
Tiny Machine Learning (TinyML) is the new frontier of machine learning. By compressing deep learning models into billions of Internet of Things (IoT) devices and microcontrollers (MCUs), we expand the scope of AI applications and achieve ubiquitous intelligence. However, due to hardware limitations, TinyML faces challenges: the tiny memory resources make it difficult to accommodate deep learning models designed for cloud and mobile platforms. For bare-metal devices, support for compilers and inference engines is also limited. Therefore, we need to collaboratively design algorithms and system stacks to enable TinyML. In this review, we will first discuss the definition, challenges, and applications of TinyML. Then, we will investigate the recent advances in deep learning on TinyML and MCUs. Next, we will introduce MCUNet, showcasing how we implement ImageNet-scale AI applications on IoT devices through system-algorithm co-design. We will further extend the solutions from inference to training and introduce techniques for on-device training. Finally, we propose future directions for this field. Today’s “large” models may become tomorrow’s “tiny” models. The scope of TinyML should evolve and adapt over time.
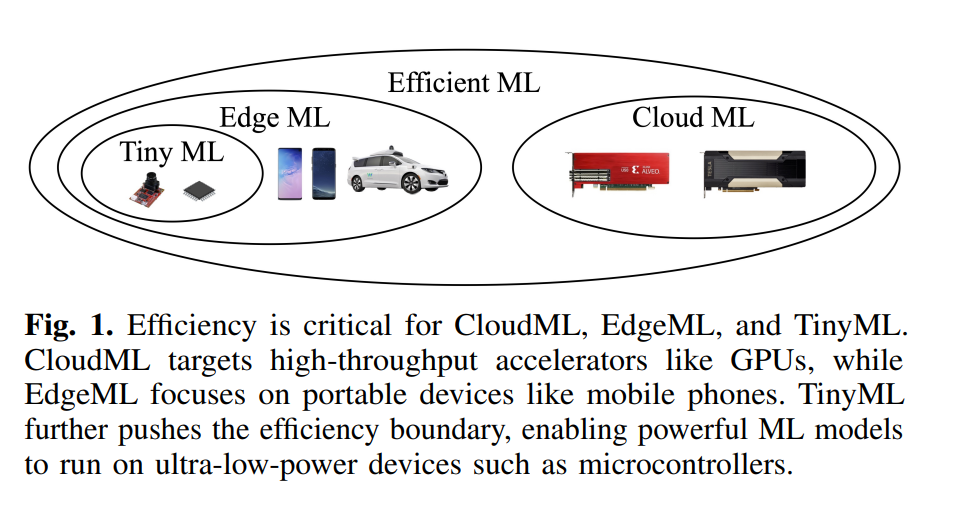
Machine Learning (ML) has had a significant impact on various fields, including vision, language, and audio. However, state-of-the-art models often come at the cost of high computation and memory consumption, making their deployment costly. To address this issue, researchers have been exploring efficient algorithms, systems, and hardware to reduce the cost of machine learning models in various deployment scenarios. Efficient ML has two main subfields: EdgeML and CloudML (Figure 1). CloudML focuses on improving latency and throughput on cloud servers, while EdgeML aims to enhance energy efficiency, latency, and privacy on edge devices. These two fields also intersect in areas such as hybrid inference, over-the-air (OTA) updates, and federated learning between edge and cloud. In recent years, the application scope of EdgeML has expanded to ultra-low-power devices, such as IoT devices and microcontrollers, referred to as TinyML.
TinyML offers several key advantages. It enables machine learning to operate with only a few hundred KB of memory, significantly reducing costs. As billions of IoT devices generate more and more data in our daily lives, the demand for low-power, always-on AI on-device is growing. By performing on-device inference near the sensors, TinyML can enhance responsiveness and privacy while reducing energy costs associated with wireless communication. For applications where real-time decision-making is crucial, such as autonomous vehicles, processing data on-device can be beneficial. In addition to inference, we are also pushing the frontier of TinyML to achieve on-device training on IoT devices, revolutionizing EdgeAI through continuous and lifelong learning. Edge devices can fine-tune models on their own without transferring data to cloud servers, thus protecting privacy. On-device learning has many benefits and various applications. For example, home cameras can continuously recognize new faces, and email clients can gradually improve their predictions by updating customized language models. It also allows IoT applications that are not physically connected to the internet to adapt to their environments, such as precision agriculture and marine sensing.
