 Previously, I wrote an article about extracting news from the news broadcast to analyze investment opportunities. During the May Day holiday, some students asked if there were other sources of the latest news. In fact, there are many information sources. Here, we take Dongfang Caifu as an example to demonstrate how to obtain the latest news and analyze the corresponding sector and stock opportunities.
Previously, I wrote an article about extracting news from the news broadcast to analyze investment opportunities. During the May Day holiday, some students asked if there were other sources of the latest news. In fact, there are many information sources. Here, we take Dongfang Caifu as an example to demonstrate how to obtain the latest news and analyze the corresponding sector and stock opportunities.
We will still use the Streamlit framework to integrate several modules: information data acquisition, NLP preprocessing, and large model inference, forming a simple AI investment research analysis loop.
1.1 Data Acquisition Layer
# Data source configuration
news_df = ak.stock_info_global_em()[['标题', '摘要', '发布时间']].dropna().head(20)- AKShare Data Engine: Obtains global real-time news through financial data interfaces, supporting multi-dimensional data collection for stocks, funds, futures, etc.
- Data Cleaning: Uses an intelligent filtering mechanism to remove invalid data and retain key fields (title/summary/time)
- Dynamic Updates: Built-in scheduled task module for minute-level data refresh, ensuring information timeliness
1.2 NLP Preprocessing Layer
def preprocess_text(text):
# Regular expression to remove non-Chinese characters
text = re.sub(r'[^�-]+', '', text)
# Jieba word segmentation + stop word filtering
words = [word for word in jieba.cut(text) if word not in STOP_WORDS and len(word) > 1]
return " ".join(words)- Text Cleaning: Removes special symbols and invalid characters using regular expressions
- Intelligent Word Segmentation: Uses the Jieba word segmentation engine combined with a financial professional dictionary for precise segmentation of industry terms
- Feature Optimization: Customized stop word list to filter redundant information, retaining core semantic elements
1.3 Large Model Inference Layer
# LangChain configuration
prompt_template = """
As a professional financial analyst, please provide investment advice based on the following news summary...
"""
chain = LLMChain(llm=llm, prompt=prompt)- Large Model Integration: Connects to cutting-edge large language models, supporting deep understanding of financial texts
- Prompt Engineering: Uses structured templates to guide model output of standardized analysis reports
- Parameter Tuning: Balances model creativity and stability, ensuring the reliability of professional advice
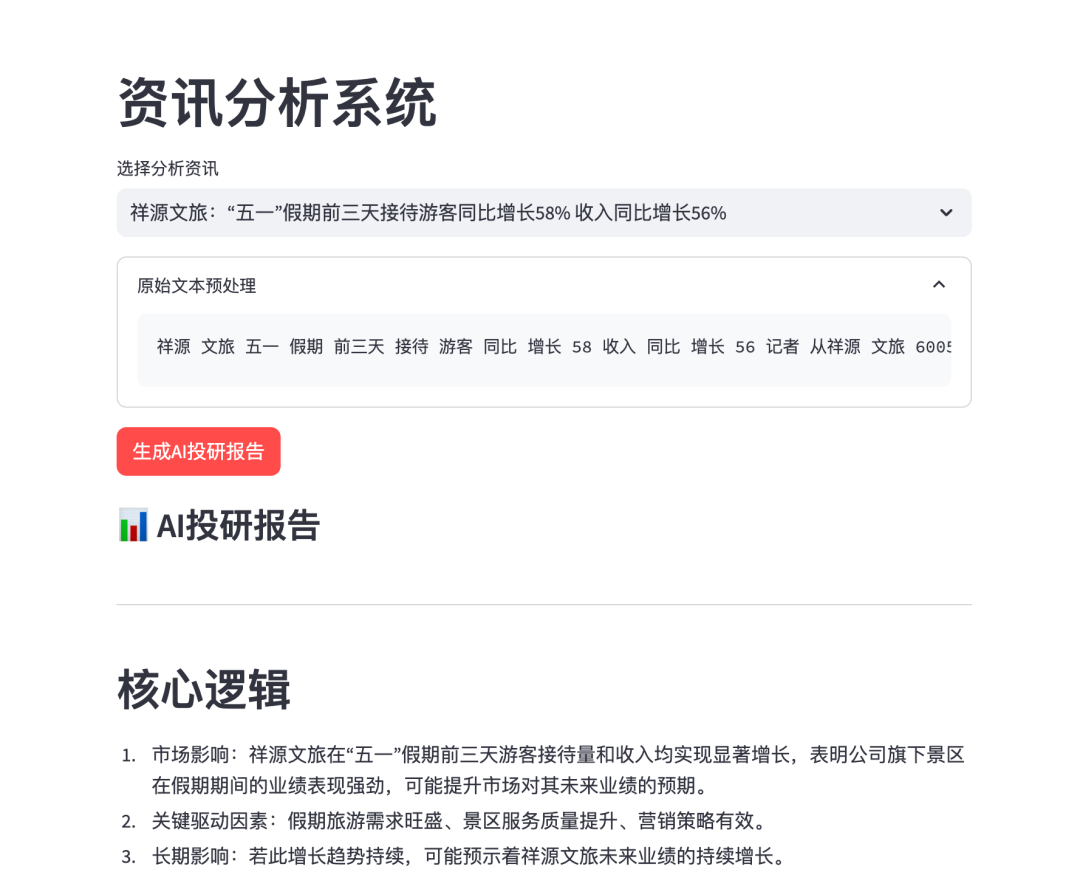
1.4 Interactive Display Layer
# Streamlit interface components
st.title("News Analysis System")
selected_news = st.selectbox("Select News for Analysis", news_df['标题'])
st.markdown(analysis.split("### 投资建议")[1])- Visual Interface: Constructs an interactive analysis panel, supporting multi-dimensional data exploration
- Dynamic Rendering: Achieves intelligent segmented display and highlighting of analysis reports
- Responsive Design: Adapts to PC/mobile displays, optimizing user experience
Related articles recommended:[Python Technology] Extracting Hot Content from News Broadcasts and Letting Large Models Provide Investment Advice
Finally, here is the source code, feel free to take it. Note:If you find extra special characters in the format, copying it should be fine when opened with a regular browser.
