
作者 | Kyle Wiggers
编译 | Sambodhi
策划 & 编辑 | 刘燕
不久前,Facebook 开源了号称是全球最强大的聊天机器人 Blender,它标志着 Facebook 在 AI 领域的新进展:新的聊天机器人不仅解决了此前聊天机器人的固有缺点,更是拥有史无前例的 94 亿个参数。
Recently, Facebook open-sourced what it claims to be the world’s most powerful chatbot, Blender, marking a new advancement for Facebook in the field of AI. This new chatbot not only addresses the inherent shortcomings of previous chatbots but also boasts an unprecedented 9.4 billion parameters.
Recently, Facebook’s artificial intelligence and machine learning division, Facebook AI Research (FAIR), provided a detailed introduction to a comprehensive AI chatbot framework named Blender.
FAIR claims that Blender, which is currently available as open source on GitHub, is the most powerful open-domain chatbot ever created, exhibiting more “human-like” qualities than existing methods for generating dialogue.
FAIR states that Blender is the culmination of years of research, combining empathy, knowledge, and personality into a single system. To achieve this, the foundational model benefits from improved decoding and skill-mixing techniques, containing up to 9.4 billion parameters (defining skill configuration variables for specific problems), which is 3.6 times that of previous systems.
Blender promises to make interactions with conversational AI systems like Alexa, Siri, and Cortana more natural than ever, whether in enterprise, industrial, or consumer environments. This is because it can ask and answer a wide variety of questions, demonstrate knowledge about specific topics, and express different emotions as needed, such as empathy, seriousness, or a “playful” demeanor.
Skill Mixing and Generation Strategies
To achieve Blender’s state-of-the-art performance, FAIR researchers focused on two engineering steps: skill mixing and generation strategies.
“Skill mixing” refers to selecting tasks that outperform larger models lacking fine-tuning. As noted by FAIR researchers in a paper, improvements in chatbots can be achieved by fine-tuning data models that focus on desirable conversational skills. It has been shown that fine-tuning can also minimize undesirable features learned from large datasets, such as toxicity.
In terms of generation strategies, the choice of decoding algorithms (the algorithms that generate text from language models) has a significant impact on the chatbot’s responses. Since the length of the bot’s responses often correlates with human judgments of quality, the length of the decoder should ideally strike an appropriate balance. Too short responses are often perceived as dull or lacking interest, while overly long responses may suggest vagueness or distraction.
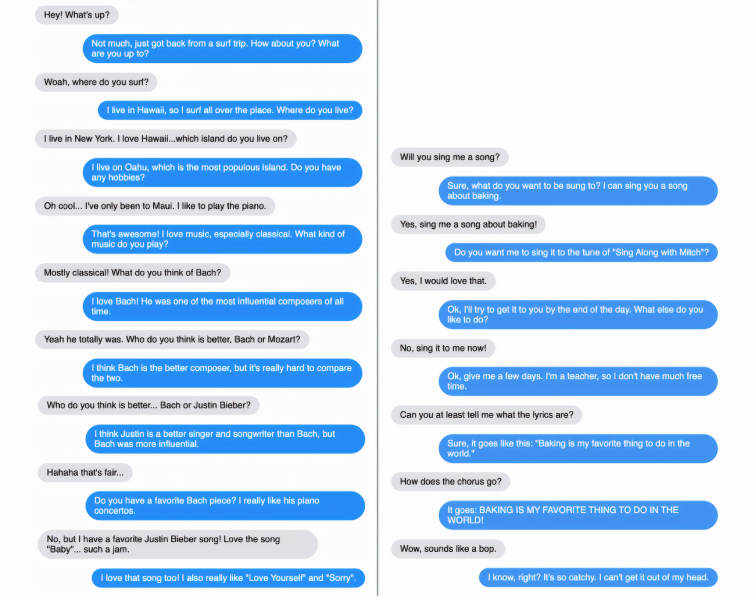
Image showing a conversation with the Blender chatbot. The blue dialogue box represents Blender’s response.
