
Introduction by Alibaba
Overview
Principle
1.The Redis core exposes many APIs for modules to use (such as memory allocation interfaces, operations on Redis core DB structures), and note that these APIs are parsed and bound by Redis itself, not resolved by the dynamic linker.
Loading
int moduleLoad(const char *path, void **module_argv, int module_argc, int is_loadex) { int (*onload)(void *, void **, int); void *handle; struct stat st; if (stat(path, &st) == 0) { /* This check is best effort */ if (!(st.st_mode & (S_IXUSR | S_IXGRP | S_IXOTH))) { serverLog(LL_WARNING, "Module %s failed to load: It does not have execute permissions.", path); return C_ERR; } } // Open module so handle = dlopen(path,RTLD_NOW|RTLD_LOCAL); if (handle == NULL) { serverLog(LL_WARNING, "Module %s failed to load: %s", path, dlerror()); return C_ERR; } // Get the address of the onload function in the module onload = (int (*)(void *, void **, int))(unsigned long) dlsym(handle,"RedisModule_OnLoad"); if (onload == NULL) { dlclose(handle); serverLog(LL_WARNING, "Module %s does not export RedisModule_OnLoad() " "symbol. Module not loaded.",path); return C_ERR; } RedisModuleCtx ctx; moduleCreateContext(&ctx, NULL, REDISMODULE_CTX_TEMP_CLIENT); /* We pass NULL since we don't have a module yet. */ // Call onload to initialize the module if (onload((void*)&ctx,module_argv,module_argc) == REDISMODULE_ERR) { serverLog(LL_WARNING, "Module %s initialization failed. Module not loaded",path); if (ctx.module) { moduleUnregisterCommands(ctx.module); moduleUnregisterSharedAPI(ctx.module); moduleUnregisterUsedAPI(ctx.module); moduleRemoveConfigs(ctx.module); moduleFreeModuleStructure(ctx.module); } moduleFreeContext(&ctx); dlclose(handle); return C_ERR; } /* Redis module loaded! Register it. */ //... Unrelated code omitted ... moduleFreeContext(&ctx); return C_OK;}API Binding
int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) { if (RedisModule_Init(ctx, "helloworld", 1, REDISMODULE_APIVER_1) == REDISMODULE_ERR) return REDISMODULE_ERR; // ... Unrelated code omitted ...}static int RedisModule_Init(RedisModuleCtx *ctx, const char *name, int ver, int apiver) { void *getapifuncptr = ((void**)ctx)[0]; RedisModule_GetApi = (int (*)(const char *, void *)) (unsigned long)getapifuncptr; // Bind Redis exported APIs REDISMODULE_GET_API(Alloc); REDISMODULE_GET_API(TryAlloc); REDISMODULE_GET_API(Calloc); REDISMODULE_GET_API(Free); REDISMODULE_GET_API(Realloc); REDISMODULE_GET_API(Strdup); REDISMODULE_GET_API(CreateCommand); REDISMODULE_GET_API(GetCommand); // ... Unrelated code omitted ...}#define REDISMODULE_GET_API(name) edisModule_GetApi("RedisModule_" #name, ((void **)&RedisModule_ ## name))void moduleCreateContext(RedisModuleCtx *out_ctx, RedisModule *module, int ctx_flags) { memset(out_ctx, 0 ,sizeof(RedisModuleCtx)); // Here, the GetApi address is passed to the module out_ctx->getapifuncptr = (void*)(unsigned long)&RM_GetApi; out_ctx->module = module; out_ctx->flags = ctx_flags; // ... Unrelated code omitted ...}void *getapifuncptr = ((void**)ctx)[0];RedisModule_GetApi = (int (*)(const char *, void *)) (unsigned long)getapifuncptr;struct RedisModuleCtx { // getapifuncptr is the first member void *getapifuncptr; /* NOTE: Must be the first field. */ struct RedisModule *module; /* Module reference. */ client *client; /* Client calling a command. */ // ... Unrelated code omitted ...};After clarifying how RM_GetApi is exported, let’s look at what RM_GetApi does internally:
int RM_GetApi(const char *funcname, void **targetPtrPtr) { /* Lookup the requested module API and store the function pointer into the * target pointer. The function returns REDISMODULE_ERR if there is no such * named API, otherwise REDISMODULE_OK. * * This function is not meant to be used by modules developer, it is only * used implicitly by including redismodule.h. */ dictEntry *he = dictFind(server.moduleapi, funcname); if (!he) return REDISMODULE_ERR; *targetPtrPtr = dictGetVal(he); return REDISMODULE_OK;}/* Register all the APIs we export. Keep this function at the end of the * file so that's easy to seek it to add new entries. */void moduleRegisterCoreAPI(void) { server.moduleapi = dictCreate(&moduleAPIDictType); server.sharedapi = dictCreate(&moduleAPIDictType); // Register functions in the global hash table REGISTER_API(Alloc); REGISTER_API(TryAlloc); REGISTER_API(Calloc); REGISTER_API(Realloc); REGISTER_API(Free); REGISTER_API(Strdup); REGISTER_API(CreateCommand); // ... Unrelated code omitted ...}int moduleRegisterApi(const char *funcname, void *funcptr) { return dictAdd(server.moduleapi, (char*)funcname, funcptr);}#define REGISTER_API(name) \ moduleRegisterApi("RedisModule_" #name, (void *)(unsigned long)RM_ ## name)Some Best Practices
