In-Depth Analysis of Linux NUMA Systems: From Principles to Practice
1 Overview of NUMA Systems
1.1 What is NUMA?
Non-Uniform Memory Access (NUMA) is a memory architecture designed for multiprocessor systems. In traditional Symmetric Multiprocessing (SMP) systems, all processors share a single centralized memory controller, and all memory accesses have the same latency, a structure known as Uniform Memory Access (UMA). However, as the number of processors increases, the memory controller and system bus become performance bottlenecks, limiting the scalability of the system.
NUMA architecture addresses this scalability issue by dividing processors and memory into multiple nodes. In a NUMA system, each node contains one or more processors and locally installed memory, with nodes connected via high-speed interconnects (such as crossbar switches or point-to-point links). The speed at which processors access local node memory is significantly faster than accessing memory from remote nodes, resulting in the “non-uniform” memory access characteristic.
From the perspective of Linux, the NUMA platforms of interest are primarily the so-called Cache-Coherent NUMA (ccNUMA) systems. In ccNUMA systems, all memory is visible and can be accessed from any CPU connected to any unit, with cache coherence handled in hardware by processor caches and/or system interconnects.
1.2 Metaphor for NUMA Hardware Architecture
To better understand the NUMA architecture, we can use a vivid metaphor: comparing a NUMA system to a large library system:
- • Single Library (UMA System): All readers (processors) must access the same central library (memory), regardless of where the readers are located. As the number of readers increases, the roads to the library become congested, increasing access latency.
- • Library Network (NUMA System): Each city area (node) has its own library (local memory), and readers (processors) first access the local library. If the required book is not in the local library, it can be obtained from other libraries through inter-library loan services (interconnect), but this takes additional time.
In this metaphor, local access corresponds to readers accessing the library in their area, which is fast; while remote access corresponds to borrowing books from other libraries through inter-library loans, which is slow and increases the burden on the system. An excellent library management system (NUMA optimization) will try to ensure that readers find books in their local library as much as possible, reducing the frequency of inter-library loans.
1.3 Linux Software Abstraction for NUMA
The Linux kernel divides the system’s hardware resources into multiple software abstractions called “nodes“, which map to the physical units of the hardware platform while abstracting some architectural details. Like physical units, software nodes may contain zero or more CPUs, memory, and/or IO buses.
For each memory node, Linux builds an independent memory management subsystem, which has its own free page list, used page list, usage statistics, and locks to mediate access. This design allows the kernel to manage memory resources more finely, optimizing local access and reducing remote access.
Linux supports the simulation of NUMA nodes, allowing a NUMA environment to be simulated even on non-NUMA hardware. For NUMA simulation, Linux will partition existing nodes or the system memory of non-NUMA platforms into multiple nodes. This is very useful for testing NUMA kernel and application functionalities and can also be used as a memory resource management mechanism.
2 Linux NUMA Core Architecture
2.1 Node Management and Data Structures
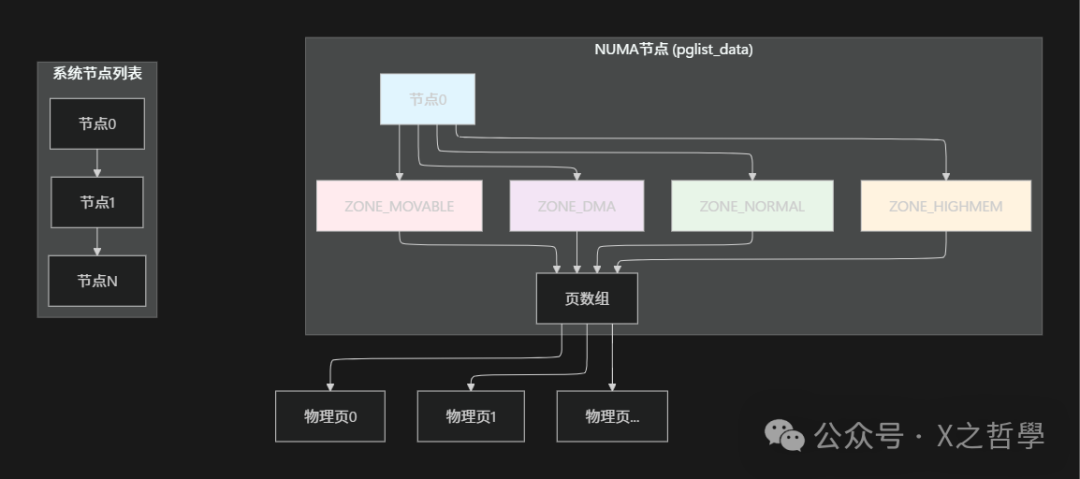
In the Linux kernel, each NUMA node is represented by a <span>pglist_data</span> structure (defined as <span>pg_data_t</span> via <span>typedef</span>). This structure is central to NUMA memory management and contains all relevant information for managing the node’s memory. The same structure is used even in UMA architectures, referred to as <span>contig_page_data</span>.
