Introduction
What happens when you inject 1000 failures into a YMatrix cluster? With the help of chaos testing, the ALOHA high availability architecture introduced in version 5.0 has been rigorously tested before its release; in addition to continuously refining key technologies, the YMatrix R&D team has also introduced advanced engineering methods and practices to ensure the product’s high availability is more reliable.
In YMatrix 5.0, we released our self-developed ALOHA (Advanced Least Operation High Availability) high availability service. As a database product focused on core systems in manufacturing, finance, and vehicle networking scenarios, the importance of stability and high availability is self-evident, and ALOHA is key to the entire system’s stability and high availability. Therefore, from the moment we wrote the first line of code for the project, establishing sufficient high availability testing methods and tools became the top priority of the project, and the ideas and engineering methods of chaos testing were introduced.
In the daily product development process, we usually focus on specific functions, and if we continue to refine, we focus more on a single, specific logic. However, when this single, specific business logic is placed in a real production environment, we often find that relying solely on human effort cannot cover all possibilities; by introducing the ideas and engineering methods of chaos testing, we can test the product in environments that closely resemble or even exceed the complexity of the production environment, thus overcoming the limitations of human effort and allowing for more comprehensive testing of the product.

Why Create ALOHA?
Before version 5.0, YMatrix’s high availability service inherited from Greenplum. Due to the times, the original high availability service operated as part of the database service itself, and during failures, the automatic switching of nodes and instance roles heavily relied on the Master for monitoring and adjudication. This architecture not only brought considerable complexity to subsequent functional development but also had a deeper flaw – “self-monitoring”. Under this logical architecture, when the Master as the adjudicator crashes, it must rely on manual judgment and operation to allow the Standby to begin replacing the Master; in addition, there are various issues in operations like fault recovery, such as the need for manual operations and significant failover delays.
To address this issue, YMatrix abandoned the original high availability architecture and released the self-developed ALOHA (Advanced Least Operation High Availability) high availability service in 5.0. It achieves more sensitive and intelligent cluster state monitoring and management by separating the monitoring and management services from the database process, allowing them to run independently; thanks to this new system, components like MatrixGate and MatrixUI can also achieve better high availability.

