

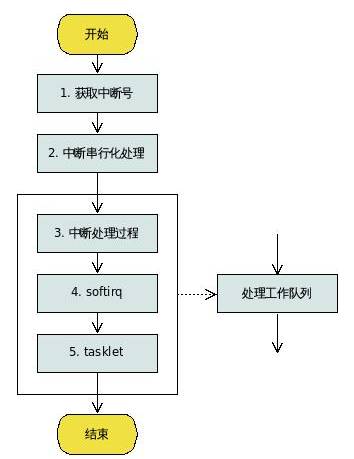
Stage One: Obtaining the Interrupt Number
Each CPU has the ability to respond to interrupts. When a CPU responds to an interrupt, it follows the same process. This process is the interrupt service routine provided by the kernel.
Upon entering the interrupt service routine, the CPU has automatically disabled interrupt responses on that CPU, as the CPU cannot assume that the interrupt service routine is reentrant.
The first step of the interrupt handler does two things:
1. Push the interrupt number onto the stack; (Different interrupt numbers correspond to different interrupt service routine entry points) 2. Push the current register information onto the stack; (to restore upon exiting the interrupt)
Clearly, these two steps are non-reentrant (if interrupted while saving register values, other operations may overwrite the registers, making recovery impossible), so the CPU must automatically disable interrupts when entering the interrupt service routine.
The information on the stack is used as function parameters to call the do_IRQ function.
Stage Two: Interrupt Serialization
Upon entering the do_IRQ function, the first step is to serialize the interrupt, handling a specific interrupt generated simultaneously by multiple CPUs. The method is that if the current interrupt is in the “executing” state (indicating another CPU is handling the same interrupt), it resets its “trigger” flag and returns immediately. The CPU that is handling the same interrupt will check the “trigger” flag again after completing its handling; if set, it will trigger the handling process again.
Thus, the handling of interrupts is a loop process, with each loop calling handle_IRQ_event to handle the interrupt.
Stage Three: Interrupt Handling Under Disabled Interrupt Conditions
Upon entering the handle_IRQ_event function, it calls the corresponding interrupt handler registered through the request_irq function in the kernel or kernel module.
The registered interrupt handler has an interrupt switch property; under normal circumstances, the interrupt handler is always executed with interrupts disabled. However, when calling request_irq to register the interrupt handler, it can also be set to operate with interrupts enabled. This situation is rare because it requires the interrupt handling code to be reentrant. (Additionally, if interrupts are enabled here, the currently handling interrupt will generally be blocked. Because while handling an interrupt, the hardware interrupt controller has not acknowledged this interrupt, the hardware will not initiate the next identical interrupt).
The interrupt handler’s process may be lengthy; if the entire process runs with interrupts disabled, subsequent interrupts will be blocked for a long time.
Thus, soft_irq was introduced. The non-reentrant part is completed in the interrupt handler (with interrupts disabled), and then raise_softirq is called to set a soft interrupt, ending the interrupt handler. The subsequent work will be done in soft_irq.
Stage Four: Soft Interrupt Handling Under Enabled Interrupt Conditions
After the previous stage loops through all triggered interrupt handlers, the do_softirq function is called to start handling software interrupts.
In the soft interrupt mechanism, a bitmask set is maintained for each CPU, with each bit representing an interrupt number. In the previous stage’s interrupt handler, raise_softirq was called to set the corresponding soft interrupt; at this point, the handler corresponding to the soft interrupt will be called (the handler is registered by open_softirq).
It can be seen that the soft interrupt model is very similar to that of interrupts; each CPU has a set of interrupt numbers, each interrupt has its corresponding priority, and each CPU handles its own interrupts. The biggest difference is between enabled and disabled interrupts.
Thus, an interrupt handling process is divided into two parts: the first part runs with interrupts disabled, while the second part runs with interrupts enabled.
Since this step runs with interrupts enabled, new interrupts may occur (interrupt nesting), and the interrupt handling corresponding to the new interrupt will start a new first to third stage. In this new third stage, new soft interrupts may also be triggered. However, this new interrupt handling process will not enter the fourth stage; instead, when it detects that it is a nested interrupt, it will exit after completing the third stage. In other words, only the first layer of the interrupt handling process will enter the fourth stage; the nested interrupt handling process will only execute up to the third stage.
