
-
Keywords: AI Chips, Semiconductor Processes, Domestic Chip Breakthroughs, NVIDIA, Autonomous Driving Chips, Open Source Ecosystem
-
This article has 7925 words, requiring 26 minutes to read, and a podcast of 43 minutes (there’s a bug in the later section, please check it out, Doubao

In September 2025, the global semiconductor and AI chip sector will enter a period of intense “technical breakthroughs + ecological competition”.
On one side, Intel bets on the aggressive 18A process for a “comeback”, while AMD challenges the NVIDIA CUDA ecosystem with ROCm 7, and the “chip selection theory” between Huang Renxun and Musk hides a struggle for industry discourse power; on the other side, domestic forces are accelerating breakthroughs: GPU companies like Muxi and Moer Thread are racing for IPO funding, while Horizon and NIO face dual challenges of “self-research substitution” and “performance breakthroughs” in the automotive chip sector.
Related Articles
- Qualcomm Edge Generative AI: Hexagon NPU Architecture Innovation Achieves 98% Performance Improvement, 0.6 Seconds Image Generation, and 20 Tokens/s LLM Inference
- Comprehensive Deep Dive into Apple Silicon LLM Inference: The Ultimate Showdown from Performance to Cost with NVIDIA GPU!
- Guidance and Evaluation for Qwen2-VL-3B Model Deployment on Rockchip RK3576 Development Board NPU for Multimodal and Multi-turn Dialogue
From Apple’s 3nm A19 Pro reconstructing mobile AI computing power to Samsung’s 2nm chip racing for mass production; from Groq’s “three years to surpass NVIDIA” aggressive declaration to Huawei’s Atlas super node aiming for “global computing power first”; and to the open-source field’s 50% latency reduction semantic routing innovation, and the mass production breakthrough of domestic RISC-V compilers — this briefing condenses the most critical technological iterations, market trends, and ecological transformations in the global chip industry, with each dynamic rewriting the rules of industry competition, bringing you to the core battlefield of “giant struggles” and “domestic breakthroughs”.
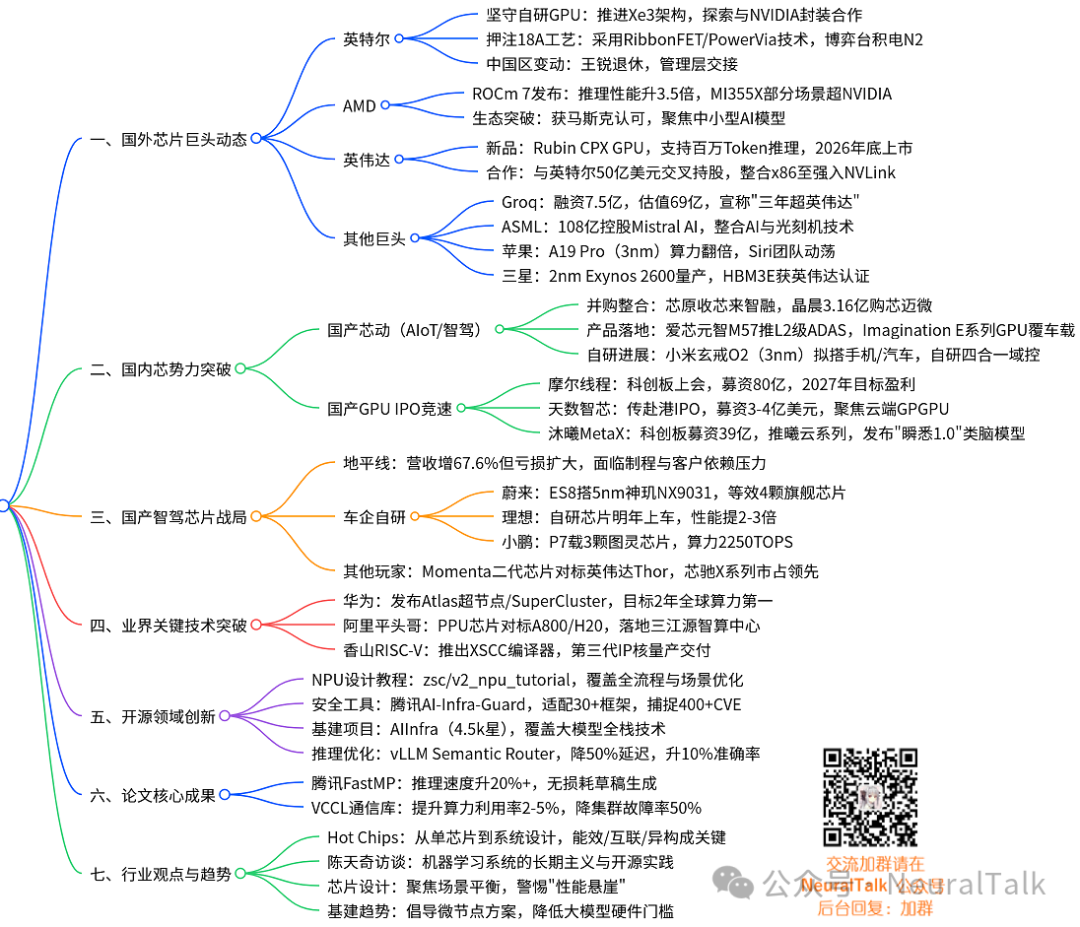
unsetunsetArticle Directoryunsetunset
- Article Directory
- 【International】Intel GPU’s Last Stand: Partnering with NVIDIA while Betting on the Life-and-Death of 18A Process
- 【Domestic】Mergers/IPO/Self-Research: Domestic Chip Dynamics in AIoT and Autonomous Driving, Four Giants Positioning for a New Battlefield
- 【Domestic GPU】Three Strong IPO Races, Brain-like Models Breaking Through Long Sequences
- 【Domestic Autonomous Driving】NIO/Xpeng’s New Cars Equipped with Self-Developed Chips, Horizon’s Revenue Growth but Expanding Losses
- 【Industry News】NVIDIA Rubin CPX, Huawei Super Node, Alibaba Pingtouge PPU, and Xiangshan RISC-V All Debut: Recent Key Breakthroughs in AI Chip Field
- 【Open Source】NPU Design Full Process Innovation Tutorial/AI-Infra-Guard/AIInfra
- 【Papers】Collective Communication Library VCCL, Tencent Lossless Generation Draft FastMP Technology
- 【Blog】Hot Chips Nine-Year Trend Evolution, Chen Tianqi Interview, Trade-offs in Chip Design, Infrastructure from Super Nodes to Micro Nodes
- Conclusion: The Chess Game of Computing Power Has No Regrets, but the Path to Breakthrough is Long and Difficult
For group discussions, please reply in the NeuralTalk WeChat public account: Join Group
