
 Currently, most mainstream smart voice solutions on the market use online voice recognition combined with platform content to create a rich smart home ecosystem. However, the online connected method has also brought many uncertainties: privacy security, network latency, interaction speed, and connection stability. Therefore, offline localized voice control solutions on the edge have become another choice for users.
Currently, most mainstream smart voice solutions on the market use online voice recognition combined with platform content to create a rich smart home ecosystem. However, the online connected method has also brought many uncertainties: privacy security, network latency, interaction speed, and connection stability. Therefore, offline localized voice control solutions on the edge have become another choice for users.
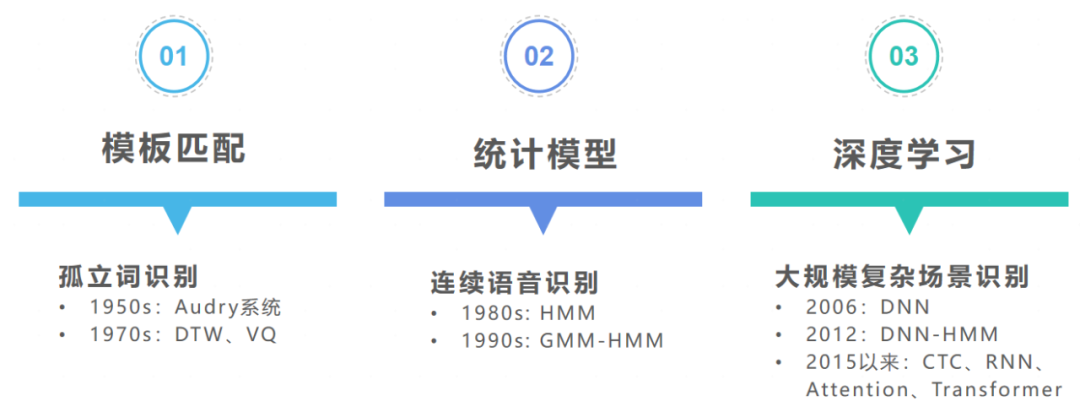
Modern voice recognition can be traced back to 1952 when Davis and others developed the world’s first experimental system capable of recognizing 10 English digits, officially starting the voice recognition process. Voice recognition has developed over more than 70 years, but from a technical perspective, it can generally be divided into three stages:
In terms of the scope of recognition, voice recognition can be divided into “open domain recognition” and “closed domain recognition”:
| Open Domain Recognition | Closed Domain Recognition |
|---|---|
| No pre-set recognition word set required | Requires a pre-set limited word set |
| Models are generally larger, with high engine computation | Recognition engines require fewer hardware resources |
| Relies on cloud-based “online” recognition | “Offline” voice recognition deployed on embedded devices |
| Mainly aimed at multi-turn dialogue interactions | Mainly for simple device control scenarios |
Edge voice recognition falls under the category of closed domain recognition.
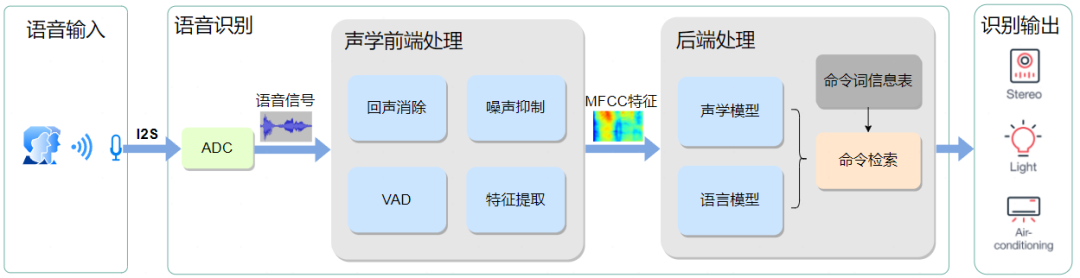
The workflow of voice recognition technology is shown in the following diagram:
-
The device microphone receives the raw voice, and the ADC converts the analog signal into a digital signal.
-
The acoustic front-end module performs echo cancellation, noise suppression, and voice activity detection to eliminate non-speech signals, then extracts MFCC features from normal speech signals. For detailed steps, refer to: 【TinyML】Tflite-micro implements offline command recognition on ESP32
-
The back-end processing part takes the voice features as input for the acoustic model to perform model inference, then combines with the language model to compute the score for command recognition, retrieves the command set based on the highest score, and finally outputs the recognition result. 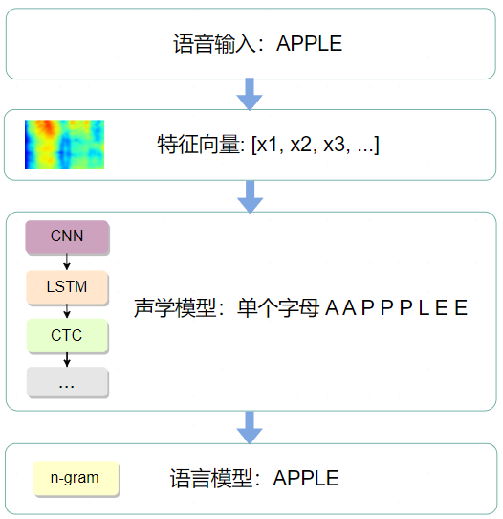
The back-end recognition process can be understood as decoding the feature vector into text, which requires processing through two models: Acoustic Model: This can be understood as modeling the sounds, converting voice input into acoustic representation output, or more accurately, giving the probability of the speech belonging to a certain acoustic symbol. In English, this acoustic symbol can be a syllable or a smaller phoneme; in Chinese, this acoustic symbol can be a tone or a phoneme as small as in English. Language Model: Resolves the issue of homophones by finding the most probable string sequence from the candidate text sequences after the acoustic model provides the pronunciation sequence. The language model also constrains and re-scores the acoustic decoding to ensure the final recognition result conforms to grammatical rules. The most common are N-Gram language models and RNN-based language models.