Disable C++ Name Mangling for Entry Functions
#include "redismodule.h"extern "C" __attribute__((visibility("default"))) int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) { // Init code and command register return REDISMODULE_OK;}Take Over Memory Statistics
REDISMODULE_API void * (*RedisModule_Alloc)(size_t bytes) REDISMODULE_ATTR;REDISMODULE_API void * (*RedisModule_Realloc)(void *ptr, size_t bytes) REDISMODULE_ATTR;REDISMODULE_API void (*RedisModule_Free)(void *ptr) REDISMODULE_ATTR;REDISMODULE_API void * (*RedisModule_Calloc)(size_t nmemb, size_t size) REDISMODULE_ATTR;New/Operator New/Placement New
1.Allocate space (using operator new)
2.Initialize the object (using placement new or type casting), i.e., call the object’s constructor
void * operator new(size_t, void *location) { return location; }To modify the default memory allocation used by new, we can use two methods.
Placement New
Object *p=(Object*)RedisModule_Alloc(sizeof(Object));new (p)Object();Also, note that special handling is needed during destruction:
p->~Object();RedisModule_Free(p);Operator New
_GLIBCXX_WEAK_DEFINITION void *operator new (std::size_t sz) _GLIBCXX_THROW (std::bad_alloc){ void *p; /* malloc (0) is unpredictable; avoid it. */ if (sz == 0) sz = 1; while (__builtin_expect ((p = malloc (sz)) == 0, false)) { new_handler handler = std::get_new_handler (); if (! handler) _GLIBCXX_THROW_OR_ABORT(bad_alloc()); handler (); } return p;}void *operator new(std::size_t size) { return RedisModule_Alloc(size); }void operator delete(void *ptr) noexcept { RedisModule_Free(ptr); }Visibility of Operator New Between Modules
Static/Dynamic Linking of C++ Standard Library
Static Linking
Dynamic Linking
Use Block Mechanism to Improve Concurrency
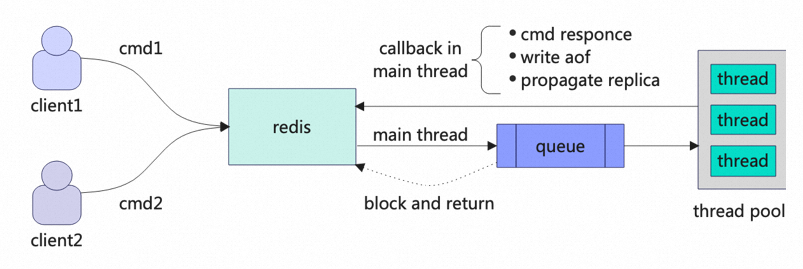
Figure 1 Typical Asynchronous Processing Model
Although block looks beautiful and powerful, it requires careful handling of some pitfalls, such as:
-
Although the command is executed asynchronously, writing AOF and replicating to the backup still occurs synchronously. If AOF is written and replicated to the backup in advance, and if the subsequent command execution fails, it cannot be rolled back; -
Since backups are not allowed to execute block commands, the master needs to rewrite block-type commands into non-block-type commands to replicate to the backup; -
During asynchronous execution, when opening a key, one cannot only look at the key name, as the original key may have been deleted before the asynchronous thread executes, and a new key with the same name may have been created, meaning the current key seen is not the original key; -
Design whether block-type commands support transactions and Lua; -
If using a thread pool, one must pay attention to the order of execution for the same key in the thread pool (i.e., processing for the same key cannot be out of order);
Avoid Symbol Conflicts with Other Modules
Since Redis can load multiple modules simultaneously, these modules may come from different teams and individuals, so there is a certain probability that different modules will define the same function names. To avoid undefined behavior caused by symbol conflicts, it is recommended that each module hide all symbols except for the Onload and Unload functions, which can be achieved by passing some flags to the compiler. For example, in GCC:
-fvisibility=hiddenBeware of Fork Traps
Handle Inflight Commands
If the module adopts an asynchronous execution model (refer to the previous block section), then when Redis performs an AOF rewrite or bgsave, at the moment Redis forks a child process, if there are still some commands in an inflight state, the newly generated base AOF or RDB may not contain the data from these inflight commands. Although this does not seem to be a major issue, as the commands in inflight will ultimately write to the incremental AOF, to maintain compatibility with Redis’s original behavior (i.e., there are no inflight commands during fork, maintaining a stable state), the module should ensure that all inflight commands are executed before executing fork.