unsetunset【International】Intel GPU’s Last Stand: Partnering with NVIDIA while Betting on the Life-and-Death of 18A Processunsetunset
- Intel: Officially Declares Not to Abandon Self-Developed GPU Product Line, collaborating with NVIDIA while advancing the Arc series and other layouts. In the future, Intel will also release the third generation Xe architecture Xe3 (codename Celestial), paired with Panther Lake CPU, with its graphics architecture and multi-chip packaging technology receiving attention, while also exploring potential collaborations with NVIDIA in packaging and other areas to maintain competitiveness in the GPU field.
- Intel: Absent from TSMC N2 Process Customer List, Betting on Self-Developed 18A Process for a “Comeback”. N2 is TSMC’s first large-scale production nanosheet architecture process, while Intel’s 18A adopts a more aggressive route, introducing RibbonFET (GAAFET implementation) and PowerVia back power supply network, pursuing a qualitative change in “performance per watt”, but the risks are extremely high: if the technology is realized, it can regain process credibility and restore market competition balance; if execution issues arise, TSMC’s N2 maturity may help AMD and NVIDIA seize advantages.
- Intel China: Announces Dr. Wang Rui, Chairman of the Board, Will Retire This Month, this is a planned management transition following the appointment of Wang Zhichong as Vice Chairman of Intel China in February this year, but the announcement did not clarify whether Wang Zhichong will succeed as Chairman.
- AMD: ROCm 7 Software Stack Appears with Version Tag on GitHub, ROCm 7 aims to break NVIDIA’s CUDA ecosystem monopoly, with inference performance improved by up to 3.5 times compared to ROCm 6, and training optimizations introduced. In demonstrations, AMD Instinct MI355X outperformed NVIDIA Blackwell B200 by about 30% in FP8 throughput under the DeepSeek R1 workload, highlighting the potential for hardware-software collaborative optimization.
- Musk: Evaluates AMD’s Small and Medium AI Models as “Quite Good”, but high-end training is still dominated by NVIDIA. His company xAI has deployed AMD Instinct MI300/MI300X accelerators but still chose NVIDIA for large-scale training.
- Huang Renxun: States Uncertainty on Whether to Use Intel for Foundry, NVIDIA and Intel’s $5 Billion Equity Cross-Transaction Strengthens Cooperation. Emphasizes that the core of this cooperation is to introduce Intel’s x86 Xeon processors into the NVLink ecosystem, allowing NVIDIA to fully leverage its advantages on x86 CPUs, while the PCIe-based NVL72 architecture can be expanded to NVL8, enhancing supercomputer scalability.
- Groq: AI Chip Company Formed by Google’s TPU Team Completes $750 Million Financing, with a valuation of $6.9 billion, doubling its valuation within a year. Its AI chip’s inference speed is claimed to be 10 times faster than NVIDIA’s GPU, with costs reduced by 90%, declaring “three years to surpass NVIDIA”.
- ASML: Invests $10.8 Billion to Acquire Major Model Company Mistral AI, Cooperation May Promote ASML’s Integration of AI Technology into Lithography Systems, leveraging Mistral’s AI capabilities to enhance process precision and production efficiency, while providing Mistral with massive training data in the semiconductor field.
