
Industry Insights and News Sharing Invites You to Submit/Recommend Articles

Electric Family Supply and Demand Information Platform
www.dd1j.com www.ev108.com

The miniaturization trend led by NASA has swept the entire consumer electronics industry. Now, all of Beethoven’s works can be stored in a needle and listened to through headphones. — Astrophysicist and science commentator Neil deGrasse Tyson
The proliferation of ultra-low-power embedded devices, along with the launch of embedded machine learning frameworks like TensorFlow Lite for microcontrollers, means that AI-driven IoT devices will see widespread adoption. — Harvard University Associate Professor Vijay Janapa Reddi
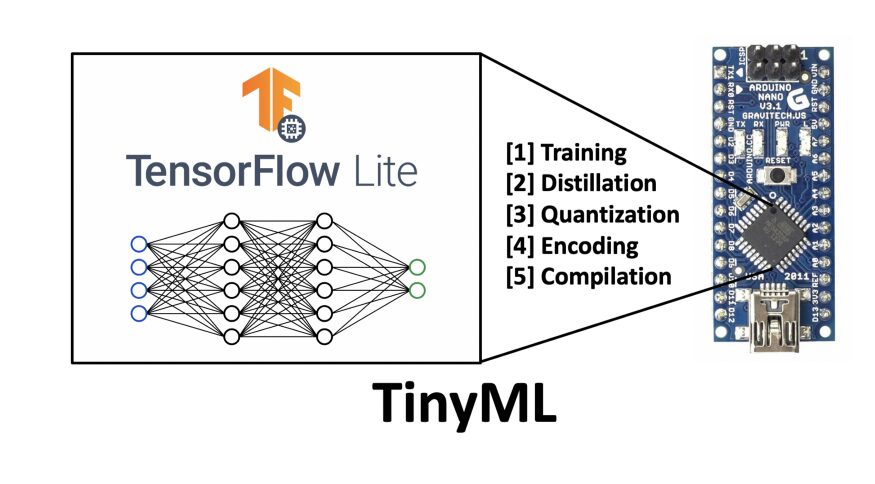
Figure 1 Overview of TinyML on Embedded Devices
Models are not always better when larger.
This article is the first in a series on TinyML, aimed at introducing readers to the concept of TinyML and its future potential. Subsequent articles in this series will delve into specific applications, implementations, and tutorials.
Over the past decade, we have witnessed an exponential growth in the scale of machine learning algorithms due to improvements in processor speeds and the advent of big data. Initially, models were not very large and ran on local computers using one or more CPU cores.
Shortly thereafter, GPU computing enabled the processing of larger datasets, and with cloud-based services such as Google Colaboratory and Amazon EC2 Instances, GPU technology became more accessible. Meanwhile, algorithms could still run on a single machine.
Recently, dedicated ASICs and TPUs have provided processing power equivalent to about eight GPUs. The development of these devices has enhanced the ability to distribute learning algorithms across multiple systems, meeting the growing demand for larger models.
The release of the GPT-3 algorithm in May 2020 pushed the scale of models to unprecedented levels. The network architecture of GPT-3 contains an astonishing 175 billion neurons, more than twice the approximately 85 billion neurons in the human brain and over ten times the number of neurons in Turing-NLG, which was released in February 2020 and is the second largest neural network in history, containing about 17.5 billion parameters. It is estimated that the training cost of the GPT-3 model is around $10 million, using about 3 GWh of electricity, equivalent to the output of three nuclear power plants in one hour.
Despite the achievements of GPT-3 and Turing-NLG being commendable, they have naturally sparked criticism from industry insiders regarding the growing carbon footprint of the AI industry. On the other hand, they have also ignited interest in more energy-efficient computing in the field of artificial intelligence. Over the past few years, concepts such as more efficient algorithms, data representations, and computations have been the focus of attention in the seemingly unrelated field of TinyML.
TinyML is the intersection of machine learning and embedded IoT devices, representing an emerging engineering discipline with the potential to revolutionize many industries.
The primary beneficiaries of TinyML are in the fields of edge computing and energy-efficient computing. TinyML originates from the concept of IoT. The traditional approach of IoT is to send data from local devices to the cloud for processing. Some concerns have been raised about this approach regarding privacy, latency, storage, and energy efficiency.
-
Energy Efficiency. Data transmission, whether wired or wireless, is energy-intensive, consuming about an order of magnitude more energy than native computing using multiply-accumulate units (MAUs). The most energy-efficient approach is to develop IoT systems with local data processing capabilities. Compared to the “computation-centric” cloud model, a “data-centric” computing approach has been explored by some AI pioneers and is currently being applied.
-
Privacy. Data transmission poses risks of privacy infringement. Data may be intercepted by malicious actors, and when stored in a single location like the cloud, the inherent security of the data is compromised. By keeping most data on the device, communication needs can be minimized, thereby enhancing security and privacy.
-
Storage. Most of the data collected by many IoT devices is useless. For instance, a security camera recording the entrance of a building 24/7 may not serve any purpose for most of the day since no unusual activity occurs. Implementing smarter systems that activate only when necessary can reduce storage capacity needs and subsequently decrease the amount of data transmitted to the cloud.
-
Latency. Standard IoT devices, such as Amazon Alexa, must transmit data to the cloud for processing, and then the output from the algorithm provides a response. In this sense, the device is merely a convenient gateway to the cloud model, akin to a carrier pigeon between the device and Amazon’s servers. The device itself is not intelligent, and the response speed entirely depends on internet performance. If the internet speed is slow, then the response from Amazon Alexa will also be slow. Smart IoT devices with built-in automatic speech recognition reduce or even completely eliminate dependence on external communication, thereby lowering latency.
The above issues are driving the development of edge computing. The concept of edge computing is to implement data processing functionality on devices deployed at the “edge” of the cloud. These edge devices are highly constrained in memory, computation, and functionality based on their own resources, necessitating the development of more efficient algorithms, data structures, and computation methods.
Such improvements also apply to larger models, achieving several orders of magnitude increase in machine learning model efficiency without compromising model accuracy. For example, Microsoft’s Bonsai algorithm can be as small as 2 KB, yet it outperforms the typically 40 MB kNN algorithm or the 4 MB neural network. This result may sound insignificant, but to put it another way – achieving the same accuracy on a model reduced by a factor of ten thousand is quite impressive. Models of such small size can run on an Arduino Uno with 2 KB of memory. In short, such machine learning models can now be built on microcontrollers priced at $5.
Machine learning is at a crossroads, with two computational paradigms advancing simultaneously: computation-centric computing and data-centric computing. In computation-centric computing, data is stored and analyzed on instances in data centers; in data-centric computing, processing is performed at the original location of the data. Although computation-centric computing seems to be nearing its limits, data-centric computing is just beginning.
Currently, IoT devices and embedded machine learning models are becoming increasingly prevalent. It is expected that by the end of 2020, there will be over 20 billion active devices. Many of these devices, such as smart doorbells, smart thermostats, and smartphones that can be “woken up” just by speaking or picking them up, may go unnoticed. This article will delve into how TinyML works and its current and future applications.
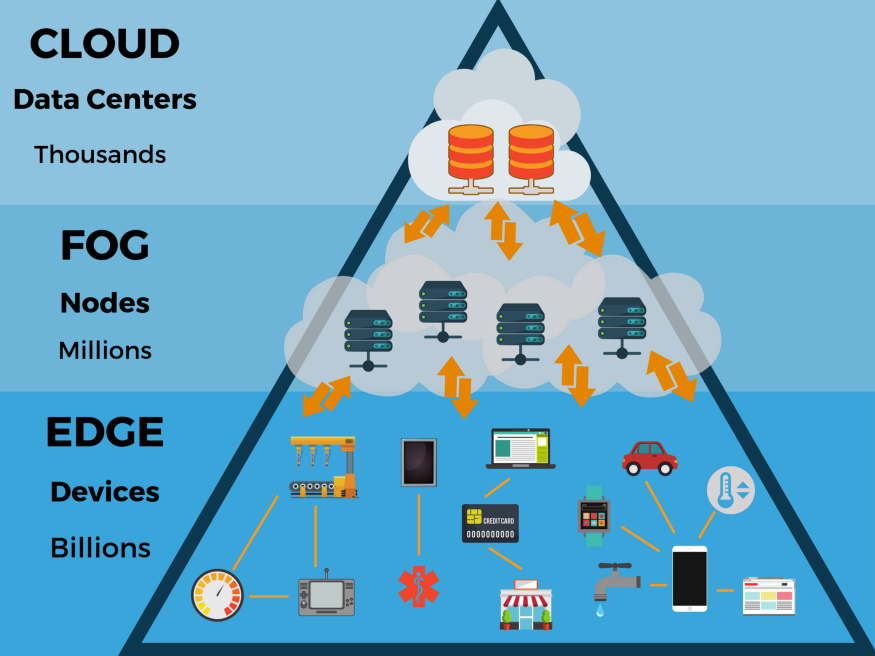
Figure 2 Hierarchical Structure of the Cloud.
In the past, various operations performed by devices had to rely on complex integrated circuits. Now, the “intelligence” of machine learning hardware is gradually being abstracted into software, making embedded devices simpler, lighter, and more flexible.
Implementing machine learning on embedded devices presents significant challenges, but substantial progress has been made in this field. Deploying neural networks on microcontrollers brings key challenges in terms of low memory usage, power constraints, and computational limitations.
Smartphones are the most typical example of TinyML. Phones are always in an active listening state for “wake words”, such as “Hey Google” for Android smartphones and “Hey Siri” for iPhones. If the voice wake-up service runs on the smartphone’s CPU (mainstream iPhone CPUs reach 1.85 GHz), the battery would deplete in a matter of hours. Such power consumption is unacceptable, especially since most people use the voice wake-up service only a few times a day.
To address this issue, developers created dedicated low-power hardware that can be powered by small batteries (e.g., CR2032 coin batteries). Even when the CPU is not running (typically indicated by the screen being off), the integrated circuit can remain active.
This integrated circuit consumes only 1 mW of power, allowing it to be powered for up to a year using a standard CR2032 battery.
While some may not find this impressive, it represents a significant advancement. The bottleneck for many electronic devices is energy. Any device requiring a mains power supply is limited by the location of the power wiring. If a dozen devices are deployed in the same location, the power supply may quickly become overloaded. Mains power is not very efficient and can be costly. Converting the power supply voltage (e.g., 120V used in the US) to the typical circuit voltage range (usually around 5V) wastes a lot of energy. Laptop users are well aware of this when they unplug their chargers. The heat generated by the internal transformer of the charger is energy wasted during the voltage conversion process.
Even if devices come with batteries, battery life is limited and requires frequent recharging. Many consumer electronics are designed to last a full workday. Some TinyML devices can run for a year on a coin-sized battery, enabling deployment in remote environments with communication only when necessary to conserve power.
In a smartphone, the wake word service is not the only seamless TinyML application. Accelerometer data can be used to determine if a user has just picked up the phone, thereby waking the CPU and illuminating the screen.
Clearly, these are not the only applications for TinyML. In fact, TinyML offers a wealth of exciting applications for product enthusiasts and businesses to create smarter IoT devices. In an era where data is becoming increasingly important, the ability to distribute machine learning resources to remote memory-constrained devices presents tremendous opportunities in data-intensive industries such as agriculture, weather forecasting, or earthquake detection.
Undoubtedly, empowering edge devices to perform data-driven processing will transform the computational paradigm in industrial processes. For example, if it is possible to monitor crops and detect features such as soil moisture, specific gases (e.g., ethylene released when apples ripen), or certain atmospheric conditions (e.g., high winds, low temperatures, or high humidity), it will greatly enhance crop growth and yield.
Another example is installing a camera in smart doorbells to use facial recognition to identify visitors. This will provide security functions and can even output the doorbell camera feed to an indoor television screen when someone arrives, allowing the homeowner to see who is at the door.
Currently, the two main application areas of TinyML are:
-
Keyword Spotting. Most people are already very familiar with this application, such as “Hey Siri” and “Hey Google” keywords, often referred to as “hot words” or “wake words”. Devices continuously listen to audio input from microphones, trained to respond only to specific sound sequences that match the learned keywords. These devices are simpler and use fewer resources than automatic speech recognition (ASR). Devices like Google smartphones also use a cascading architecture for speaker verification to ensure security.
-
Visual Wake Words. Visual wake words use images as a substitute for wake words, indicating presence or absence through binary classification of images. For example, designing a smart lighting system that activates upon detecting a person’s presence and turns off when they leave. Similarly, wildlife photographers can use visual wake functionality to start recording when specific animals appear, and security cameras can start recording when human activity is detected.
The following diagram provides a comprehensive overview of current TinyML machine learning applications.
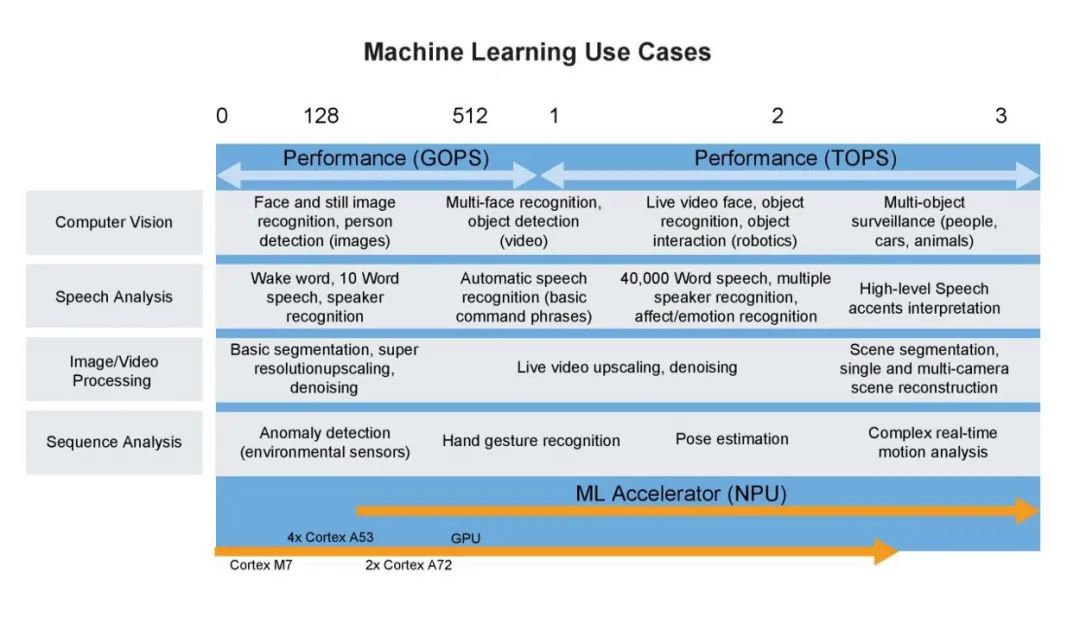
Figure 3 Machine Learning Use Cases for TinyML. Image Source: NXP.
The working mechanism of TinyML algorithms is almost identical to traditional machine learning models, typically training the model on the user’s computer or in the cloud. The real play of TinyML comes in the post-training processing, commonly referred to as “deep compression”.
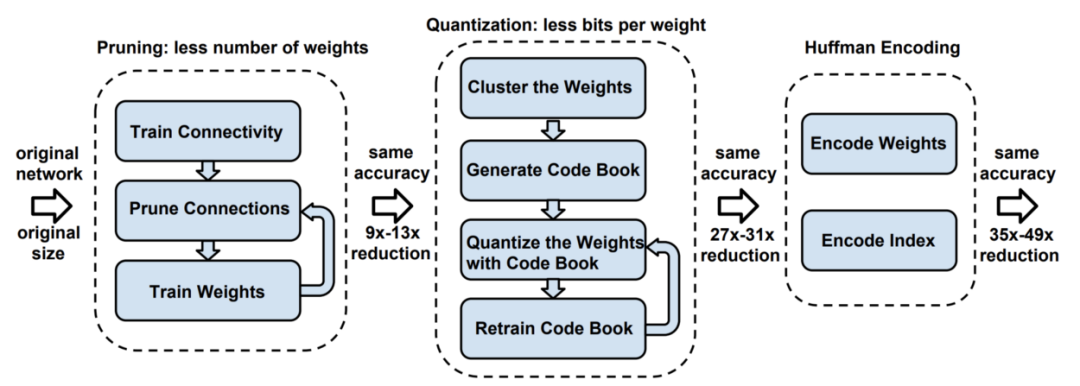
Figure 4 Illustration of Deep Compression. Source: [ArXiv Paper](https://arxiv.org/pdf/1510.00149.pdf).
After training, models need to be modified to create more compact representations. The main techniques for achieving this process include pruning and knowledge distillation.
The basic idea of knowledge distillation is to consider the sparsity or redundancy present within larger networks. While large-scale networks have high representational capacity, if the network capacity is not saturated, a smaller network (i.e., with fewer neurons) can represent it. In the research work published by Hinton et al. in 2015, the embedded information transferred from the Teacher model to the Student model is referred to as “dark knowledge”.
The following diagram illustrates the process of knowledge distillation:
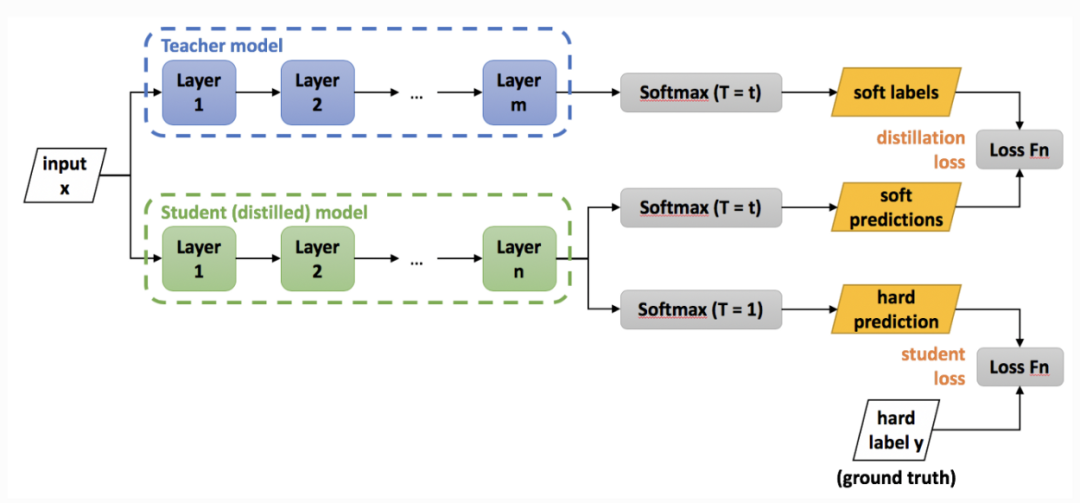
Figure 5 Illustration of Knowledge Distillation Process.
In the diagram, the Teacher model is a trained convolutional neural network model tasked with transferring its “knowledge” to a smaller-scale convolutional network model with fewer parameters, referred to as the Student model. This process, known as “knowledge distillation”, aims to encapsulate the same knowledge in a smaller-scale network, enabling a form of network compression for use on more memory-constrained devices.
Similarly, pruning helps achieve a more compact model representation. Broadly speaking, pruning aims to remove neurons that are nearly useless for output predictions. This process typically involves smaller neural weights being removed, while larger weights are retained due to their higher importance during inference. Subsequently, the network can be retrained on the pruned architecture to fine-tune the output.
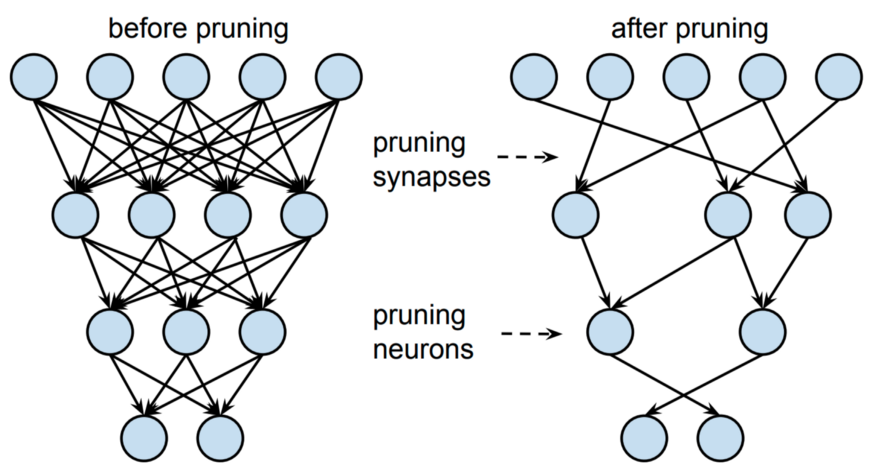
Figure 6 Illustration of Pruning Knowledge Representation in Distilled Models.
After distillation, the model needs to undergo quantization to form a format compatible with embedded device architectures.
Why perform quantization? Assume we are using an ATmega328P microcontroller that performs 8-bit arithmetic on an Arduino Uno. Ideally, to run the model on the Uno, unlike many desktop and laptop computers that use 32-bit or 64-bit floating point representations, the model weights must be stored as 8-bit integer values. By quantizing the model, the storage size of the weights can be reduced to 1/4, from 32-bit to 8-bit, with minimal impact on accuracy, typically around 1-3%.
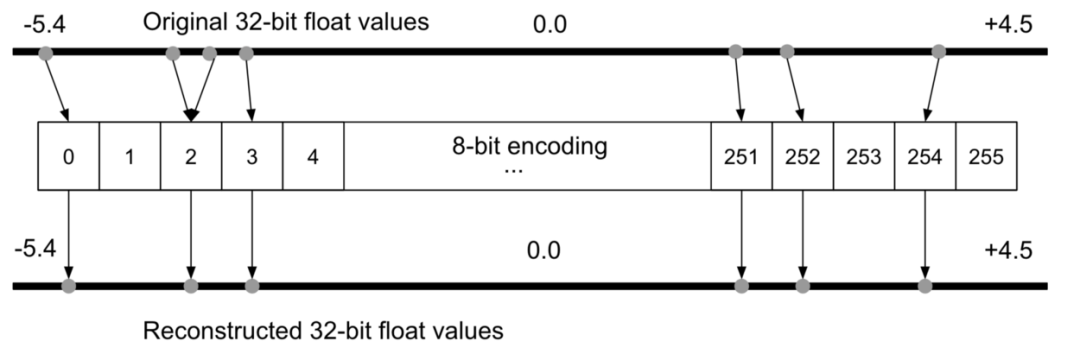
Figure 7 Illustration of Quantization Error in 8-Bit Encoding Process, Used for Reconstructing 32-Bit Floating Point Numbers. Image Source: [TinyML](https://tinymlbook.com/).
Due to the presence of quantization error, some information may be lost during the quantization process. For example, on integer-based platforms, a floating-point representation of 3.42 may be truncated to 3. To address this issue, research has proposed quantization-aware (QA) training as an alternative. QA training essentially restricts the network to only use values available on quantized devices during the training process (see Tensorflow examples for specifics).
Coding is an optional step. Coding stores data in the most efficient way, further reducing model size. The famous Huffman coding is commonly used.
After quantization and coding, the model needs to be converted into a format interpretable by lightweight network interpreters, with TF Lite (approximately 500 KB) and TF Lite Micro (approximately 20 KB) being the most widely used. The model will be compiled into C or C++ code, which is usable by most microcontrollers and effectively utilizes memory, running on interpreters on the device.
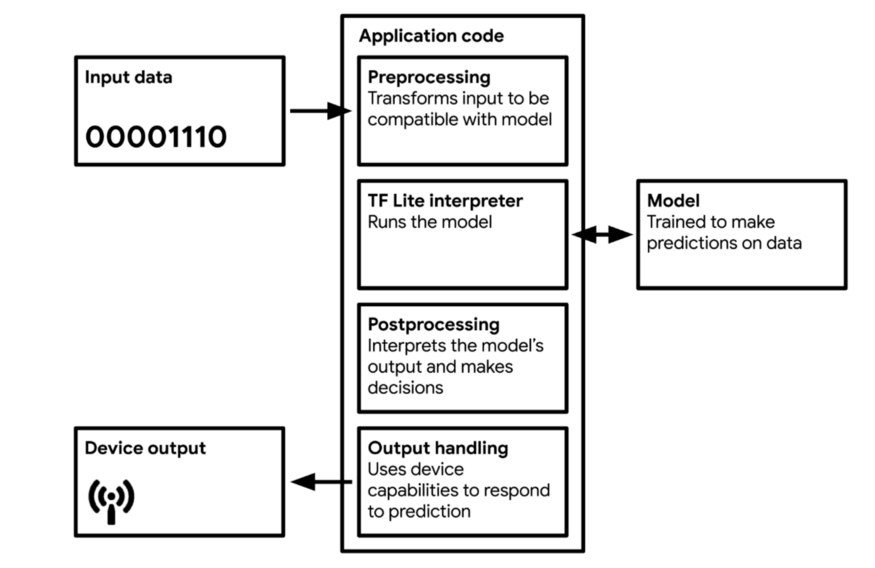
Figure 8 Workflow Diagram of TinyML Applications. Source: [TinyML](https://tinymlbook.com/).
Most TinyML technologies address the complexities arising from processing on microcontrollers. TF Lite and TF Lite Micro are very small because they eliminate all non-essential features. Unfortunately, they also remove some useful features, such as debugging and visualization. This means that if errors occur during deployment, it may be challenging to determine the cause.
Furthermore, although models must be stored locally on the device, they must also support executing inference. This means that the microcontroller must have sufficient memory to run (1) the operating system and software libraries; (2) neural network interpreters, such as TF Lite; (3) stored neural network weights and architecture; (4) intermediate results during inference. Therefore, research papers in the direction of TinyML typically provide peak memory usage for quantization algorithms, along with memory usage, the number of multiply-accumulate units (MACs), accuracy, etc.
Training on the device introduces additional complexities. Due to reduced numerical precision, ensuring sufficient accuracy required for network training is extremely difficult. Under standard desktop computing precision, automatic differentiation methods are generally accurate. The precision of computing derivatives can reach an astonishing 10^{-16}, but performing automatic differentiation on 8-bit numbers yields poor results. During backpropagation, derivatives are combined and ultimately used to update neural parameters. At such low numerical precision, the model’s accuracy may be severely compromised.
Despite these issues, some neural networks have been trained using 16-bit and 8-bit floating-point numbers.
The first paper addressing the reduction of numerical precision in deep learning was published by Suyog Gupta and colleagues in 2015, titled “Deep Learning with Limited Numerical Precision”. The results presented in this paper are quite interesting, demonstrating that it is possible to reduce the 32-bit floating-point representation to a 16-bit fixed-point representation with little to no loss in accuracy. However, this result only applies when using stochastic rounding, as it produces unbiased results on average.
In the paper published by Naigang Wang and colleagues in 2018, titled “Training Deep Neural Networks with 8-bit Floating Point Numbers”, 8-bit floating-point numbers were used to train neural networks. Using 8-bit numbers during training is significantly more challenging than during inference because maintaining fidelity in gradient calculations during backpropagation is essential to achieve machine-level precision.
Model computational efficiency can be improved through model customization. A good example is MobileNet V1 and V2, which are widely deployed model architectures on mobile devices, essentially a convolutional neural network that achieves higher computational efficiency through recasting. This more efficient form of convolution is known as depthwise separable convolution. Optimizations based on hardware profiling and neural architecture search can also be used to address architectural latency, but this article will not elaborate on this.
