This article is reprinted from the public account: AI Algorithm Chips and Systems. This article is for academic/technical sharing only. If there is any infringement, please contact us to delete the article.
01 Abstract
This article provides an in-depth analysis of the neural processing unit (NPU) integrated into Intel’s Meteor Lake mobile processor. The NPU, codenamed “NPU 3720,” is based on Movidius technology acquired by Intel and is designed to handle machine learning workloads with higher energy efficiency. The article discusses its high-level architecture, neural compute engine design, memory subsystem, link bandwidth, and real-world application performance (such as Stable Diffusion). The analysis indicates that the NPU has energy efficiency advantages in specific scenarios, but it has limitations in performance, software ecosystem support, and the variety of data types, especially when compared to integrated GPUs and discrete GPUs.
02 Overview
AI is a hot topic currently, and to avoid falling behind, Intel has integrated a neural processing unit (NPU) into its Meteor Lake mobile processor. This NPU is referred to internally at Intel as “NPU 3720,” although this name does not appear in public market materials. This analysis is based on the Intel Core Ultra 7 155H processor installed in the ASUS Zenbook 14. The NPU 3720 features a large number of execution units and operates at a relatively low clock frequency of 1.16 GHz, aiming to process machine learning workloads with better energy efficiency than other hardware.
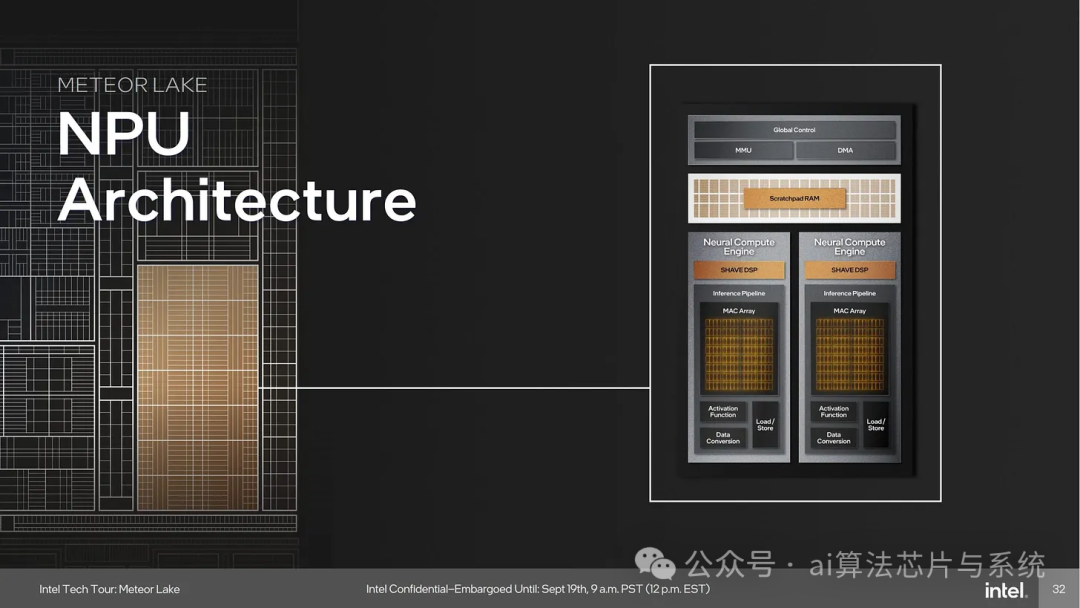
This article is relatively short because a deep exploration of the NPU requires extensive testing, writing, validation, and research work. For a non-profit project conducted in spare time, the workload for a deep analysis of the NPU is too large.
03 High-Level Architecture
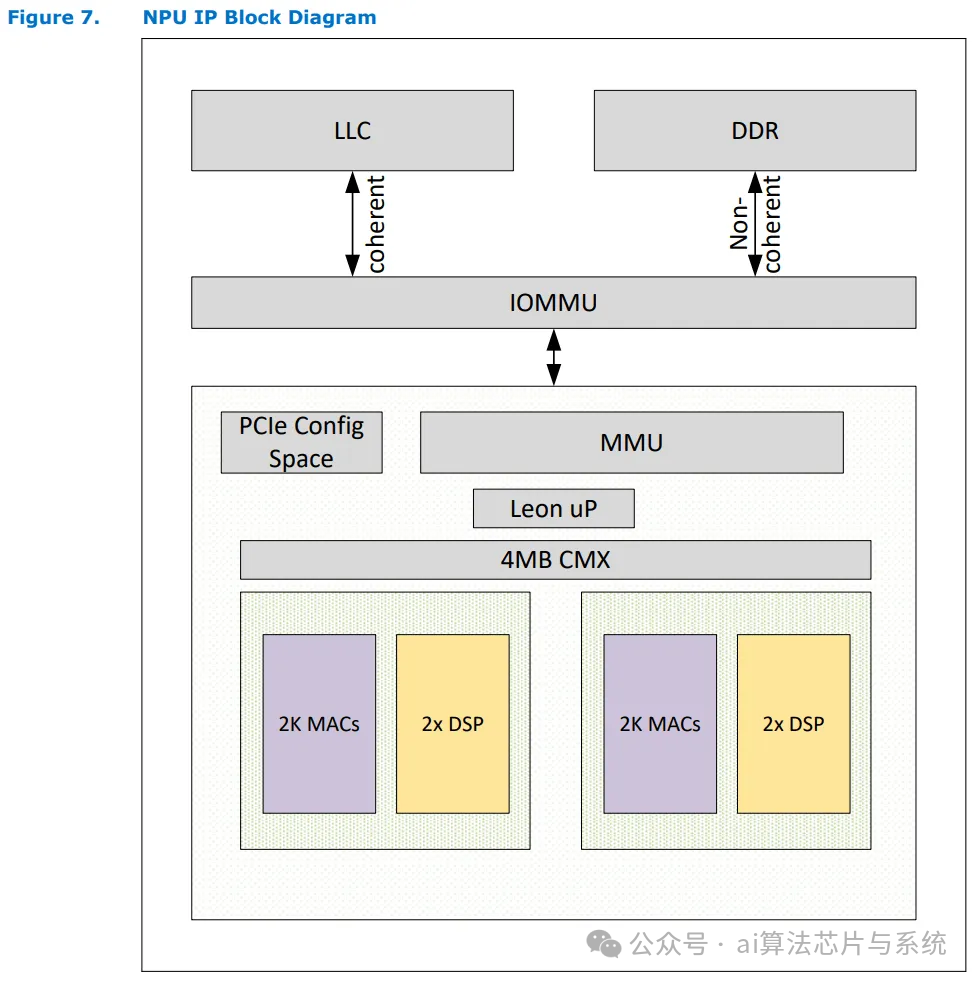
