Article Summary
This article introduces TorchSparse, a high-performance inference engine designed specifically for point cloud computing, which improves the efficiency of point cloud processing by optimizing sparse convolution calculations.
1. Background and Challenges:
– With the popularity of 3D sensors (such as LiDAR and depth cameras), the application of 3D point clouds in AR/VR and autonomous driving is becoming increasingly widespread.
– 3D point cloud data is sparse and irregular, making it difficult for traditional hardware to efficiently handle sparse convolution calculations.
– Existing sparse acceleration technologies are not suitable for 3D point clouds, and sparse convolution libraries such as MinkowskiEngine and SpConv perform inadequately on general-purpose hardware.
2. Introduction to TorchSparse:
– TorchSparse is an inference engine optimized for point cloud computing that improves efficiency by enhancing computational regularity and reducing memory usage.
– It employs techniques such as adaptive matrix multiplication grouping, quantization, vectorized memory access, and locality-aware memory access optimizations.
3. Performance Evaluation:
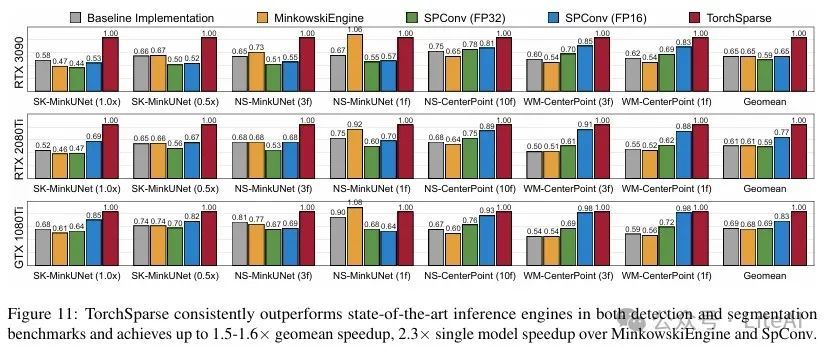
– Seven representative models were evaluated on three benchmark datasets, with TorchSparse achieving 1.6x and 1.5x end-to-end acceleration compared to MinkowskiEngine and SpConv, respectively.
– On NVIDIA GTX 1080Ti, RTX 2080Ti, and RTX 3090 GPUs, TorchSparse meets real-time processing requirements (≥10FPS).
4. Ablation Study:
– A detailed ablation study was conducted on matrix multiplication, data movement, and mapping operations to verify the effectiveness of each optimization strategy.
– The adaptive grouping strategy demonstrated excellent performance in matrix multiplication, while quantization and vectorized memory access significantly reduced data movement latency, and the optimization of mapping operations also led to notable performance improvements.

Article link: https://arxiv.org/pdf/2204.10319
Project link: https://github.com/mit-han-lab/torchsparse

TL;DR
Article Methodology
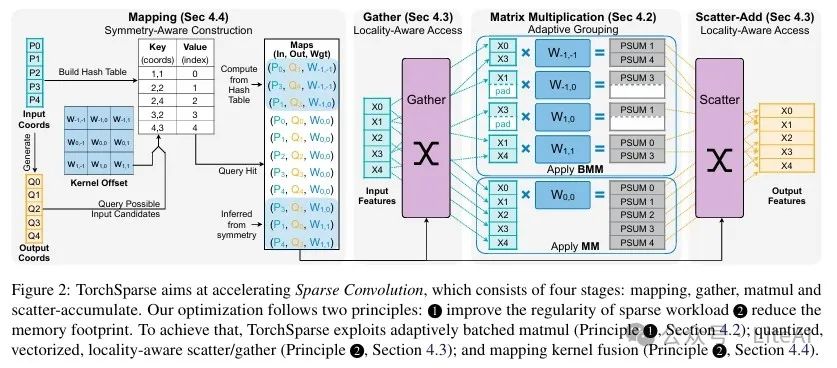
1. Optimization Principles of TorchSparse:
– Improve computational regularity: By adaptively grouping matrix multiplication, batch processing the computation of different kernel offsets, trading off redundant calculations for better regularity.
– Reduce memory usage: Utilizing quantization, vectorized memory transactions, and locality-aware memory access patterns to minimize data movement costs.
2. Matrix Multiplication Optimization:
– Symmetric grouping: For odd kernel sizes and stride of 1 in sparse convolution, combine the computation of symmetric kernel offsets to naturally form a batch size of 2.
– Fixed grouping: Divide the computation into three groups and pad the features within each group to reach the maximum size, suitable for downsampling layers.
