
Tiny Machine Learning (TinyML) has gained significant attention due to its potential to enable intelligent applications on resource-constrained devices. This review provides an in-depth analysis of the advancements in efficient neural networks and the deployment methods of deep learning models for TinyML applications on ultra-low-power microcontrollers (MCUs). It first introduces neural networks along with their architectures and resource requirements, exploring MEMS-based applications on ultra-low-power MCUs, emphasizing their potential for implementing TinyML on resource-constrained devices. The core of the review focuses on efficient neural networks for TinyML. It covers techniques such as model compression, quantization, and low-rank factorization that optimize neural network architectures to minimize resource usage on MCUs. The paper then delves into the deployment of deep learning models on ultra-low-power MCUs, addressing challenges such as limited computational power and memory resources. Techniques like model pruning, hardware acceleration, and algorithm-architecture co-design are discussed as strategies for achieving efficient deployment. Finally, the review provides an overview of the current limitations in the field, including the trade-offs between model complexity and resource constraints. Overall, this review article offers a comprehensive analysis of efficient neural networks and deployment strategies for TinyML on ultra-low-power MCUs. It identifies future research directions to unlock the full potential of TinyML applications on resource-constrained devices.
Over the past decade, Artificial Intelligence (AI) has transformed our daily experiences and technological advancements, enabling machines to perform tasks that traditionally require human-like intelligence, such as recognizing objects or speech, or playing advanced games like Go.
Machine Learning (ML) is the most prominent AI approach, training computers to learn patterns and representations through data without explicit programming. Deep Learning (DL) is a higher-level subset of machine learning inspired by the organization of the brain, using artificial neural networks (NNs) to simulate and solve complex problems across various fields, including language processing, protein generation, or automation.
Sensors and microcontrollers. Meanwhile, the adoption and development of the Internet of Things (IoT) have also increased, bringing new devices and applications into our daily lives. Micro-Electro-Mechanical Systems (MEMS) and Microcontroller Units (MCUs) are essential hardware components of IoT, enabling hardware devices to collect and process information (motion, sound, temperature, pressure, etc.) directly in their local environment without additional resources or external communication. Local and autonomous data processing optimizes information flow but inherently brings power constraints. Certain applications also require continuous data processing, adding further constraints on power. MEMS and MCUs serve as the interface for perceiving information between the analog and digital worlds. These devices have a wide range of applications, including smartphones, automobiles, wearables, environmental monitoring, and healthcare systems. Their consumer market size reaches billions in annual sales, so even minor deviations from power constraints can lead to significant costs.
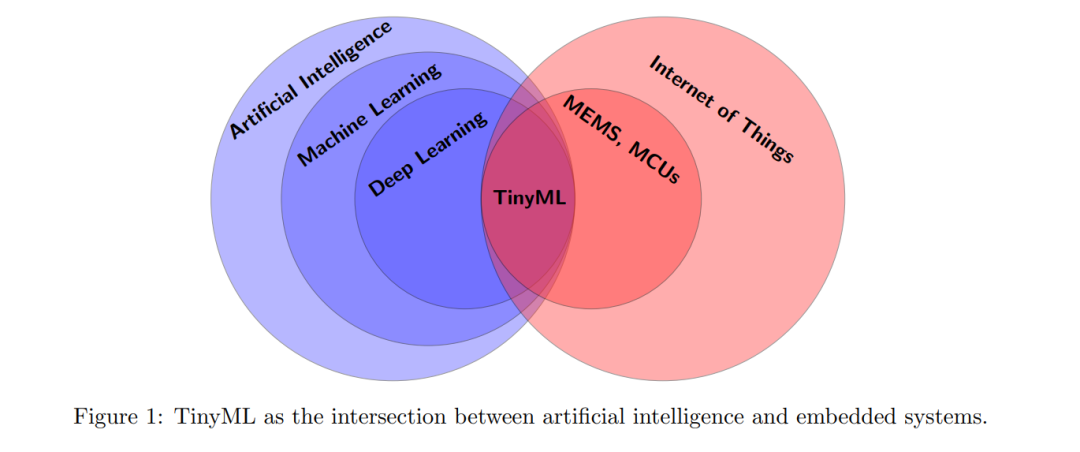
TinyML. The convergence of machine learning and IoT has drawn significant attention in research and industry, as it enables embedded hardware to process local data and interact with the environment in an automated and intelligent manner. This intersection has led to the emergence of TinyML, a term first introduced by Han and Siebert in 2019 (see Figure 1). TinyML focuses on developing efficient neural network models and deployment techniques for low-power, resource-constrained devices. Some examples of TinyML applications include detecting or counting events, gesture recognition, predictive maintenance, or keyword spotting, commonly found in household appliances, remote devices, smartphones, smartwatches, or augmented reality glasses.
However, the exponential growth of deep learning is closely tied to the development of powerful hardware, such as Graphics Processing Units (GPUs), capable of supporting its extensive computational demands. Consequently, deep learning has not achieved the same growth and support on low-power devices like microcontrollers to enable deep learning to run at the edge. In fact, the energy footprint of deep learning and the vast field of embedded devices present new challenges for researchers and the industry, but they also bring exciting opportunities.
Overview. The review begins with Section 2, providing a general introduction to neural networks, outlining their fundamental principles and architectures. It explores the evolution of neural networks and their applications across various fields, emphasizing their computational demands and the challenges posed for resource-limited devices.
Then, Section 3 provides a comprehensive overview of MEMS-based applications on ultra-low-power microcontroller units (MCUs). It discusses advancements in MEMS technology and its integration with MCUs, making it possible to develop efficient sensing and actuation systems. The potential of MEMS-based applications for enabling TinyML on resource-constrained devices is highlighted.
The core of the review, Section 4, focuses on efficient neural networks for TinyML. This section examines various techniques and methods aimed at optimizing neural network architectures and reducing their computational and memory requirements. It explores model compression, quantization, and low-rank factorization techniques, demonstrating their effectiveness in achieving high-performance inference on MCUs while maintaining minimal resource usage.
Following the discussion of efficient neural networks, Section 5 delves into the deployment of deep learning models on ultra-low-power MCUs. It investigates the challenges of porting complex models to MCUs with limited computational power and memory resources. This section discusses techniques like model pruning, hardware acceleration, and algorithm-architecture co-design, elucidating strategies for efficiently deploying deep learning models for TinyML applications.
Section 6 presents an overview of the current limitations in the TinyML field. This section discusses challenges faced by researchers and practitioners, including the trade-offs between model complexity and resource constraints, the need for benchmark datasets and evaluation metrics for TinyML, and the exploration of new hardware architectures optimized for TinyML workloads.
Finally, Section 7 summarizes and provides insights into open challenges and emerging trends and technologies that may impact the TinyML field.
Overall, this review article provides a comprehensive analysis of efficient neural networks and deployment strategies for TinyML on ultra-low-power MCUs. It highlights the current state of the field and identifies the future research directions needed to unlock the full potential of TinyML applications on resource-constrained devices.