Intel’s NPU design is derived from Movidius’s solution, which initially took the form of a programmable digital signal processor (DSP). After acquiring Movidius in 2016, Intel expanded the existing platform to include a large-scale multiply-accumulate (MAC) array. AI workloads involve a significant amount of matrix multiplication, and MAC units are well-suited for such computations. The MAC array of the NPU 3720 is distributed across two Neural Compute Engine (NCE) tiles, capable of executing 4096 INT8 multiply-accumulate operations per cycle, achieving a peak performance of 9.5 TOPS at the lower frequency of 1.16 GHz.
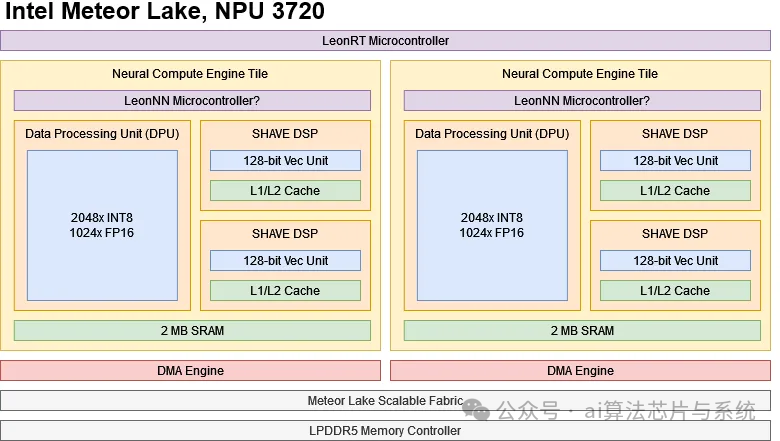
Similar to GPUs, the NPU connects to the system as a PCIe device, with commands issued by the host. Intel did not design a dedicated command processor but instead retained Movidius’s 32-bit LEON microcontroller. The LEON uses the SPARC instruction set and runs a real-time operating system. One core, named “LeonRT,” is responsible for NPU initialization and host command parsing; the other core, “LeonNN,” dispatches tasks to the NCE computational resources, acting as a low-level hardware scheduler. Both LEON cores have independent caches. The NPU also integrates Movidius’s SHAVE (Streaming Hybrid Architecture Vector Engine) DSP, which is deployed in parallel with the MAC array to handle machine learning steps that cannot be mapped to the MAC array.
The core of the accelerator design is to tightly couple the hardware to specific tasks, a principle that is also reflected in the NPU’s memory hierarchy. Each NCE is equipped with 2 MB of software-managed SRAM; since it is not a cache, the NPU does not need to store tags or state arrays to track data locations. Access requests can read data directly from the SRAM storage, eliminating the need for tag matching and virtual address translation steps. However, the lack of a caching mechanism places a greater burden on the compiler and software, which must explicitly move data into the SRAM.
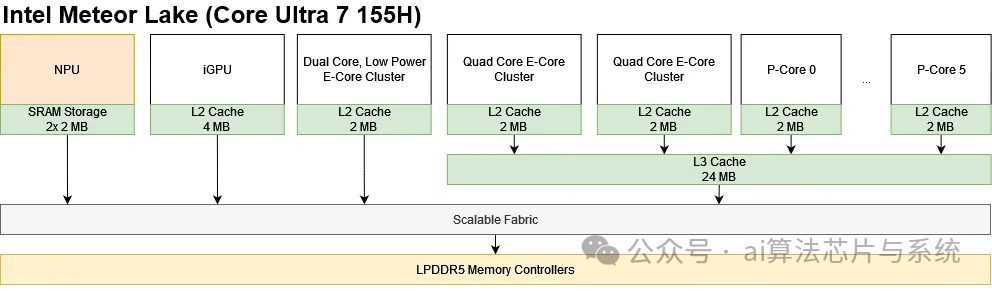
At the system level, the NPU is integrated alongside the integrated GPU and CPU cores through Meteor Lake’s Scalable Fabric and shares the LPDDR5 memory subsystem with other modules. The operating system driver accesses the NPU as a PCIe device, with an access mechanism consistent with other peripherals like the integrated GPU.
