Article Overview
1. Introduction to the TinyTL Method
– TinyTL reduces memory usage by freezing weights and only learning bias modules.
– Introduces a lightweight residual module (Lite Residual Module) to enhance model adaptability with minimal memory overhead (3.8%).
– Experiments show that TinyTL significantly saves memory (up to 6.5 times) with minimal accuracy loss.
2. Background and Challenges
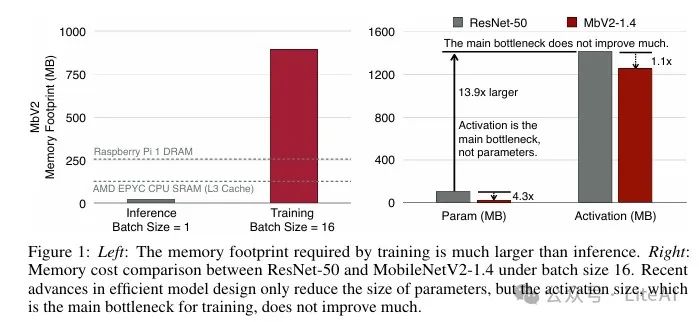
– Smart edge devices have limited memory and energy; traditional parameter reduction methods do not directly save memory.
– Activations are the main bottleneck for training memory, not parameters.
– Existing methods such as network pruning and quantization cannot solve memory issues during the training phase.
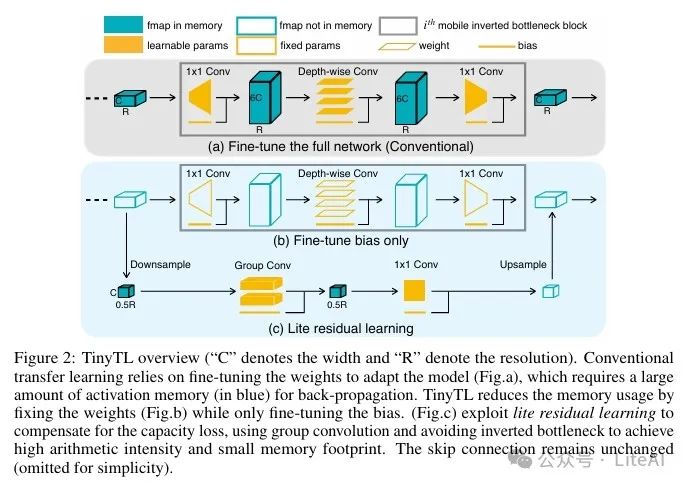
3. Technical Details of TinyTL
– By analyzing memory usage during the backpropagation process, it is found that intermediate activation values are only used to update weights.
– Proposes lightweight residual learning to optimize memory usage by reducing the size of activation values.
– Uses group convolutions and high arithmetic intensity designs to reduce channel numbers and resolution, thereby lowering memory overhead.
4. Experiments and Results
– Extensive experiments were conducted on 9 image classification datasets, where TinyTL outperformed traditional methods in both accuracy and memory efficiency.
– Compared to full network fine-tuning, TinyTL saves up to 12.9 times memory while maintaining accuracy.
– With feature extractor adaptation, TinyTL can select the most suitable sub-network for different tasks.
5. Practical Applications and Impact
– TinyTL enables edge devices to adapt locally to new data, protecting privacy.
– Applicable to privacy-sensitive applications such as healthcare and smart homes.
– Helps to popularize AI in rural areas with poor network conditions.

Article link: https://arxiv.org/pdf/2007.11622
Project link: https://github.com/mit-han-lab/tinyml/tree/master/tinytl
TL;DR
Article Method
The TinyTL method is a transfer learning approach for device-side learning, aimed at optimizing training memory usage by reducing activations.
1. Background and Challenges:
– Edge devices have limited memory, and traditional methods of reducing training parameters do not directly decrease memory usage, as the main bottleneck for training memory is activations rather than parameters.
– Existing methods such as network pruning and quantization primarily target the inference phase and cannot solve memory issues during the training phase.
2. TinyTL Method:
– Freezing Weights: The TinyTL method freezes the weights of the pre-trained feature extractor and only updates the bias modules to reduce memory usage.
– Introducing Lightweight Residual Modules: To compensate for the capacity loss caused by freezing weights, TinyTL introduces lightweight residual modules that refine the feature extractor by learning small residual feature maps, adding only 3.8% to memory overhead.
3. Technical Details:
– Backpropagation Analysis: By analyzing memory usage during backpropagation, it is found that intermediate activation values are only used to update weights, not biases. Thus, updating only the biases can significantly save memory.
– Lightweight Residual Module Design: The lightweight residual module reduces memory overhead by using group convolutions and high arithmetic intensity designs to decrease channel numbers and resolution. Specifically, group convolutions are used instead of depthwise convolutions, and the resolution of input feature maps is reduced.