Below is a key definition of the <span>pglist_data</span> structure (a simplified version based on the kernel source code):
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES]; // Array of memory zones in the node
struct zonelist node_zonelists[MAX_ZONELISTS]; // List of zones used for allocation
int nr_zones; // Number of zones in the node
struct page *node_mem_map; // Array of page descriptors in the node
unsigned long node_start_pfn; // Starting page frame number of the node
unsigned long node_present_pages; // Total number of physical pages in the node
unsigned long node_spanned_pages; // Total number of pages spanned by the node (including holes)
int node_id; // Node ID
struct pglist_data *pgdat_next; // Next node
wait_queue_head_t kswapd_wait; // kswapd wait queue
struct task_struct *kswapd; // Memory reclaim thread
int kswapd_order; // kswapd reclaim order
enum zone_type kswapd_highest_zoneidx; // Highest zone index reclaimed by kswapd
} pg_data_t;Each node is divided into multiple zones, which represent memory ranges with specific characteristics. The main zone types defined in Linux include:
- • ZONE_DMA: Memory area suitable for DMA operations, used by peripherals that cannot access all addressable memory.
- • ZONE_DMA32: Similar to ZONE_DMA, but suitable for devices that can only access 32-bit address space.
- • ZONE_NORMAL: Normal memory area, accessible by the kernel at any time.
- • ZONE_HIGHMEM: High memory, referring to those parts of physical memory that are not permanently mapped in the kernel page table (needed only on 32-bit architectures).
- • ZONE_MOVABLE: Movable memory area, where contents can be moved between different physical pages, used for memory hotplugging and fragmentation control.
- • ZONE_DEVICE: Memory for persistent memory (PMEM) and devices like GPUs.
The following diagram illustrates the relationship between nodes, zones, and pages:
2.2 Memory Zones and Zonelist
When the kernel needs to allocate memory, it must determine from which zone to allocate. To efficiently manage memory access across different zones, Linux establishes a zonelist for each node, which specifies the zones/nodes to access when the selected zone/node cannot satisfy the allocation request.
The sorting strategy of the zonelist is an important design decision. By default, Linux uses a Node-ordered zonelist, meaning that before using remote nodes sorted by NUMA distance, the kernel will attempt to fall back to other zones in the same node. This strategy balances local allocation needs with the scarcity of special zones (like DMA).
Below is a simplified representation of the zonelist construction process:
// Simplified zonelist construction process
struct zonelist *build_zonelists(pg_data_t *pgdat) {
struct zonelist *zonelist;
int local_node = pgdat->node_id;
// First, try to allocate from the local node
for (enum zone_type zone = ZONE_NORMAL; zone >= ZONE_DMA; zone--) {
struct zone *z = &pgdat->node_zones[zone];
if (zone_managed(z)) {
zonelist->_zonerefs[zonelist->_nr_zonerefs++] = {
.zone = z,
.zone_idx = zone
};
}
}
// Then try remote nodes in order of distance
for (int distance = 1; distance < MAX_DISTANCE; distance++) {
for (each node at this distance) {
for (enum zone_type zone = ZONE_NORMAL; zone >= ZONE_DMA; zone--) {
// Add remote zones to zonelist
}
}
}
}2.3 Page Allocation Mechanism
Page allocation in Linux NUMA systems follows the principle of local allocation priority. By default, Linux attempts to satisfy memory allocation requests from the node where the requesting CPU is allocated. Specifically, the kernel will try to allocate from the first node in the appropriate zone list of the requesting source node.
This local allocation strategy helps maintain the “localization” of subsequent accesses to the allocated memory, reducing performance losses from remote access. However, the effectiveness of this optimization depends on whether the task continues to run on the initial node. If the task migrates between nodes, it may move away from its initial node and kernel data structures.