In this review, we will first discuss the definition and challenges of TinyML, analyzing why we cannot directly scale mobile ML or cloud ML models to TinyML. Then, we will delve into the importance of system-algorithm co-design in TinyML. Next, we will survey recent literature and advancements in the field, presenting a comprehensive review and comparison in Tables II and III. We will then introduce our TinyML project MCUNet, which combines efficient system and algorithm design to achieve TinyML from inference to training. Finally, we will discuss several emerging topics for future research directions in this field.
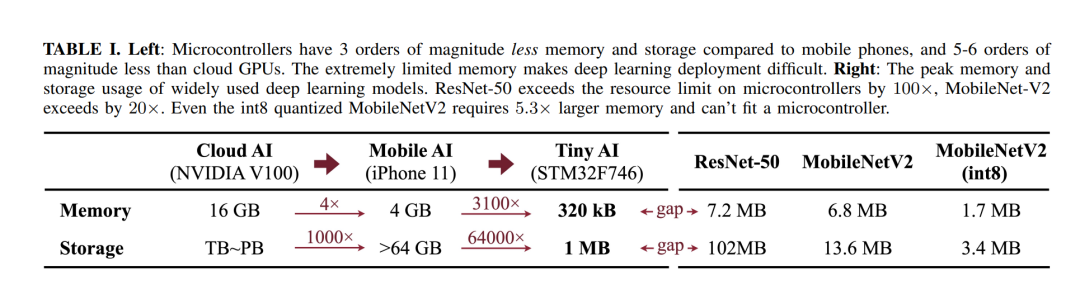
A. Challenges of TinyML The success of deep learning models often comes at a high computational cost, which is not feasible for devices (such as microcontrollers) that cannot use TinyML applications due to strict resource constraints. Deploying and training AI models on MCUs is extremely challenging: there is no DRAM, no operating system (OS), and strict memory limits (SRAM less than 256kB, FLASH read-only). The resources available on these devices are several orders of magnitude smaller than those available on mobile platforms (see Table I). Previous work in this field either (I) focused on reducing model parameters without addressing the real bottleneck of activations, or (II) only optimized operator kernels without considering improvements in network architecture design. Both approaches did not consider the problem from a co-design perspective, leading to suboptimal solutions for TinyML applications. We observe several unique challenges of TinyML and speculate on how they might be overcome: 1) Models designed for mobile platforms are not suitable for TinyML; 2) Directly adapting models for inference does not work for tiny training; 3) TinyML requires co-design.

B. Applications of TinyML By bringing expensive deep learning models to IoT devices, TinyML has many practical applications. Some example applications include:
-
Personalized healthcare: TinyML can enable wearable devices, such as smartwatches, to continuously track users’ activity and oxygen saturation levels to provide health advice. Body posture estimation is also a critical application for elderly healthcare.
-
Wearable applications: TinyML can assist people in using wearable or IoT devices for voice applications, such as keyword recognition, automatic speech recognition, and speaker verification.
-
Smart homes: TinyML can enable object detection, image recognition, and facial detection on IoT devices to build smart environments, such as smart homes and hospitals.
-
Human-computer interfaces: TinyML can enable human-computer interface applications, such as gesture recognition. TinyML can also predict and recognize sign language.
-
Smart vehicles and traffic: TinyML can perform object detection, lane detection, and decision-making without cloud connectivity, achieving high accuracy and low latency results for autonomous driving scenarios.
-
Anomaly detection: TinyML can enable robots and sensors to perform anomaly detection, reducing the need for human labor.