04 Neural Compute Engine Architecture
The MAC array of a single NCE tile is further divided into 512 MAC Processing Engines (MPE), each capable of executing 4 INT8 multiply-accumulate operations per cycle; the throughput for FP16 MAC is half that of INT8.
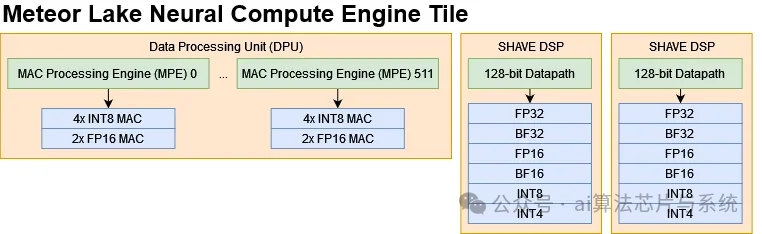
Details on the SHAVE DSP core could not be obtained, but tests conducted on the OpenCLOn12 platform indicate that its FP32 throughput is slightly above 50 GFLOPS. Since the DPU does not support FP32, this result should come from the SHAVE core. The SHAVE architecture announced by Movidius in 2011 features a single 128-bit vector data path, with a theoretical value of 37 GFLOPS at 1.16 GHz; Intel may have subsequently iterated on SHAVE to enhance vector throughput. Nevertheless, the SHAVE core does not undertake the primary computational tasks at the DPU level but is used to support extended data types like FP32, transcendental functions, and data type conversions. However, compared to CPUs or GPUs, its data type support remains limited, with complete lack of FP64 support, which can be a significant obstacle in certain scenarios.
LevelZeroCompilerInDriver: Compilation of the network failed. Error code: 2013265924. Unable to find FP64 for the time step.Intel OpenVINO, error encountered while attempting to compile the UNET model of Stable Diffusion for the NPU.
Running the MatMul test using the Intel NPU acceleration library, I measured an FP16 throughput of 1.35 TFLOPS, while the theoretical peak is 4.7 TFLOPS, indicating a significant gap. Small matrix sizes suffer from efficiency losses due to task startup overhead; the CPU vector unit has nearly zero startup latency, and data is often already resident in the cache, giving it an advantage in small matrix scenarios. As the matrix size increases, NPU utilization improves, but it is still limited by memory bandwidth; at this point, Meteor Lake’s integrated GPU can compete strongly with the NPU even at FP32 precision.
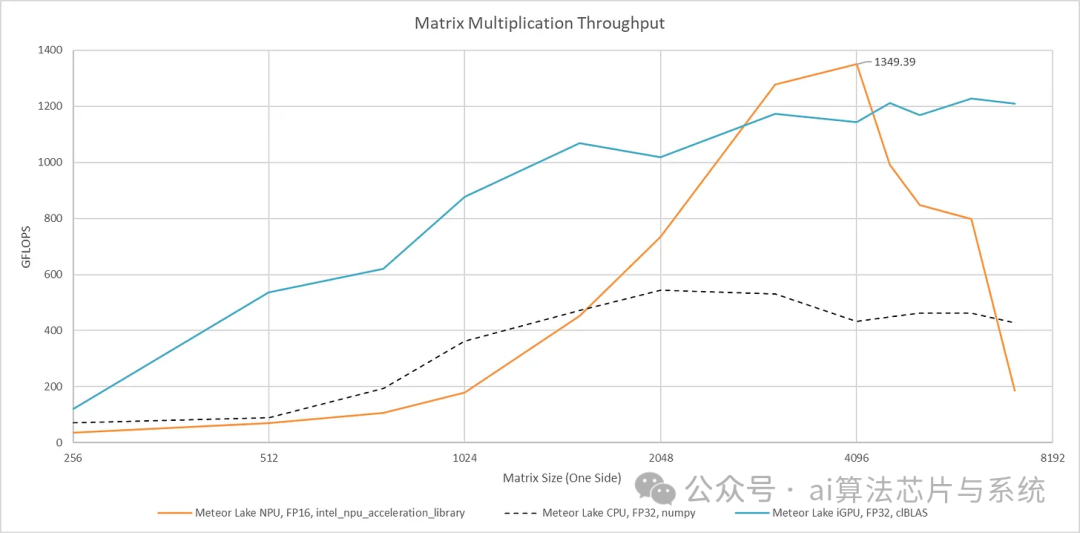
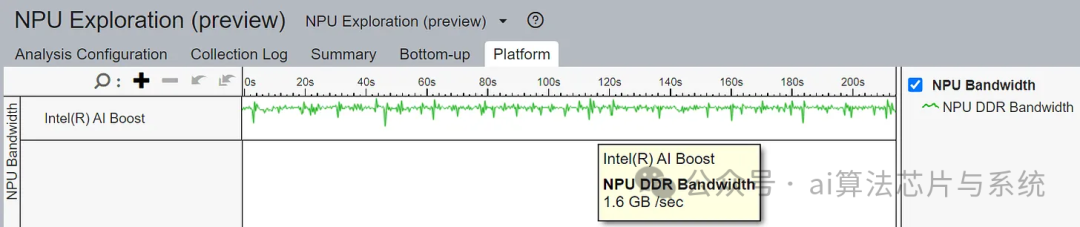
At a matrix size of 7168×7168, performance drops sharply. VTune shows that the NPU’s memory bandwidth is very low, but no other metrics are available. It is possible that the NPU is optimized for smaller models, and when memory usage becomes too large, TLB misses occur. Alternatively, when data overflows the SRAM, the NPU may be limited by DMA latency.