Running machine learning models on resource-constrained devices opens the door to many new applications. Technological advancements that make standard machine learning more energy-efficient will help alleviate some concerns about the environmental impact of data science. Additionally, TinyML supports embedded devices equipped with data-driven algorithms, enabling applications in various scenarios from preventive maintenance to detecting bird calls in forests.
While continuing to scale up models is a steadfast direction for some machine learning practitioners, the development of machine learning algorithms that are more memory, computation, and energy-efficient is also a new trend. TinyML is still in its infancy, and there are few experts in this direction. The references in this article list some important papers in the field of TinyML, and interested readers are encouraged to read them. This field is rapidly growing and is expected to become an important new application of AI in the industrial sector in the coming years. Stay tuned.
Matthew Stewart, PhD student in Environmental and Data Science at Harvard University, Machine Learning Consultant at Critical Future, personal blog: https://mpstewart.net
References
[1] Hinton, Geoffrey & Vinyals, Oriol & Dean, Jeff. (2015). Distilling the Knowledge in a Neural Network.
[2] D. Bankman, L. Yang, B. Moons, M. Verhelst and B. Murmann, “An always-on 3.8μJ/86% CIFAR-10 mixed-signal binary CNN processor with all memory on chip in 28nm CMOS,” 2018 IEEE International Solid-State Circuits Conference — (ISSCC), San Francisco, CA, 2018, pp. 222–224, doi: 10.1109/ISSCC.2018.8310264.
[3] Warden, P. (2018). Why the Future of Machine Learning is Tiny. Pete Warden’s Blog.
[4] Ward-Foxton, S. (2020). AI Sound Recognition on a Cortex-M0: Data is King. EE Times.
[5] Levy, M. (2020). Deep Learning on MCUs is the Future of Edge Computing. EE Times.
[6] Gruenstein, Alexander & Alvarez, Raziel & Thornton, Chris & Ghodrat, Mohammadali. (2017). A Cascade Architecture for Keyword Spotting on Mobile Devices.
[7] Kumar, A., Saurabh Goyal, and M. Varma. (2017). Resource-efficient Machine Learning in 2 KB RAM for the Internet of Things.
[8] Zhang, Yundong & Suda, Naveen & Lai, Liangzhen & Chandra, Vikas. (2017). Hello Edge: Keyword Spotting on Microcontrollers.
[9] Fedorov, Igor & Stamenovic, Marko & Jensen, Carl & Yang, Li-Chia & Mandell, Ari & Gan, Yiming & Mattina, Matthew & Whatmough, Paul. (2020). TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids.
[10] Lin, Ji & Chen, Wei-Ming & Lin, Yujun & Cohn, John & Gan, Chuang & Han, Song. (2020). MCUNet: Tiny Deep Learning on IoT Devices.
[11] Chen, Tianqi & Moreau, Thierry. (2020). TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.
[12] Weber, Logan, and Reusch, Andrew (2020). TinyML — How TVM is Taming Tiny.
[13] Krishnamoorthi, Raghuraman. (2018). Quantizing deep convolutional networks for efficient inference: A whitepaper.
[14] Yosinski, Jason & Clune, Jeff & Bengio, Y. & Lipson, Hod. (2014). How transferable are features in deep neural networks?.
[15] Lai, Liangzhen & Suda, Naveen & Chandra, Vikas. (2018). CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs.
[16] Chowdhery, Aakanksha & Warden, Pete & Shlens, Jonathon & Howard, Andrew & Rhodes, Rocky. (2019). Visual Wake Words Dataset.
[17] Warden, Pete. (2018). Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition.
[18] Zemlyanikin, Maxim & Smorkalov, Alexander & Khanova, Tatiana & Petrovicheva, Anna & Serebryakov, Grigory. (2019). 512KiB RAM Is Enough! Live Camera Face Recognition DNN on MCU. 2493–2500. 10.1109/ICCVW.2019.00305.
Original Link:
https://towardsdatascience.com/tiny-machine-learning-the-next-ai-revolution-495c26463868
Transferred from WeChat Official Account:AI Frontline
