Skip to content
Ceva’s NPU Core Targeting TinyML Workloads
(Dylan McGrath, MPR, September 6, 2024)
Ceva’s NeuPro-Nano is a licensed neural processing unit (NPU) designed for running TinyML workloads, providing up to 200 billion operations per second (GOPS) for power-constrained edge IoT devices. Compared to other competing NPU IP products aimed at IoT edge, NeuPro-Nano can function as an independent solution for AI and machine learning applications; it includes control and management features that can, in some cases, operate without an additional host processor, thereby saving chip area.
AI has shifted to the network edge to reduce latency and bandwidth consumption while enhancing data security (see MPR report January 2020, “AI is Livin’ On The Edge”). TinyML has emerged as a specialized field of machine learning focused on deploying models to the smallest, most energy-efficient edge devices, often running on microcontrollers (MCUs) that cost just a few dollars or less and can run on small batteries for years (see MPR report March 2020, “Deep Learning Gets Smaller”). TinyML typically runs on the main CPU of the processor, but moving AI to the NPU is often more energy-efficient, thus extending the battery life of powered devices.
As NeuPro-Nano hits the market, TinyML chips are experiencing rapid development. With increasing complexity of machine learning models and rising expectations for edge performance, more TinyML chips are integrating NPUs to enhance the energy efficiency of AI acceleration.
NeuPro-Nano is now available in two different licensed configurations. It features a fully programmable, scalable architecture and supports various AI acceleration functions such as sparse acceleration, non-linear activation types, and fast quantization. It expands Ceva’s NPU IP product line, now covering applications from power-constrained edge IoT to automotive, mobile, and generative AI applications that require hundreds of times more AI computing power. To support NeuPro-Nano, Ceva has also expanded its NeuPro Studio AI software development kit (SDK), which supports open AI frameworks including TensorFlow Lite Micro and microTVM, to assist in developing TinyML applications.
Increasingly, applications require intelligence on devices, necessitating extremely compact TinyML models. In consumer electronics, TinyML is used in wearables, smart home, and smart audio devices. In the industrial IoT space, TinyML devices are used to collect and process data from various sensors to monitor equipment health, perform predictive maintenance, diagnose faults through sensor data analysis, help identify root causes of device failures, conduct simple visual inspections for defects or inconsistencies, process monitoring, anomaly detection, defect classification, and other tasks. Battery-powered TinyML systems are also used in healthcare (for remote patient monitoring applications), agriculture (such as livestock monitoring devices), automotive, and smart cities.
Microcontrollers, sensors, and audio SoCs targeting edge AI are increasingly leveraging TinyML to execute models directly. Most TinyML models currently run on MCUs or DSPs, often in conjunction with hardware accelerators to overcome the computational limitations of these general-purpose devices. However, TechInsights expects the number of chips specifically designed for TinyML applications to increase in the coming years.
Battery-powered TinyML chips must be optimized for low power (typically less than 10 milliwatts) and for deployment on resource-constrained hardware. They require up to 10MB of flash, ROM, or RAM and less than 500KB of code storage, along with computational resources for inference tasks. They typically also have the capability to interact with various sensors for data collection and wireless connectivity for data transmission and updates. Some TinyML devices use hardware accelerators to speed up computations. However, today, most TinyML applications run on MCUs, most of which lack AI acceleration.
High-Performance Quantization Units
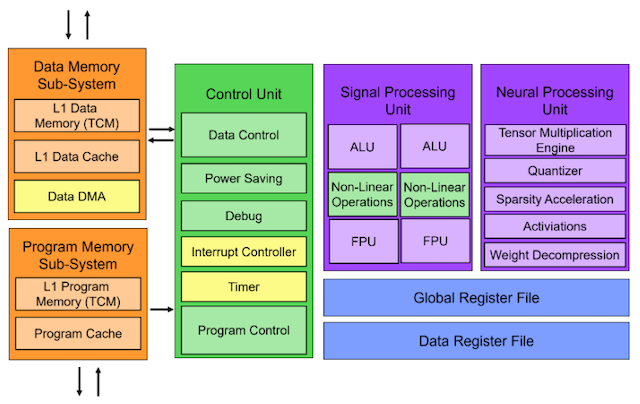
At a high level, the NeuPro-Nano core consists of five modules, as shown in Figure 1: control unit, signal processing unit, an independent data and program storage subsystem, and the NPU module.
The NPU module contains a tensor multiplication engine for performing tensor operations, such as matrix multiplication for AI and convolution for digital signal processing. A special quantizer unit converts high-precision floating-point data to integers to reduce model size.