- Apple: Releases the Most Powerful 3nm Mobile AI Chip A19 Pro, featuring a 6-core CPU + 6-core/5-core GPU design, with each GPU core integrating a neural network accelerator, achieving peak GPU performance three times that of A18 Pro, comparable to MacBook, suitable for running local large language models and other high-intensity tasks. Apple has recently faced turmoil in the AI field, with former Siri head and AKI senior director Robby Walker set to leave, who led the creation of the “Apple-style AI search experience” AKI team, and the highly anticipated new version of Siri’s personalized features has been postponed to spring 2026 due to testing quality issues.
- Qualcomm: Officially Announces the Fifth Generation Snapdragon 8 Supreme Edition as a New Member of the Flagship Mobile Platform, to Debut at the 2025 Snapdragon Summit. This naming represents the fifth generation of the Snapdragon 8 series flagship products, not a generational leap, but a continuation of the naming system. Last year’s Snapdragon 8 Supreme Edition introduced the self-developed Qualcomm Oryon CPU to reshape flagship performance, and this year will further upgrade.
- SiFive: In September 2025, SiFive Launches Second Generation Smart Series Processor IP, covering a full range from control cores to matrix engines. The product line adds the X100 small core (supporting 32/64-bit), suitable for embedded and low-power scenarios; high-performance X390 and XM series enhance matrix engine scale and computing power, targeting AI inference training.
- Samsung: 2nm Chip Exynos 2600 Set for Mass Production, commercializing Galaxy S26 eight months ahead of competitors, optimizing energy efficiency and heat dissipation through “thermal conduction blocking technology”, with GeekBench scores slightly ahead of Qualcomm Snapdragon 8 Elite.
- Samsung: Samsung Electronics’ 12-layer stacked HBM3E product has passed NVIDIA certification, Samsung claims that with 1c generation DRAM technology and 4nm logic chips, HBM4 products achieve a data transfer rate of 11Gbps, making it the first manufacturer to reach this standard in the industry, with future HBM4 supply systems expected to expand to AMD, Broadcom, Google, and others.
unsetunset【Domestic】Mergers/IPO/Self-Research: Domestic Chip Dynamics in AIoT and Autonomous Driving, Four Giants Positioning for a New Battlefieldunsetunset
- Chip Origin: Acquires RISC-V CPU IP Supplier Chip Lai Zhihong, after the acquisition, Chip Origin’s stock price hit the limit, and the market is optimistic. Chip Lai is one of the first domestic RISC-V CPU IP suppliers, performing outstandingly in the embedded AIoT market, with significant labor cost advantages, and was valued at 2.5 to 3 billion yuan before the acquisition.
- Allwinner Technology: Shanghai AIoT Chip Leader Allwinner Technology Acquires Chip Maiwei for 316 Million, Plans to Go Public in Hong Kong to Strengthen AIoT Layout. After the transaction is completed, Chip Maiwei will become its wholly-owned subsidiary. Allwinner Technology specializes in multimedia SoC chips and system-level solutions for various fields such as smart set-top boxes and smart TVs. This acquisition will help Allwinner Technology integrate communication technology, expand its technology in the AIoT and connectivity fields, and build a “cellular + optical + Wi-Fi” multi-dimensional communication technology stack, strengthening its product layout in smart cockpits, wearables, and other scenarios.
- AiChip: At the 2025 IAA Mobility Exhibition in Germany, showcasing a globalized assisted driving solution based on the M57 chip. This solution is a collaboration between AiChip and STRADVISION, using M57 as the main control chip, equipped with an 8-megapixel camera, deploying 3D visual perception algorithms, supporting static object, vehicle/pedestrian detection, etc., achieving L2-level ADAS, compatible with China’s new AEB regulations, and has secured mass production customers, expected to go into mass production in 2026. It will also showcase M57, M55H, M76H, and other automotive chips and series development platforms, with multiple partners presenting ADAS integrated machines and domain controllers based on its chips, helping AiChip accelerate the globalization of intelligent driving solutions.
- Imagination: At the D&R IP SoC 2025 Technology Conference, released the E series GPU. In edge AI, computing power covers 2 – 200 TOPS, supporting scenarios such as natural language processing and industrial vision. In the automotive field, the E series GPU collaborates with RISC-V, supporting multi-core expansion and hardware virtualization, capable of carrying up to 16 virtual machine tasks, significantly advantageous in smart cockpit chip scenarios, helping to build a software-defined automotive platform that achieves heterogeneous collaborative computing from instrumentation to autonomous driving.
