 MLNLPThe MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP graduate students, university professors, and corporate researchers.The vision of the communityis to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners.Source | Machine HeartEditor | Zhang Qian
MLNLPThe MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP graduate students, university professors, and corporate researchers.The vision of the communityis to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners.Source | Machine HeartEditor | Zhang Qian
How much parameter redundancy exists in LoRA? This innovative research introduces the LoRI technology, which demonstrates that even significantly reducing the trainable parameters of LoRA can still maintain strong model performance. The research team tested LoRI on mathematical reasoning, code generation, safety alignment, and eight natural language understanding tasks. They found that training only 5% of the LoRA parameters (equivalent to about 0.05% of the full fine-tuning parameters) allows LoRI to match or exceed the performance of full fine-tuning, standard LoRA, and DoRA methods.

Deploying large language models still requires substantial computational resources, especially when fine-tuning is needed to adapt to downstream tasks or align with human preferences.
To reduce the high resource costs, researchers have developed a series of Parameter-Efficient Fine-Tuning (PEFT) techniques. Among these techniques, LoRA has been widely adopted.
However, LoRA still incurs significant memory overhead, especially in large-scale models. Therefore, recent research has focused on further optimizing LoRA by reducing the number of trainable parameters.
Recent studies have shown that incremental parameters (the parameters after fine-tuning minus the pre-trained model parameters) exhibit significant redundancy. Inspired by the effectiveness of random projections and the redundancy of incremental parameters, researchers from the University of Maryland and Tsinghua University proposed a LoRA method with reduced interference—LoRI (LoRA with Reduced Interference).
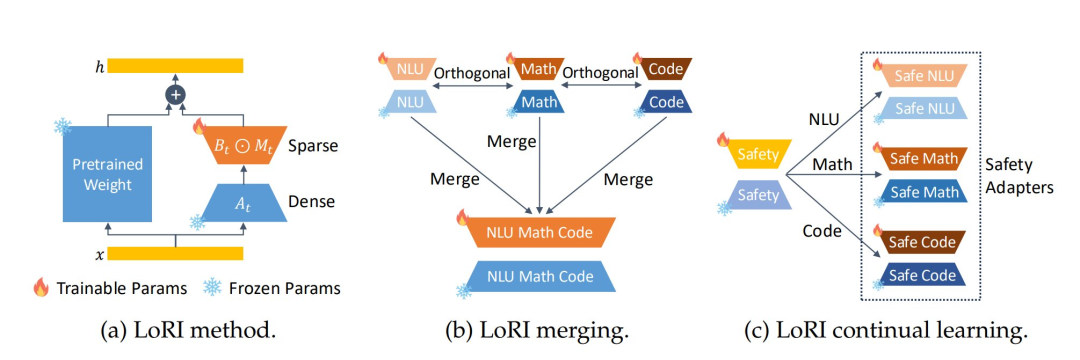
LoRI keeps the low-rank matrix A as a fixed random projection while using a task-specific sparse mask to train matrix B. To retain the most critical elements in B, LoRI performs a calibration process by selecting the elements with the highest magnitude across all layers and projections to extract the sparse mask.
As shown in Figure 1(a), even with 90% sparsity in B and A kept frozen, LoRI still maintains good performance. This indicates that the adaptation process does not require updating A, and B has considerable redundancy. By applying more constrained updates than LoRA, LoRI significantly reduces the number of trainable parameters while better preserving the knowledge of the pre-trained model during the adaptation process.
