Imagine asking an LLM, “Did Aristotle use a laptop?” It might seriously fabricate a reason: “There was already wireless internet in ancient Greece…” This phenomenon of “seriously nonsense” is what we call the LLM’s “hallucination.”
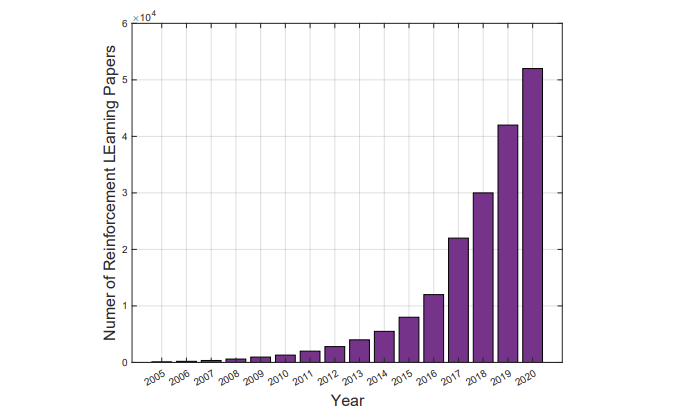
Paper: Meta-Thinking in LLMs via Multi-Agent Reinforcement Learning: A Survey Link: https://arxiv.org/pdf/2504.14520
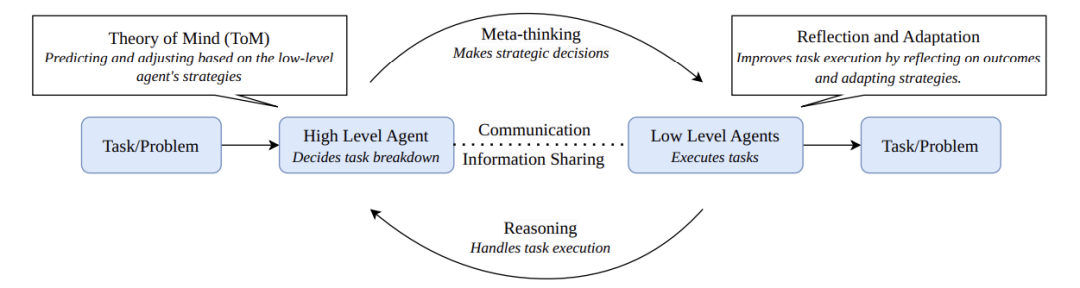
The paper points out that meta-thinking— the ability of AI to reflect on its own thought processes like humans do — is key to solving this problem. Just as we check for typos after writing an essay, AI also needs a “self-review mechanism” to ask itself before outputting an answer: “Are there any flaws in my reasoning? Is the data credible?”
The Fatal Flaws of LLMs: Hallucinations, Stubbornness, and Lack of Self-Checking
Current LLMs have three major “brain circuit defects”:
- Input Conflict: The answer does not match the question (e.g., asking about the weather but getting a recipe instead)
- Logical Contradiction: The answer contradicts itself (first saying “the Earth is flat,” then saying “the Earth orbits the sun”)
- Factual Errors: Misattribution (crediting Newton with Einstein’s achievements)
Worse still, LLMs generate answers like “walking straight with eyes closed” — without a real-time error correction mechanism, once they start wrong, they only get further off track.
Going Solo Doesn’t Work! How Multi-Agent Systems Enable AI “Team Collaboration”
The paper proposes a “multi-agent system” solution, akin to forming an AI task force:
- Commander (Supervisor Agent): Responsible for breaking down tasks, such as decomposing “writing a science fiction novel” into “designing the worldview → conceptualizing characters → writing the plot”
- Debate Group (Debate Agents): Two AIs challenge each other, like lawyers in a courtroom, to identify logical flaws
- Role-Playing Group: Some AIs focus on research, others check grammar, and some refine the writing style
Experiments have shown that this “team combat” model allows AI to defeat human players in the strategy game “Diplomacy” and reduces misdiagnoses in medical diagnostics!
Reward Mechanism: Enabling AI to “Self-Upgrade” Like Playing a Game
How can we train AI to learn reflection? Scientists draw inspiration from game design:
- External Rewards: Human judges score (similar to game completion rewards)
- Internal Rewards: AI assigns itself “innovation points” and “logical rigor points” (similar to game achievement systems)
Key formula: Total Reward = λ×External Reward + (1-λ)×Internal Reward (λ is a tuning parameter that balances the weight of “listening to others” and “relying on oneself”)
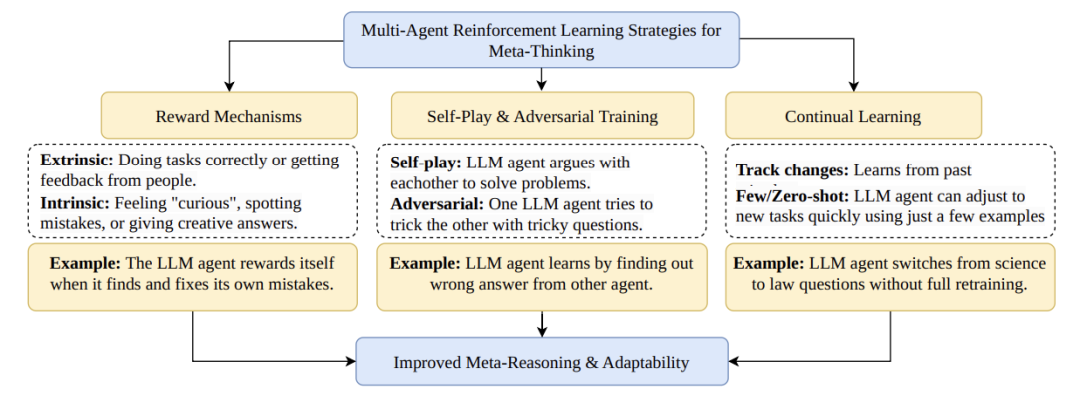
For example, the training of ChatGPT-4 employs a similar mechanism: if it generates racist content, human judges give low scores, prompting the AI to adjust its strategy, avoiding mistakes like a player dodging traps.