GPUs have a large number of fused multiply-accumulate units, as graphics rendering also involves matrix multiplication. With a larger power budget, fast caches, and high memory bandwidth, even older discrete GPUs like NVIDIA’s GTX 1080 outperform the NPU significantly.
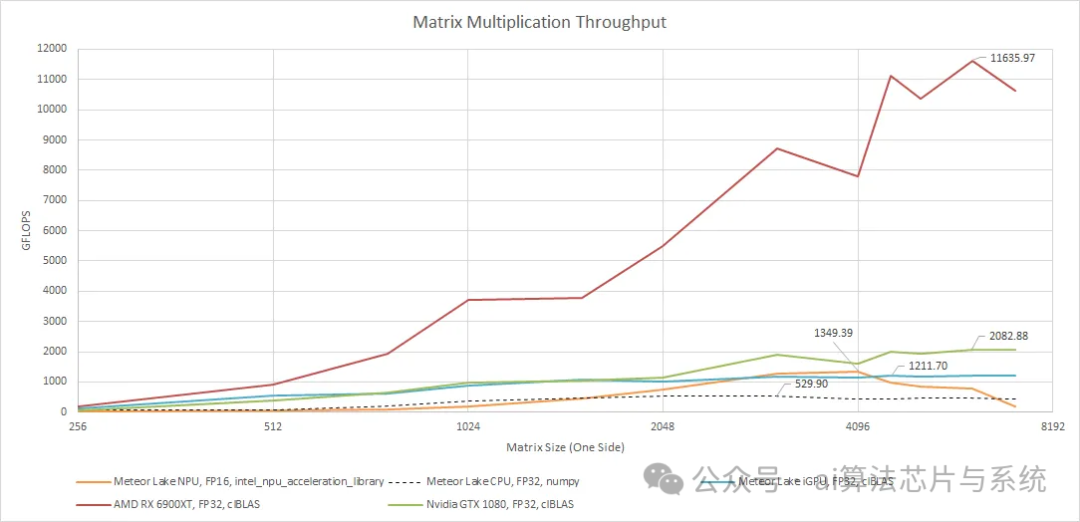
Newer GPUs, such as AMD’s RX 6900XT, exhibit completely different performance levels. GPU performance scales well with shrinking process nodes and increased power budgets, so even without tensor cores, the RX 6900 XT can provide substantial matrix multiplication throughput.
05 Memory Subsystem
The NPU can access a storage space of 128 KB with relatively low latency. The latency is 16.02 ns, slightly lower than the RDNA 2 scalar cache (17.8 ns), and falls between the L1 cache latencies of NVIDIA’s Ampere and Ada Lovelace. It is unclear how the NPU completed this latency test, but it is speculated that its code runs on the SHAVE DSP.
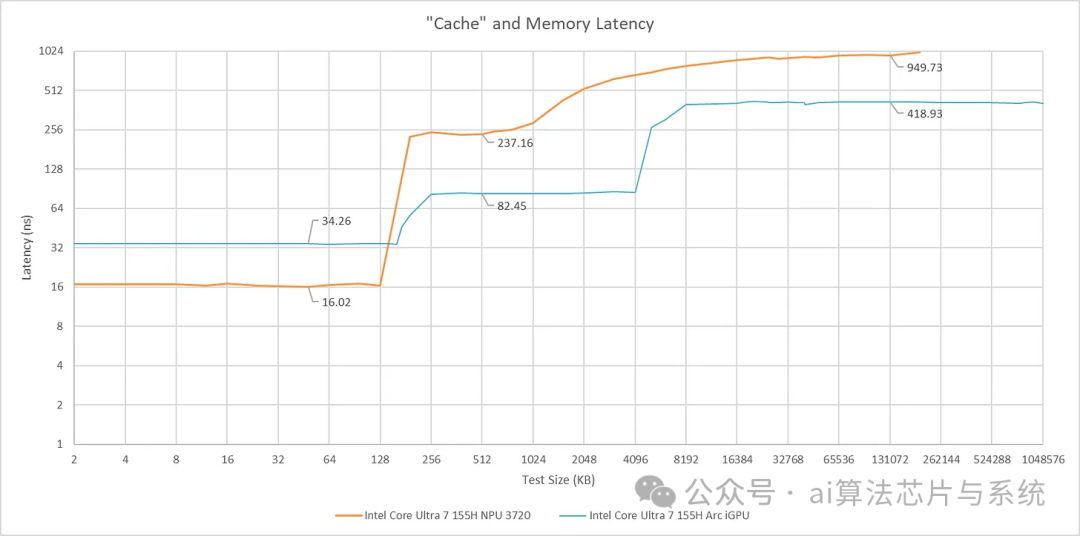
Although the latency test suggests the presence of a cache, its behavior is entirely different from conventional caches. Changing the stride of pointer chasing did not affect the results until the stride exceeded 128 KB. If described in cache terms, it is equivalent to having only one 128 KB cache line. Furthermore, it is both direct-mapped and fully associative.
The more likely scenario is that we are not facing a traditional cache, but rather a 128 KB high-speed storage configured next to the load/store unit. When an access miss occurs, the software is responsible for one-time moving 128 KB of data to fill it. The 237 ns latency measured at 512 KB is likely due to the NPU loading a 128 KB block from the NCE’s scratchpad at a speed exceeding 500 GB/s; in contrast, DRAM latency is close to 1 µs, making it appear extremely slow. Intel’s data manual indicates that requests undergo address translation via the MMU before leaving the device.