-
Model Optimization and Compression: Various optimization algorithms such as hyperdimensional computing, memory swapping mechanisms, and constrained neural architecture search are proposed to reduce model size and computational demands through techniques like quantization, pruning, and knowledge distillation, while maintaining high accuracy.
-
Low Latency Real-time Processing: By adopting low-latency acoustic feature extraction algorithms, improved model inference methods, and streaming recognition techniques, while meeting real-time requirements, high accuracy is maintained.
-
Edge Acoustic Environment Adaptation: Noise suppression algorithms, data augmentation for acoustic model training in various noise environments, and multi-channel audio processing.
-
Open Source Tools
| Tool | Description | Programming Language | Link |
|---|---|---|---|
|
|
Kaldi is a powerful speech recognition toolkit that supports various acoustic modeling and decoding techniques. It provides a series of tools and libraries for acoustic model training, feature extraction, decoding, etc. |
C++ Shell Python |
https://github.com/kaldi-asr/kaldi |
|
vosk-api |
Vosk is an offline open-source speech recognition tool. It can recognize 16 languages, including Chinese. |
Python |
https://github.com/alphacep/vosk-api |
|
PocketSphinx |
Another small speech recognition engine developed by Carnegie Mellon University, suitable for embedded systems and mobile applications. |
Python C/C++ |
https://github.com/cmusphinx/pocketsphinx |
|
DeepSpeech |
An open-source speech recognition engine developed by Mozilla, using RNN and CNN to process acoustic features, providing pre-trained models for use. |
Python |
https://github.com/mozilla/DeepSpeech |
|
Julius |
An open-source large vocabulary continuous speech recognition engine supporting multiple languages and models. |
C/C++ |
https://github.com/julius-speech/julius |
|
HTK |
HTK is a toolkit for building hidden Markov models (HMMs). |
C |
https://htk.eng.cam.ac.uk/ |
|
ESPnet |
An end-to-end speech processing toolkit, including tasks such as speech recognition and synthesis. |
Python Shell |
https://github.com/espnet/espnet |
-
Open Source Inference Frameworks
| Platform Framework | Description | Programming Language |
|---|---|---|
|
Tensorflow-Lite |
A lightweight machine learning inference framework developed by Google specifically for mobile devices, embedded systems, and edge devices. |
|
|
uTVM |
uTVM is a branch of TVM, focusing on low-latency, efficient deep learning model inference on embedded systems, edge devices, and IoT devices. |
|
|
Edge Impulse |
Edge Impulse is an end-to-end platform for developing and deploying machine learning models for IoT devices, supporting rich sensor and data integration, model development tools, model deployment, and inference. |
C/C++ |
|
NCNN |
ncnn is an optimized neural network computing library focused on high-performance, efficient deep learning model inference on resource-constrained devices. |
|
-
Open Source Databases
| Database | Description | Link |
|---|---|---|
|
TIMIT |
TIMIT is a widely used dataset for speech recognition research, containing read sentences from speakers with various American English accents. It includes sentences recorded by speakers of various accents, genders, and ages for training and testing speech recognition systems. |
https://catalog.ldc.upenn.edu/LDC93s1 |
|
LibriSpeech |
LibriSpeech is a large dataset for speech recognition, containing audio and text from public domain English readings. |
http://www.openslr.org/94/ |
|
Speech Ocean |
Speech Ocean provides multi-language, cross-domain, and cross-modal AI data and related data services to the entire industry. |
https://www.speechocean.com/dsvoice/catid-52.htm |
|
Data Tang |
Data Tang is a domestic AI data service company providing training datasets, data collection, and annotation customization services. |
https://www.datatang.com/ |
| Supplier | Chip Module | Wake-up and Command Customization | Iteration Method |
|---|---|---|---|
|
Qiying Tailun |
CI120 Series CI130 Series CI230 Series |
https://aiplatform.chipintelli.com/home/index.html |
Serial Port Burning OTA |
|
Hailin Technology |
HLK-v20 |
http://voice.hlktech.com/yunSound/public/toWebLogin |
Serial Port Burning |
|
Anxinke |
VC Series Modules |
https://udp.hivoice.cn/solutionai |
Serial Port Burning |
|
Jixin Intelligent |
SU-03T SU-1X Series SU-3X Series |
https://udp.hivoice.cn/solutionai |
Serial Port Burning |
|
Weichuang Zhiyin |
WTK6900 |
Offline Customization Service |
– |
|
Jiuzhou Electronics |
NRK330x Series |
Offline Customization Service |
– |
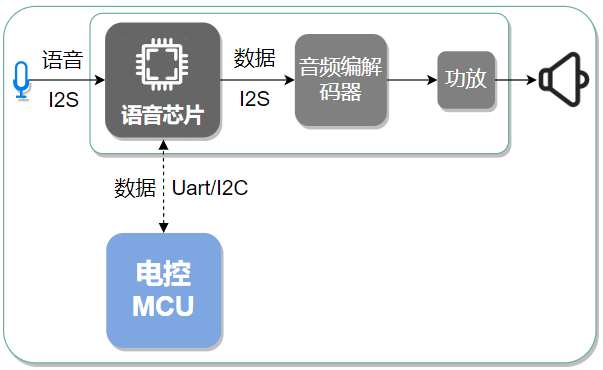
Voice chip modules usually do not require external circuits; they can work by connecting to power, MIC, and speakers.
