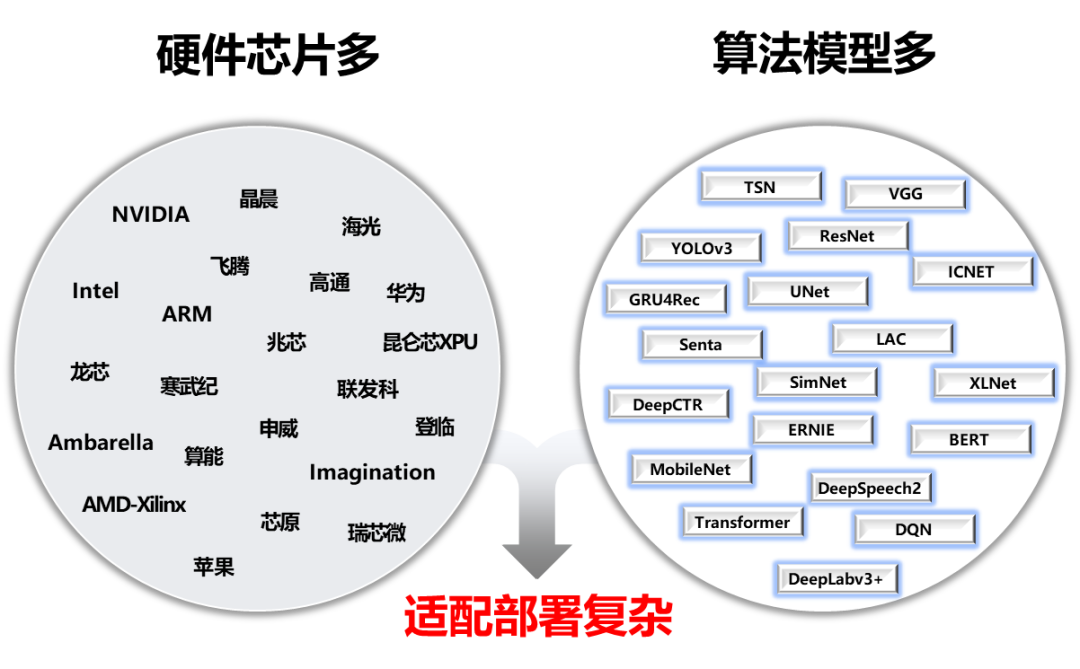
To solve the challenges of AI deployment, we initiated the FastDeploy project. FastDeploy standardizes the model API for important AI models in industrial deployment scenarios, providing downloadable demo examples that can run immediately. Compared to traditional inference engines, it achieves end-to-end inference performance optimization. FastDeploy also supports online (service deployment) and offline deployment forms, catering to different developers’ deployment needs.