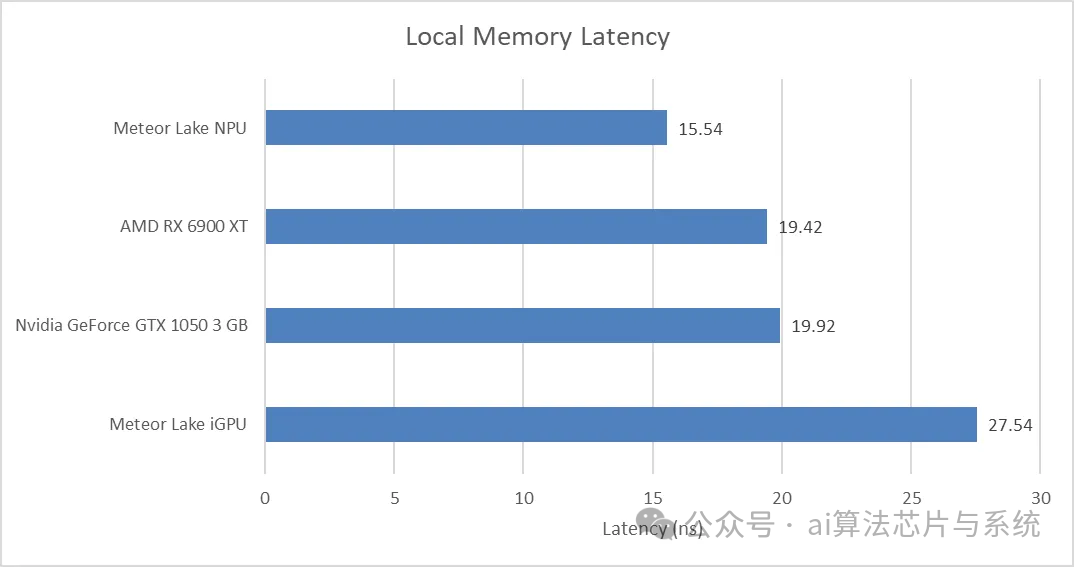
OpenCL’s local memory corresponds better with the NPU’s scratchpad memory, as both are non-coherent, directly-addressable storage spaces. The NPU again demonstrates excellent latency characteristics; while the CPU’s latency is certainly lower, the NPU is now on par with the latest generation of GPUs.
06 Link Bandwidth
Similar to the integrated GPU, the NPU should be able to access the CPU’s memory space quickly. Data copying between the NPU memory does not require going through the PCIe bus. However, when using OpenCL’s <span><span>clEnqueueWriteBuffer</span></span> and <span><span>clEnqueueReadBuffer</span></span> commands to transfer data, the NPU’s performance is far inferior to that of the integrated GPU.
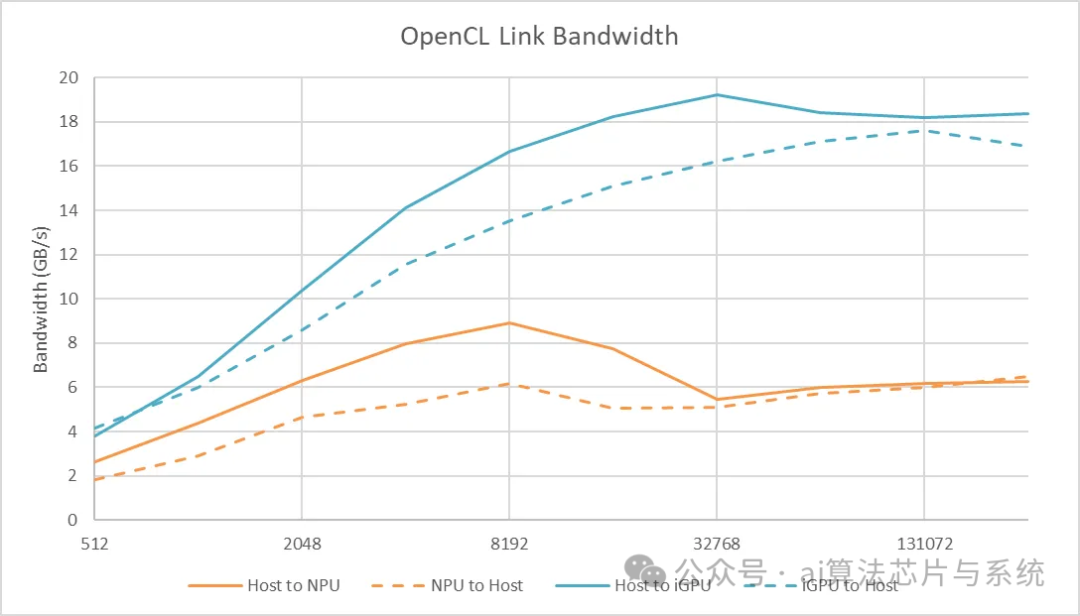
The integrated GPU of Meteor Lake can exceed 19 GB/s when moving data from the CPU memory space to the GPU memory space. The NPU, however, cannot break through 10 GB/s. This is either due to its connection to the Meteor Lake Scalable Fabric being narrow or its DMA engine capabilities being weak.
07 Performance Testing of Stable Diffusion v1.5
Stable Diffusion generates images from text prompts: starting from random noise, it iterates through denoising steps using UNET to arrive at the final image. When the number of UNET steps is high, it takes significant time even on high-end hardware, making it a typical target for hardware acceleration.