- Xiaomi: The Most Powerful Self-Developed Chip Xuanjie O2 Exposed! Sticking to TSMC’s 3nm Process, Expected to Debut Next Year, Possibly First on Xiaomi 16S Pro. In addition, Xuanjie O2 may be applied to Xiaomi’s automotive sector, as Lei Jun has stated that if the second-generation Xuanjie experience exceeds expectations, it will be considered for vehicles, and Xiaomi is preparing to self-develop a four-in-one domain controller for the chip’s application in vehicles. The Xuanjie O1 released in the first half of this year is based on TSMC’s 3nm process, debuted on the Xiaomi 15S Pro, and adopts a “2+4+2+2” ten-core four-cluster design, covering both complex and low-power scenarios.
unsetunset【Domestic GPU】Three Strong IPO Races, Brain-like Models Breaking Through Long Sequencesunsetunset
- 【Moer Thread】 IPO on the Sci-Tech Innovation Board Next Week, Plans to Raise 8 Billion to Focus on Self-Controllable AI Chips, Invest in Next-Generation Self-Controllable AI Training and Inference Chips, Graphics Chips, and AI SoC Chip R&D and Supplement Working Capital. Moer Thread was established in 2020, receiving investments from Five Sources Capital, Sequoia China, and other institutions; revenue is expected to grow from 46 million in 2022 to 438 million in 2024 (a compound growth rate of 208.44%), with 702 million in revenue in the first half of 2025, but net losses attributable to the parent company during the same period were 1.84 billion, 1.673 billion, and 1.492 billion, with a loss of 271 million in the first half of 2025, expecting to achieve profitability by 2027. The company focuses on full-featured GPUs, aiming to become a leading GPU enterprise with international competitiveness, providing AI computing support for the industry’s digital transformation.
- 【Tianshu Zhixin】 Reportedly Going Public in Hong Kong, Plans to Raise $300 – 400 Million. Tianshu Zhixin was established in 2015 and is the first domestic provider of general-purpose GPU (GPGPU) cloud chips and computing systems, releasing the “Tianhai 100 chip” and accelerator cards in 2021, achieving mass production of general-purpose GPU chips, filling a domestic gap; in 2022, it launched the “Zhikai 100 series accelerator cards” to complete its product layout. The founding team comes from well-known companies like Trident and AMD, with experience in graphics card and machine vision chip R&D and mass production.
- 【Muxi MetaX】 IPO Progressing, Plans to Raise 3.9 Billion Yuan on the Sci-Tech Innovation Board, Focusing on AI Training, Inference, and General Computing, launching the Xiyun C, Xisi N, and Xicai G series products. The company was established in 2020, adopting a Fabless model, with the Xiyun C series being the main source of revenue (expected to contribute over 97% of revenue in 2024), with C500 already commercialized and deployed in intelligent computing centers, while C600 and C700 are under research; Xisi N focuses on inference acceleration, and Xicai G is positioned for graphics rendering. As of now, Muxi GPU has shipped over 25,000 units, with board revenue accounting for nearly 70%, and is adapting to domestic AI frameworks and open-source ecosystems. Although revenue is growing rapidly (from 426,400 yuan in 2022 to 320 million yuan in the first quarter of 2025), it has accumulated net losses exceeding 3 billion yuan, with tight cash flow, and relies on overseas for wafer foundry, HBM storage, and EDA tools.
- 【Muxi MetaX】 The Institute of Automation of the Chinese Academy of Sciences and Muxi jointly released the brain-like pulse large model “Shunxi 1.0”, achieving orders of magnitude acceleration in long sequence inference on domestic GPUs, completing the full process training inference on a thousand-card GPU computing power platform. This model is based on a “self-generated complexity” non-Transformer architecture, with a 7B version open-sourced and a 76B testing website available.
unsetunset【Domestic Autonomous Driving】NIO/Xpeng’s New Cars Equipped with Self-Developed Chips, Horizon’s Revenue Growth but Expanding Lossesunsetunset
- 【Horizon】 Revenue of 1.567 Billion Yuan in the First Half of 2025 (YoY Increase of 67.6%), but Losses Expanded to 5.233 Billion Yuan (Adjusted operating loss of 1.111 billion yuan, a year-on-year increase of 34.9%). The main reason for the losses is the increase in sales costs (up 177.13% to 543 million yuan) and R&D expenses (up 62% to 2.3 billion yuan). Technically, Horizon is still at the 7nm process, while Intel, Qualcomm, and NVIDIA have laid out 4nm/5nm, making it weak in high-end market competitiveness; on the market side, core customers like BYD and Li Auto are developing their own chips (e.g., Li Auto M100 has been tested in small batches), reducing dependence on it, and Horizon’s top five customers still account for over 52% of revenue, with a sharp drop in business volume from major customers (last year, two core customers accounted for over 60% of revenue, this year only 12%), squeezing profitability and revenue stability. The company is advancing the development of a full-scene urban auxiliary driving solution HSD, but faces dual pressures of technological iteration and market competition.
- 【NIO】 The All-New ES8 Launches, Equipped with the World’s First 5nm Autonomous Driving Chip Shenji NX9031, with performance equivalent to four flagship chips, supporting task concurrency and microsecond-level wake-up, with a processing capability of 6.5G Pixel/s (latency <5ms).