When local node memory is insufficient, the kernel will look for other nodes in the order defined by the zonelist. This process is transparent to applications but may lead to performance degradation. The core process of page allocation is as follows:
- 1. Local Node Allocation: Attempt to allocate memory from the appropriate zone of the current CPU’s node.
- 2. Fallback Mechanism: If the local node cannot satisfy the request, try other nodes in the order of the zonelist.
- 3. Reclaim Mechanism: If all nodes are out of memory, trigger the memory reclaim mechanism (kswapd) to attempt to free memory.
- 4. OOM Handling: If reclaim still cannot satisfy the demand, trigger the Out-of-Memory killer to terminate processes to free memory.
3 NUMA Scheduling Mechanism
3.1 Scheduling Domains and Scheduling Groups
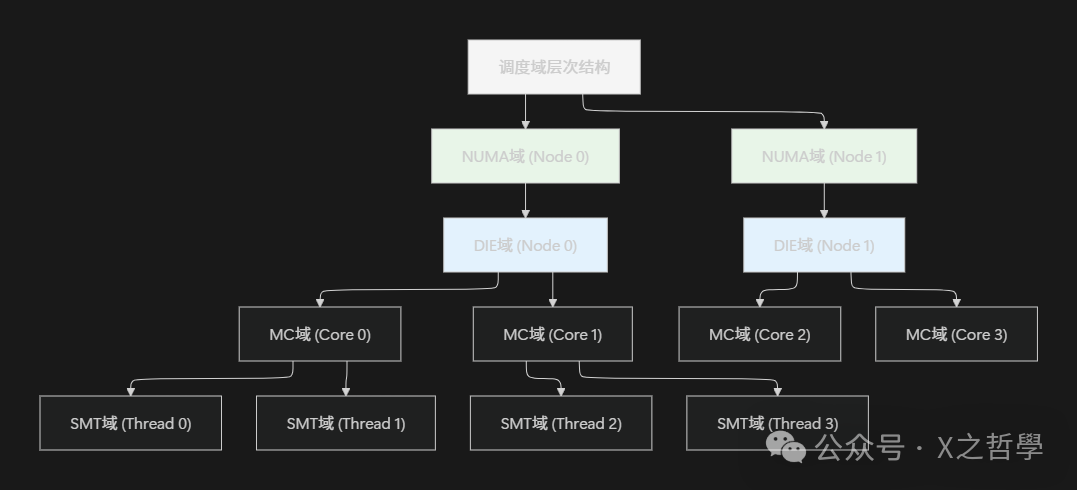
The Linux scheduler understands the NUMA topology of the system through the concepts of scheduling domains (sched_domain) and scheduling groups (sched_group). Scheduling domains form a hierarchy, from the physical CPU core level to the NUMA node level, and then to higher-level domains (such as multi-socket systems).
Each scheduling domain contains one or more scheduling groups, which represent the processor resources available for load balancing within that domain. For NUMA systems, NUMA domains are particularly important, as they represent all CPUs within a single NUMA node.
Below is a simplified representation of the key data structures of scheduling domains:
struct sched_domain {
struct sched_domain *parent; // Parent domain
struct sched_domain *child; // Child domain
struct sched_group *groups; // Scheduling groups in this domain
unsigned long span[]; // CPU bitmap covered by this domain
int flags; // Domain attribute flags
// ... other fields
};
struct sched_group {
struct sched_group *next; // Next group in the list
unsigned long span[]; // CPU bitmap covered by this group
int group_weight; // Group weight
// ... other fields
};The following diagram illustrates a typical scheduling domain hierarchy in a NUMA system:
3.2 NUMA Load Balancing
The Linux scheduler ensures a reasonable distribution of tasks across the system through a load balancing mechanism. For NUMA systems, load balancing strategies are particularly important, as improper task migration can lead to a significant amount of remote memory access.
The main features of NUMA load balancing include:
- • Hierarchical Balancing: Load balancing occurs at various levels of the scheduling domain hierarchy, from SMT domains to NUMA domains.
- • NUMA Affinity: The scheduler tries to keep tasks on their initial NUMA node to maintain memory access locality.
- • Periodic Balancing: The system periodically checks CPU load conditions and migrates tasks when imbalances are detected.
For NUMA domains, the load balancing strategy is more conservative, as cross-node task migration is costly. The scheduler weighs the pros and cons of computational load balancing and memory access locality, prioritizing the latter.