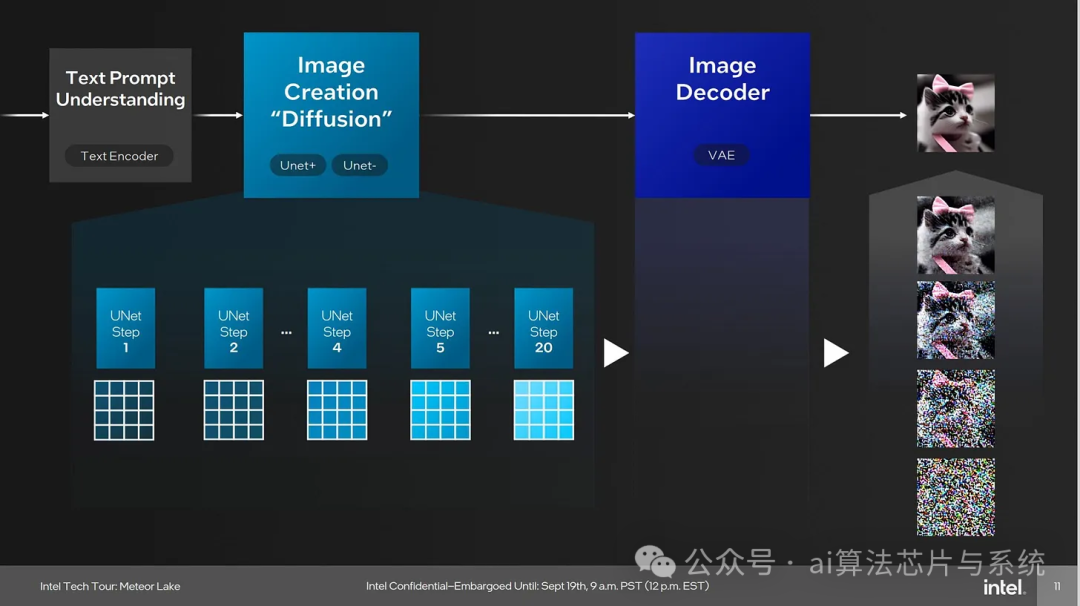
Getting Stable Diffusion to run on the NPU is not easy. I first attempted to modify the OpenVINO Stable Diffusion pipeline to adapt it for NPU compilation:
- • UNET compilation failed due to FP64 operations.
- • The VAE decoder reported an error due to lack of support for a certain operator:
Cannot create ScaledDotProductAttention layer __module.vae.decoder.mid_block.attentions.0/aten::scaled_dot_product_attention/ScaledDotProductAttention id:111 from unsupported opset: opset13Intel OpenVINO, error encountered while attempting to compile the VAE decoder for the NPU.
Subsequently, I attempted to modify the ONNX version of the Stable Diffusion pipeline, calling the NPU via DirectML. However, the NPU is a special case, and the process remains cumbersome. Typically, applications need to first create a DirectX12 device based on a DXGI (DirectX Graphics Infrastructure) device, and then use DirectML; however, the NPU does not have graphics rendering or display output capabilities, so it is not a DXGI device. Posts on StackOverflow regarding setting the ONNX <span><span>device_id</span></span> did not resolve the issue.Thus, I turned to studying the ONNX source code[1] and found that it is necessary to configure the <span><span>device filter</span></span> instead of the <span><span>device_id</span></span>. However, the target code segment had been conditionally compiled (<span><span>#ifdef</span></span><code><span><span>) excluded. After spending several hours trying to recompile ONNX from the source and enabling the relevant macro definitions, I ultimately gave up.</span></span>

Eventually, I found the OpenVINO GIMP plugin released by Intel, which has implemented Stable Diffusion functionality. It loads a pre-compiled opaque blob rather than compiling the public model on the fly. It can be inferred that Intel internally generated this blob to bypass the NPU’s limitations regarding unsupported operators and FP64; at the same time, the model was converted to INT8 to run at full speed on the NPU (the original Stable Diffusion defaults to FP32). Since users cannot generate blobs themselves, they cannot use newer models like Stable Diffusion 2.0 and can only run version 1.5 on the NPU to generate 512×512 images.
