
This article is approximately 3200 words long and is recommended for an 8-minute read. This article will outline the key points related to the large language model (LLM) Agent and discuss the important directions for AI Agents in the era of large models.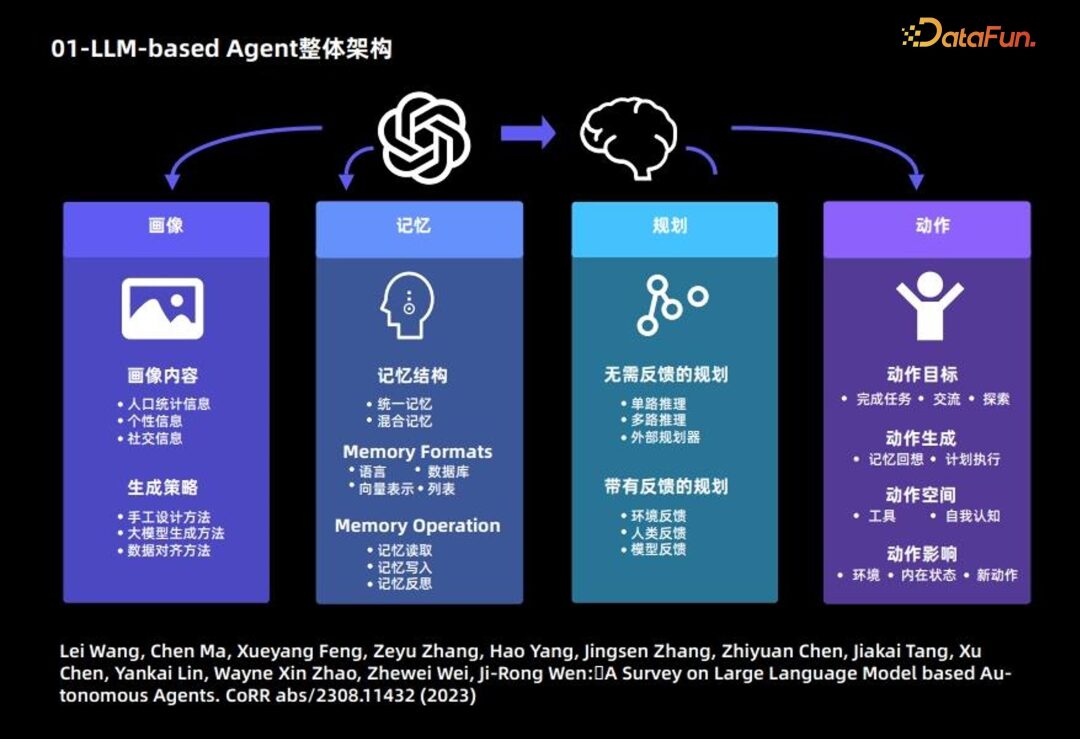
-
Manual design method: Write the content of the user profile into the large model’s prompt in a specified manner; suitable for a smaller number of Agents; -
Large model generation method: First specify a small number of profiles as examples, then use the large language model to generate more profiles; suitable for a large number of Agents; -
Data alignment method: Use the background information of individuals in a pre-specified dataset as prompts for the large language model to make corresponding predictions.
-
Unified memory: Only considers short-term memory, ignoring long-term memory; -
Hybrid memory: Combines long-term and short-term memory
-
Language -
Database -
Vector representation -
List
-
Memory reading -
Memory writing -
Memory reflection
-
Feedback-free planning: The large language model does not require external environmental feedback during reasoning. This type of planning is further subdivided into three types: single-path reasoning, which uses the large language model once to fully output reasoning steps; multi-path reasoning, which leverages crowdsourcing ideas to generate multiple reasoning paths and determine the best path; and external planner borrowing. -
Feedback-based planning: This planning method requires external environmental feedback, and the large language model needs to base its next steps and subsequent planning on the feedback from the environment. Feedback for this type of planning comes from three sources: environmental feedback, human feedback, and model feedback.
-
Action goals: Some Agents aim to complete a specific task, some aim to communicate, and some aim to explore. -
Action generation: Some Agents generate actions based on memory recall, while others execute specific actions according to the original plan. -
Action space: Some action spaces are collections of tools, while others consider the entire action space from the perspective of the large language model’s own knowledge and self-awareness. -
Action impact: Includes impact on the environment, impact on internal states, and impact on future new actions.