| Manufacturer | Framework | Related Link |
|---|---|---|
|
|
esp-adf voice development framework, based on ESP-IDF infrastructure and esp-sr voice recognition processing algorithm library. |
https://github.com/espressif/esp-adf/tree/master |
|
STM32 |
Provides an end-to-end solution allowing developers to quickly deploy various AI models on STM32 microcontrollers. |
https://stm32ai.st.com/stm32-cube-ai/ |
|
Siliconlabs |
Provides the MLTK toolset |
https://siliconlabs.github.io/mltk/ |
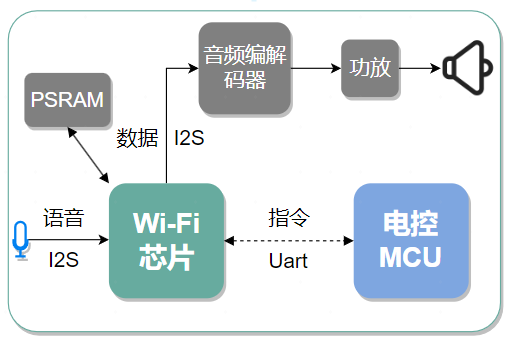
The hardware framework used is shown in the above figure. Since neural network inference is required, to ensure the accuracy of voice recognition, models such as LSTM or Seq2Seq are generally introduced, leading to larger final model files and certain memory resource requirements during runtime, so external Flash or SDCard is usually needed.
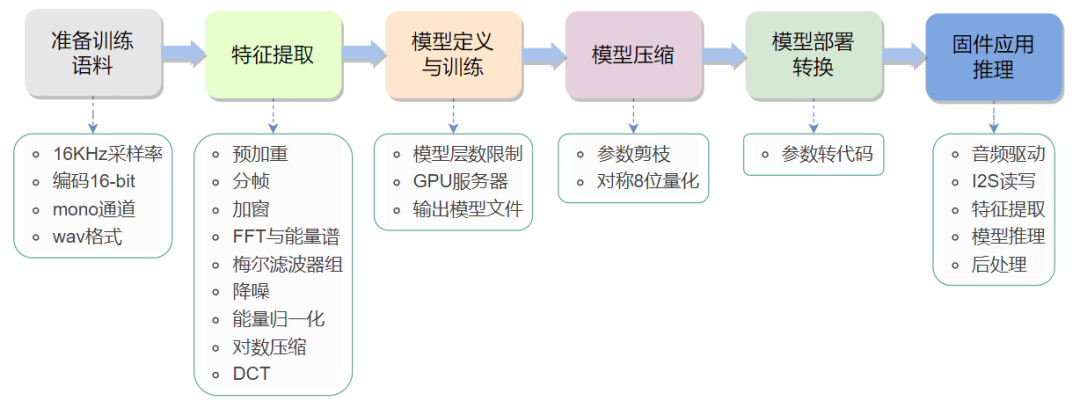
The biggest advantage of open-source frameworks based on neural networks is full process self-control, including model training and deployment, while the downside is that the process is longer, and designing and tuning the network model is a significant challenge. The main process is shown in the above figure, and detailed steps can be found in 【TinyML】Tflite-micro implements offline command recognition on ESP32.
Neural network chips usually have high computing power, capable of meeting complex functional requirements, but are also more expensive, mainly used in smart speakers and intelligent voice control scenarios.
| Manufacturer | Model |
|---|---|
|
Allwinner Technology |
R328, R58, R16, H6, F1C600 |
|
Amlogic |
A113X, A112, S905D |
|
BEKEN |
BK3260 |
|
Intel |
Atom x5-Z8350 |
|
MTK |
MT7668, MT7658, MT8167A, MT8765V, MT7688AN, MT8516, MT2601 |
|
Rockchip |
RK3308, RK3229, RK3326, OS1000RK |
|
iFlytek |
CSK4002 |
Previous Recommendations