Figure 1 NeuPro-Nano Structural Module Block Diagram
(The architecture of NeuPro-Nano is significantly different from Ceva’s other licensed NPU cores, including NeuPro-M. It is a more general-purpose NPU design that seeks to balance data path cycles and compute cycles for optimized MAC utilization. (Source: Ceva))
To handle sparse acceleration, the NPU module features a sparsity unit similar to the sparsity unit in Ceva’s NeuPro-M NPU (see MPR report January 2022, “Ceva Tackles Unstructured Sparsity”). However, the sparse acceleration capabilities in NeuPro-Nano are more stringent than the sparsity engine in NeuPro-M (see MPR report September 2023, “NeuPro-M Enhances Support for BF16, FP8”). Sparse support includes two aspects: lossless storage compression (Ceva’s trademarked NetSqueeze, which does not degrade model accuracy) and performance acceleration. To enhance performance, NeuPro-Nano requires sparsity to be semi-structured and supports acceleration of up to 2x. The NeuPro-M sparsity engine can handle additional levels of sparsity and can accelerate sparsity up to 4x.
NetSqueeze dynamic weight decompression technology uses proprietary mechanisms and algorithms to eliminate zero weights to compress memory usage. The NetSqueeze mechanism handles compressed weights directly without any intermediate decompression stage and requires no intervention from software programmers. Advanced hardware prefetching mechanisms reduce traffic overhead and maintain a balance between data path cycles and compute cycles, resulting in higher MAC utilization.
The NPU module also includes weight decompression to optimize the storage and retrieval of neural network weights and activation functions (including ReLU, sigmoid, and tanh).
Integrated Control Functions
Ceva claims that NeuPro-Nano has up to a 45% significant advantage in chip area occupancy over competing solutions, as its integrated control functions can eliminate the need for a host CPU in some cases. Existing TinyML NPUs typically require a companion CPU or MCU to handle general tasks such as feature extraction, sensor interfacing, peripheral control, and system management. In contrast, NeuPro-Nano can operate independently, capable of executing neural networks, feature extraction, and control code.
Many existing TinyML devices utilize Cortex-M or other CPUs for control functions. Device vendors may prefer to continue using the same controllers in future generations to avoid adding software ports. NeuPro-Nano can also be used for multi-core implementations, processing neural network computations alongside CPUs like Cortex-M, which can continue to handle general and system management functions.
The scalability of NeuPro-Nano is an important attribute for TinyML NPUs operating at the edge. It supports up to 64 INT8 data type MACs per cycle.
The architecture is also fully programmable, capable of executing various neural network algorithms and operations. It supports the most common high-level machine learning data types, with precision ranging from 4 bits to 32 bits. It natively supports Transformer models.
Machine Learning Model Optimization
NeuPro-Nano offers several enhancements to improve the efficiency and performance of machine learning models. It implements sparse acceleration techniques to reduce the computation of weights with zero values in neural networks. It accelerates the performance of non-linear activation functions (such as ReLU, sigmoid, and tanh).
Quantization techniques are becoming increasingly popular in machine learning, as they can reduce model size, lower storage and power requirements, and improve computation speed by converting high-precision floating-point numbers (e.g., 32-bit floats) into low-precision integer formats (e.g., 8-bit integers). The trade-off of quantization is a decrease in model accuracy, although the extent of accuracy loss depends on several factors, including the specific quantization technique used and the architecture of the model.
Ceva has developed a fast quantization technique that uses a dedicated proprietary instruction set architecture and natively supports fast approximate TFLM quantization, a technique that accelerates TensorFlow Lite model (TFLM) quantization without sacrificing significant accuracy. Ceva claims that its implementation of these mechanisms can speed up the quantization of TFLM models by up to 5 times. Additionally, NeuPro-Nano implements an online real-time weight decompression tool to reduce the memory footprint required by the model.
Standalone Product with Independent Functionality
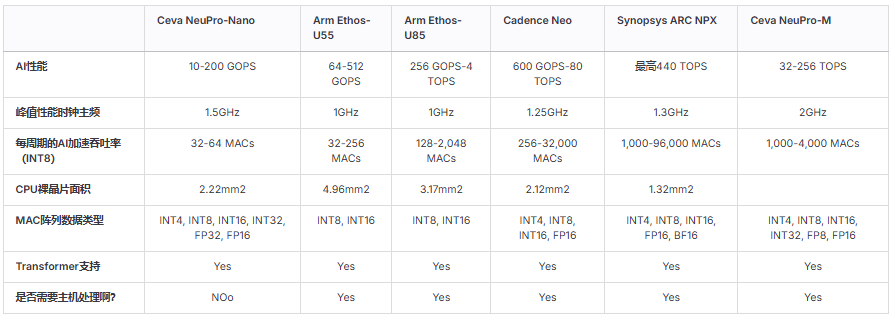
Other leading IP vendors also offer licensed NPU cores for edge applications. Arm’s Ethos-U55 (see MPR report March 2020, “Cortex-M55 Supports Tiny-AI Ethos”), Synopsys ARC NPX NPU (see MPR report April 2022, “Synopsys NPX6 Expands AI Options”), and Cadence Neo NPU (see MPR report October 2023, “Cadence Boosts DLA Speed by 20 Times”) are scalable IP cores that support a wide range of computational capabilities. Ceva offers separate licensed NPU cores that compete with these products at the high end.