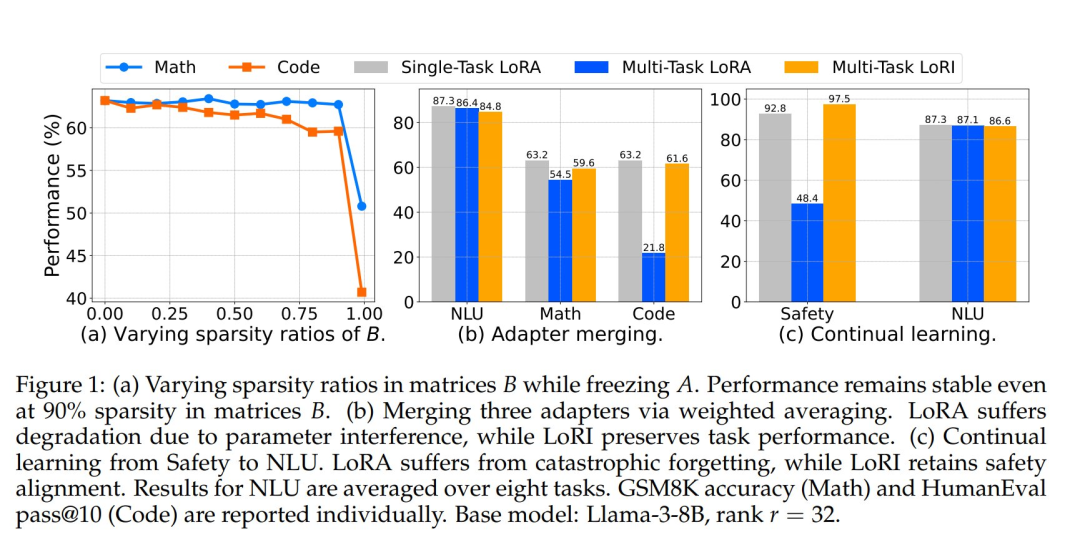

Multi-task learning is crucial for achieving general models with multi-task capabilities, traditionally accomplished through joint training on combinations of task-specific datasets. However, training large models on such mixed data is prohibitively costly in terms of time and computational resources. Model merging is a training-free alternative that builds powerful models by combining existing models. This approach is particularly suitable for merging LoRA adapters to endow a single LoRA with multi-task capabilities.
However, as shown in Figure 1(b), directly merging heterogeneous LoRA often leads to parameter interference, resulting in the merged LoRA performing worse than single-task LoRA. Additionally, many existing merging methods require trial and error to determine the best approach for specific task combinations.
LoRI addresses these challenges by implementing adapter merging without the need for manual selection of merging methods. By using a fixed, randomly initialized projection A, LoRI maps task-specific adapters to approximately orthogonal subspaces, thereby reducing interference when merging multiple LoRIs.
In addition to multi-tasking, safety-critical scenarios require that each newly introduced adapter enhances model capabilities while maintaining the safety alignment of the pre-trained base model. LoRI provides a lightweight continual learning method for adjusting the model while maintaining safety, where training occurs sequentially across tasks. This strategy first fine-tunes the adapter on safety data to establish alignment, then adapts to each downstream task separately.
However, as shown in Figure 1(c), continual learning often leads to catastrophic forgetting, where adaptation to new tasks severely damages previously acquired knowledge. LoRI mitigates forgetting by leveraging the sparsity of matrix B with task-specific masks. This isolation of cross-task parameter updates promotes continual learning with minimal interference while maintaining safety and task effectiveness.
To evaluate the effectiveness of LoRI, the authors conducted extensive experiments across various benchmarks covering natural language understanding, mathematical reasoning, code generation, and safety alignment tasks.
Using Llama-3-8B and Mistral-7B as base models, their results indicate that LoRI achieves or exceeds the performance of full fine-tuning (FFT), LoRA, and other PEFT methods while using 95% fewer trainable parameters than LoRA. Notably, on the HumanEval of Llama-3, LoRI with 90% sparsity in B outperformed LoRA by 17.3%.
In addition to single-task adaptation, they also evaluated LoRI’s performance in multi-task environments, including adapter merging and continual learning scenarios. The serial merging of LoRI adapters consistently outperformed LoRA adapters, closely matching the performance of single-task LoRA baselines. In terms of continual learning, LoRI significantly outperformed LoRA in mitigating catastrophic forgetting in safety alignment while maintaining strong performance on downstream tasks.

-
Paper Title: LoRI: Reducing Cross-Task Interference in Multi-Task Low-Rank Adaptation
-
Paper Link: https://arxiv.org/pdf/2504.07448
-
Code Link: https://github.com/juzhengz/LoRI
-
HuggingFace: https://huggingface.co/collections/tomg-group-umd/lori-adapters-67f795549d792613e1290011
Method Overview
a
The LoRI method proposed in the paper has the following key points:
-
LoRI freezes the projection matrix A_t and uses task-specific masks to sparsely update B_t;
-
LoRI supports merging multiple task-specific adapters, reducing parameter interference;
-
LoRI establishes safe adapters through continual learning and reduces catastrophic forgetting.
In the comments section of the author’s tweet, someone asked how this method differs from previous methods (such as IA3). The author replied that “IA3 and LoRI differ in how they adjust model parameters: IA3 learns scaling vectors for key/value/FFN activations. The trainable parameters are the scaling vectors. LoRI (based on LoRA) decomposes weight updates into low-rank matrices. It keeps A frozen and applies a fixed sparse mask to B. Thus, only the unmasked parts of B are trained.”
Experimental Results
a
The authors used Llama-3-8B and Mistral7B as benchmark models, and all experiments were conducted on 8 NVIDIA A5000 GPUs. As shown in Figure 1(a), LoRI maintains strong performance even when matrix B reaches 90% sparsity. To explore the impact of sparsity, the authors provided two LoRI variants: LoRI-D with a dense matrix B, and LoRI-S with 90% sparsity applied to matrix B.
Single-Task Performance
Table 1 shows the single-task results of different methods on 8 natural language understanding (NLU) benchmarks, while Table 2 reports the performance of different methods on mathematical, programming, and safety benchmarks.
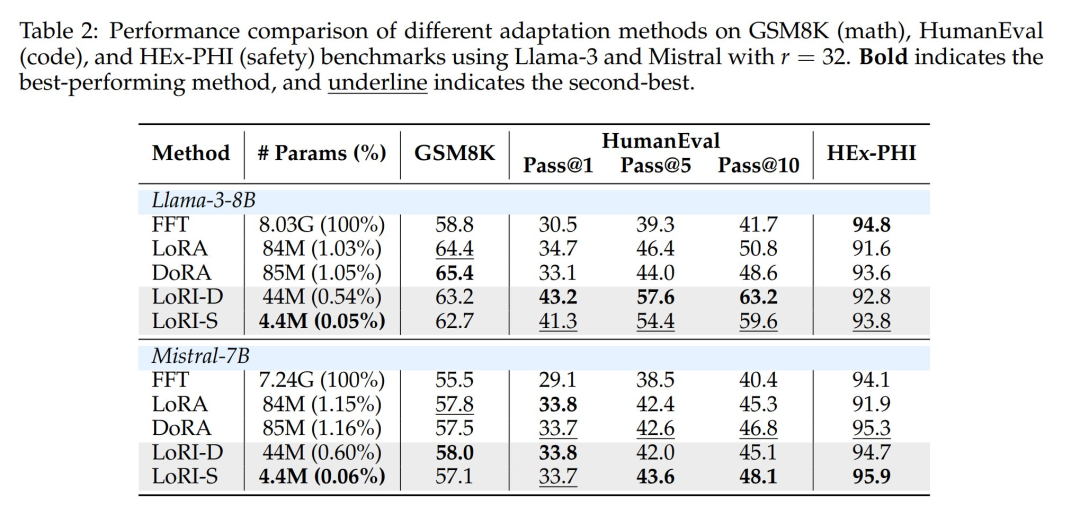
Full parameter fine-tuning (FFT) updates all model parameters, while LoRA and DoRA reduce the amount of trainable parameters to about 1%. LoRI-D further compresses the parameter count to 0.5% by freezing matrix A, while LoRI-S achieves extreme compression of 0.05% by applying 90% sparsity to matrix B—reducing trainable parameters by 95% compared to LoRA. Despite the significant reduction in tunable parameters, LoRI-D and LoRI-S perform comparably or even better than LoRA and DoRA on NLU, mathematical, programming, and safety tasks.
Adapter Fusion
The authors selected four categories of heterogeneous tasks for the LoRA and LoRI fusion study, which is more challenging than merging similar adapters (such as multiple NLU adapters).