After a year of intensive refinement, FastDeploy currently possesses three distinctive capabilities:
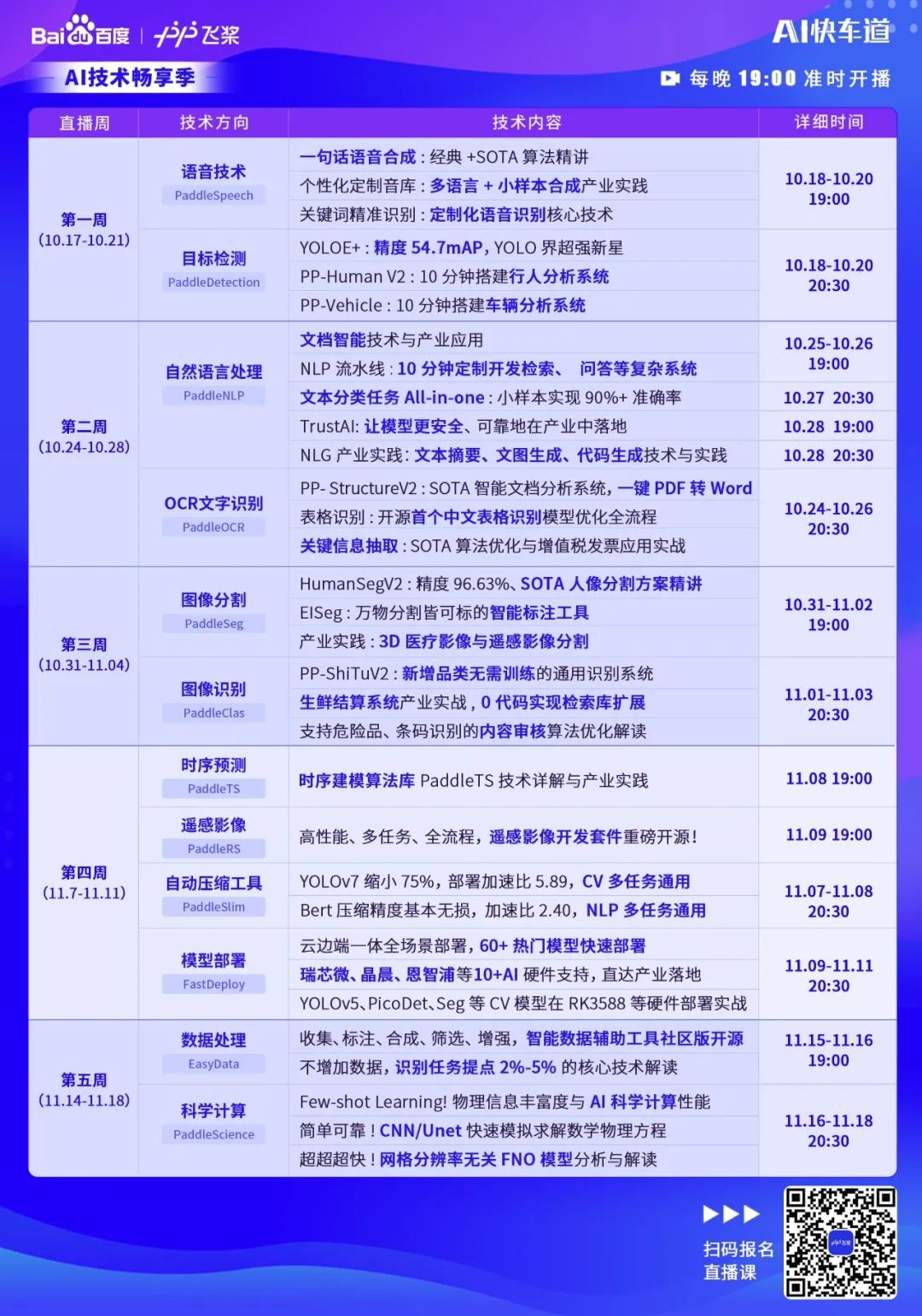
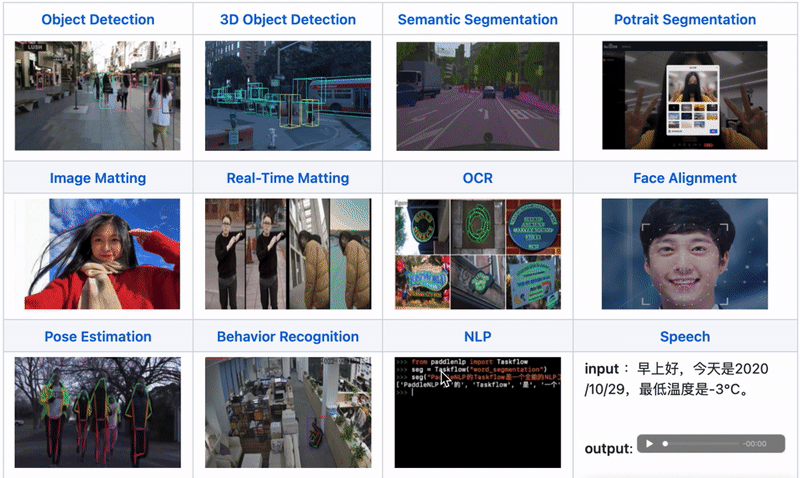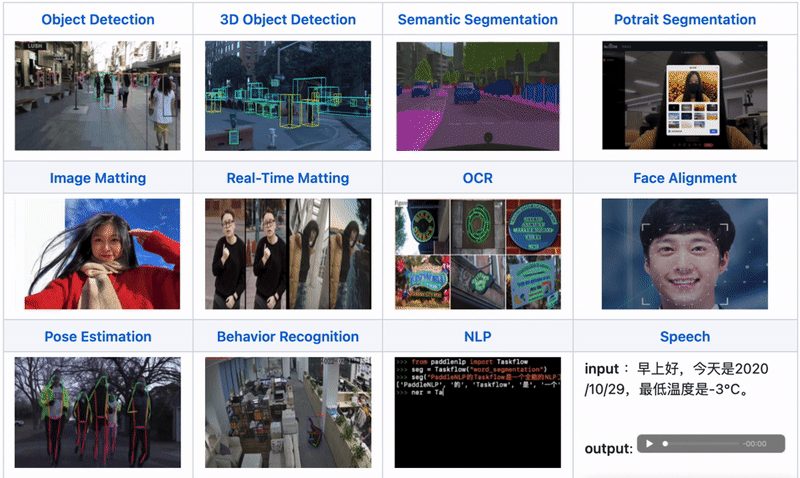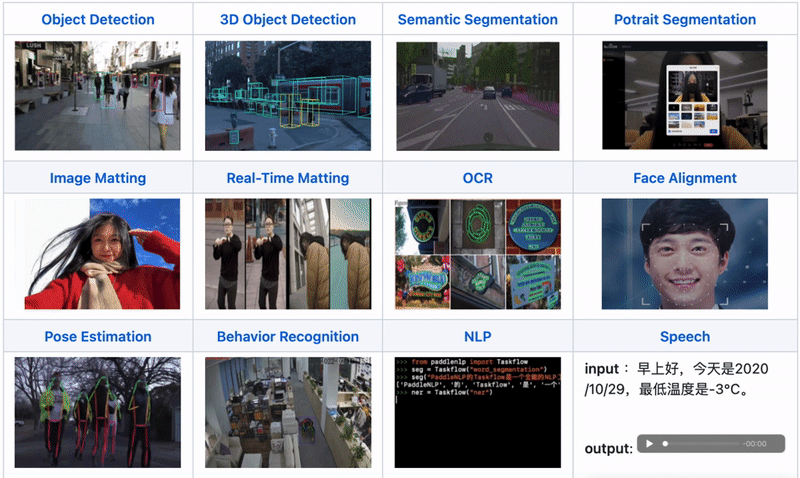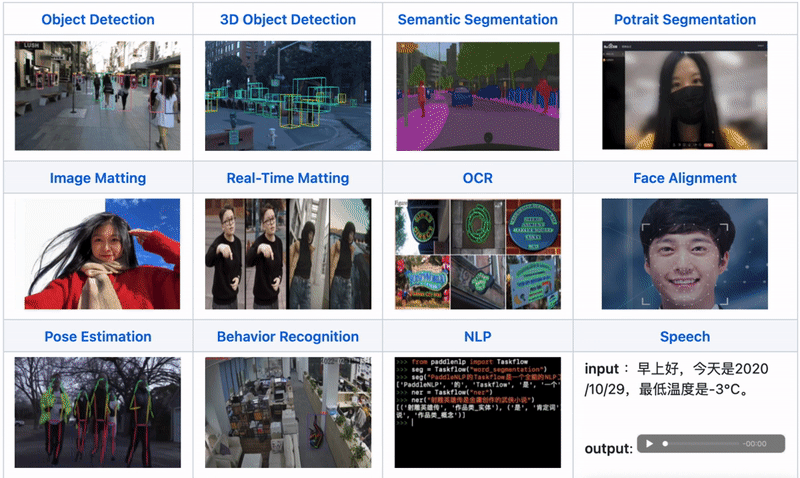
All-Scenario: Supports various hardware including GPU, CPU, Jetson, ARM CPU, Rockchip NPU, Amlogic NPU, and NXP NPU, supporting local deployment, service deployment, web deployment, mobile deployment, etc. It covers three major fields: CV, NLP, and Speech, supporting 16 mainstream algorithm scenarios including image classification, image segmentation, semantic segmentation, object detection, character recognition (OCR), face detection and recognition, portrait cutout, pose estimation, text classification, information extraction, pedestrian tracking, and speech synthesis.