- 【Li Auto】 In Q2 2025, sales exceeded 111,000 units (ranking first among Chinese new energy brands with over 200,000 units), with revenue of 30.2 billion yuan (a quarter-on-quarter increase of 16.7%), and a net profit of 100 million yuan (a quarter-on-quarter increase of 69.6%), achieving profitability for 11 consecutive quarters, with cash reserves reaching 106.9 billion yuan. The company expects R&D expenses of 12 billion yuan for the year (with over 6 billion for AI), focusing on intelligence: in the autonomous driving field, advancing the VLA large model (similar to ChatGPT 4.0, supporting L3 – L5 level autonomous driving); self-developed chips have been taped out and will be applied in vehicles next year (doubling performance for large models, tripling for CNN); the smart cockpit “Li Auto Classmate” will evolve into an intelligent entity capable of autonomously completing complex tasks.
- 【Xpeng】 The All-New P7 Launches, Equipped with Three Self-Developed Turing Chips, with Computing Power Reaching 2250 TOPS, He Xiaopeng stated that they are conducting closed-loop R&D through chips, VLA models, VLM models, and application services, with the first major version of VLA to be pushed in September (for P7 and G7 Ultra versions), aiming for a tenfold improvement in intelligent assisted driving experience by the end of the year; in November, free upgrades of VLM software and hardware will be pushed, along with OTA updates.
- 【Momenta】 Domestic autonomous driving company Momenta’s market share reaches 60.1%, with reports of second-generation chip development in progress, performance targeting NVIDIA Thor, with a target price of 5000 yuan for the complete autonomous driving solution, using a “chip + solution” package to reduce costs.
- 【Chipstar】 Invited to the World New Energy Vehicle Conference on September 10, focusing on “Central Computing + Regional Control” architecture, providing automotive-grade chip solutions: the X10 AI cockpit chip released in April features 40 TOPS NPU computing power, 154 GB/s bandwidth, supporting 7B multimodal large models and multi-AI task collaboration; the X9 series has become the highest market share smart cockpit chip in the domestic market, covering over 50 vehicle models.
unsetunset【Industry News】NVIDIA Rubin CPX, Huawei Super Node, Alibaba Pingtouge PPU, and Xiangshan RISC-V All Debut: Recent Key Breakthroughs in AI Chip Fieldunsetunset
- NVIDIA’s Next-Generation GPU Rubin CPX Debuts: Single Card Supports Millions of Token Inference, Comprehensive Upgrades in Computing Power and Memory Bandwidth Summary: NVIDIA has released the Rubin CPX GPU designed for long context inference, capable of processing millions of tokens at once. This GPU, paired with Vera CPU and Rubin GPU, forms the Vera Rubin NVL144 CPX platform, providing 8 exaflops of AI computing power (7.5 times that of GB300 NVL72), equipped with 100TB of high-speed memory and 1.7 PB/s memory bandwidth. Technically, Rubin CPX achieves 30 petaflops of computing power based on NVFP4 precision, equipped with 128GB GDDR7 memory, with attention processing capability improved threefold compared to GB300 NVL72; combined with the SMART framework and decoupled inference architecture, it can efficiently support software development, video generation, and other long context tasks, expected to be launched by the end of 2026.
- Huawei AI Chip Plan: The World’s Strongest Super Node + Super Cluster, Fully Leading in the Next Two Years Summary: Huawei announced its AI chip-related plans at the Full Connect Conference, launching the Atlas 950/960 SuperPod super nodes (supporting 8192 and 15488 Ascend cards, respectively), SuperCluster super clusters (with computing power exceeding 500,000 cards and one million cards), and planning for the Ascend 950/960/970 series chips (e.g., Ascend 950R for inference, 950DT for training, using self-developed HBM), while also open-sourcing a new interconnection protocol. By integrating computing power through system architecture and interconnection technology, the Atlas 950 super node is expected to be launched in Q1 2026, maintaining global computing power first for the next two years, assisting in the development of AI infrastructure.
- Alibaba Pingtouge PPU AI Chip Featured on “News Broadcast”, Parameters Comparable to NVIDIA A800/H20 Summary: CCTV’s “News Broadcast” reported on China Unicom’s Sanjiangyuan Green Power Intelligent Computing Center, where domestic computing power involves several AI chip brands including Alibaba Pingtouge (ten thousand cards). Signed projects include 1747 devices, 22832 computing power cards, with a total computing power of 3479P; proposed signed projects have a computing power of 2002P. The Pingtouge PPU chip parameters were highlighted, using HBM2e memory (capacity 96GB), inter-chip bandwidth of 700GB/s, and power consumption of 400W, with several configurations exceeding NVIDIA A800, approaching H20. PPU is Alibaba’s self-developed AI chip, with a basic version (focusing on inference, peak computing power of 120TFLOPS) and an advanced version (focusing on training), previously used in Ant’s Bailing large model training.