During these engineering steps, researchers tested three types of model architectures, all based on Transformers. Like all deep neural networks, Google’s innovative Transformer product consists of hierarchically arranged neurons (mathematical functions) that transmit signals from input data and adjust the strength (weights) of each connection. This is how they extract features and learn predictions, but Transformers also have an attention mechanism. This means that each output element is connected to every input element, with their weights dynamically calculated.
The first is a retriever model, which, given a dialogue history (or context) as input, scores a large pool of candidate responses and outputs the highest-scoring one to select the next dialogue response. FAIR researchers adopted a multi-encoder architecture that uses the representation of each candidate response to encode the features of the context, claiming that this architecture improves performance while maintaining “ease of processing” compared to other architectures like cross-encoders.
The second model is a generator, which produces responses rather than retrieving them from a fixed set. Three models were considered in terms of size, ranging from 90 million parameters to 2.7 billion parameters, and up to 9.4 billion parameters.
The third model attempts to address the generator’s tendency to produce repetitive responses and “hallucinated” knowledge. It employs a “retrieve and refine” (RetNRef) approach, where the aforementioned retriever model generates a response when provided with dialogue history, which is then appended to the generator’s input sequence. This way, the generator can learn when to copy response elements from the retriever and when not to, allowing it to output more interesting, engaging, and “vivid” responses. (Responses generated by the retriever model often contain more vivid language than standard generator models.)
FAIR paired a guide generation model with another retriever to jointly decide when to integrate knowledge into the chatbot’s responses. These two models produce a set of initial knowledge candidates, which are then ranked, after which they select a sentence and use it to constrain the generated response. A classifier determines whether to perform retrieval for each dialogue to avoid providing knowledge when it is unnecessary.
Decoding
For the generation model, FAIR researchers used a beam search decoding method to generate responses to a given dialogue context. Beam search retains a set of partially decoded sequences, known as hypotheses, which are concatenated to form sequences and then scored, allowing the best sequences to bubble to the top.
To control the length of the chatbot’s responses, the FAIR team considered two methods: a hard constraint on the minimum generation length and classifier predictions for response length, setting the minimum generation length constraint to the corresponding predicted value. The latter is more complex, but the result is that the response length to questions is not fixed, ensuring that the chatbot can provide longer responses when it seems appropriate.
Training the Model
To prepare the various models that make up Blender, researchers first conducted pre-training, which is not conditioning machine learning models for specific tasks. They used Facebook’s own Fairseq, a toolkit that supports training custom language models, with data samples sourced from the Reddit corpus, which contains 1.5 billion comments (with two sets of 360,000 comments reserved for validation and testing), and made adjustments for known chatbots, non-English Subreddits, deleted comments, comments with URLs, and comments of a certain length.
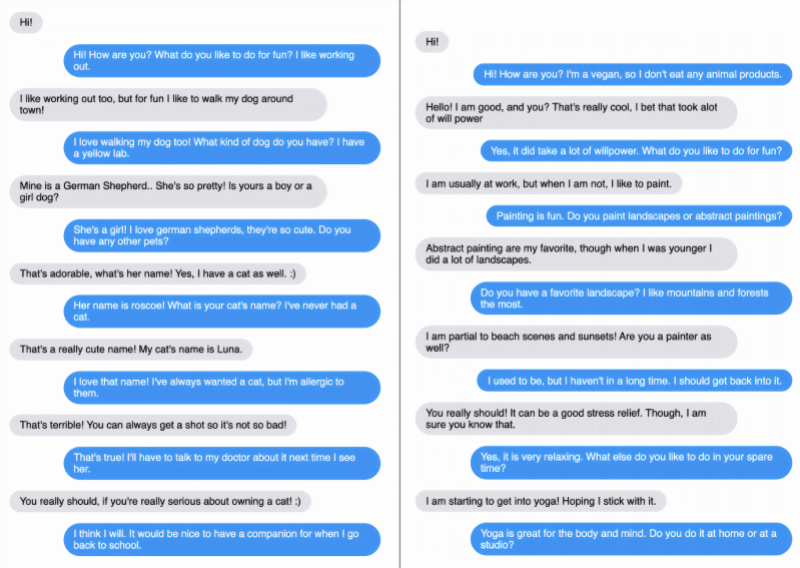
Next, the FAIR team fine-tuned the models using another Facebook-developed suite, ParlAI, which is used for training and testing dialogue models. One of the selected training corpora was ConvAI2, which contains 140,000 utterances, including paired volunteers getting to know each other through questions and answers.