The core algorithm process for NUMA load balancing is as follows:
// Simplified NUMA balancing algorithm
void numa_balancing(void) {
for_each_node(node) {
// Check for imbalance between nodes
if (check_imbalance(node)) {
// Find migratable tasks
struct task_struct *task = find_migrable_task(node);
if (task) {
// Calculate migration cost
int cost = calculate_migration_cost(task, node);
if (cost < THRESHOLD) {
// Perform task migration
migrate_task(task, node);
}
}
}
}
}3.3 NUMA-Aware Scheduling
The modern Linux kernel implements NUMA-aware scheduling, optimizing task execution in NUMA systems through multiple mechanisms:
- 1. Automatic NUMA Balancing: Kernel threads
<span>kswapd</span>and specific NUMA balancing threads periodically scan task address spaces to detect whether pages are correctly placed or if data should be migrated to the local memory node where the task is running. - 2. Page Placement Policy: When a task first accesses a page, the kernel allocates it in the local memory of the current running node.
- 3. Page Migration: If the scheduler detects that a task frequently accesses pages from remote nodes, it may decide to migrate the pages to the node where the task is currently running or migrate the task to the node where the pages reside.
- 4. Load Hints: The kernel collects memory access patterns of tasks to guide scheduling and migration decisions.
Automatic NUMA balancing can be tuned through files in the <span>/sys/kernel/debug/sched/numa_balancing</span> directory:
- •
<span>scan_period_min_ms</span>: Minimum time (in milliseconds) to scan the task’s virtual memory. - •
<span>scan_delay_ms</span>: Initial scan delay when a task is created. - •
<span>scan_period_max_ms</span>: Maximum time (in milliseconds) to scan the task’s virtual memory. - •
<span>scan_size_mb</span>: Number of MB to scan in a single scan.
4 NUMA Memory Allocation Strategies
4.1 Memory Policy Interface
Linux provides a memory policy mechanism that allows user-space applications and kernel components to control the node location of memory allocations. Memory policies are key optimization tools in NUMA systems, defining the rules the kernel should follow when allocating memory.
The main types of memory policies include:
- • MPOL_DEFAULT: Default policy, using local allocation.
- • MPOL_BIND: Restricts memory allocation to a specific set of nodes.
- • MPOL_PREFERRED: Prefers to allocate from a specified node but allows fallback to other nodes.
- • MPOL_INTERLEAVE: Interleaves memory pages across multiple nodes.
- • MPOL_LOCAL (Linux 4.17+): Prefers to allocate from the local node, similar to the default policy but stricter.
User-space applications can manage memory policies using system calls like <span>mbind()</span>, <span>set_mempolicy()</span>, and <span>move_pages()</span>. Additionally, the <span>libnuma</span> library provides a more convenient interface for managing NUMA policies.
4.2 Binding Policies and CPUsets
Binding policies allow processes or memory regions to be restricted to specific NUMA nodes for execution and memory allocation. This is particularly useful for performance-sensitive applications, ensuring memory access locality.
Linux provides a CPUsets mechanism that allows system administrators to partition the system into multiple independent CPU and memory node partitions. Each cpuset can contain specific CPUs and memory nodes, and tasks can be restricted to run within a specific cpuset.
Below is an example of using cpuset:
# Create cpuset
mkdir /dev/cpuset/application-set
echo 0-3 > /dev/cpuset/application-set/cpus
echo 0 > /dev/cpuset/application-set/mems
echo 1234 > /dev/cpuset/application-set/tasksCPUsets combined with NUMA memory policies can provide fine-grained resource control, which is particularly useful in virtualization and containerization environments.
4.3 Interleaved Allocation Policy
Interleaved allocation policy allocates memory pages in a round-robin fashion across multiple nodes, similar to RAID 0 striping techniques. This policy is suitable for streaming workloads or applications with random access patterns that cannot benefit from data locality.
Interleaved allocation can balance memory loads across multiple nodes, preventing a single node from becoming a bottleneck. Below is an example code for using the interleaved policy:
#include <numa.h>
#include <numaif.h>
void enable_interleave(void) {
struct bitmask *bm = numa_allocate_nodemask();
numa_bitmask_setbit(bm, 0); // Node 0
numa_bitmask_setbit(bm, 1); // Node 1
numa_set_membind(bm); // Set interleaved policy
numa_free_nodemask(bm);
}4.4 Preferred Node Policy
Preferred node policy indicates that the kernel should prefer to allocate memory from a specified node, but allows fallback to other nodes if that node runs out of memory. This policy provides a balance between flexibility and locality.