-
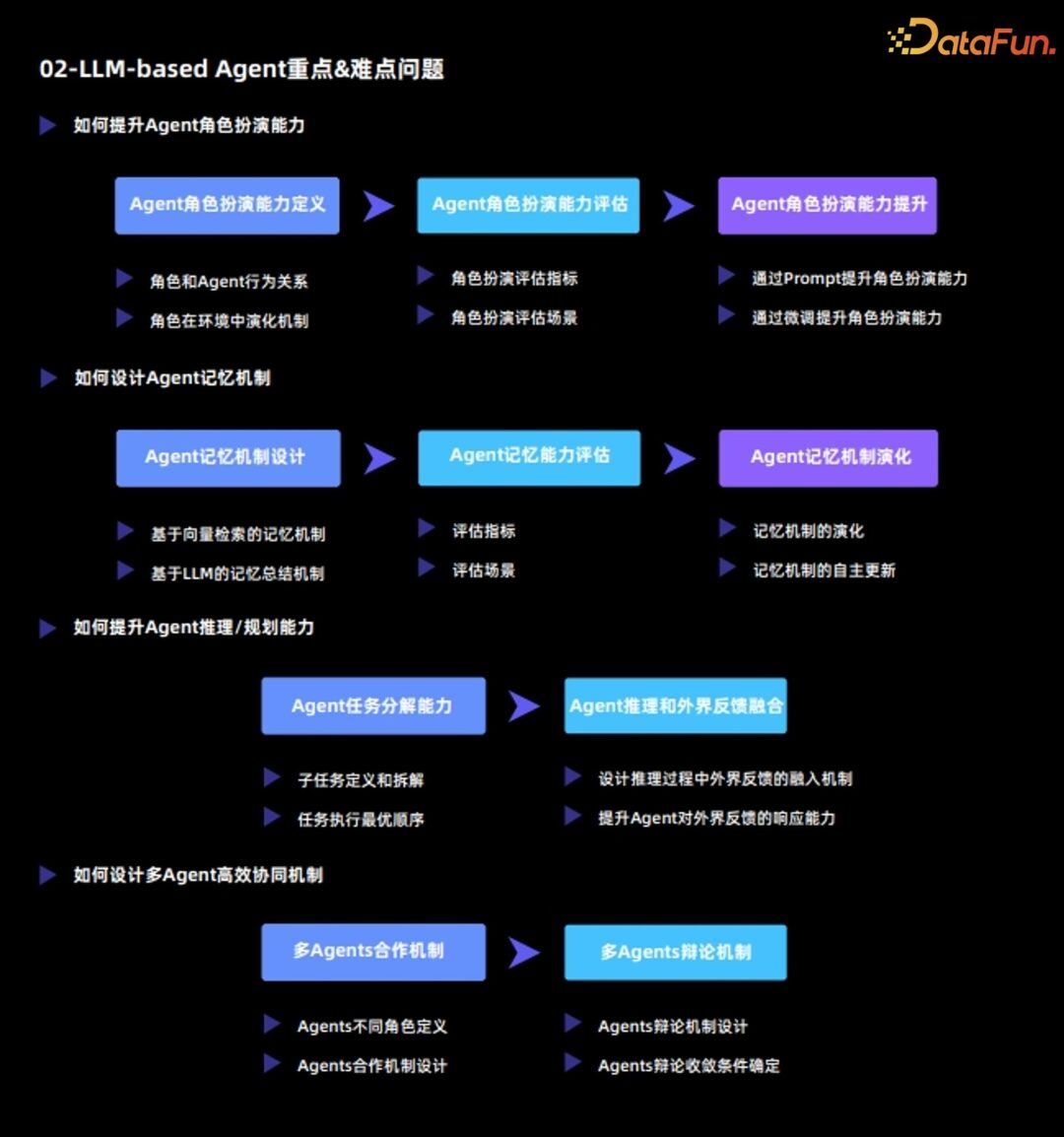
Relationship between role and Agent behavior -
Mechanism of role evolution in the environment
-
Role-playing evaluation metrics -
Role-playing evaluation scenarios
-
Enhancing role-playing ability through prompts: This method essentially stimulates the existing capabilities of the large language model by designing prompts; -
Enhancing role-playing ability through fine-tuning: This method usually fine-tunes the large language model based on external data to enhance its role-playing ability.
