custom circuit in the field of application-specific integrated circuits, solving the shortcomings of custom circuits and overcoming the previous limitations of programmable devices with a limited number of gate circuits. Advantages: can be programmed infinitely, low latency, supports both pipeline parallelism and data parallelism, real-time performance is the strongest, and flexibility is the highest. Disadvantages: high development difficulty, only suitable for fixed-point operations, relatively expensive. Graphics Processing Units (GPUs), also known as display cores, visual processors, and display chips, are microprocessors specifically designed to perform image and graphics-related calculations on personal computers, workstations, game consoles, and some mobile devices (such as tablets and smartphones). Advantages: provides a foundational structure for multi-core parallel computing, with an extremely high number of cores that can support massive data parallel computations and has higher floating-point computation capabilities. Disadvantages: management control capability (weakest), power consumption (highest). ASIC, or application-specific integrated circuit, refers to integrated circuits designed and manufactured according to specific user requirements and the needs of specific electronic systems. Currently, using CPLD (Complex Programmable Logic Devices) and FPGA (Field Programmable Gate Arrays) for ASIC design is one of the most popular methods. Advantages: as a product closely integrating integrated circuit technology with specific user machinery or system technology, it has advantages such as smaller size, lighter weight, lower power consumption, improved reliability, enhanced performance, increased confidentiality, and reduced costs compared to general-purpose integrated circuits. Disadvantages: insufficient flexibility, more expensive than FPGAs.
With the rise of ADAS and autonomous driving technologies, as well as the gradual deepening of software-defined vehicles, the demand for computing power and massive data processing capabilities in smart cars has surged. The traditional chip “stacking” solution can no longer meet the computational power requirements of autonomous driving. Chips ultimately serve the vehicle’s onboard computing platform, and in the context of “software-defined vehicles”, addressing the computational platform support issues for intelligent driving systems cannot be achieved solely through chip power stacking. Chips are the stage for software, and the standard for evaluating the quality of chips is whether the software above can maximize its functions. When comparing two chips with the same computational power, the one that allows software to run more efficiently is the “better chip”. The main factors determining the true value of computational power are memory (SRAM and DRAM) bandwidth, actual operating frequency (i.e., supply voltage or temperature), and the algorithm’s batch size. The TOPS of a single chip is a key indicator but not the only one. Autonomous driving is a complex system that requires collaboration among vehicles, roads, clouds, and edges. Therefore, its competition involves not only chips but also software-hardware collaboration, platforms, and toolchains, etc. The unlimited expansion of chip computational power and hardware embedding will not be a trend in the future; hardware also needs to match reality. High power consumption is accompanied by low utilization rates.
Introduction to Event Cameras
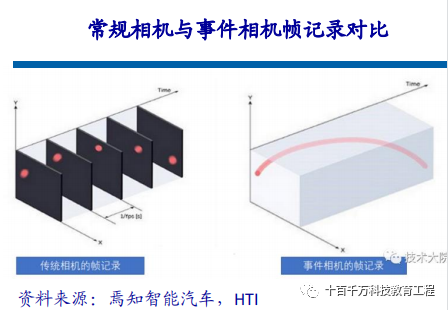
Overview and Working Mechanism The inspiration for event cameras comes from the vision of human eyes and animals, sometimes referred to as silicon retinas. Biological vision is sensitive only to areas with changes; event cameras capture the occurrence or change of events. In traditional visual domains, the information returned by cameras is synchronous, meaning that at a certain moment t, the camera will expose and fill all pixels in a matrix to return a photo. All pixels on a photo correspond to the same moment. As for video, it is merely a series of images, with time intervals between adjacent images varying widely; this is known as frame rate or time latency. Event cameras, similar to the human brain and eyes, skip irrelevant backgrounds and directly perceive the core of a scene, creating pure events rather than data.
The working mechanism of event cameras is that when the brightness of a pixel at a certain location changes and reaches a certain threshold, the camera will return an event in the aforementioned format, where the first two items are the pixel coordinates of the event, the third item is the timestamp of the event, and the last item takes a value of polarity (0 or 1, or -1 and 1), representing whether the brightness changes from low to high or from high to low. Thus, as long as there is a pixel value change within the entire camera’s field of view, an event will be returned. All these events occur asynchronously (even the smallest time intervals cannot be completely simultaneous), so the timestamps of the events are all different. Due to the simplicity of the return process, event cameras have lower latency characteristics compared to traditional cameras, capable of capturing pixel changes over very short time intervals, with delays in the microsecond range.
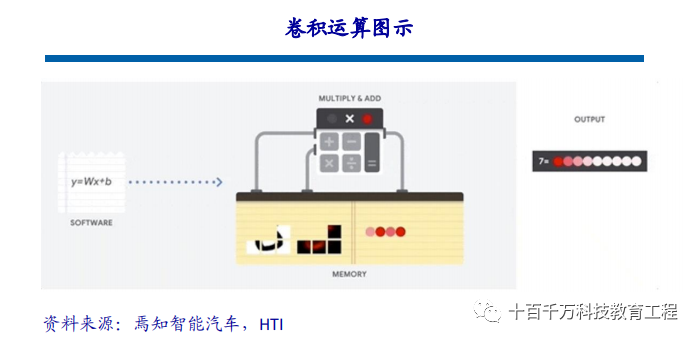
Applications in Autonomous Driving The visual recognition algorithms currently used in the autonomous driving field are fundamentally based on convolutional neural networks. The essence of visual algorithm computation is a series of convolution operations. This computation is not complex, essentially involving addition, subtraction, multiplication, and division, which is a type of multiplication and accumulation operation. However, this simple computation is abundant in convolutional neural networks, placing high demands on the performance of processors. Taking ResNet-152 as an example, which is a 152-layer convolutional neural network, the computational load required to process an image of size 224*224 is approximately 22.6 billion times. If this network processes a 1080P camera at 30 frames per second, the required computational power reaches a staggering 33 trillion times per second.
Saving Computational Power by Reducing Ineffective Calculations In the field of autonomous driving, 99% of visual data is useless background in AI processing. For example, when detecting a ghost probe, the area of change is very small, but traditional visual processing still has to deal with 99% of the unchanged background area, wasting a lot of computational power and time. Alternatively, like finding a diamond in gravel, AI chips and traditional cameras need to identify every grain of sand to find the diamond, but humans can detect the diamond with just a glance. The time taken by AI chips and traditional cameras is 100 or even 1000 times that of humans. In addition to the advantages of reduced redundant information and almost no latency, event cameras also excel in capturing fast-moving objects. Traditional cameras may blur due to a certain exposure time, while event cameras almost do not experience this issue. Furthermore, event cameras have a true high dynamic range; due to their characteristics, traditional cameras become “blind” in environments with strong or weak light, yet pixel changes still exist, allowing event cameras to see what is in front of them.
