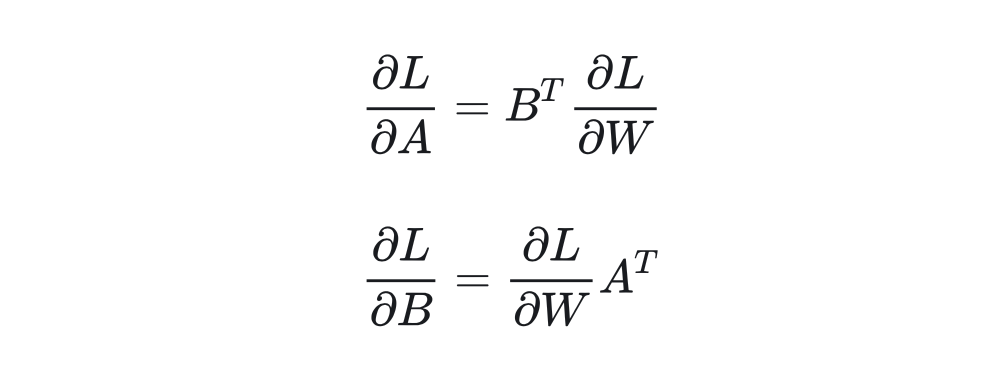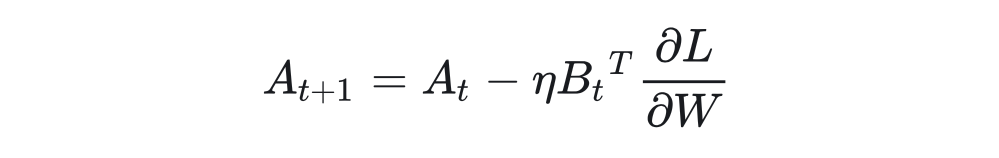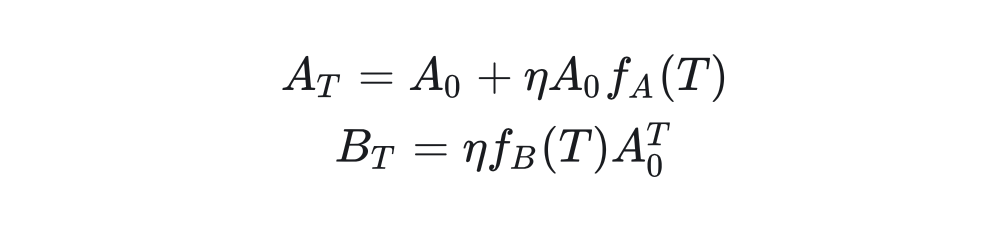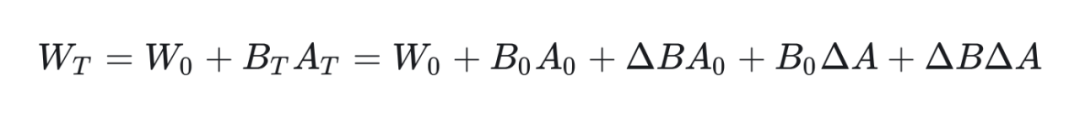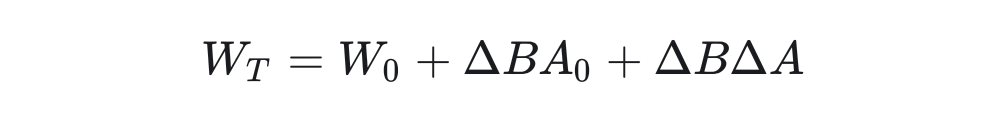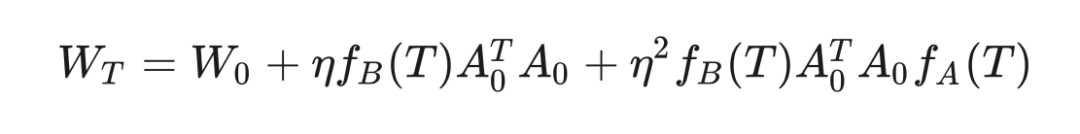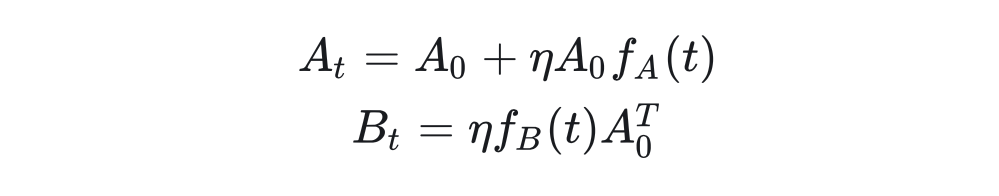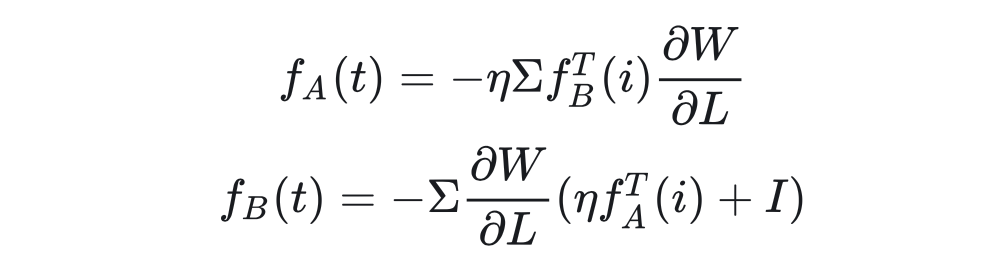Exploring the Essence of LoRA: A Low-Rank Projection of Full Gradients
Article Title:FLORA: Low-Rank Adapters Are Secretly Gradient Compressors
Article Link:
https://arxiv.org/pdf/2402.03293
This paper not only introduces a brand new high-rank efficient fine-tuning algorithm but also deeply interprets the essence of LoRA: LoRA is a low-rank projection of full gradients. In fact, this perspective is not surprising; we can see traces of this viewpoint in many past papers. For example, LoRA-FA proposes not to fine-tune the A matrix in LoRA but to only fine-tune the B matrix; LoRA+ suggests using a larger learning rate to fine-tune the B matrix in LoRA; ReLoRA/PLoRA/CoLA and others propose periodically merging LoRA weights for reinitialization. Their essence is actually the title of this paper.
The method proposed in this paper is actually not superior to LoRA because the essence of LoRA saving GPU memory is that when using the Adam optimizer, it can avoid calculating the first and second moments of the full weights (both of which must be represented in fp32, which consumes a lot of memory). The method proposed in this paper is actually an optimization of gradient accumulation, which can avoid the extra memory overhead caused by accumulating gradients during the gradient accumulation process. When using Adam for training, FLoRA cannot actually save memory. However, the analysis of LoRA in this paper is very brilliant.
The B Matrix in LoRA Dominates Weight Updates
1.1 Gradients in LoRA
First, we define the following symbols: and and .Then we have the formula for LoRA:Taking the derivative of the loss:
1.2 Amount of Weight UpdatesAfter obtaining the gradient, for the backward propagation at step t+1:
Where is the learning rate, and the update for matrix B is similar. Since matrix B is initialized to all zeros and matrix A is initialized to a normal distribution (in the peft library, it is kaiming initialization, which is different from the original LoRA). So for any step T during the training process, we have:
Where ,. Specific definitions will be proposed in the appendix, meaning that at any step T during training, the values of A and B are obtained from the projection of the matrix initialized from the normal distribution. After obtaining the values of A and B, we can derive that for any step T during the training process:
Since is a zero matrix, we have:
Substituting the values of and :
The third term can be ignored, indicating that when using LoRA for training, freezing matrix A can achieve similar effects (this is the idea behind LoRA-FA and also LoRA+; since matrix B dominates the parameter updates, a larger learning rate is required). When we freeze matrix A, we have:
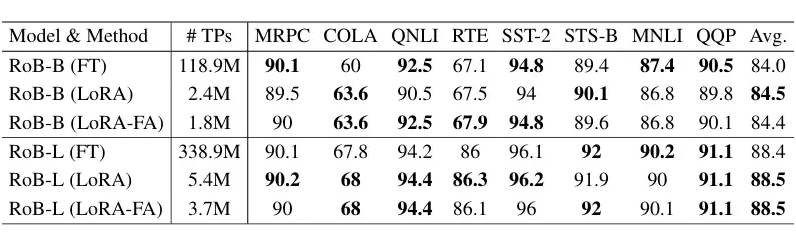
In other words, LoRA-FA essentially updates weight W through a one-time random dimensionality reduction projection of the gradient of weight W. LoRA and LoRA-FA are similar; we can consider this viewpoint to be largely valid.▲ Comparison of LoRA-FA and LoRA effects, showing very similar performance
FLoRA Algorithm
Based on the above insights, the author team proposed a new training algorithm:
▲ This algorithm is actually a variant of gradient accumulation. Given the gradient accumulation steps T, gradients for parameter W are computed over T steps, and at each step, a randomly initialized dimensionality reduction matrix reduces the gradient, achieving low-rank updates for the parameters by accumulating the reduced gradient values.
For optimizers using momentum mechanisms like Adam:▲ The above algorithm can achieve low-rank accumulation of momentum
Appendix
Here, the authors use mathematical induction to prove:
And during the proof process, the forms of and were obtained: