Click belowcard, follow the “LiteAI” public account
Hi, everyone, I am Lite. Recently, I shared the Efficient Large Model Full Stack Technology from Part 1 to 19, which includes large model quantization and fine-tuning, efficient inference of LLMs, quantum computing, generative AI acceleration, and more. The content links are as follows:
Efficient Large Model Full Stack Technology (Part 19): Efficient Training and Inference Framework | TorchSparse++: Efficient Training and Inference Framework for Sparse Convolutions on GPU
Subsequent content will be updated, stay tuned!
Starting today, I will systematically share the Tiny Machine Learning (TinyML) project with friends, including:
-
Efficient LLM Quantization
-
-
Efficient CNN Algorithms & System Co-design
Among them, the content of efficient LLM quantization has been shared previously, you can review the earlier content:
AWQ: Quantization Method for “End-Side Large Models”
Efficient Large Model Full Stack Technology (Part 11): LLM Quantization | ICML 2023 SmoothQuant: Accurate and Efficient Post-Training Quantization of Large Language Models
Today, I will share the first part of the efficient ML systems: TinyChat: Visual Language Model and Edge AI 2.0.
Overview of Efficient ML Systems
1. Limitations of Edge AI 1.0
– Early edge AI focused on deploying compressed AI models for specific tasks.
– Different models needed to be trained for different datasets, which is time-consuming and difficult to handle outliers.
2. Increased Generality of Edge AI 2.0
– Edge AI 2.0 shifts to foundational Visual Language Models (VLMs), improving adaptability.
– VLMs have the ability to understand complex instructions and quickly adapt to new scenarios.
– Applications include autonomous driving, Internet of Things (IoT), and smart homes.
3. Solutions for VLMs on Edge Devices: AWQ + TinyChat
– Deploying VLMs on edge devices enables real-time processing and privacy protection.
– AWQ technology protects important weights through activation-aware weight quantization, quantizing to 4-bit precision with almost no accuracy loss.
– TinyChat is an efficient inference framework that supports various hardware platforms, including desktop GPUs, laptop GPUs, and mobile GPUs.
4. Multi-Platform Support of TinyChat
– Supports various edge devices such as RTX 4090, RTX 4070, and Jetson Orin.
– Fully Python-based runtime provides flexible deployment and customization.
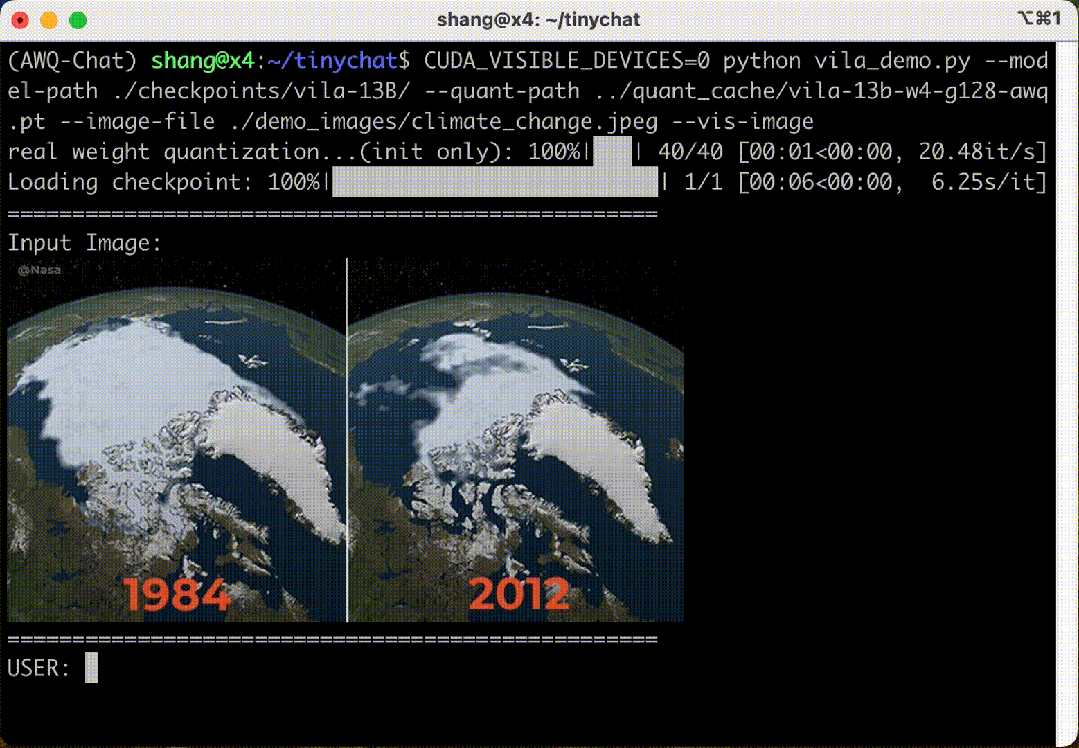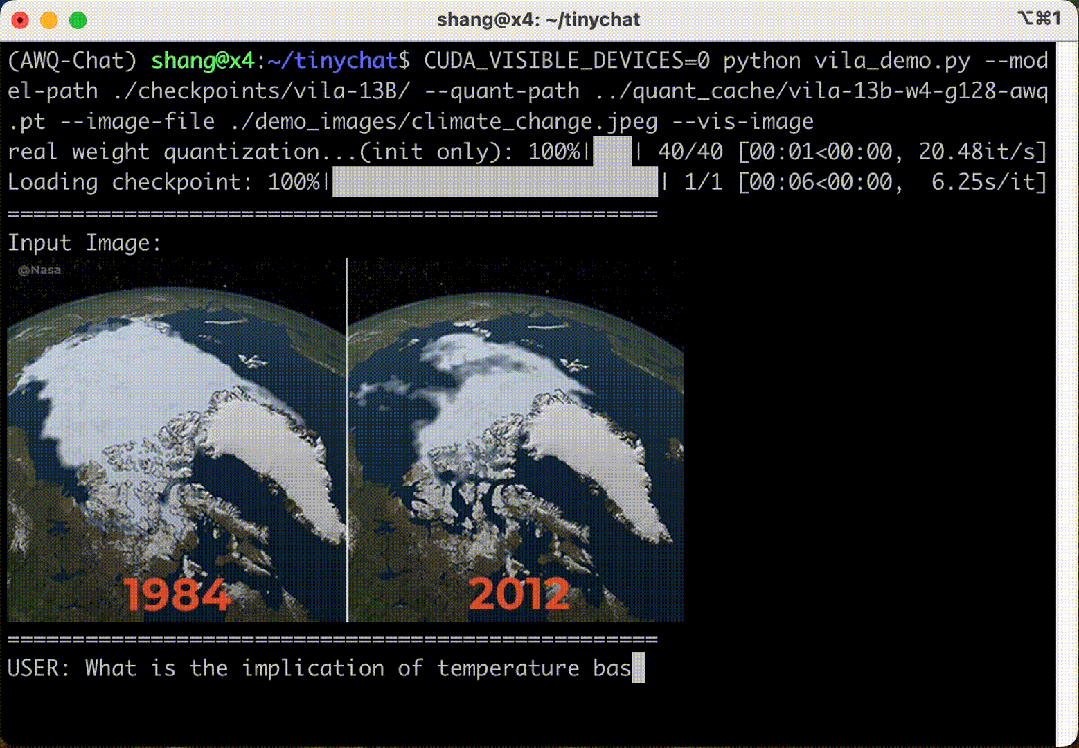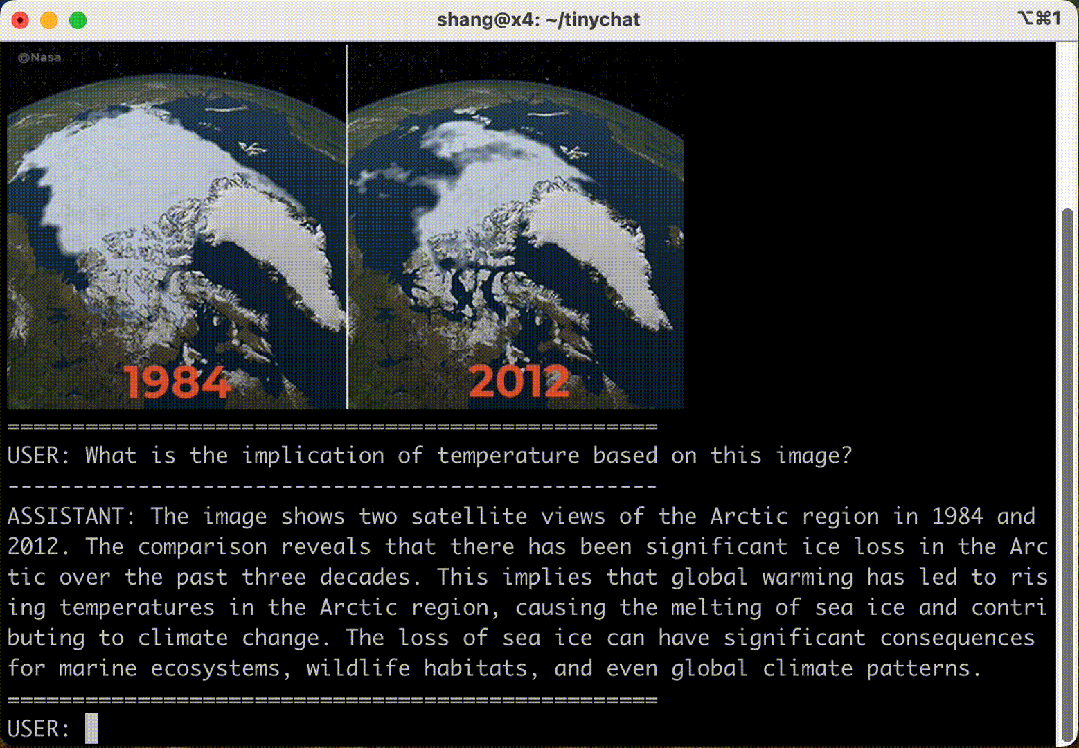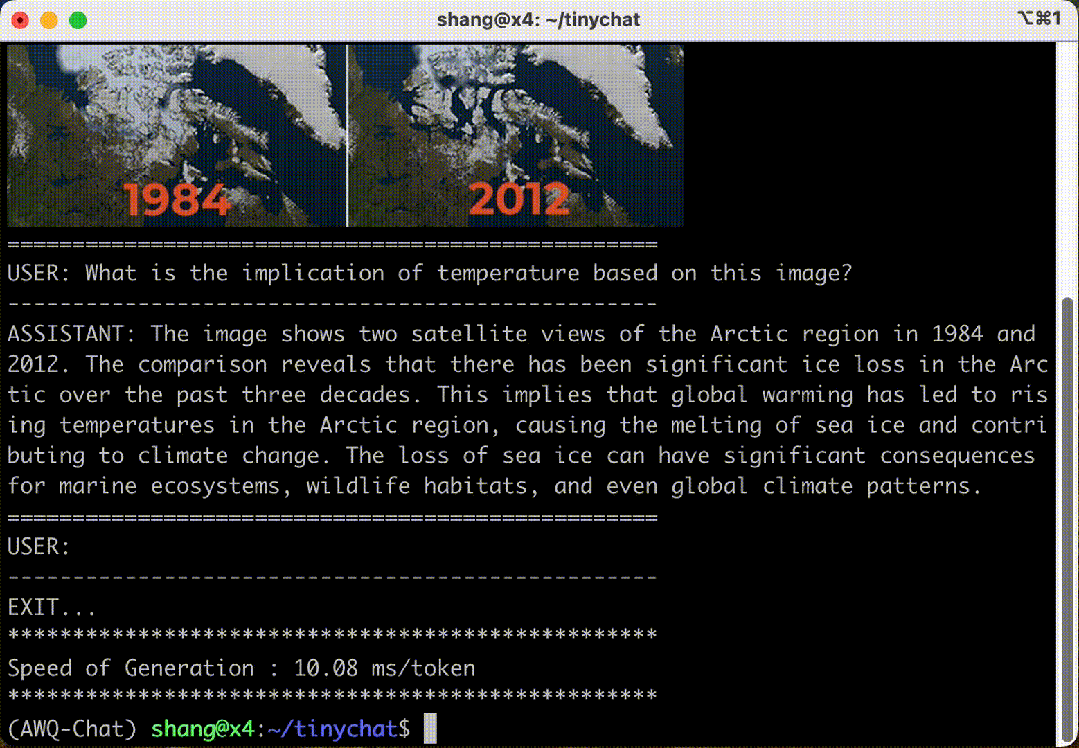
5. Multi-Image Inference and Context Learning of VILA-13B Model
– TinyChat supports the multi-image understanding capability of the VILA-13B model, allowing multiple images to be uploaded simultaneously.