Challenge: 1000 Failure Injections
💡Automatic Failover
After enabling “data mirroring,” each data instance (Primary) has a corresponding mirrored data instance (Mirror). When the Primary node fails, the Mirror node will automatically be promoted to Primary, achieving automatic failover.
If the cluster has a standby master node (Standby), then when the master node (Master) fails, the Standby will also be automatically promoted.
The engineers at YMatrix constructed the most rigorous test ever in this typical test case. Under the premise that a cluster maintains workload and services without interruption, inject a random failure every 15 minutes:
-
Network partition (Master node, Standby node, data nodes)
-
Power failure (Master node, Standby node, data nodes)
-
Instance crash (main instance, standby instance, data instance, mirrored data instance)
-
Kill service (cluster, shard, replication, etcd)
-
The database should achieve automatic switching within the expected time (in seconds or minutes) to ensure service availability;
-
Related components such as MatrixGate and MatrixUI can work as expected without service interruption;
-
After a failure, the overall state can be restored without interruption during the service.
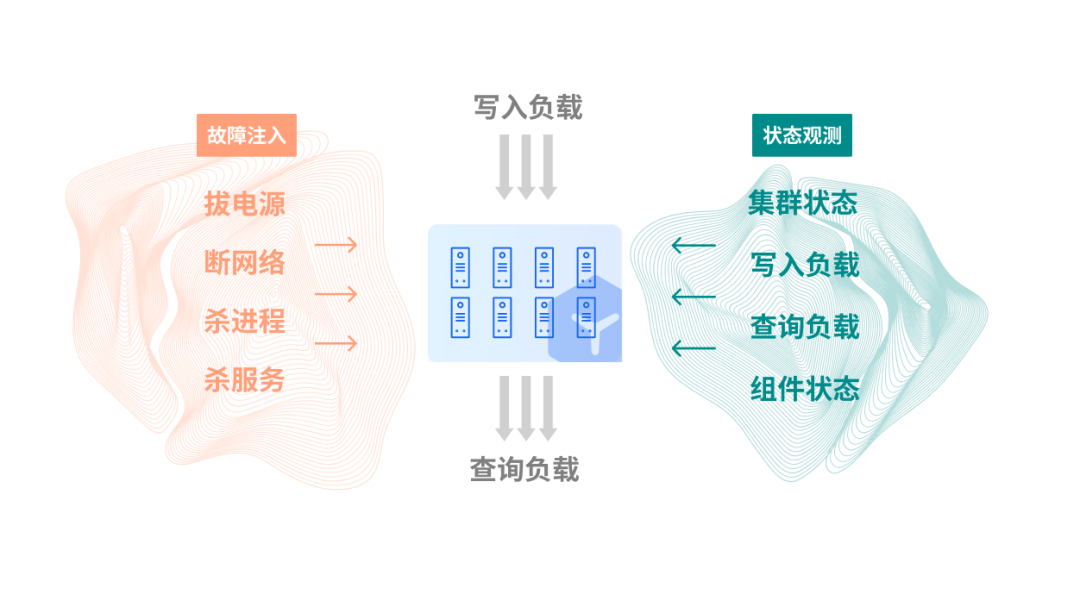
The development and improvement of the testing framework for high availability testing have run through the entire ALOHA project.
At the release of version 5.0, in our testing framework, the simulated business cluster underwent over 10 days of testing, injecting a total of more than 1000 random failures every 15 minutes while maintaining stable cluster service and correctly performing state recovery. Thus, we have finally set an important milestone on the road to “building unbreakable data services”.
In the post-5.0 era, in addition to the high-intensity longevity testing before release, the relevant chaos testing cases for high availability have also been incorporated into daily testing and expanded to other component projects, running at high frequency daily with the R&D progress to ensure the entire YMatrix product is “unbreakable” in terms of high availability.

Undetectable Bugs
The chaos testing for high availability has helped the R&D team discover unexpected issues, with a recent example being a bug in the high availability of MatrixUI.
Phenomenon
During the testing process, the status observation module found that MatrixUI failed to correctly listen on port 8240 to provide HTTP services, and upon inspection, the MatrixUI process was found to be deadlocked, with panic logs present in the logs.
Analysis
Combining the error logs and error injection records, we found that the disconnection was due to the “power failure” fault injected during testing.

Conclusion
MatrixUI aimed to provide a “seamless” user experience during master-slave switching in the cluster by continuing to offer services at the original address. While this enhances user experience during cluster failures, it also significantly increases development difficulty, requiring MatrixUI to decide which process to provide services based on system status.
Due to the numerous system states, it is challenging to cover all logic when different faults overlap solely relying on human effort; with chaos testing, we can discover details overlooked during development, continuously improve the product, and ultimately ensure the stability of YMatrix in harsh environments.

Join Us
The development and testing of the ALOHA high availability architecture have gathered the efforts of many partners. Now, the relevant testing frameworks and cases are running in our daily testing tasks and have played an important role in concentrated testing before version releases.
“Building unbreakable database services” is the vision of YMatrix R&D engineers; writing every line of code is both work and our technical belief :).
If you also want to “build unbreakable database services” with us, come join us.
Recruitment Link🔗: YMatrix is hiring: Distributed Database Development Engineer, remote work supported!

Add YMatrix Assistant
Join the official technical communication group
Phone | 400-800-0824
Official Website |www.ymatrix.cn
Recommended Reading
Building Unbreakable Database Services: YMatrix’s Chaos Engineering Practices (Part 1)

How should databases be selected in the financial industry: banking, securities, insurance…?

Query efficiency improved by 23 times, ZTE joins YMatrix to build a hyper-converged data foundation for a certain operator

