Click the 🔺 public account above to follow me ✅
Computing power has become a significant bottleneck in the development of AI. To overcome this bottleneck, GPUs and NPUs, as the two main forces, are addressing this issue in different ways. So, how does the NPU accelerate AI from a hardware perspective? What are the essential differences between it and the GPU?

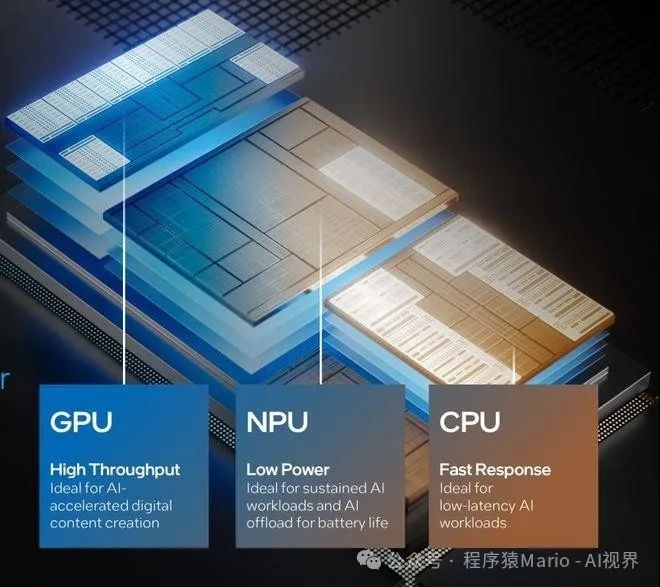
GPU (Graphics Processing Unit)
The GPU was originally designed for graphics rendering, characterized by:
-
Powerful parallel computing capabilities: Contains numerous computing cores that can handle multiple tasks simultaneously.
-
High versatility: In addition to graphics processing, modern GPUs can also be used for various general computing tasks.
-
Architectural features: Utilizes SIMD (Single Instruction, Multiple Data) architecture, suitable for processing regular, parallelizable computational tasks.
-
Main applications: Game graphics rendering, video processing, scientific computing, AI training, etc.
NPU (Neural Processing Unit)
The NPU is a processor specifically designed for deep learning and neural network computations:
-
Dedicated design: Optimized at the hardware level for neural network computations.
-
Efficient matrix operations: Provides higher efficiency in matrix calculations through specialized data flow design.
-
Low power consumption: Compared to GPUs, it consumes less energy when processing AI tasks.
-
Main applications: AI inference, running deep learning models, edge computing, etc.
| Comparison Dimension | GPU | NPU |
|---|---|---|
| Design Purpose | Originally designed for graphics processing, later expanded to general computing (such as AI training, scientific computing, etc.). | Optimized for neural network computations, focusing on AI inference and specific computational tasks. |
| Data Processing Method | Data needs to frequently move between computation units and caches, incurring some data transfer overhead. | Utilizes data flow design to reduce data movement, improving efficiency, especially suitable for matrix operations in neural networks. |
| Flexibility | More flexible, capable of handling various types of computational tasks (such as graphics rendering, AI training, scientific simulations, etc.). | Optimized for specific tasks (such as neural networks), efficiency for other tasks may be lower. |
| Application Scenarios | Gaming, professional graphics work (such as 3D rendering), AI training, high-performance computing, etc. | AI inference, edge computing, AI processing on mobile devices (such as image recognition, speech recognition, etc.). |
Let’s start with a simple example. In AI computation, the most computationally intensive task is matrix computation. Even multiplying two 4×4 matrices requires 64 multiplications and 48 additions. To speed up AI computation, the essence is to complete these basic operations faster.
As a master of parallel computing, the GPU’s solution is to deploy a large number of computation units that can work simultaneously. For example, in calculating the first row of a matrix, the GPU first loads the data into the cache, then the controller reads the data and distributes it to multiple multipliers for computation, storing the results back in the cache. Next, these results are sent to adders for computation, ultimately yielding the final result. By duplicating multiple sets of computation units, the GPU can process multiple rows of calculations simultaneously, significantly enhancing computational efficiency.
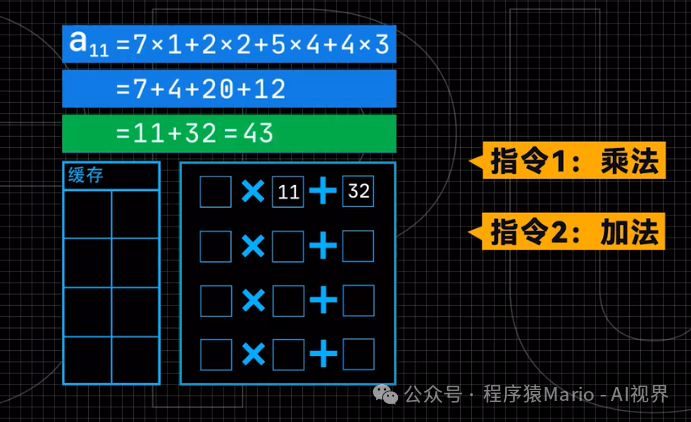
However, this method still has an efficiency bottleneck: data needs to constantly shuttle back and forth between the processors and the cache. This process is akin to a production line in a factory, where each step must send semi-finished products back to the warehouse, and the next step retrieves them from the warehouse, which clearly causes time wastage.