– VILA has context learning capabilities, inferring patterns from previous image-text pairs without explicit prompts.
6. Integration of TinyChat with Gradio UI
– Provides a user-friendly Gradio UI for interacting with the VILA model.
– Supports various interaction modes, including multi-image inference, context learning, and chain of thought.
– Can be deployed on personal devices, such as laptops equipped with RTX 4070 GPUs.
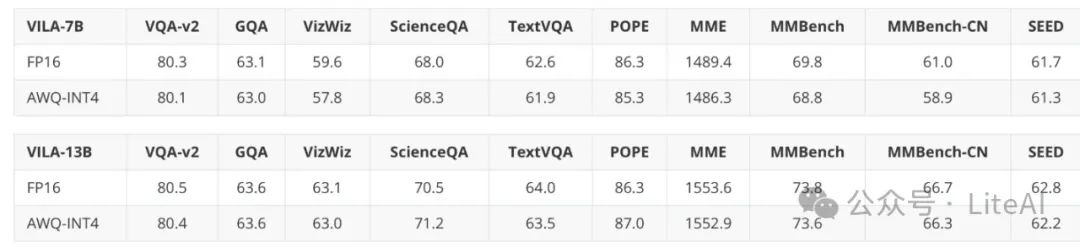
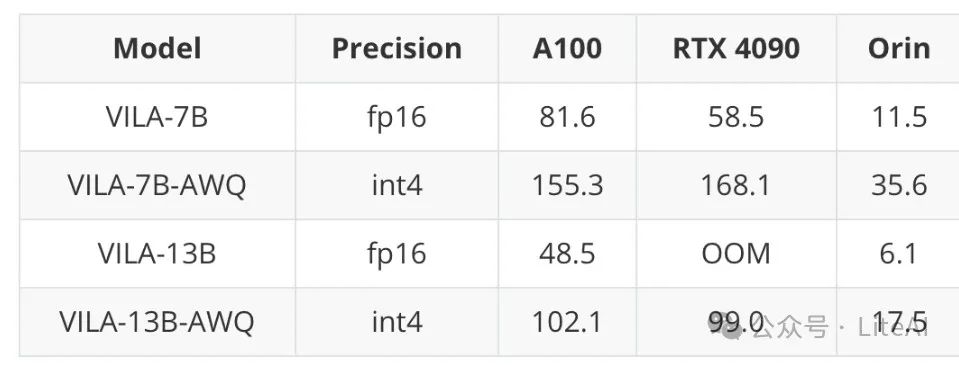
7. Quantization Evaluation and Inference Speed
– AWQ can quantize the VILA/LLaVA model to INT4 and efficiently deploy it on edge devices.
– TinyChat maintains a 3x speedup on edge devices (measured in tokens per second).
TL;DR
Explore the latest advancements of TinyChat and AWQ, integrating Visual Language Models (VLM) on edge devices! The exciting progress of VLM enables LLM to understand visual inputs, performing image understanding tasks such as caption generation and question answering. In the latest version, TinyChat now supports leading VLMs like VILA, which can be easily quantized through AWQ, providing users with an excellent experience in image understanding tasks.
Early iterations of edge AI revolved around deploying compressed AI models to edge devices. This phase, known as Edge AI 1.0, focused on task-specific models. The challenges of this approach included the need to train different models with different datasets, where “negative samples” were difficult to collect, and anomalies were hard to handle. This process was very time-consuming, highlighting the need for more adaptive and better-generalized AI solutions.