Among the three competitors, Ethos-U55 has the most similar performance and acceleration features to NeuPro-Nano; like NeuPro-Nano, Ethos-U55 is a highly customizable edge AI NPU designed specifically to accelerate machine learning inference in embedded and IoT devices with constrained chip area (Arm offers Ethos-U65 and Ethos-U85 for embedded AI applications requiring higher performance). Neo and NPX are scalable, covering a broader range of AI performance and MAC acceleration capabilities for higher-end applications.
Of the products considered, only Ceva’s NeuPro-Nano can be implemented as a self-sufficient solution with integrated CPU functionality, as shown in Table 1. Ethos-U85, ARC NPX, and Neo require a host processor as a central control unit to handle control and management functions, allocate tasks, transfer data, and control communications. As mentioned, at least in the initial stages, few customers may consider NeuPro-Nano as a self-sufficient core.
Like Ceva, Arm, Synopsys, and Cadence also provide comprehensive software stacks and SDKs to simplify the development and deployment of TinyML applications.
Table 1 Comparison of Licensed NPU IP
(NeuPro-Nano optimized for TinyML workloads is at the low end of Ceva’s IP portfolio, while NeuPro-M provides higher AI performance for applications such as computer vision and ADAS. Arm’s Ethos product line can also scale to higher performance levels, as can Cadence’s Neo and Synopsys’ NPX. (Source: Vendors))
Small Scale but Growing Opportunities
Ceva’s NeuPro-Nano is specifically designed for resource-constrained edge devices running TinyML workloads, but combines many features offered by Ceva’s more powerful NPUs like NeuPro-M, along with energy efficiency optimization technologies such as dynamic energy adjustment, sparse acceleration, and dynamic voltage acceleration.
Most current IoT chips running AI operate in the cloud. Among those that perform some AI on-device, most run AI in software on the CPU rather than allocating additional chip area for an NPU. However, battery-powered IoT systems gain critical energy savings from the implementation of NPUs, which provide a more efficient way to execute neural networks. Thus, the demand for NPUs in edge IoT is increasing, especially for battery-powered systems. But despite the market potentially growing, it is also filled with competition. Due to the low cost of developing and providing simple AI cores, NeuPro-Nano faces competition from the well-known IP vendors mentioned above as well as from AI IP startups with different features, areas, performance, and power consumption characteristics.
NeuPro-Nano stands out among licensed NPU cores targeting TinyML devices because it can be implemented as an independent core that can execute not only neural networks but also control code, DSP code, and feature extraction. While this differentiates NeuPro-Nano, MPR expects this capability will only attract a relatively small market subset. Due to the relatively limited performance of NeuPro-Nano, many architectures will continue to require a host CPU. Chip companies are often reluctant to port their Arm software to different architectures, especially new architectures with limited and unproven software tools and operating system support (note that despite years of attempts, RISC-V adoption in MCUs remains limited). However, customers willing to make this leap will benefit from the smaller footprint of implementing an independent NPU with integrated CPU functionality, with Ceva estimating savings of up to 45% in chip area compared to a combination of NPU and host processor.
In summary, NeuPro-Nano enters a relatively small but growing NPU market for battery-powered IoT edge system-on-chip applications, with a unique value proposition. While the market opportunity for self-sufficient NPU cores with integrated CPU functionality seems limited in the short term, it may accelerate as demand for edge AI grows. For applications where AI is a primary function, MCU vendors may create products lacking traditional Arm-based host CPUs, relying solely on NPUs like NeuPro-Nano. Keeping a close eye on leading MCU vendors should clearly indicate that the self-sufficient NPU approach is rapidly gaining popularity.
* An early example of edge AI devices without significant CPU cores is Syntiant’s NDP250: “Syntiant’s NDP250 Enhances Storage”.
* Interested in exploring the data center AI chip market? Check out “TechInsights’ AI Chip and Accelerator Forecast”.
* Looking for a report on Arm’s Ethos-U85 NPU? See “Ethos-U85 Adds Transformer Support”.
* Want to know more about the NPU IP market? See “Synopsys NPX6 Expands AI Options”.
* Need more background on TinyML? Check out “Deep Learning Gets Smaller”.