Experimental Results
The experimental results of the TinyTL method on multiple image classification datasets are as follows:
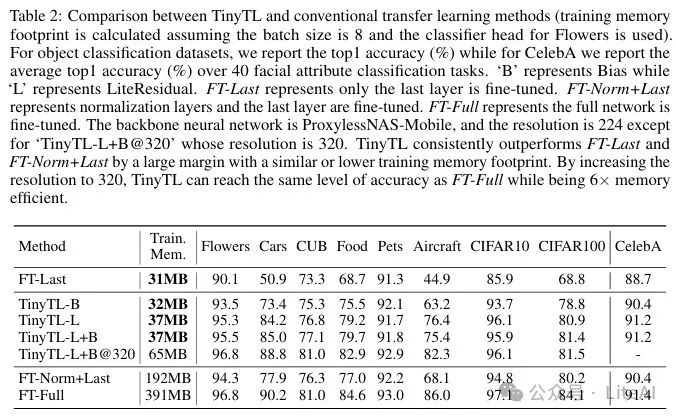
1. Comparison with Existing Methods:
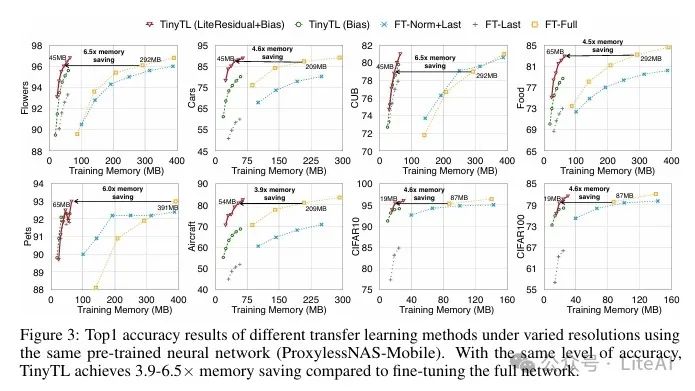
– FT-Last (fine-tuning only the last layer): TinyTL significantly improves Top-1 accuracy while maintaining similar training memory usage. For example, on the Cars dataset, TinyTL-L+B’s Top-1 accuracy is 34.1% higher than FT-Last.
– FT-Norm+Last (fine-tuning normalization layers and the last layer): TinyTL-L+B improves Top-1 accuracy while increasing training memory efficiency by 5.2 times.
– FT-Full (fine-tuning the entire network): TinyTL-L+B@320 saves 6 times the training memory while achieving accuracy similar to FT-Full.
2. Comparison of Different Variants of TinyTL:
– TinyTL-B (fine-tuning only biases and the last layer): On most datasets, TinyTL-L and TinyTL-L+B significantly outperform TinyTL-B while adding minimal memory overhead.
– TinyTL-L (fine-tuning lightweight residual modules and the last layer): TinyTL-L achieves higher accuracy than TinyTL-B on most datasets.
– TinyTL-L+B (fine-tuning lightweight residual modules, biases, and the last layer): TinyTL-L+B’s accuracy is slightly higher than TinyTL-L on most datasets while maintaining the same memory overhead.
3. Results at Different Input Resolutions:
– At different input resolutions, TinyTL can significantly reduce memory usage while maintaining or even improving accuracy. For example, at a resolution of 224, TinyTL-L+B’s memory usage is 37MB, while at a resolution of 320, it is 65MB.
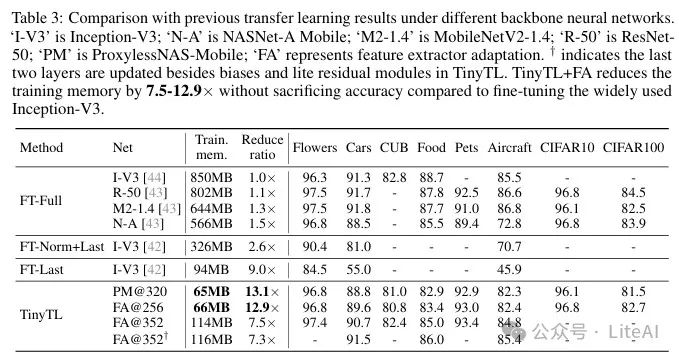
4. Results with Feature Extractor Adaptation:
– With feature extractor adaptation, TinyTL achieves 7.5-12.9 times training memory savings across multiple datasets while maintaining accuracy similar to fine-tuning the entire Inception-V3 network.
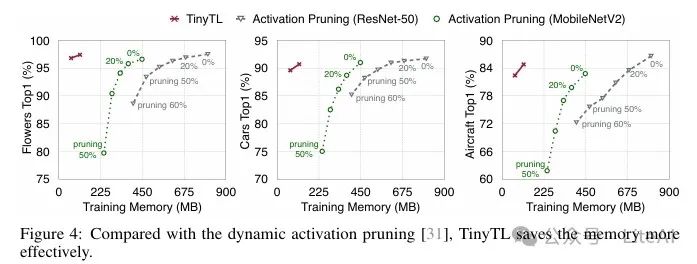
5. Comparison with Dynamic Activation Pruning:
– Compared to dynamic activation pruning, TinyTL achieves higher memory efficiency with minimal accuracy drop. TinyTL realizes greater memory savings through redesigning the transfer learning framework (lightweight residual modules, feature extractor adaptation).
6. Results with Batch Size of 1:
– With a batch size of 1, TinyTL’s training memory usage further reduces to about 16MB, making training feasible on cache (SRAM), thus significantly reducing energy consumption.
Final Thoughts
Scan the code to add me, or add WeChat (ID: LiteAI01) for technical, career, and professional planning discussions. Please note “Research Direction + School/Region + Name”