This leads to the core innovation of the NPU: establishing direct channels between computation units at the hardware level. The intermediate results computed by the multipliers no longer return to the cache but are directly used as inputs for the adders. This design allows the entire computation process to require only one data transfer, significantly enhancing computational efficiency.
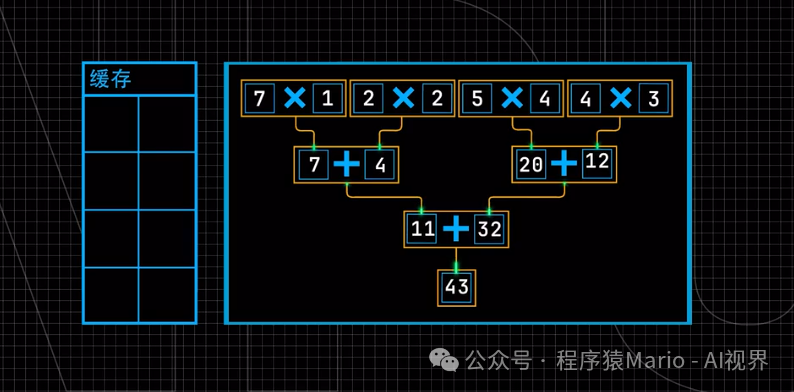
However, this design is also a double-edged sword. Although the GPU seems to take a longer route, this flexibility allows it to construct any complex computational formula through software instructions. In contrast, the NPU, in pursuit of speed, solidifies the computational path at the hardware level, meaning it can only efficiently handle specific types of computations, and its efficiency will significantly drop when faced with other types of calculations.
It is worth mentioning that modern NPU designs are far more complex than one might imagine. Taking Huawei’s Ascend NPU as an example, it can directly handle 16×16 FP16 precision matrix operations, and for INT8 precision matrices, it can even support scales up to 32×16. In addition to matrix computation units, it also integrates vector computation units, scalar computation units, and CPU cores to meet the diverse needs of AI computation.
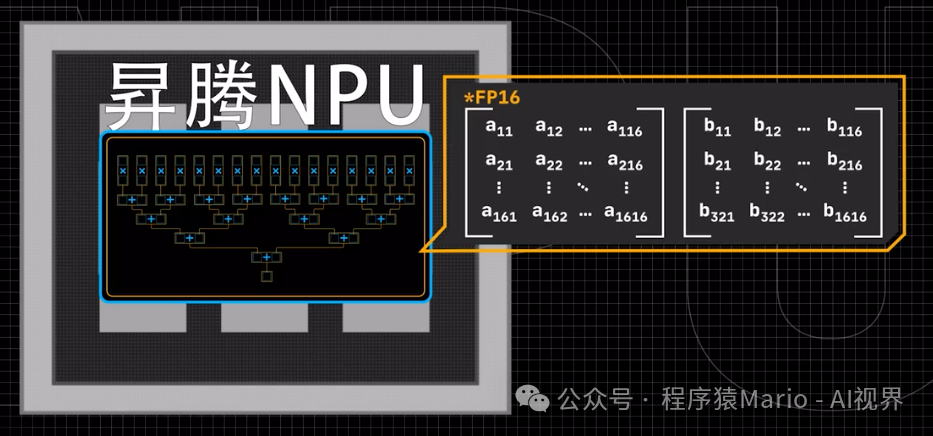
In fact, the boundaries between GPUs and NPUs are becoming increasingly blurred. Modern GPUs are also beginning to integrate matrix computation units similar to NPUs, such as NVIDIA’s Tensor Core. This trend of integration indicates that under the premise of accelerating AI computation, different technological routes are borrowing from each other and evolving together.
As AI technology continues to develop, we can expect to see more innovative hardware acceleration solutions emerge. However, whether it is a GPU or an NPU, they both illustrate a simple truth in their own ways: sometimes, changing the way of thinking is more important than simply increasing computational speed.
🎁 To get more AI information, remember tofollow the public account🎁Don’t forget to like 👍 + follow, wishing you all the best, and may your pocket money exceed AI tokens! — Blessings from [Programmer Mario]