Another was Empathetic Dialogues, which contains 50,000 crowd-sourced utterances in emotional contexts. However, another dataset, the Wizard of Wikipedia, consists of 194,000 topics, with each dialogue starting with a randomly selected topic, aiming to showcase expert knowledge.
The fourth fine-tuning dataset, Blended Skill Talk, aims to mix the first three datasets (ConvAI2, Empathetic Dialogues, and Wizard of Wikipedia) to combine their respective skills during dialogues. Here, we collected 76,000 utterances, including guided and unguided human speakers, where guided speakers could choose utterances suggested by the chatbot trained on these three separate datasets.
Evaluation
After training, researchers compared Blender’s performance with Google’s latest machine learning model, the Meena chatbot, which has 2.6 billion parameters. Human volunteers were tasked with answering two questions: “Who would you prefer to have a long conversation with?” and “Which speaker sounds more human-like?”— they were presented with 100 randomly selected logs from Meena’s public release and the same number of logs generated by Blender. In each case, volunteers saw a series of dialogues paired between humans and the respective chatbots.
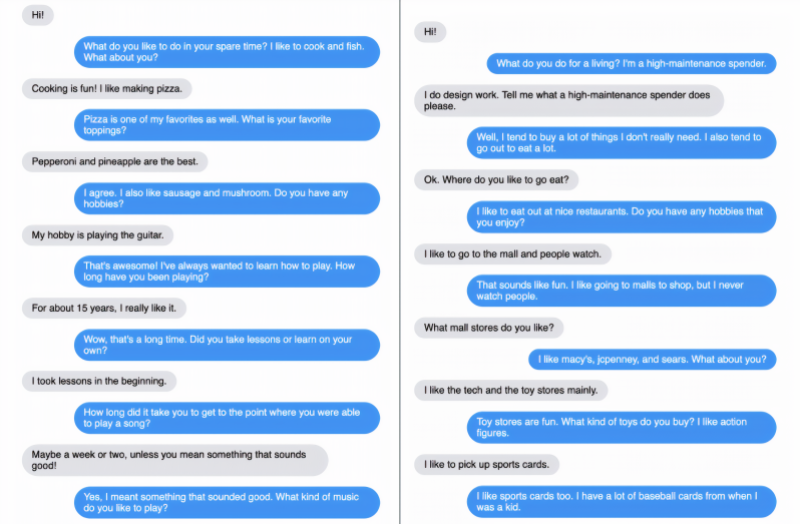
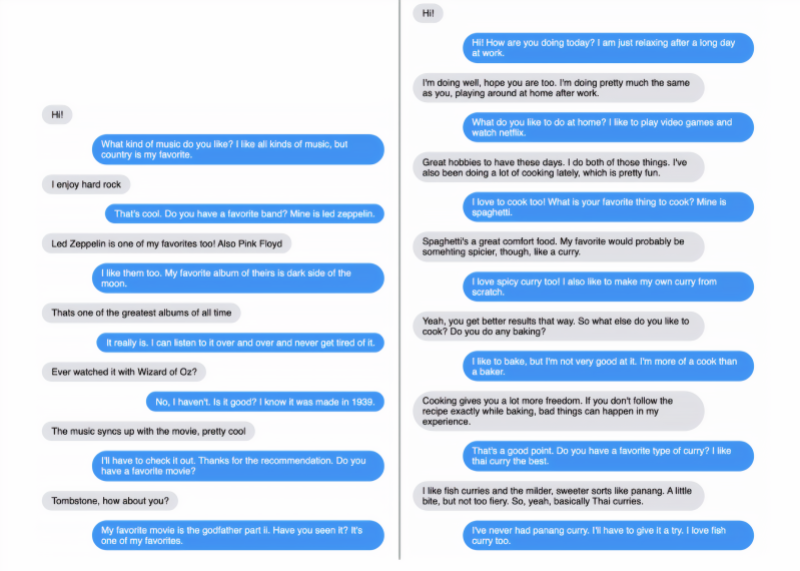
The topics of the dialogues ranged from cooking, music, movies, pets, to yoga, vegetarianism, instruments, and shopping malls, with the Blender model often delving into details when asked about relevant stores, bands, movies, actors, types of pets, and pet names. In one instance, Blender provided a detailed answer to a question comparing Bach and Justin Bieber, and when asked to write a song, it indeed generated lyrics, although they lacked any particular poetic quality.