-
Edge AI 2.0: The Rise of Generalization
Edge AI 2.0 marks a shift towards enhanced adaptability powered by foundational Visual Language Models (VLM). VLMs demonstrate incredible versatility, understanding complex instructions and quickly adapting to new scenarios. This flexibility makes them essential tools in a wide range of applications. They can optimize decision-making in autonomous vehicles, create personalized interactions in IoT/AIoT environments, and enhance smart home experiences. The core advantage of VLMs lies in the “world knowledge” they acquire during language pre-training.
-
Solutions for Edge VLM: AWQ + TinyChat
The demand for real-time processing and privacy protection makes deploying VLMs on edge devices crucial. Unlike text, images may contain highly sensitive personal data, making cloud-based solutions pose privacy risks. Edge-based VLMs improve responsiveness and efficiency, which are critical for rapid decision-making in smart environments and autonomous systems. However, their excessive resource consumption makes them unsuitable for edge device deployment. Model compression, especially quantization of model weights, is key to successful deployment. However, standard 4-bit quantization significantly reduces the accuracy of large models. To address this issue, we developed AWQ (Activation-Aware Weight Quantization, MLSys 24). This technology innovatively uses activation-aware scaling factors to protect important weights during the quantization process. AWQ allows us to quantize VLMs to 4-bit precision with negligible accuracy loss, paving the way for VLMs to transition to edge computing while maintaining performance standards.
Despite advancements like AWQ, deploying large language visual models on edge devices remains a complex task. The lack of byte alignment in 4-bit weights requires specialized computations for optimal efficiency. TinyChat stands out as a highly efficient inference framework specifically designed for LLMs and VLMs on edge devices. The adaptability of TinyChat enables it to run on various hardware platforms, from NVIDIA RTX 4070 laptop GPUs to NVIDIA Jetson Orin, attracting significant interest from the open-source community. Now, TinyChat has expanded its scope to support the visual language model VILA, enabling significant understanding and reasoning of visual data. TinyChat provides exceptional efficiency and flexibility in combining text and visual processing, allowing edge devices to perform cutting-edge multimodal tasks.
-
Flexible Framework with Multi-Platform Support
TinyChat offers seamless support for a wide range of edge devices, including desktop GPUs (e.g., RTX 4090), laptop GPUs (e.g., RTX 4070), and mobile GPUs (e.g., Jetson Orin). TinyChat is open-source and features a fully Python-based runtime, granting users extraordinary deployment and customization flexibility.
TinyChat VILA-13B (4-bit) running on RTX 4090
-
Multi-Image Inference and Context Learning
The latest version of TinyChat leverages the multi-image inference capability of VILA, allowing users to upload multiple images simultaneously to enhance interaction. This opens up more possibilities.
VILA also demonstrates excellent context learning capabilities. Without explicit system prompts, VILA can seamlessly infer modalities from previous image-text pairs, generating relevant text for new image inputs. In the demonstration video below, VILA successfully recognized NVIDIA’s logo and emulated the style of previous examples to output NVIDIA’s most famous products.
-
TinyChat Supports Gradio UI
With the release of TinyChat and VILA, the author team has developed a user-friendly Gradio UI, making it very easy to interact with the VILA model. Just upload an image and receive instant feedback from VILA, regardless of the device’s computing power. The Gradio UI provides various interaction modes, enabling users to explore the full range of VILA’s capabilities, including multi-image inference, context learning, chain of thought, and more!
Thanks to AWQ support, it is possible to quantize VILA/LLaVA models to INT4 and effectively deploy them on edge devices via TinyChat. Here, the performance of AWQ on quantizing visual language models is also evaluated, confirming that AWQ handles the VILA model well, improving efficiency while maintaining accuracy.
This section also evaluates the inference speed of TinyChat on the visual language model (VILA). Compared to the FP16 baseline, TinyChat maintains a 3x speedup on edge devices (calculated in tokens/s).
TinyChat is efficient for VLM inference.
Reference link: https://hanlab.mit.edu/blog/tinychat-vlm
In Conclusion
Here, I recommend the latest course 6.5940 from HanLab for Fall 2024 (the course is ongoing).
Course link: https://efficientml.ai
Course materials: https://pan.quark.cn/s/1324c20d7efd
Your likes, views, and follows are my greatest motivation to persist!
Scan to add me, or add WeChat (ID: LiteAI01) for technical, career, and professional planning discussions, note “Research Direction + School/Region + Name”