Article Overview
1. Research Background and Challenges
– Training models on devices can adapt to new data and protect privacy.
– IoT devices have limited memory resources, and training consumes too much memory.
– Existing deep learning frameworks are not suitable for edge devices.
2. Algorithm System Design
– Proposed Quantization-Aware Scaling (QAS) for stable 8-bit quantized training.
– Developed Sparse Update to skip gradient calculations for unimportant layers.
– Designed Tiny Training Engine (TTE) to support sparse updates and automatic differentiation at compile time.
3. Experimental Results
– Achieved convolutional neural network training under 256KB SRAM and 1MB Flash.
– Reduced training memory to 141KB, with accuracy comparable to cloud training.
– Successfully deployed on the Cortex M7 microcontroller to validate feasibility.
4. Optimization and Contribution Analysis
– QAS effectively addresses the challenge of optimizing quantized graphs, improving training stability.
– Sparse updates automatically select the best update scheme through contribution analysis.
– Operator reordering reduces memory usage and improves training speed.
5. Experimental Setup and Results
– Experiments conducted using MobileNetV2, ProxylessNAS, and MCUNet models.
– Evaluated transfer learning accuracy on multiple downstream datasets.
– Compared accuracy and memory consumption of different update strategies.
6. Related Research and Future Work
– Summarized the current research status of efficient transfer learning, system design, and deep learning on microcontrollers.
– Looked forward to future work, including expansion to other modalities and models.
– Discussed the limitations of the research and its societal impacts.

Article link: https://arxiv.org/pdf/2206.15472
Project link: https://github.com/mit-han-lab/tiny-training

TL;DR
Article Method
The article proposes an algorithm-system co-design framework for on-device training to address the limited memory resources of IoT devices.
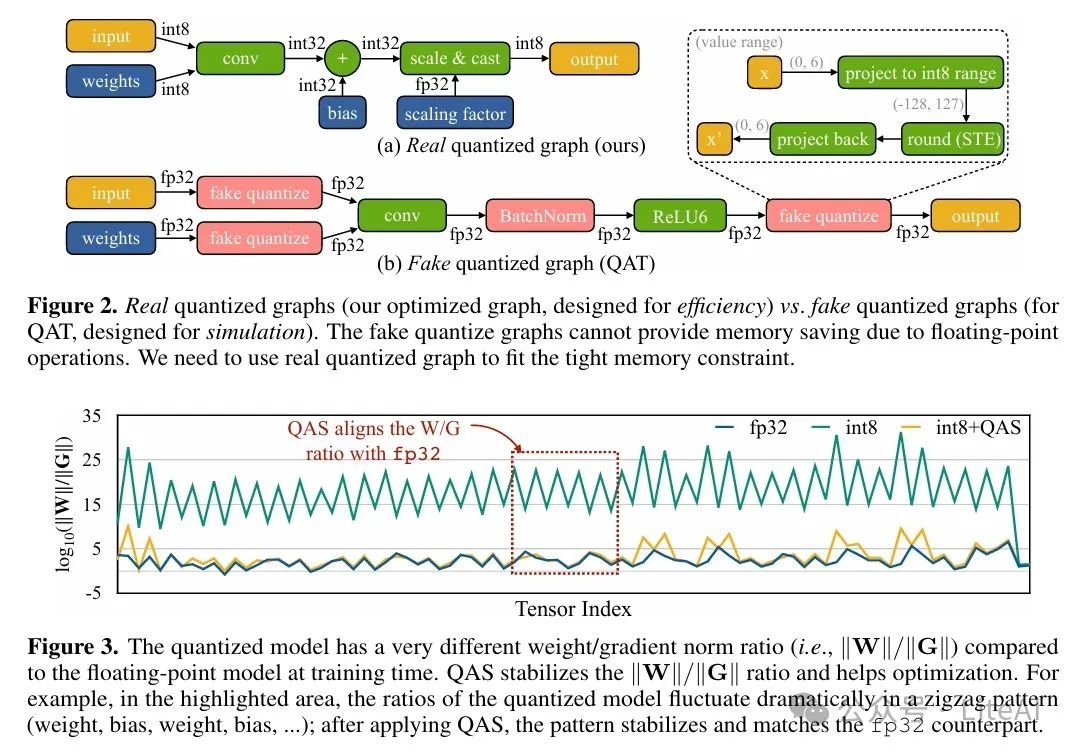
1. Quantization-Aware Scaling (QAS):
– Challenge: The quantized neural network graph is difficult to optimize due to low-precision tensors and lack of Batch Normalization layers.