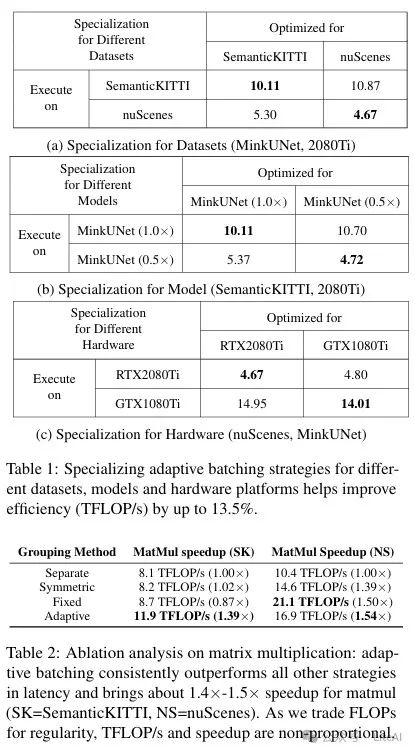
– Adaptive grouping: Automatically determine the adaptive grouping strategy for inputs, dynamically maintaining the grouping through two adjustable parameters (redundant computation tolerance and workload threshold).
3. Data Movement Optimization:
– Quantization and vectorized memory access: FP16 quantization reduces DRAM access by half, and combined with vectorized memory transactions further reduces data movement latency.
– Fusion and locality-aware memory access: Fuse all gather operations before matrix multiplication and all scatter operations after matrix multiplication, using a locality-aware memory access order to maximize data reuse.
4. Mapping Operation Optimization:
– Select mapping search strategy: Choose an appropriate mapping search strategy from [grid, hashmap].
– Kernel fusion: Fuse multiple stages of downsampling operations into one kernel to reduce DRAM access frequency.
Experimental Results
1. Overall Performance Improvement:
– TorchSparse achieved 1.6x and 1.5x end-to-end acceleration over seven representative models, outperforming MinkowskiEngine and SpConv, respectively.
– On NVIDIA GTX 1080Ti, RTX 2080Ti, and RTX 3090 GPUs, TorchSparse meets real-time processing requirements (≥10FPS).
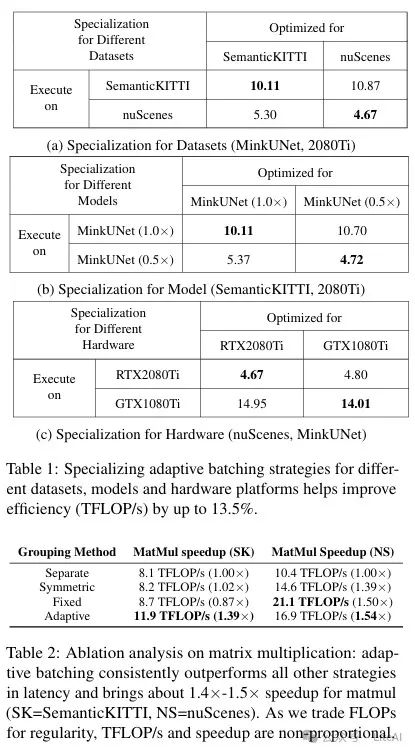
2. Matrix Multiplication Optimization Results:
– The adaptive grouping strategy performed excellently in matrix multiplication, achieving 1.4x to 1.5x acceleration compared to the baseline without grouping.
– The manually designed fixed grouping strategy performed poorly on certain datasets and models, indicating the necessity of the adaptive grouping strategy.
3. Data Movement Optimization Results:
– Quantization and vectorized memory access significantly reduced data movement latency, achieving an overall data movement acceleration of 2.72x.
– Fusion and locality-aware memory access patterns further improved data reuse, achieving 2.86x gather acceleration and 2.61x scatter acceleration.
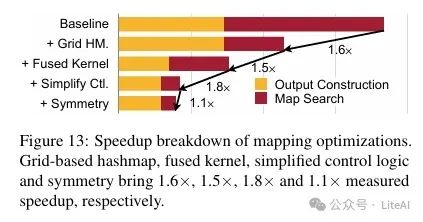
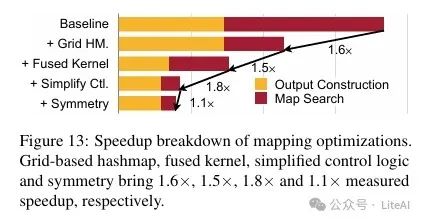
4. Mapping Operation Optimization Results:
– Grid-based mapping search is 2.7x faster than general hashmap-based solutions, achieving 1.6x end-to-end mapping acceleration.
– Kernel fusion and simplified control logic optimizations further improved the efficiency of mapping operations, ultimately achieving 4.6x end-to-end mapping acceleration.
5. Hardware Platform Adaptability:
– TorchSparse performed excellently on GTX 1080Ti, RTX 2080Ti, and RTX 3090 GPUs, achieving 1.5x acceleration even on GTX 1080Ti without FP16 tensor cores.
Final Thoughts
Scan the code to add me, or add WeChat (ID: LiteAI01), for technical, career, and professional planning discussions, please note “Research Direction + School/Region + Name”