- Domestic Xiangshan RISC-V Processor Launches Exclusive Compiler XSCC, Third Generation IP Core Achieves Mass Production Delivery Summary: The Xiangshan open-source community officially announced the launch of the Xiangshan Compiler (XSCC), which is based on the LLVM framework, focusing on memory access optimization, branch prediction improvements, and other micro-architecture-level performance enhancements, with version 1.0 already released on GitHub, supporting the generation of riscv64 target code, and can run on x86_64 hosts with Ubuntu 22.04 and above. Meanwhile, the third generation “Xiangshan” (Kunming Lake) IP core has achieved the first batch of mass production customer product-level delivery; a domestic mass-produced GPGPU chip integrating the second generation “Xiangshan” (Nanhu) IP core has been unveiled, with over ten thousand shipments of intelligent acceleration cards based on this chip, marking the large-scale application of the “Xiangshan” IP core, assisting in the development of the domestic RISC-V ecosystem.
unsetunset【Open Source】NPU Design Full Process Innovation Tutorial/AI-Infra-Guard/AIInfraunsetunset
- zsc/v2_npu_tutorial: NPU Design Full Process Innovation Tutorial: Focusing on 200 TOPS Inference Performance and 2:4 Structured Sparsity / nvfp4 Quantization, from Algorithm Mapping to RTL Implementation (Autonomous Driving & Embodied Intelligence Scenarios) Summary: This tutorial focuses on the full process of neural network processor (NPU) design, with a core goal of 200 TOPS inference performance, targeting scenarios in autonomous driving (perception/prediction/planning networks) and embodied intelligence (VLM/VLA models), deeply integrating 2:4 structured sparsity and nvfp4 (E2M1) quantization technology. The course innovatively compares the two architectures of pulse arrays (using TPU as an example) and data flow (using Groq TSP as an example), systematically covering algorithm operator analysis, storage data flow design, RTL implementation, compiler mapping, multi-core interconnection, and performance optimization. Aimed at deep learning engineers, IC designers, and others, combined with rooftop line models, operator fusion, NoC bandwidth calculations, and other practices, with accompanying code repositories and FPGA simulation platforms, helping learners master the core technologies of the entire process from algorithm upstream to chip deployment, solving the balance of latency, throughput, and energy efficiency in practical scenarios. For writing methods and more books, see here: https://zhuanlan.zhihu.com/p/1932021734954997646
- Tencent/AI-Infra-Guard: Nearly 400 CVE Vulnerabilities Accurately Captured! Tencent AI-Infra-Guard: 30+ AI Framework Adaptation + Jailbreak Assessment, 1.7k Star Intelligent Red Team Platform Open Source is Here Summary: AI-Infra-Guard (A.I.G) is a comprehensive, intelligent, and user-friendly AI red team platform developed by Tencent’s Zhuque Laboratory, receiving 1.7k stars and 191 forks on GitHub. Its core capabilities cover three major modules: first, AI infrastructure vulnerability scanning, supporting over 30 frameworks including Ollama, covering nearly 400 known CVEs; second, MCP server risk scanning, driven by AI Agents, capable of detecting nine categories of security risks; third, LLM jailbreak assessment, quickly generating assessment reports based on various selected datasets. For deployment, the project supports one-click installation via Docker (including scripts for automatic Docker installation), or pulling pre-built images or source builds, natively adapting to Mac M2 ARM, requiring 4GB+ memory and 10GB+ disk. The platform adopts a scalable plugin framework, allowing the community to contribute fingerprint rules, vulnerability rules, etc., and is open-sourced under the MIT license, with documentation available in both Chinese and English versions.
- Infrasys-AI/AIInfra: 4.5k Star Open Source Project AIInfra: Full-Stack Infrastructure Innovation Practice for Large Models, 7 Core Modules + 47 Contributors Building Training and Inference Technology System Summary: AIInfra is an open-source AI infrastructure project launched by Infrasys-AI, focusing on full-stack software and hardware technology for large models, supporting large model training and inference from underlying chips to upper software stacks. The project includes seven core modules (overview of large model systems, AI computing clusters, etc.), with accompanying Jupyter practical code, PPT, and videos on Bilibili/YouTube, with 47 contributors participating in the construction, receiving 4.5k stars and 623 forks, with resource scale reaching 10G. Its innovation lies in distinguishing itself from the AISystem project, deeply exploring distributed clusters for large models, training and inference algorithms, covering cutting-edge directions such as Flash Attention, MoE architecture, RAG, etc., providing complete content from theoretical analysis to engineering practice, helping developers master large model system design, and promoting the open-source sharing and application of AI infrastructure technology.
- vLLM Semantic Router: Open Source Semantic Routing Innovation for LLM Inference, Achieving 50% Latency Reduction and 10% Accuracy Improvement Address: https://blog.vllm.ai/2025/09/11/semantic-router.html Summary: The current LLM inference field has shifted from “pursuing scale” to “efficiency and precise computation”, with GPT-5, Claude 3.7, etc., optimizing performance through differentiated routing. To this end, vLLM has launched the open-source Semantic Router, filling the semantic decision-making gap in the vLLM engine, addressing the pain points of “high costs for full activation inference and low accuracy for full deactivation inference”. This routing system is centered around four pillars: using ModernBERT for semantic classification, dividing into “fast path” and “Chain-of-Thought path” based on query complexity, building a high-performance engine based on Rust+Hugging Face Candle, supporting Kubernetes and Envoy cloud-native integration. Trials show that it achieves about a 10% accuracy improvement, 50% latency reduction, and 50% token reduction, with accuracy improvements exceeding 20% in commercial economic fields. The project originates from open-source community collaboration and will be showcased at KubeCon North America 2025, currently focusing on working groups and the v0.1 roadmap (including ExtProc modularization, semantic caching, etc.). Future plans include achieving pluggable classifiers/embedding models, promoting LLM inference to evolve towards “instant adaptation strategies”, providing intelligent and efficient inference solutions for open-source LLM.