– Solution: QAS stabilizes the training process by automatically adjusting the gradient ratios of tensors with different bit precisions. The formula is as follows:
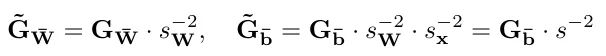
Where, s_W and s_x are the scaling factors for weights and inputs, respectively.
2. Sparse Update:
– Challenge: The memory usage of full backpropagation can easily exceed the SRAM of microcontrollers.
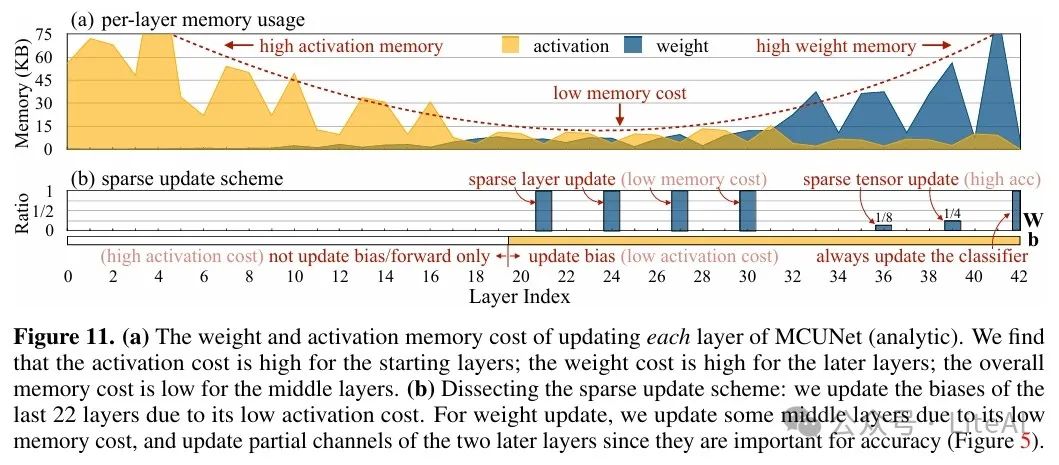
– Solution: Reduce memory consumption by skipping gradient calculations for unimportant layers and sub-tensors. Specific methods include:
1. Bias Update: Only update bias parameters since the cost of updating biases is low.
2. Sparse Layer Update: Select a subset of layers for weight updates.
3. Sparse Tensor Update: Further allow updating a portion of the channels of the weight tensor to reduce cost.
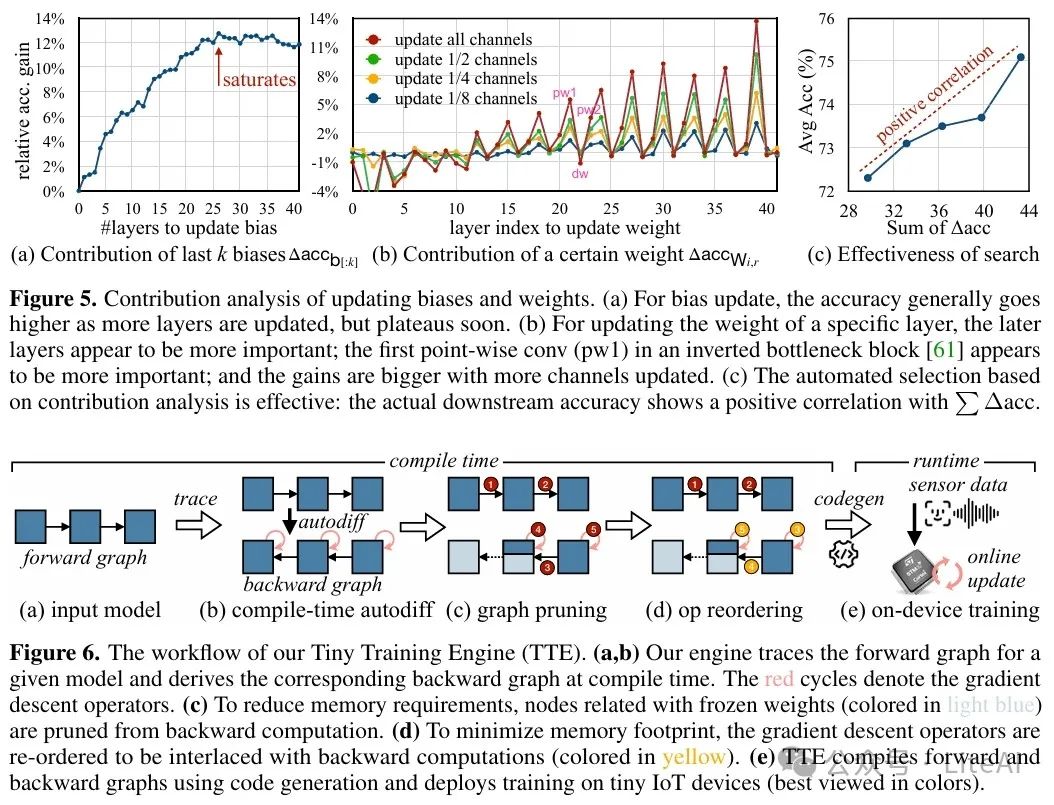
3. Contribution Analysis:
– Method: Automatically derive sparse update schemes by analyzing the contribution of each parameter (weight/bias) to downstream accuracy to decide which parameters to update.
– The optimization problem is:
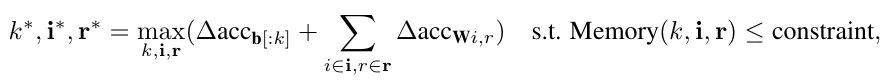
Where, k is the number of layers for bias updates, i is the index set of layers for weight updates, and r is the update ratio.