Easy and Flexible: Deploy AI models in just three lines of code, replace models with one API call, and seamlessly switch to other model deployments, providing deployment demos for over 150 popular AI models.
Extreme Efficiency: Unlike traditional deep learning inference engines that only focus on model inference time, FastDeploy emphasizes the end-to-end deployment performance of model tasks. Through high-performance pre- and post-processing, integration of high-performance inference engines, and one-click automatic compression, it achieves extreme performance optimization for AI model inference deployment.
https://github.com/PaddlePaddle/FastDeploy
The following sections will further explain these three major features, with a total of about 2100 words, and an estimated reading time of 3 minutes.
1
Three Major Features
2
Three-Step Deployment Practical Guide
CPU/GPU Deployment Practical Guide
Jetson Deployment Practical Guide
RK3588 Deployment Practical Guide (Similar to RV1126, Amlogic A311D, etc.)
1
Three Major Features Explained
All-Scenario: One Codebase Covers Multi-Platform and Multi-Hardware, Including CV, NLP, and Speech
Easy and Flexible: Deploy Models in Three Lines of Code, Quickly Experience 150+ Popular Model Deployments with One Command
# Deploying PP-YOLOE
import fastdeploy as fd
import cv2
model = fd.vision.detection.PPYOLOE("model.pdmodel",
"model.pdiparams",
"infer_cfg.yml")
im = cv2.imread("test.jpg")
result = model.predict(im)
# Deploying YOLOv7
import fastdeploy as fd
import cv2
model = fd.vision.detection.YOLOv7("model.onnx")
im = cv2.imread("test.jpg")
result = model.predict(im)
FastDeploy for different model deployments
# Deploying PP-YOLOE
import fastdeploy as fd
import cv2
option = fd.RuntimeOption()
option.use_cpu()
option.use_openvino_backend() # Switch to OpenVINO deployment with one command
model = fd.vision.detection.PPYOLOE("model.pdmodel",
"model.pdiparams",
"infer_cfg.yml",
runtime_option=option)
im = cv2.imread("test.jpg")
result = model.predict(im)
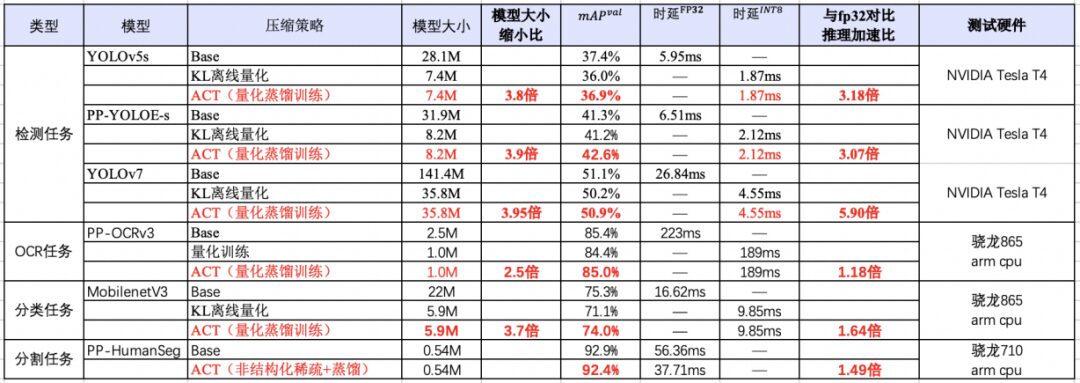
Extreme Efficiency: One-Click Compression and Speed-Up, Preprocessing Acceleration, End-to-End Performance Optimization to Enhance AI Algorithm Deployment
Join the FastDeploy Technical Exchange Group
Group Benefits✨
How to Join the Group✨
-
Scan the QR code below, follow the official account, fill out the questionnaire, and then enter the WeChat group
-
Check the group announcement to receive benefits

To help developers further understand FastDeploy’s deployment capabilities and use them in their projects more quickly, we have prepared a live technical exchange event. Scan the code to join the group and follow our live broadcast room!