In the module, this can be achieved through the Redis-exposed RedisModuleEvent_ForkChild event, allowing us to execute a callback function before the fork occurs.
RedisModule_SubscribeToServerEvent(ctx, RedisModuleEvent_ForkChild, waitAllInflightTaskFinish);For example, in waitAllInflightTaskFinish, wait for the queue to be empty (i.e., all tasks are executed):
static void waitAllInflightTaskFinish() { while (!thread_pool->idle()) ;}int pthread_atfork(void (*prepare)(void), void (*parent)void(), void (*child)(void));Avoid Deadlocks
As we know, a child process created via fork is almost but not completely identical to the parent process. The child process receives a copy of the parent process’s user-level virtual address space (but independently), including text, data, bss segments, heap, and user stack. The child process also receives a copy of any open file descriptors from the parent process, meaning the child process can read and write any open files in the parent process. The main difference between the parent and child processes is that they have different PIDs.
However, it is important to note that in Linux, only the thread that calls fork is copied to the child process. The fork(2) – Linux Man Page has the following description:
The child process is created with a single thread–the one that called fork(). The entire virtual address space of the parent is replicated in the child, including the states of mutexes, condition variables, and other pthreads objects; the use of pthread_atfork(3) may be helpful for dealing with problems that this can cause.
In other words, except for the thread that calls fork, other threads “evaporate” in the child process.
Therefore, if some resource locks are held in asynchronous threads, then in the child process, because these threads disappear, the child process may encounter deadlock issues.
The solution, like handling inflight commands, is to ensure that all locks are released before the fork occurs. (In fact, as long as all inflight commands are executed, generally all locks will be released.)
Ensure AOF Replication to Backup is Idempotent
The primary goal of Redis’s master-slave replication is to ensure consistency between the master and slave. Therefore, the slave must unconditionally receive replication content from the master and maintain strict consistency. However, for some special commands, careful handling is required.
For example, Tair exposes Tair String, which supports setting version numbers for data. For example, when a user writes:
EXSET key value VER 10EXSET key value ABS 11Support Graceful Shutdown
The module may start some asynchronous threads or manage some asynchronous resources, which need to be handled during Redis shutdown (such as stopping, destructing, writing to disk, etc.), otherwise, Redis may core dump upon exit.
In Redis, one can register the RedisModuleEvent_Shutdown event to implement this, which will call back our provided ShutdownCallback when Redis shuts down.
Of course, in newer versions of Redis, modules can also expose unload functions to achieve similar functionality.
RedisModule_SubscribeToServerEvent(ctx, RedisModuleEvent_Shutdown, ShutdownCallback);-
Implement AOF file compression, such as rewriting all write operations of a hash as a single hmset command (it may also be multiple); -
Avoid a single AOF being too large after rewriting (e.g., exceeding 500MB); if it exceeds, it needs to be rewritten into multiple commands while ensuring that these multiple commands need to be executed in a transactional manner (i.e., ensuring the isolation of command execution); -
For some complex structures that cannot be simply rewritten as existing commands, a separate “internal” command can be implemented, such as xxxload/xxxdump, for serialization and deserialization of the module’s data structure, which will not be exposed to clients; -
If RedisModule_EmitAOF contains array type parameters (i.e., parameters passed using the ‘v’ flag), the length of the array must be of type size_t to avoid encountering strange errors;
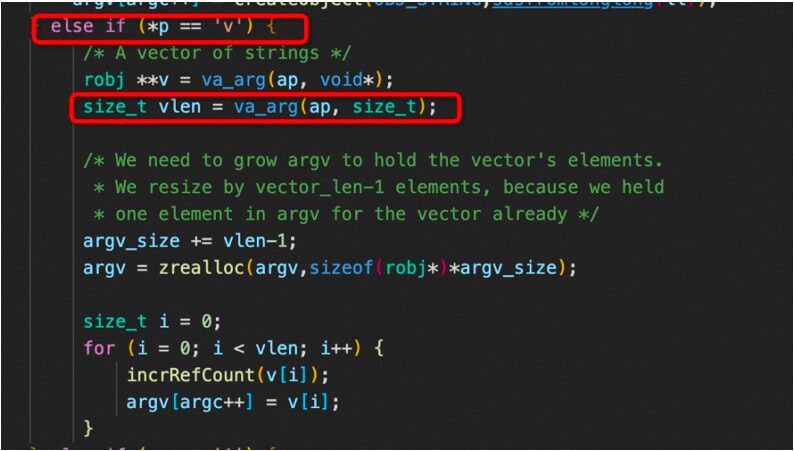
RDB Encoding with Backward Compatibility
RDB is a binary format for serialization and deserialization, which is relatively simple. However, it is important to note that if the serialization method of the data structure may change in the future, it is best to add a version for encoding and decoding, ensuring compatibility during upgrades, as follows:
void *xxx_RdbLoad(RedisModuleIO *rdb, int encver) { if (encver == version1 ) { /* version1 format */ } else if (encver == version2 ){ /* version2 format */ }}Suggestions for Implementing Some Commands
-
Parameter Verification: Try to verify the legality of parameters (such as whether the number of parameters is correct, whether the parameter types are correct, etc.) at the beginning of the command to avoid prematurely polluting the keyspace when the command has not been successfully executed (e.g., by using RedisModule_ModuleTypeSetValue to modify the main database in advance). -