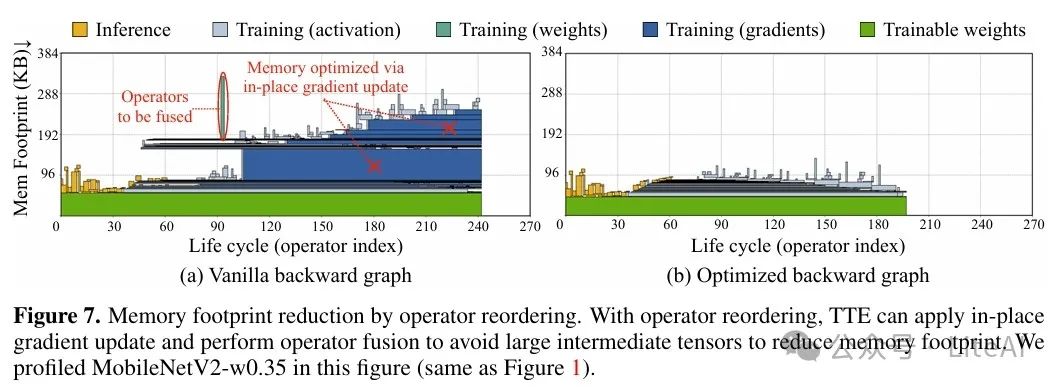
4. Tiny Training Engine (TTE):
– Compile-time automatic differentiation and code generation: Transfers automatic differentiation from runtime to compile time, generating a static backward graph for pruning and optimization, reducing memory and computational overhead.
– Backward graph pruning: Prunes redundant nodes, keeping only the nodes for bias updates and sparse layer updates.
– Operator reordering and in-place updates: Achieves in-place gradient updates and operator fusion by reordering operators, reducing memory usage.
Through the above methods, the article achieves convolutional neural network training on microcontrollers with 256KB SRAM and 1MB Flash while maintaining accuracy comparable to cloud training.
Evaluation Results
The experimental results of the article mainly demonstrate the effectiveness of achieving efficient on-device training under limited memory conditions.
1. Effectiveness of Quantization-Aware Scaling (QAS):
– After using QAS, the training accuracy of the quantized model is comparable to that of the floating-point model, compensating for the accuracy gap in quantized training. For example, in the MCUNet model, using QAS improved accuracy from 64.9% to 73.5%.