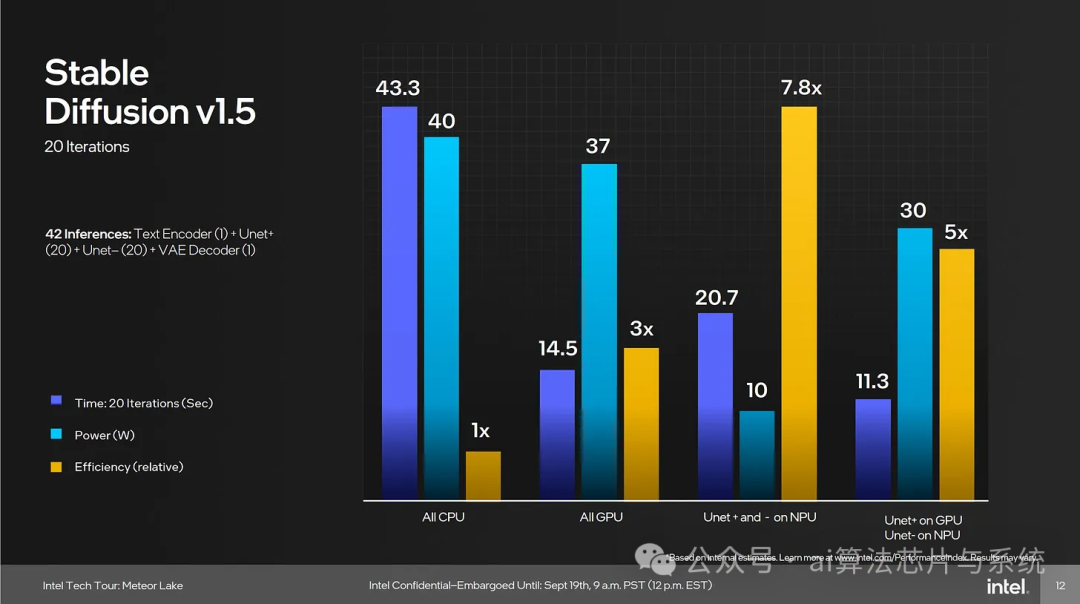
The UNET inference of Stable Diffusion can be split into two steps: UNET+ and UNET-, with the latter used for negative prompts. The GIMP plugin provided by Intel defaults to executing UNET+ on the NPU, while UNET- is handled by the integrated GPU. I modified the plugin code to test both the “full NPU” and “full integrated GPU” paths. For comparison, I also ran the unmodified Stable Diffusion 1.5 model using Olive+DirectML on the Meteor Lake integrated GPU and a discrete GPU to assess overall performance differences.
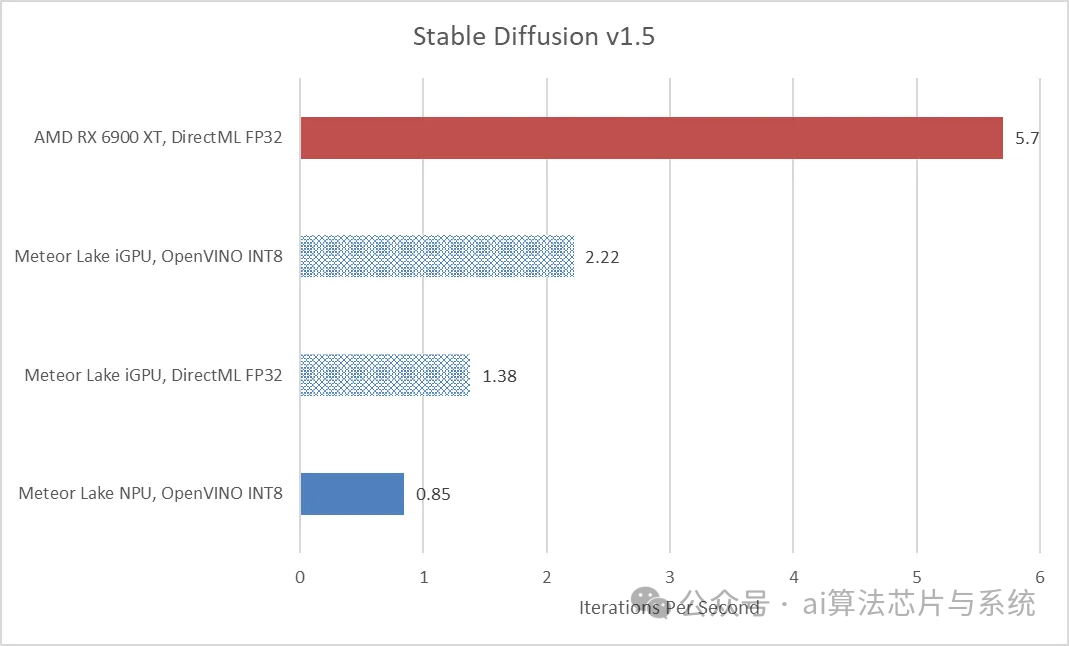
The actual results were consistent with Intel’s official slides: Meteor Lake’s integrated GPU easily outperformed the NPU. My “pure GPU” score was 1.38 iterations/s, which closely matches the official figure of 20 iterations/14.5 s (or 1.379 iterations/s). Even when loading the full FP32 model, the integrated GPU is still 62% faster than the NPU; if the same INT8 model is run on the integrated GPU, the lead increases to 261%. As for discrete GPUs, taking the AMD RX 6900 XT as an example, even at FP32 precision, its speed is 6.7 times that of the NPU.
08 Summary and Outlook
Since the dawn of computing, engineers have continuously designed various accelerators. When hardware is highly matched to specific tasks, performance or power consumption benefits can be achieved. The NPU of Meteor Lake is designed for machine learning workloads: its core supports INT8 and FP16, with only a symbolic implementation for FP32 and a complete abandonment of FP64; its memory subsystem is also simplified accordingly, reducing overhead through predictable data movement patterns in machine learning. Overall, this NPU reflects the value of Intel’s past acquisitions and demonstrates the flexibility of the Meteor Lake Scalable Fabric—compared to the older Sandy Bridge architecture, the position and number of SoC integrated accelerators can be configured more freely.