Error Messages: The returned error messages should be as simple and clear as possible, explaining what the error type is. -
Keep Response Types Uniform: Pay attention to the uniformity of the return types of commands in various situations, such as when a key does not exist, when the key type is incorrect, when execution is successful, and when there are some parameter errors. Generally, except for returning error types, all other situations should return the same type, such as returning a simple string or an array (even if it is an empty array). This makes it easier for clients to parse command return values. -
Confirm Read/Write Types: Commands should strictly distinguish between read and write types, which affects whether the command can be executed on replicas and whether the command needs to be synchronized or written to AOF. -
Idempotency and AOF Replication: For write commands, it is necessary to use RedisModule_ReplicateVerbatim or RedisModule_Replicate for master-slave replication and AOF writing (if necessary, the original command needs to be rewritten). Among them, the AOF generated by RedisModule_Replicate will automatically be wrapped with multi/exec (ensuring isolation of commands generated within the module). Therefore, it is recommended to prioritize using RedisModule_ReplicateVerbatim for replication and AOF writing. However, if the command contains parameters such as version numbers, it is necessary to use RedisModule_Replicate to rewrite the version number as an absolute version number and rewrite the expiration time as an absolute expiration time. Additionally, if a command is ultimately rewritten by RedisModule_Replicate, it must ensure that the rewritten command does not undergo further rewriting. -
Reuse argv Parameters: The types of parameters in the argv passed to the command are RedisModuleString **, and these RedisModuleStrings will be automatically freed after the command returns. Therefore, the command should not directly reference these RedisModuleString pointers. If it is necessary to do so (e.g., to avoid memory copying), one can use RedisModule_RetainString/RedisModule_HoldString to increase the reference count of the RedisModuleString, but one must remember to manually free it later. -
Key Opening Method: When using RedisModule_OpenKey to open a key, one must strictly distinguish the opening types: REDISMODULE_READ and REDISMODULE_WRITE, as this affects the updating of internal stat_keyspace_misses and stat_keyspace_hits information, and also affects the issue of expiration and writing. Additionally, a key opened with REDISMODULE_READ cannot be deleted, or an error will occur. -
Key Type Handling: Currently, only the string set command can forcibly overwrite keys of other types; other commands need to return “WRONGTYPE Operation against a key holding the wrong kind of value” error when encountering keys that exist but have mismatched types. -
Cluster Support for Multi-Key Commands: For multi-key commands, one must properly handle the firstkey, lastkey, and keystep values, as only with these three values correct will Redis check for CROSS SLOTS issues in cluster mode. -
Global Index and Structure: If the module maintains its own global index, one must carefully consider whether the index contains dbid, key, and other information, as Redis’s move, rename, and swapdb commands will “swap” the names of keys and exchange two dbids. If the index is not updated synchronously at this time, unexpected errors will occur.
-
Determine Actions Based on Roles: The Redis instance running the module may be a master or a slave, and the module can use RedisModule_GetContextFlags to determine the current role of Redis and take different actions based on different roles (such as whether to actively handle expiration, etc.).
Conclusion
Tair currently supports a wide range of extended data structures (of which Redis 5.x enterprise version uses module method, Tair’s self-developed enterprise version 6.x uses builtin method), covering various application scenarios (see introduction document), including both small and elegant data structures like TairString and TairHash (already open-sourced), as well as more complex and powerful computational data structures like Tair Search and Vector, fully meeting various business scenarios under the AIGC background. Welcome to use.
Introduction Document: https://help.aliyun.com/zh/redis/developer-reference/extended-data-structures-of-apsaradb-for-redis-enhanced-edition
fork(2)-Linux Man Page: http://linux.die.net/man/2/fork
Alibaba Cloud Developer Community, the choice of millions of developers
The Alibaba Cloud Developer Community offers millions of quality technical contents, thousands of free system courses, rich experience scenarios, active community activities, and industry expert sharing and exchange. Welcome to click 【Read Original】 to join us.