-
Memory mechanism based on vector retrieval -
Memory mechanism based on LLM summarization
-
Evaluation metrics -
Evaluation scenarios
-
Evolution of memory mechanisms -
Autonomous updates of memory mechanisms
-
Definition and breakdown of sub-tasks -
Optimal sequence for task execution
-
Design mechanisms for integrating external feedback during reasoning: forming an interactive whole between the Agent and the environment; -
Enhancing the Agent’s responsiveness to external feedback: on one hand, the Agent needs to genuinely respond to the external environment, and on the other hand, it needs to be able to ask questions about the external environment and seek solutions.
-
Definition of different roles among Agents -
Design of cooperation mechanisms among Agents
-
Design of debate mechanisms among Agents -
Determination of convergence conditions for Agent debates
-
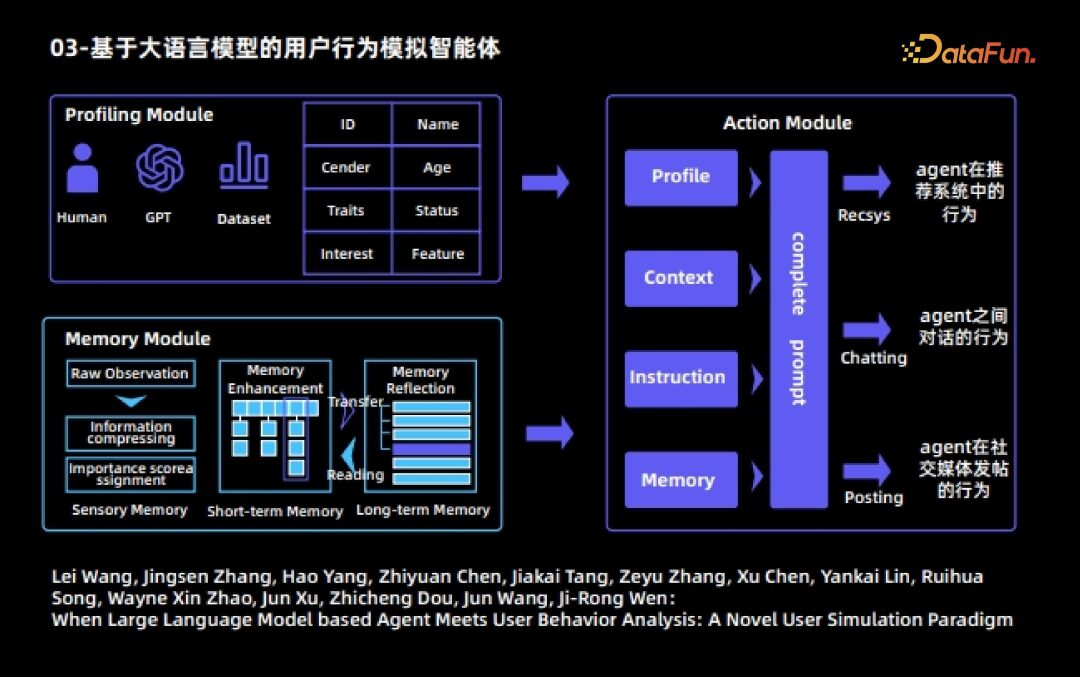
Processes the objectively observed raw observations to generate more informative observations, which are stored in short-term memory; -
Short-term memory content has a relatively short storage time
-
Content from short-term memory that is repeatedly triggered and activated will automatically transfer to long-term memory -
Long-term memory content has a relatively long storage time -
Long-term memory content will autonomously reflect and refine based on existing memories.
-
Agent behavior in recommendation systems, including watching movies, searching for the next page, and leaving the recommendation system; -
Dialogue behavior among Agents; -
Agent behavior in posting on social media.