This chapter introduces key methods for designing and training efficient TinyML models, along with their theoretical concepts and practical implications. These methods have garnered increasing interest as they bridge the gap between deep learning theory and efficient neural network deployment.
Specifically, model pruning, knowledge distillation, and quantization have demonstrated very promising compression ratios, especially in larger-scale networks (mobile or cloud-sized), which are more robust to model adjustments. Furthermore, some model compression methods also serve as forms of regularization, potentially helping models generalize better. Thus, these methods show high potential to meet the requirements of ultra-low-power MCUs.
In fact, since TinyML is still in its early stages, tools and processes are not yet mature enough to assess and truly leverage the high compression rates of existing methods for ultra-low-power MCUs; therefore, we will review the practical tools and various aspects of deploying compressed neural networks for TinyML in the next section.
Summary
In Section 2, we introduced the state of neural networks and articulated our interest in their applications, followed by an overview of MEMS-based applications, emphasizing the opportunities and challenges posed by our ultra-low-power constraints, which enhance the need for TinyML research efforts. In Section 3, we continued with Section 4, introducing existing methods for designing efficient neural networks on ultra-low-power MCUs, and provided an overview of existing tools for deploying neural networks for TinyML applications in Section 5. Finally, we examined the current limitations in the TinyML field in Section 6.
Open Challenges. TinyML faces several open challenges. Ensuring the robustness of TinyML models against adversarial attacks remains a significant challenge. Adversarial attacks can manipulate input data to mislead models, posing security risks to critical applications. Research is needed to develop robust TinyML models that can withstand various forms of adversarial attacks. This includes exploring adversarial training, input perturbation defense techniques, and understanding the trade-offs between model complexity and robustness. Additionally, many edge devices in TinyML applications operate in dynamic environments where resource availability fluctuates. Dynamically managing resources such as power, memory, and bandwidth to adapt to changing conditions is a complex challenge. Future investigations will need to focus on adaptive resource management strategies for TinyML models, considering real-time changes in resource availability. This includes exploring dynamic model adaptation, on-the-fly optimization, and resource-aware scheduling techniques to ensure optimal performance under varying conditions. Addressing these challenges will not only enhance the robustness and adaptability of TinyML models but also contribute to the broader development of the field.
Emerging Trends and Technologies. In the coming years, several trends and technologies may impact the TinyML field. Edge AI and edge computing: The integration of TinyML with edge computing is a significant trend, enabling machine learning models to be processed closer to the data source. This approach reduces latency, addresses bandwidth constraints, and optimizes TinyML models for resource-constrained edge devices. Quantum computing: Quantum computing has the potential to revolutionize the TinyML field by accelerating model training and optimization processes. As quantum computing technology matures, researchers may explore its applications to enhance the efficiency and performance of TinyML models. Custom hardware accelerators: The development of custom hardware accelerators designed for the efficient execution of TinyML models on edge devices is a key trend. Specialized hardware architectures aim to improve performance and energy efficiency, facilitating the widespread deployment of TinyML across diverse applications.
These trends collectively signify a shift toward more efficient, decentralized, and specialized computing approaches, paving the way for advancements in deploying and optimizing TinyML models on resource-constrained edge devices. They suggest a dynamic landscape for the future of TinyML, where innovations in hardware, communication, and algorithmic methods will contribute to the ongoing development of this field. Researchers and practitioners in TinyML should stay informed about these trends to leverage their potential benefits and address new challenges.

Convenient Access to Specialized Knowledge
Convenient Download, please follow the Special Knowledge public account (click the blue Special Knowledge above to follow)
Reply or send a message “TMLN” in the background to obtain the download link for “How to Implement TinyML? A Review of Efficient Neural Networks for Micro Machine Learning” from Special Knowledge.

Click “Read the Original” to learn how to use Special Knowledge, and access over 100,000 AI-related knowledge materials