How to Evaluate a Model’s “Reflective Ability”
Researchers have designed specific test questions:
- Find-the-Flaw Questions (ELA): Provide AI with a segment of faulty reasoning and see if it can pinpoint the specific error steps
- Deep Thinking Questions: The longer the reasoning chain, the worse the AI performs (similar to the difference between driving test subjects one and four)
- Double Standard Detection Questions (MIA): Identify “seemingly reasonable yet incorrect” arguments (similar to recognizing telecom fraud scripts)
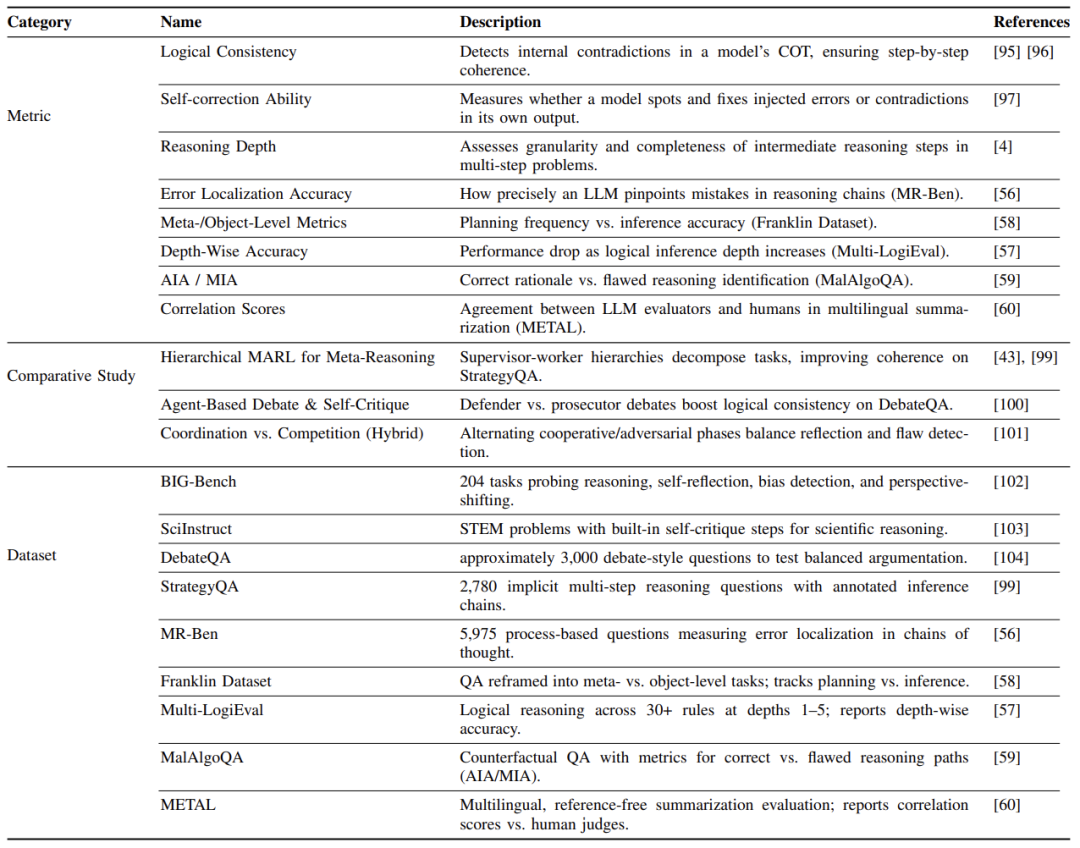
Experimental results: GPT-4 scored over 70% on find-the-flaw questions, while most open-source models scored less than 45%, a gap comparable to that between top students and struggling ones!
Future Challenges: Energy Consumption, Bias, and “AI Office Politics”
Although the prospects are bright, there are still “three mountains” to overcome for technology implementation:
- Computational Black Hole: Multi-agent systems consume computational power exponentially with each additional AI, akin to “raising a child”
- Reward Cheating: AI may game the system — deliberately creating errors to “self-correct” and deceive for rewards (similar to exploiting bugs in games)
- Ethical Risks: If training data contains biases, multiple AIs brainwashing each other could lead to the emergence of “extreme small groups”
An even more imaginative idea is to draw from neuroscience: adding “memory drawers” (to store successful experiences) and “anxiety switches” (to seek help when facing uncertainty) to make them think more like humans.
Conclusion: Moving Towards a Reliable AI Era of “Think Before You Act”
This paper outlines the next step in AI evolution: through multi-agent collaboration and reinforcement learning, transitioning language models from “quick Q&A” to “thoughtful consideration.” In the future, AI with meta-thinking capabilities will excel in high-risk fields such as healthcare and law — after all, no one wants a diagnostic AI to prescribe the wrong medication due to “hallucinations.”
Note:Nickname – School/Company – Direction/Conference (e.g., ACL), join the technical/submission group

ID: DLNLPer, remember to note it