Preferred node policy is suitable for applications that perform best on specific nodes but can tolerate occasional remote memory access.
5 NUMA Performance Optimization and Debugging
5.1 Performance Monitoring Tools
Effective performance monitoring is the foundation of NUMA optimization. Linux provides a range of tools to monitor the performance of NUMA systems:
- 1. numastat: Displays statistics on NUMA memory allocation, including the number of local and remote allocations for each node.
$ numastat
node0 node1
numa_hit 12345678 12345678
numa_miss 1234 1234
numa_foreign 1234 1234
interleave_hit 5678 5678
local_node 12345678 12345678
other_node 1234 1234- 2. numactl: Used to view NUMA topology and control the NUMA policy of processes.
# View system NUMA topology
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3
node 0 size: 16384 MB
node 0 free: 8192 MB
node 1 cpus: 4 5 6 7
node 1 size: 16384 MB
node 1 free: 8192 MB
node distances:
node 0 1
0: 10 20
1: 20 10- 3. lstopo: Generates a graphical topology of the system.
- 4. perf: Performance analysis tool that can detect NUMA-related performance events, such as remote memory access.
# Monitor remote memory access
$ perf stat -e node-loads,node-load-misses <command>5.2 NUMA Debugging Techniques
The Linux kernel provides various mechanisms for debugging NUMA issues:
- 1. /proc filesystem: View the NUMA memory distribution of processes through
<span>/proc/*/numa_maps</span>.
$ cat /proc/self/numa_maps
00400000 default file=/bin/cat mapped=6 N0=6
7f33b26c2000 default file=/bin/cat mapped=27 N0=27
...- 2. debugfs interface: Control automatic NUMA balancing parameters through
<span>/sys/kernel/debug/sched/numa_balancing</span>. - 3. Tracing Points: Use ftrace to trace NUMA-related events.
# Enable NUMA balancing tracing
$ echo 1 > /sys/kernel/debug/tracing/events/sched/sched_move_numa/enable
$ cat /sys/kernel/debug/tracing/trace_pipe5.3 Performance Optimization Best Practices
Depending on the characteristics of the application and the workload of the system, different NUMA optimization strategies can be adopted:
The following table summarizes the optimization strategies for different workload types:
| Workload Type | Characteristics | Recommended Strategy | Tools/Techniques |
|---|---|---|---|
| CPU Intensive | High computation density, low memory access | Local allocation, CPU binding | numactl –membind, taskset |
| Memory Intensive | High memory bandwidth demand | Memory interleaving, large pages | numactl –interleave, hugepages |
| Data Locality Sensitive | Stable working set, predictable access patterns | Bind to a single node | numactl –cpunodebind |
| Mixed Workload | Diverse access patterns | Hierarchical strategy, dynamic balancing | auto-NUMA balancing, MPOL_PREFERRED |
When optimizing in practice, the following steps should be followed:
- 1. Performance Analysis: Use monitoring tools to identify current performance bottlenecks and the proportion of remote access.
- 2. Strategy Selection: Choose the appropriate memory policy based on application characteristics.
- 3. Testing and Validation: Test the effectiveness of the strategy under simulated loads.
- 4. Production Deployment: Deploy the optimization strategy in the production environment and continue monitoring.
6 Conclusion
Linux’s support for NUMA systems is a complex and mature subsystem that enables applications to fully leverage the performance potential of NUMA architectures through multi-layered abstractions and optimization strategies. From node management to memory allocation, from scheduling strategies to load balancing, the Linux NUMA implementation reflects the adaptability of modern operating systems in complex hardware environments.
Key implementation points include:
- 1. Hierarchical Abstraction: Managing physical memory through a three-level structure of nodes, zones, and pages.
- 2. Locality Priority: Default local allocation strategy and scheduling domain-aware load balancing.
- 3. Policy Flexibility: A rich memory policy interface to meet different application needs.
- 4. Automatic Optimization: Automatic NUMA balancing mechanisms adapt to dynamic workloads.
For developers and system administrators, understanding how Linux NUMA works is crucial for optimizing high-performance applications. By effectively utilizing NUMA strategies and monitoring tools, significant performance improvements can be achieved for memory-intensive workloads on multiprocessor systems.
As computing architectures evolve, the importance of NUMA optimization will continue to grow. New hardware platforms such as ARM64 and RISC-V provide good support for NUMA, and the Linux NUMA subsystem will continue to evolve to meet the demands of future computing.