-
Ecology and agriculture: TinyML can also assist ecological, agricultural, environmental, and phenotyping applications to protect endangered species or predict weather events. Overall, the potential applications of TinyML are diverse and numerous, and as the field continues to advance, these applications will expand.
TinyML Progress
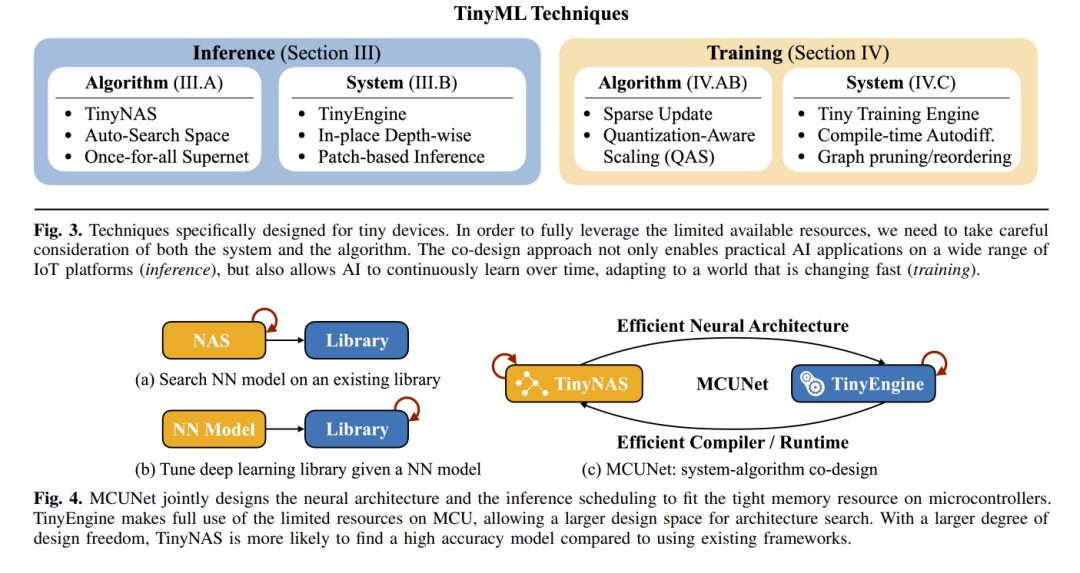
A. Recent Advances in TinyML Inference
In recent years, TinyML and its deep learning on microcontrollers (MCUs) have rapidly grown in both industry and academia. The main challenge of deploying deep learning models for inference on MCUs is the limited memory and computational capabilities available on these devices. For example, a popular ARM Cortex-M7 MCU, the STM32F746, has only 320KB of SRAM and 1MB of flash memory. In deep learning scenarios, SRAM limits the size of activations (reads/writes), while flash memory limits the size of the model (read-only). Additionally, the processor clock speed of the STM32F746 is 216 MHz, which is 10 to 20 times lower than that of a laptop. To enable deep learning inference on MCUs, researchers have proposed various designs and solutions to address these issues. Table II summarizes the latest relevant research targeting MCUs, including algorithmic solutions and system solutions. In Table III, we measure three different metrics (latency, peak memory, and flash usage) of four representative related studies (i.e., CMSIS-NN, X-Cube-AI, TinyEngine, and TFLite Micro) on the same MCU (STM32H743) and the same datasets (VWW and Imagenet) to provide a more accurate and transparent comparison.
a) Algorithmic Solutions
The efficiency of neural networks is crucial for the overall performance of deep learning systems. Reducing complexity by removing redundancy and through pruning and quantization is two popular methods to improve network efficiency. Tensor decomposition is also an effective compression technique. To enhance network efficiency, knowledge distillation is also a method of transferring learned knowledge from one teacher model to another student model. Another approach is to directly design small and efficient network architectures. Recently, neural architecture search (NAS) has dominated the design of efficient networks.