However, the nested interrupt handling process may also trigger soft interrupts, so the first layer of the interrupt handling process in the fourth stage needs to be a loop process, continuously handling all nested soft interrupts. Why is this necessary? Because this allows soft interrupts to be executed in the order they were triggered; otherwise, later soft interrupts might complete before earlier ones.
In extreme cases, nested soft interrupts may be very numerous, and handling them all may take a long time. Thus, the kernel will, after handling a certain number of soft interrupts, push the remaining unhandled soft interrupts to a kernel thread called ksoftirqd for processing, then end the current interrupt handling process.
Stage Five: Tasklet Under Enabled Interrupt Conditions
In fact, soft interrupts are rarely used directly. The processing in the second part that runs under enabled interrupt conditions is generally completed by the tasklet mechanism.
A tasklet is derived from soft interrupts; the kernel defines two soft interrupt masks, HI_SOFTIRQ and TASKLET_SOFTIRQ (with different priorities), and the soft interrupt handlers corresponding to these two masks serve as entry points into the tasklet processing process.
Thus, in the interrupt handler of the third stage, after completing the part that disabled interrupts, tasklet_schedule/tasklet_hi_schedule is called to mark a tasklet, and then the interrupt handler ends. The subsequent work is handled by the soft interrupt handlers corresponding to HI_SOFTIRQ/TASKLET_SOFTIRQ for the marked tasklet (each tasklet has its processing function set during initialization).
It seems that tasklets are just an additional layer of calls on top of softirqs; what is their function? As mentioned earlier, softirqs correspond to CPUs, with each CPU handling its own softirqs. These softirq handlers need to be designed as reentrant because they may run simultaneously on multiple CPUs. In contrast, tasklets are executed serially across multiple CPUs, so their handling functions do not need to consider reentrance.
However, softirqs are still less convoluted than tasklets, so a few processes with higher real-time requirements are still directly implemented using softirqs after careful design. For example: clock interrupt handling processes, network send/receive handling processes.
Conclusion Stage
After the CPU receives an interrupt, the interrupt handling is completed through the above five stages. Finally, the register information saved on the stack in the first stage needs to be restored. The interrupt handling ends.
About Scheduling
The above process also implicitly raises a question: the entire processing process continuously occupies the CPU (except when a new interrupt may interrupt under enabled interrupt conditions). Furthermore, during the several stages of interrupt handling, the program cannot relinquish the CPU!
This is determined by the design of the kernel. The interrupt service routine does not have its own task structure (i.e., the process control block mentioned in operating systems textbooks), so it cannot be scheduled by the kernel. Typically, when a process relinquishes the CPU, if certain conditions are met, the kernel will find it through its task structure and schedule it to run.
Two potential issues may arise here:
1. Continuous low-priority interrupts may continuously occupy the CPU, preventing high-priority processes from obtaining CPU access; 2. Functions that may cause sleep (including memory allocation) cannot be called during these stages of interrupt handling;
Regarding the first issue, newer Linux kernels have added the ksoftirqd kernel thread. If the processing of softirqs continues beyond a certain number, it will end the interrupt handling process and wake up ksoftirqd to continue processing. Although softirqs may be pushed to be handled by the ksoftirqd kernel thread, they still cannot sleep during softirq processing because it cannot guarantee that softirqs will be handled in the ksoftirqd kernel thread.
It is said that in Montavista (a type of embedded real-time Linux), the kernel’s interrupt mechanism has been modified. The interrupt handling process of certain interrupts has been given a task structure, allowing it to be scheduled by the kernel, solving the two issues mentioned above (Montavista’s goal is real-time performance, which sacrifices some overall performance).
Work Queue
The baseline version of the Linux kernel provides a workqueue mechanism to address the above issues.
A work structure is defined (containing a processing function), and then at some point in the above interrupt handling stages, the schedule_work function is called. The work is added to the workqueue, waiting for processing.
Work queues have their own processing threads; these works are pushed to these threads for processing. The processing can only occur within these worker threads, so sleeping is allowed here.
The kernel starts a work queue by default, corresponding to a set of worker threads events/n (where n represents the processor number, meaning there are n such threads). Drivers can directly add tasks to this work queue. Some drivers may also create and use their own work queues.



 WeChat ID: BDCollegedy
WeChat ID: BDCollegedy Long press the left QR code to follow
Long press the left QR code to follow