Table 3 presents the fusion results for the four categories of tasks. The authors applied serial and linear fusion to the LoRI-D and LoRI-S variants. Since LoRI has already sparsified matrix B, pruning-based methods (such as magnitude pruning, TIES, DARE) are no longer applicable—these methods would prune matrix A, leading to inconsistent pruning strategies for the AB matrix.

As shown in Table 3, directly merging LoRA leads to a significant drop in performance (especially in code generation and safety alignment tasks). Although pruning methods (such as DARE, TIES) can enhance code performance, they often come at the cost of sacrificing accuracy in other tasks. In contrast, LoRI performs robustly across all tasks, with the serial fusion scheme of LoRI-D overall performing best, nearly matching the single-task baseline, indicating minimal interference between LoRI adapters.
Continual Learning
While merging adapters can achieve multi-task capabilities, it cannot provide robust safety alignment in scenarios requiring strong safety guarantees. As shown in Table 3, the highest safety score achievable through merging LoRA or LoRI is 86.6.
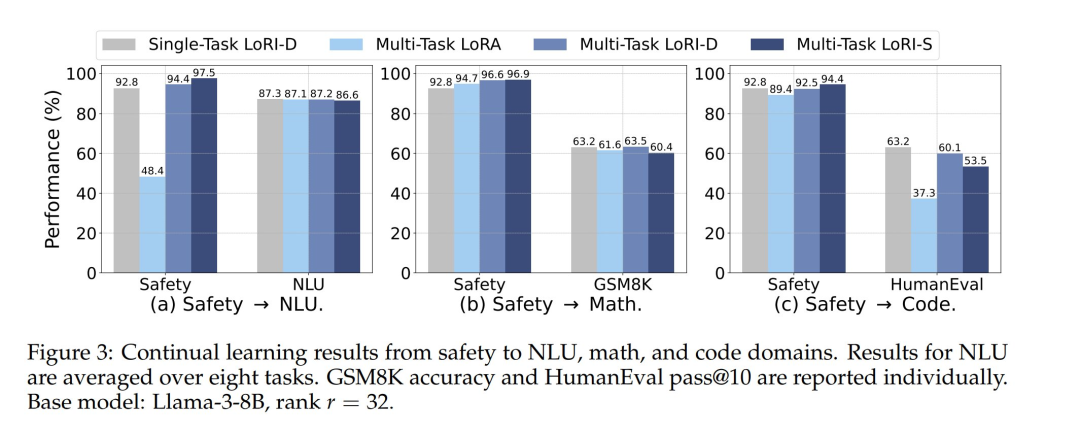
To address this issue, the authors employed a two-stage training process: first, training the safety adapter on the Saferpaca safety alignment dataset; then adapting it to each downstream task, including natural language understanding (NLU), mathematics, and code.
Figure 3 shows the results of these continual learning experiments. LoRA exhibits severe catastrophic forgetting in safety alignment—especially in the safety→NLU experiment—likely due to the large NLU training set (approximately 170,000 samples). Among all methods, LoRI-S achieved the best retention of safety alignment, even outperforming single-task LoRI-D. This is because its B matrix has 90% sparsity, allowing for isolation of parameter updates between safety alignment and task adaptation. LoRI-D also demonstrated some resistance to forgetting, thanks to its frozen A matrix. For task adaptation, LoRI-D generally outperformed LoRI-S, as the latter’s aggressive sparsity limited its adaptability.
Overall, LoRI provides a lightweight and effective method for building safe adapters while supporting downstream task adaptation and maintaining alignment.
For detailed content, please refer to the original paper.
Technical Group Invitation

△ Long press to add the assistant
Scan the QR code to add the assistant WeChat
Please note:Name-School/Company-Research Direction(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)to apply for joiningNatural Language Processing/Pytorchand other technical groups
About Us
MLNLP Communityis a grassroots academic community jointly built by scholars in machine learning and natural language processing from both domestic and international backgrounds. It has developed into a well-known community for machine learning and natural language processing, aiming to promote progress between the academic and industrial sectors of machine learning and natural language processing.The community provides an open communication platform for related practitioners in further education, employment, and research. Everyone is welcome to follow and join us.