To make deep learning feasible on MCUs, researchers have proposed various algorithmic solutions. Rusci et al. proposed a rule-based quantization strategy that reduces memory usage by minimizing the bit precision of activations and weights. Depending on the memory constraints of various devices, this method can quantize activations and weights to mixed precision of 8-bit, 4-bit, or 2-bit. On the other hand, while NAS has achieved success in finding efficient network architectures, its effectiveness is highly dependent on the quality of the search space. For memory-constrained MCUs, standard model designs and appropriate search spaces are particularly lacking. To address this issue, TinyNAS, proposed as part of MCUNet, employs a two-step NAS strategy to optimize the search space based on available resources. TinyNAS then specializes the network architecture within the optimized search space, allowing it to automatically handle various constraints (such as device, latency, energy, memory) at low search costs. MicroNets observed that the inference latency of networks in the NAS search space is linearly related to the number of FLOPs in the model. Therefore, it proposed differentiated NAS, using FLOPs as a proxy for latency to achieve low memory consumption and high speed. MCUNetV2 identified that in most convolutional neural network designs, imbalanced memory distribution is a major memory bottleneck, where the memory usage of the first few blocks is an order of magnitude larger than the rest of the network. Therefore, this study proposed receptive field redistribution, shifting the receptive field and FLOPs to later stages, reducing the computational overhead of the halo. To minimize the difficulty of manually redistributing receptive fields, this study also automated the neural architecture search process to optimize both the neural architecture and inference scheduling simultaneously. UDC explored a broader design search space to generate compressible high-precision neural networks suitable for neural processing units (NPUs), addressing memory issues by leveraging a wider range of weight quantization and sparsity.
b) System Solutions
In recent years, popular training frameworks such as PyTorch, TensorFlow, MXNet, and JAX have contributed to the success of deep learning. However, these frameworks often rely on host languages (e.g., Python) and various runtime systems, which add significant overhead and make them incompatible with tiny edge devices. Emerging frameworks such as TVM, TF-Lite, MNN, NCNN, TensorRT, and OpenVino provide lightweight runtime systems for edge devices (such as mobile phones), but they are not small enough for MCUs. These frameworks cannot accommodate the memory-constrained IoT devices and MCUs.
CMSIS-NN implements optimized kernels to improve the inference speed of deep learning models on ARM Cortex-M processors, minimizing memory usage and enhancing energy efficiency. X-Cube-AI, designed by STMicroelectronics, supports the automatic conversion of pre-trained deep learning models to run on STM MCUs and provides an optimized kernel library. TVM and AutoTVM also support microcontrollers (referred to as µTVM/microTVM). Compilation techniques can also be used to reduce memory requirements. For example, Stoutchinin et al. proposed improving deep learning performance on MCUs by optimizing convolution loop nesting. Liberis et al. and Ahn et al. proposed reordering operation executions to minimize peak memory usage, while Miao et al. sought better memory utilization by temporarily swapping data from SRAM. To reduce peak memory, other researchers further proposed computing partial spatial regions at multiple levels. Additionally, CMix-NN supports mixed precision kernel libraries for quantized activations and weights on MCUs to reduce memory usage. TinyEngine, proposed as part of MCUNet, was introduced as a memory-efficient inference engine to expand the search space and accommodate larger models. TinyEngine shifts most operations from runtime to compile time, generating only the code that will be executed by the TinyNAS model. Furthermore, TinyEngine adapts the memory scheduling of the entire network topology rather than optimizing layer by layer. TensorFlow-Lite Micro (TF-Lite Micro) is one of the earliest deep learning frameworks to support bare-metal microcontrollers, enabling deep learning inference on memory-constrained MCUs. However, the above frameworks only support layer-by-layer inference, limiting the model capacity that can be executed with minimal memory and making high-resolution inputs impossible. Therefore, MCUNetV2 proposed a universal block-wise inference scheduling that operates on small spatial regions of feature maps, significantly reducing peak memory usage and enabling high-resolution input inference on MCUs. TinyOps combines fast internal memory with additional slow external memory through direct memory access (DMA) peripherals to increase memory size and accelerate inference. TinyMaix, similar to CMSIS-NN, is an optimized inference kernel library, but it avoids new yet rare features and seeks to maintain the readability and simplicity of the codebase.