After showing volunteers the chats from both Meena and Blender, 67% of volunteers indicated that the better-performing Blender chatbot sounded more human-like, containing a generative model with 9.4 billion parameters, pre-trained on the Blended Skill Talk corpus. About 75% of volunteers stated they would prefer to have long conversations with the fine-tuned model of 2.7 billion parameters rather than with Meena. Furthermore, in an A/B comparison between human-human and human-Blender dialogues, 49% of volunteers preferred the fine-tuned model on Blended Skill Talk, while only 36% preferred the model trained solely on public domain dialogues.
However, the issues are not without challenges. Further experiments showed that Blender sometimes produces responses in the style of aggressive samples from the training corpus, most of which come from Reddit comments. FAIR researchers noted that fine-tuning on the Blended Skill Talk dataset can mitigate this issue to some extent, but a comprehensive solution will require the use of unsafe word filters and a safety classifier.

Of course, FAIR researchers do not claim that the issues of open-domain dialogue have been resolved. In fact, they list several major limitations of Blender:
-
Vocabulary Usage: Even the best Blender models tend to generate common phrases too frequently, such as: “do you like,” “lot of fun,” “have any hobbies,” etc.
-
Unconscious Repetition: The model often repeats what others say to it. For example, if the conversation partner mentions a pet dog, it will claim to have a pet dog or say that they both like the same band, etc.
-
Contradictions and Forgetting: Blender models can contradict themselves, although the degree of contradiction is less in larger models. They also fail to establish logical connections, meaning they should not pose previously mentioned questions (to avoid the phenomenon of “forgetting”).
-
Knowledge and Factual Accuracy: It is relatively easy to induce factual errors in the Blender model, especially when delving deeply into a topic, leading to more frequent factual inaccuracies.
-
Dialogue Length and Memory: FAIR researchers state that over days or weeks of dialogue, Blender’s conversations can become dull and repetitive, especially considering that Blender cannot remember previous dialogue content.
-
Deeper Understanding: Blender models lack the ability to learn concepts through further dialogue, and they cannot relate to entities, actions, and experiences in the real world.
Addressing all these issues may require new model architectures, and the FAIR team states they are exploring this. They are also focused on building more robust classifiers to filter harmful language in dialogues and eliminate the pervasive gender bias in chatbots.
Facebook stated in a blog post: “We are excited about the progress made in improving open-domain chatbots; however, building a truly intelligent conversational agent that can chat like a human remains one of the biggest open challenges in today’s AI field… Real progress in this area depends on reproducibility, which is built on the opportunity to establish best practices. We believe that releasing models is crucial for a comprehensive and reliable understanding of their capabilities.”
FAIR has made available pre-trained and fine-tuned Blender models with 90 million parameters, 2.7 billion parameters, and 9.4 billion parameters on GitHub, along with a script for interacting with the chatbot (which includes built-in safety filters). All code used for model evaluation and fine-tuning, including the datasets themselves, is available in ParlAI.
作者介绍:
Kyle Wiggers, a technology journalist based in New York, writes about artificial intelligence for VentureBeat. He supports VentureBeat’s ethical statement.
Further Reading:
https://venturebeat.com/2020/05/02/emotion-detection-is-a-hot-ask-in-marketing-but-the-tech-just-isnt-ready-yet/

Are you also “watching”? 👇