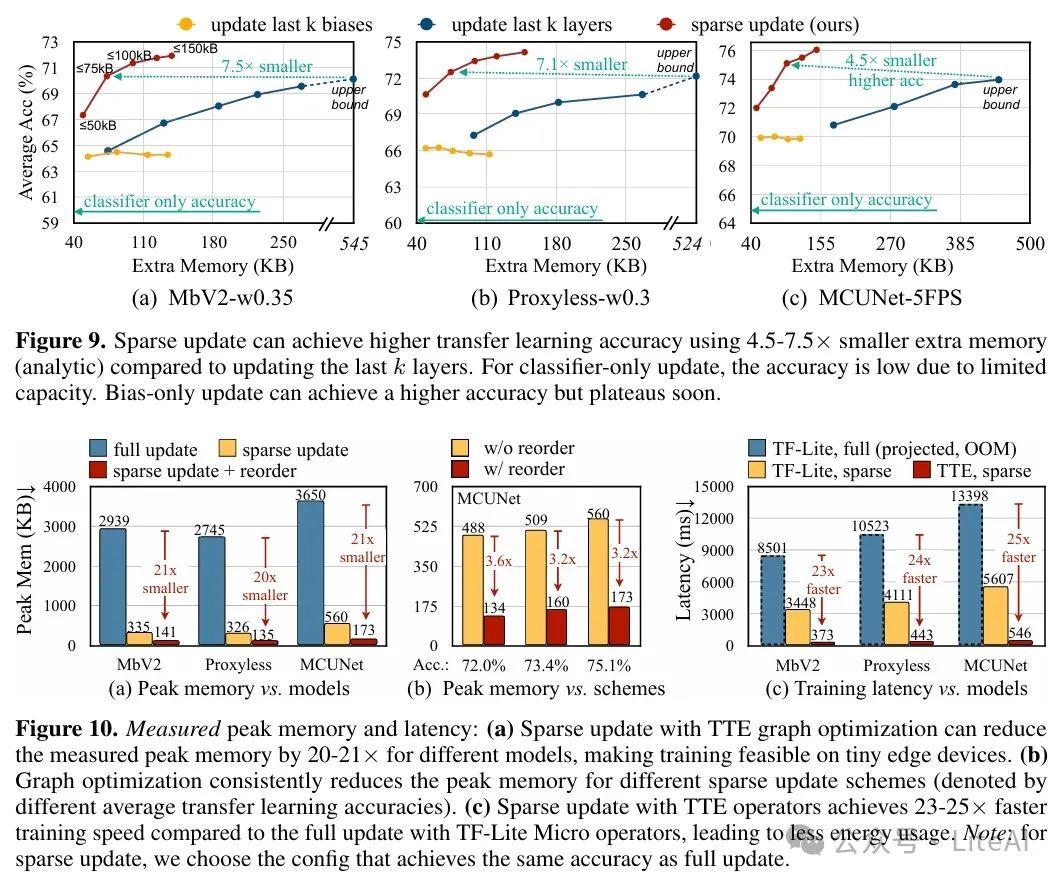
2. Effectiveness of Sparse Updates:
– Sparse updates achieved higher downstream task accuracy with lower memory consumption. For instance, compared to updating the last k layers, sparse updates achieved higher accuracy on the MCUNet model using less memory.
3. Performance of Tiny Training Engine (TTE):
– TTE significantly reduced training memory and latency through compile-time automatic differentiation and operator reordering. For example, on the STM32F746 microcontroller, TTE reduced training memory by 20-21 times and improved training speed by 23-25 times.
4. Comparison of Accuracy with Cloud Training:
– The method in the article achieved accuracy comparable to cloud training on multiple downstream datasets. For example, on the VWW dataset, the method achieved a top-1 accuracy of 89.1%, exceeding the 88.7% accuracy of MCUNet.
5. Effectiveness of Contribution Analysis:
– Contribution analysis effectively guided the selection of sparse update schemes. Experimental results showed that the update schemes selected through contribution analysis performed excellently in actual downstream tasks, validating the effectiveness of the method.
Final Thoughts
Scan the code to add me, or add WeChat (ID: LiteAI01) for exchanges on technology, career, and career planning. Please note “Research Direction + School/Region + Name”