B. Recent Advances in TinyML Training
On-device training on small devices is becoming increasingly popular as it allows machine learning models to be trained and refined directly on small, low-power devices. On-device training offers several benefits, including providing personalized services and protecting user privacy, as user data is never transferred to the cloud. However, compared to on-device inference, on-device training presents additional challenges due to the need to store intermediate activations and gradients, leading to larger memory usage and increased computational operations.
Researchers have been exploring methods to reduce memory usage when training deep learning models. One approach is to manually design lightweight network architectures or leverage NAS. Another common method is to trade off memory efficiency through computation, such as releasing activations during inference and recomputing discarded activations during backpropagation. However, this approach comes at the cost of increased computation time, which is untenable for resource-limited small devices. Layered training is another method that can reduce memory usage compared to end-to-end training, but it is less effective in achieving high accuracy levels. Another method reduces memory usage during training by building dynamic and sparse computation graphs through activation pruning. Some researchers have proposed different optimizers. Quantization is also a common method to reduce the size of activations during training by decreasing the bit-width of training activations.
Due to limited data and computational resources, on-device training typically focuses on transfer learning. In transfer learning, neural networks are first pre-trained on large-scale datasets (such as ImageNet) and serve as feature extractors. Then, only the last layer needs to be fine-tuned on a smaller, task-specific dataset. This approach reduces memory usage by eliminating the need to store intermediate activations during training, but accuracy may suffer when domain shifts are significant due to limited capacity. Fine-tuning all layers can achieve better accuracy but requires substantial memory to store activations, which is untenable for small devices. Recently, several memory-friendly on-device training frameworks have been proposed, but these frameworks target larger edge devices (i.e., mobile devices) and cannot be adopted on MCUs. Another approach is to update only the parameters of batch normalization layers. This reduces the number of trainable parameters, but this does not translate to memory efficiency, as the intermediate activations of batch normalization layers still need to be stored in memory.
It has been shown that the activations of neural networks are a major limiting factor in the ability to train on small devices. Tiny-Transfer-Learning (TinyTL) addresses this issue by freezing the weights of the network and only fine-tuning the biases, allowing intermediate activations to be discarded during backpropagation, thereby reducing peak memory usage. TinyOL only trains the weights of the last layer, enabling weight training while keeping activations small enough to fit on small devices. This enables incremental on-device data stream training. However, fine-tuning only the biases or the last layer may not provide sufficient accuracy. To train more layers on devices with limited memory, POET (Private Optimal Energy Training) introduces two techniques: rematerialization, which releases activations early at the cost of recomputation, and paging, which allows activations to be transferred to secondary storage. POET uses integer linear programming to find the energy-optimal scheduling for on-device training. To further reduce the memory needed to store training weights, MiniLearn applies quantization and dequantization techniques, storing weights and intermediate outputs at integer precision and dequantizing them to floating-point precision during training. When deploying deep learning models on small devices, they are often quantized to reduce the memory usage of parameters and activations. However, even after quantization, parameters may still be too large to fit within the limited hardware resources, preventing full backpropagation. To address these challenges, MCUNetV3 proposes an algorithm-system co-design approach. The algorithm part includes quantization-aware scaling (QAS) and sparse updates. QAS calibrates gradient scales and stabilizes 8-bit quantization training, while sparse updates skip the gradient computation of less important layers and subtensors. The system part includes the Tiny Training Engine (TTE), which has been developed to support QAS and sparse updates, enabling on-device learning on memory-constrained microcontrollers, such as those with 256KB or less memory.
For convenient viewing
Convenient download, please followSpecial Knowledge public account (click the blue special knowledge to follow)
Reply or send a message “TML24” to obtain the download link for “MIT’s Han Song et al.’s Overview of Tiny Machine Learning: Progress and Future“

Click “Read the original text” to learn how to useSpecial Knowledge, view and obtain100000+ AI-themed knowledge materials