-
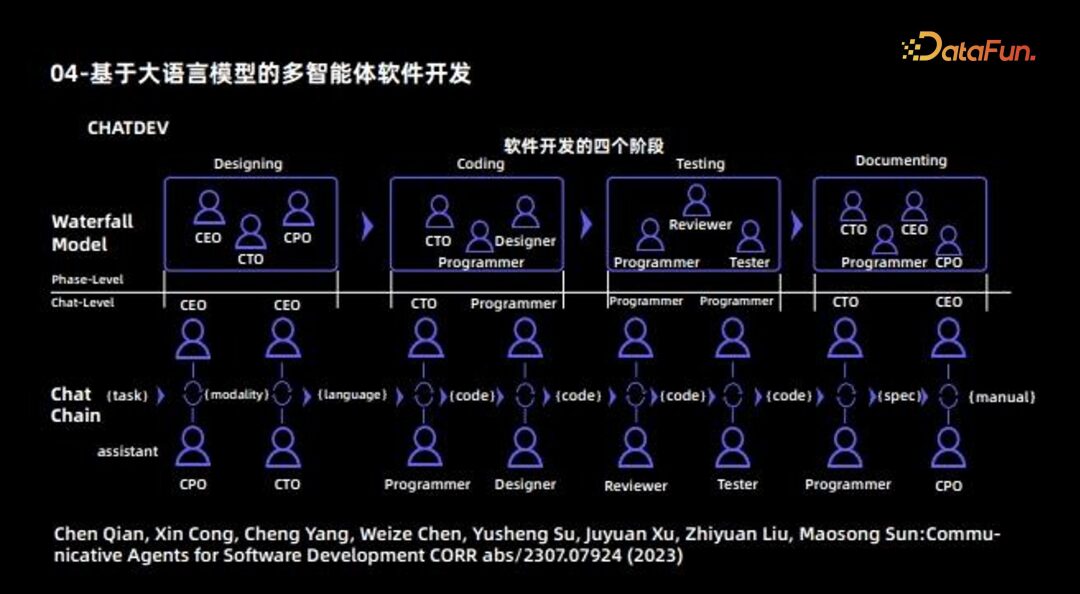
Solving specific tasks, such as MetaGPT, ChatDev, Ghost, DESP, etc. This type of Agent should ultimately be a “superhuman” aligned with correct human values, with two “qualifiers”: Alignment with correct human values; Capabilities that surpass ordinary humans. -
Simulating the real world, such as Generative Agent, Social Simulation, RecAgent, etc. The capabilities required for this type of Agent are entirely opposite to the first type. Allowing Agents to present diverse values; Hoping that Agents align more closely with ordinary people rather than surpassing them.
-
Illusion problem Due to the need for Agents to constantly interact with the environment, the illusion at each step will accumulate, leading to a cumulative effect that exacerbates the problem; thus, the illusion problem of large models needs further attention here. Solutions include: Designing efficient human-machine collaboration frameworks; Designing efficient human intervention mechanisms. -
Efficiency issue During the simulation process, efficiency is a very important issue; the following table summarizes the time taken by different Agents under different numbers of APIs.
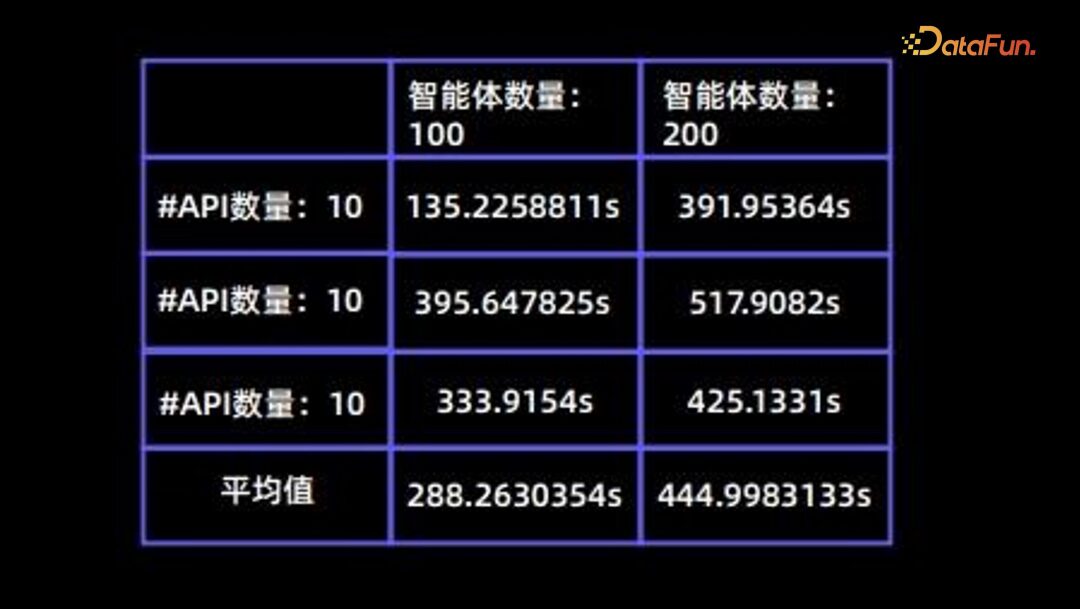
Editor: Wang Jing