2
Three-Step Deployment Practical Guide
1
CPU/GPU Deployment Practical Guide (Taking YOLOv7 as an example)
Install FastDeploy Deployment Package, Download Deployment Example (Optional, deployment code can also be implemented in three lines of API)
pip install fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd examples/vision/detection/yolov7/python/
Prepare Model Files and Test Images
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
CPU/GPU Inference Model
# CPU Inference
python infer.py --model yolov7.onnx --image 000000014439.jpg --device cpu
# GPU Inference
python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu
# Use TensorRT inference on GPU
python infer.py --model yolov7.onnx --image 000000014439.jpg --device gpu --use_trt True
Inference Result Example:

2
Jetson Deployment Practical Guide (Taking YOLOv7 as an example)
Install FastDeploy Deployment Package, Configure Environment Variables
git clone https://github.com/PaddlePaddle/FastDeploy cd FastDeploy
mkdir build && cd build
cmake .. -DBUILD_ON_JETSON=ON -DENABLE_VISION=ON -DCMAKE_INSTALL_PREFIX=${PWD}/install make -j8
make install
cd FastDeploy/build/install
source fastdeploy_init.sh
Prepare Model Files and Test Images
wget https://bj.bcebos.com/paddlehub/fastdeploy/yolov7.onnx
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
Compile Inference Model
cd examples/vision/detection/yolov7/cpp
cmake .. -DFASTDEPLOY_INSTALL_DIR=${FASTDEPOLY_DIR}
mkdir build && cd build
make -j
# Use TensorRT inference (if the model does not support TensorRT, it will automatically switch to CPU inference)
./infer_demo yolov7s.onnx 000000014439.jpg 27s.onnx 000000014439.jpg 2
Inference Result Example:

3
RK3588 Deployment Practical Guide (Taking the lightweight detection network PicoDet as an example)
Install FastDeploy Deployment Package, Download Deployment Example (Optional, deployment code can also be implemented in three lines of API)
# Refer to the compilation documentation to complete FastDeploy compilation and installation
# Documentation link: https://github.com/PaddlePaddle/FastDeploy/blob/develop/docs/cn/build_and_install/rknpu2.md
# Download deployment example code
git clone https://github.com/PaddlePaddle/FastDeploy.git
cd examples/vision/detection/paddledetection/rknpu2/python
Prepare Model Files and Test Images
wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip
unzip -qo picodet_s_416_coco_npu.zip
## Download Paddle Static Graph Model and Unzip
wget https://bj.bcebos.com/fastdeploy/models/rknn2/picodet_s_416_coco_npu.zip
unzip -qo picodet_s_416_coco_npu.zip
# Static Graph to ONNX Model, note that the save_file should match the zip file name
paddle2onnx --model_dir picodet_s_416_coco_npu \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--enable_dev_version True
python -m paddle2onnx.optimize --input_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--output_model picodet_s_416_coco_npu/picodet_s_416_coco_npu.onnx \
--input_shape_dict "{'image':[1,3,416,416]}"
# Convert ONNX Model to RKNN Model
# The converted model will be generated in picodet_s_320_coco_lcnet_non_postprocess directory
python tools/rknpu2/export.py --config_path tools/rknpu2/config/RK3588/picodet_s_416_coco_npu.yaml
# Download Image
wget https://gitee.com/paddlepaddle/PaddleDetection/raw/release/2.4/demo/000000014439.jpg
Inference Model
python3 infer.py --model_file ./picodet _3588/picodet_3588.rknn \
--config_file ./picodet_3588/deploy.yaml \
--image images/000000014439.jpg