unsetunset【Papers】Collective Communication Library VCCL, Tencent Lossless Generation Draft FastMP Technologyunsetunset
- Tencent FastMP Technology Analysis: Boosting Inference Speed by 20%+, Lossless Generation Draft Can Also Validate Accurately Code: https://github.com/Tencent-BAC/FastMTP Paper: https://github.com/Tencent-BAC/FastMTP/blob/main/FastMTP_technical_report.pdf Summary: Tencent proposed FastMP technology, focusing on accelerating large model inference, with the core being the process of generating “drafts” and validating them to improve efficiency. It is based on the EAGLE concept improvement, making MP (multi-prediction) more efficient during inference, optimizing training strategies (such as simulating inference scene training, exponential decay loss functions, main model self-distillation, etc.), and language-aware compression for “high filler word ratio”. Tests show that FastMP improves inference speed by an average of over 20% on tasks such as coding, translation, and knowledge Q&A, with the acceleration effect being more significant in tasks that are more regular and structured, while also having the advantage of “running regardless of correctness first”, providing a new path for optimizing large model inference efficiency.
- Collective Communication Library VCCL Releases Extreme GPU Computing Power, Co-Developed by Chuangzhi, Jiliu, Zhipu, Unicom, Beihang, Tsinghua, and Southeast University | Machine Heart Code: https://github.com/sii-research/VCCL Summary: Chuangzhi, Jiliu, Zhipu, Unicom, Beihang, Tsinghua, and Southeast University jointly open-source the GPU Collective Communication Library VCCL (Venus Collective Communication Library). VCCL serves as the “nervous system” of intelligent computing clusters, developed based on NCCL, enhancing communication efficiency and system stability through three core designs: DPDK-like P2P intelligent scheduling, Primary-backup QP fault tolerance, and Flow Telemetry microsecond-level traffic observation: improving the computing power utilization rate of dense model training by 2-5%, reducing cluster failure rates by over 50%, and accurately capturing changes in communication rates during training. Currently, VCCL has been deployed in multiple production environment clusters, helping ultra-large-scale GPU clusters break through computing and communication bottlenecks.
unsetunset【Blog】Hot Chips Nine-Year Trend Evolution, Chen Tianqi Interview, Trade-offs in Chip Design, Infrastructure from Super Nodes to Micro Nodesunsetunset
- Hot Chips Reveals AI Computing Power Leap: From Single Chip to System Design, Energy Efficiency, Interconnect, and Heterogeneity Become Key to Technological Breakthroughs | Biran Technology Research Institute Summary: The Hot Chips conference showcases the development trajectory of AI computing power, shifting from early single-chip performance competition to breakthroughs in system-level design. In terms of energy efficiency, through architectural optimization (such as explosive processors, heterogeneous collaboration), AI computing power efficiency has improved by over 35%, while costs continue to decline; breakthroughs in interconnect technology, such as NVSwitch and Grace Hopper super chip’s high-speed interconnect solutions, solve multi-chip expansion and data transmission bottlenecks; heterogeneous computing has become a trend, with deep integration of GPU, NPU, RISC-V, and other architectures, adapting to full-scene AI needs from edge (2TOPS) to cloud (200TOPS+). In addition, innovations in packaging and cooling technologies (such as liquid cooling, 3D stacking) support the stable operation of high-computing power chips, with innovative solutions from multiple manufacturers (NVIDIA, Intel, Huawei, etc.) driving AI from the laboratory to large-scale commercial landing, providing a computing power base for large model training, autonomous driving, and other scenarios.
- Chen Tianqi: Machine Learning Systems, Long-termism, Original Intention, XGBoost, MXNet, TVM, MLC LLM, OctoML, CMU, UW, ACM Class Address: https://www.bilibili.com/video/BV1s6pgzLE3y/ Summary: Chen Tianqi has been on the path of machine learning systems for nearly 20 years — what will the scenery look like from Chen Tianqi’s perspective over these 20 years of turbulence? In this podcast, you will hear:
- Chen Tianqi and I will break down each of his open-source projects — why they were born, how they grew, and where they turned.
- We will also delve into Chen Tianqi’s personal experiences — how he encountered computers at a young age, how he self-taught compiler writing in high school, the foundational knowledge he built in the ACM class at Jiaotong University, his research breakthroughs at UW, and ultimately walking both entrepreneurial and academic paths.
- More importantly, we also discuss Chen Tianqi’s underlying values — how to implement long-termism, how to maintain the courage to fail and the original intention in uncertainty. After achieving success in research, entrepreneurship, and academia, what is Chen Tianqi planning for the next step?