Note: The Zhipu API used in the program can be replaced with other large models; it is mainly demonstrated here because it is free. You can directly apply for a key athttps://open.bigmodel.cn/ application.
import akshare as ak
import streamlit as st
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
import re
import jieba
# Zhipu API configuration
zhipu_api_key = "your key"
llm = ChatOpenAI(
temperature=0.95,
model="glm-4-flash",
openai_api_key=zhipu_api_key,
openai_api_base="https://open.bigmodel.cn/api/paas/v4/",
max_tokens=2048)
# Text preprocessing configuration
STOP_WORDS = {
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '而', '及', '可以',
'这', '一个', '为', '之', '与', '等', '也', '会', '要', '于', '中', '对', '并', '其',
'或', '后', '但', '被', '让', '说', '去', '又', '已', '向', '使', '该', '将', '到',
'应', '与', '了', '这', '我们', '他们', '自己', '这个', '这些', '这样', '因为', '所以'}
# LangChain prompt template
prompt_template = """
As a professional financial analyst, please provide investment advice based on the following news summary:
News Title: {news_title}
News Summary: {news_summary}
Please output in the following structured format:
### Core Logic
1. Market Impact: Explain the core impact of the news in no more than 3 sentences
2. Key Driving Factors: List 3-5 key driving factors
### Sector Opportunities
List the top three related sectors by benefit level, each including:
- Sector Name
- Benefit Logic
- Benefit Strength Assessment (High/Medium/Low)
### Investment Advice
Recommend 5 stocks with the highest relevance in table format:
| Stock Code | Stock Name | Relevance Logic | Operation Advice |
|---------|---------|--------|--------|"""
prompt = PromptTemplate(
input_variables=["news_title", "news_summary"],
template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt)
# Text processing function
def preprocess_text(text):
"""News text preprocessing"""
text = re.sub(r'[^�-]+', '', text)
words = [word for word in jieba.cut(text) if word not in STOP_WORDS and len(word) > 1]
return " ".join(words)
# Streamlit interface
def app():
# Main interface
st.title("News Analysis System")
try:
# Get real-time news
news_df = ak.stock_info_global_em()[['标题', '摘要', '发布时间']].dropna().head(20)
# News selector
selected_news = st.selectbox("Select News for Analysis", news_df['标题'])
news_detail = news_df[news_df['标题'] == selected_news].iloc[0]
# Text preprocessing
with st.expander("Original Text Preprocessing", expanded=False):
cleaned_text = preprocess_text(news_detail['摘要'])
st.code(cleaned_text[:500] + "...", language='text')
# Generate analysis report
if st.button("Generate AI Investment Research Report", type="primary"):
with st.spinner('AI is analyzing...'):
analysis = chain.run({
"news_title": selected_news,
"news_summary": cleaned_text[:1000] # Summary truncation optimization
})
# Structured display
st.subheader("📊 AI Investment Research Report")
st.markdown("---")
try:
# Core logic analysis
core_logic = analysis.split("### 核心逻辑")[1].split("### 板块机会")[0]
st.markdown(f"## Core Logic\n{core_logic}")
# Sector opportunity display
sectors = analysis.split("### 板块机会")[1].split("### 投资建议")[0]
st.markdown(f"## Sector Opportunities\n{sectors}")
# Investment advice table
st.markdown("## Investment Advice")
st.markdown(analysis.split("### 投资建议")[1])
except Exception as e:
st.warning("Structural parsing exception, displaying raw output:")
st.code(analysis, language='markdown')
except Exception as e:
st.error(f"System exception: {str(e)}")
if __name__ == "__main__":
app()By the way: Some students, please do not ask me to send the source code from the public account articles in WeChat anymore. The source code has been completely attached in the article. For example, during the May Day holiday, I was sometimes not near my computer, and when I was playing, someone suddenly asked me to send the source code of a certain article. The original code may involve some private keys. If you find any special characters, just use a tool to format it. If you are really too lazy to do it, you can add the knowledge star group where most of the source files of my public account articles are placed, and I provide access to some article effects on the exclusive star group WeChat group.Some students asked about the star group entrance, this depends on your needs.1 year 99, low cost performance. If you have no needs, don’t join.