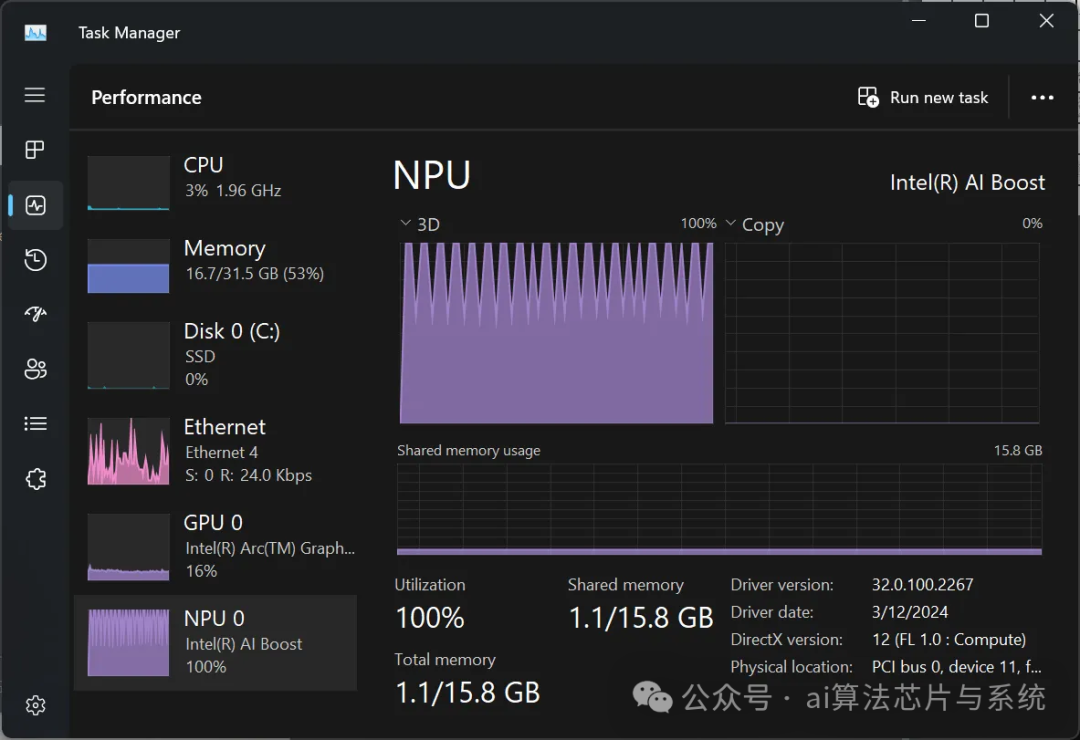
However, the NPU still has significant shortcomings. Accelerators inherently lack the flexibility of more general designs: while no one expects the NPU to handle general computing, the limited data type support of the NPU 3720 directly hinders the operation of certain ML models. Custom accelerators need to build a dedicated software ecosystem around them—the process of deploying Stable Diffusion on the NPU is both cumbersome and limited. By 2024, ordinary consumers may be accustomed to multiple programming languages and willing to browse open-source code, but they expect to directly call ready-made models rather than obtaining opaque blobs out of thin air. In other scenarios, the NPU may perform better; I will further verify this when I have more time and resources in the future.

For runnable models, the NPU only brings power savings and does not necessarily lead to performance improvements. Meteor Lake reports power consumption for the CPU cores, integrated GPU, and System Agent separately; the NPU belongs to the System Agent, with its full-load power rarely exceeding 7 W, while the integrated GPU can reach 20 W. However, the integrated GPU achieves this at the cost of performance and flexibility that the NPU cannot match. If machine learning workloads do not need to be executed in mobile scenarios, discrete GPUs can provide orders of magnitude performance leaps. The NPU may have value in specific contexts, but the marketing label of “AI PC” is clearly disconnected from reality.
Consider the AI PC as a super personal computer equipped with the right hardware and software to handle AI…ZDNET article “What is an AI PC?”[2]
As long as there is sufficient video memory, any PC equipped with a mid-range discrete graphics card can handle AI tasks. GPUs already have a mature AI software stack and can support a wider range of models without additional hassle than the NPU. I can directly run Stable Diffusion 2.0 to generate 768×768 high-resolution images with GPU acceleration, and the speed is still faster than the NPU generating 512×512 images with a mysterious INT8 blob. In my view, any enthusiast-level gaming desktop is already an “AI PC”; as for the ASUS Zenbook 14, I would gladly call it an “AI PC” regardless of whether it has an NPU.

The NPU of Meteor Lake is an intriguing accelerator, but its applicable scenarios and range of benefits are very limited. If I relied on AI tasks daily, I would run ready-made models directly on the integrated GPU—higher performance and less deployment time. The NPU only makes sense when extreme battery life extension is needed, and I hardly work in a state away from power, as even economy class seats are now equipped with power outlets. I hope Intel continues to iterate on both hardware and software in the future to broaden the application boundaries of the NPU. Over the past fifteen years, GPU computing has evolved to a state of considerable ease of use; witnessing the moment when workloads are offloaded to low-power modules remains exciting, and I look forward to the NPU experiencing a similar evolution.
09 References
- • Intel Core Ultra Processors (PS Series) Datasheet
- • https://techcrunch.com/2016/09/05/intel-buys-computer-vision-startup-movidius-as-it-looks-to-build-up-its-realsense-platform/
This article is translated and reconstructed from Intel Meteor Lake’s NPU[3]
Reference Links
<span><span>[1]</span></span> ONNX Source Code: https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/core/providers/dml/dml_provider_factory.cc<span><span>[2]</span></span> “What is an AI PC?”: https://www.zdnet.com/article/what-is-an-ai-pc-exactly-and-should-you-buy-one-in-2025/<span><span>[3]</span></span> Intel Meteor Lake’s NPU: https://chipsandcheese.com/p/intel-meteor-lakes-npu
—END—
Click the business card below
Follow us now