- Analyzing Trade-offs in Chip Design: From GPGPU to Network Cards, Balancing Computing Power and Scenarios | zartbot Summary: The article explores trade-offs in chip design, using B100 and H100 as examples, pointing out that single chips are constrained by maximum die size (<850mm²), with B100 increasing TMEM to leverage TensorCore performance, resulting in a reduction in CUDA Core’s SM, causing performance in some scenarios to be inferior to H100. It also mentions that domestic chips often pursue common functional performance, leading to “performance cliffs” in complex scenarios, and AI accelerators face similar issues. It also analyzes changes in the AI accelerator market (such as BRCM winning large orders, Google TPU capacity enhancement) and discussions on domestic CUDA compatibility, with future explorations from GPGPU, NPU, network cards, DPU, etc., to deeply discuss physical constraints of computing power chips, Chiplet, interconnect, and software architecture design trade-offs.
- From Super Nodes to Micro Nodes: What Infrastructure Do Large Models Need? Address: https://zhuanlan.zhihu.com/p/1952744774143542334 Summary: This article focuses on the trade-offs in building infrastructure for large models, criticizing the super node approach and advocating for the micro node solution. Large models have limited interconnect needs, and an 8-card NVLink domain can meet the requirements with low-speed networks, while super nodes (like NVL72) are comparable in computing power to similarly sized clusters but increase ineffective interconnect costs, which is not a cost-reduction path. The core cost lies in memory, with expensive HBM forming a high-cost closed loop, while cheaper media like DDR and Flash offer better cost-performance ratios. MOE model needs fall into the DDR sweet spot, promoting the development of “micro nodes”. The author’s team “Brown Ant” and “Ant Colony” prototypes (DDR5 + RTX 5090) validate its feasibility, potentially lowering hardware thresholds to the thousand-yuan level, facilitating the accessibility of large models.
unsetunsetConclusion: The Chess Game of Computing Power Has No Regrets, but the Path to Breakthrough is Long and Difficultunsetunset
As Intel bets on the “life-and-death game” of the 18A process and Huawei’s Atlas super node makes its “summit declaration” on the same track, as NVIDIA’s ecological moat collides fiercely with AMD and Groq’s breakthrough blades, and as domestic GPU companies rush for IPO with hundreds of billions in funding demands, while automotive companies rewrite supply chain discourse power with self-developed chips — this global AI chip race has long surpassed mere technical competition, becoming a comprehensive game concerning process evolution, ecological construction, and industry chain resilience.
The logic of the global arena is becoming increasingly clear: giants are seeking balance between “aggressive processes” and “ecological barriers”, with Intel’s RibbonFET technology and NVIDIA’s Rubin CPX long context inference capabilities, fundamentally using underlying innovations to consolidate industry discourse power; while ASML’s acquisition of Mistral AI’s cross-border layout further reveals a new paradigm of “lithography + large models” in the industry chain. Each breakthrough in technical parameters (such as Samsung’s 2nm mass production, HBM4 rate standards) and each progress in ecological adaptation (such as ROCm 7 performance leap) are reshaping the boundaries of computing power competition.
For group discussions, please reply in the NeuralTalk WeChat public account: Join Group
The breakthroughs of domestic forces show characteristics of “multiple blossoms and deep breakthroughs”:
- The IPO races of Moer Thread and Muxi are a necessary choice to leverage capital power for technological breakthroughs;
- Xiaomi’s adherence to 3nm with Xuanjie O2 and NIO’s implementation of 5nm with Shenji NX9031 mark the turn of domestic chips from “following” to “leading”;
- The mass production delivery of the Xiangshan compiler and the efficiency innovation of vLLM semantic routing further make open source an important support for breaking technological monopolies.
Even though challenges such as HBM dependence and ecological adaptation remain, every step of exploration from “supplementing the chain” to “strengthening the chain” is solidifying the foundation for autonomous computing power.
From the “system-level design shift” revealed at the Hot Chips conference to the extreme pursuit of efficiency in technologies like Tencent’s FastMP and VCCL, the industry has reached a consensus: the ultimate of computing power competition is not the performance limit of a single chip, but the full-chain collaboration of “chip-architecture-ecology-infrastructure”. As Huawei’s super node, Alibaba’s PPU, and NVIDIA’s cluster solutions compete on the same stage, and as domestic RISC-V competes with x86 and ARM architectures in different scenarios, a new pattern of “multi-dimensional computing power coexistence” is taking shape.
In this chess game, there are no eternal winners, but there are unchanging rules — technological innovation is the core of breakthroughs, ecological maturity is the foundation for standing firm, and industry chain resilience is the confidence to traverse cycles. Whether it is the giants’ “last stand” or the domestic forces’ “step-by-step approach”, every move is rewriting the map of global computing power. The future has arrived, and the story of computing power continues to be written, while those who adhere to R&D and deeply cultivate the ecosystem will ultimately define the new industry future in this transformation.