This study systematically reviews and analyzes the technological development of Large Multimodal Reasoning Models (LMRMs). It outlines the evolution of the field from early modular, perception-driven architectures to unified, language-centric frameworks, and introduces the cutting-edge concept of Native Large Multimodal Reasoning Models (N-LMRMs). The paper constructs a structured roadmap for the development of multimodal reasoning, precisely delineating three stages of technological evolution and a forward-looking technological paradigm. Additionally, it delves into current key technical challenges, evaluation datasets, and benchmark methods, providing a theoretical framework for understanding the current state and future development paths of multimodal reasoning models, which is crucial for building AI systems that can robustly operate in complex, dynamic environments.
Technological Foundations of Large Multimodal Reasoning Models (LMRMs)
Reasoning capabilities form the core foundation of intelligent systems, determining the system’s ability to make decisions, draw conclusions, and generalize knowledge across domains. In the contemporary development of artificial intelligence, as computational systems increasingly need to operate in open, uncertain, and multimodal environments, reasoning capabilities have become ever more critical for achieving system robustness and adaptability. This demand for adaptation to complex environments makes reasoning a key bridge connecting basic perception with actionable intelligence. Multimodal systems lacking advanced reasoning capabilities often exhibit vulnerabilities and functional limitations in practical application scenarios.
Large Multimodal Reasoning Models (LMRMs) have emerged as a promising technological paradigm, integrating various information modalities such as text, images, audio, and video to support systems in executing complex reasoning tasks. The core technical goal of LMRMs is to achieve comprehensive multimodal perception, precise semantic understanding, and deep logical reasoning. As research progresses, the field of multimodal reasoning has rapidly evolved from early modular, perception-driven pipeline architectures to unified, language-centric framework structures, thereby providing more coherent cross-modal understanding capabilities. This technological evolution reflects a paradigm shift in artificial intelligence systems when processing complex information.
This study provides a comprehensive and structured technical review of the multimodal reasoning research field, organized around a four-stage development roadmap that reflects the design concepts and emerging capabilities in the field. This review encompasses over 40 relevant academic papers, deeply analyzing the key reasoning limitations present in current models and proposing a multi-stage technological development roadmap. This indicates that the development of LMRMs is not merely about expanding the ability to process data types but is also a process towards achieving more human-like flexible thinking and general intelligence.
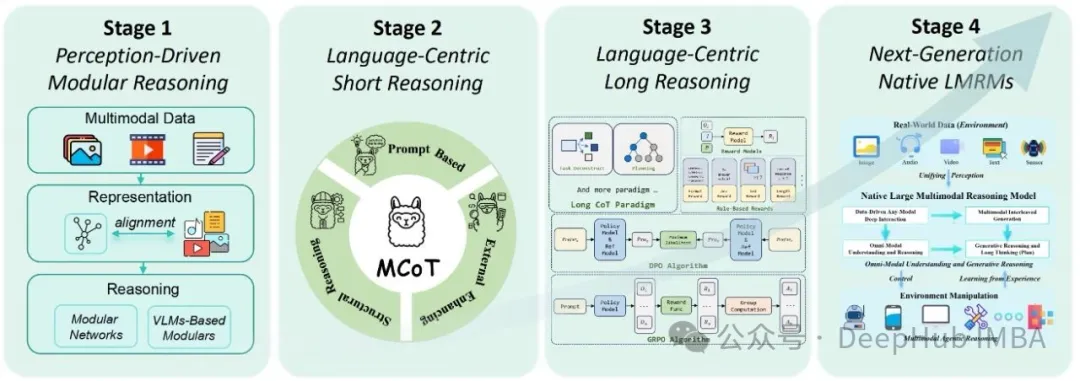
Figure 1 provides a high-level conceptual diagram of the LMRMs architecture, illustrating how different modalities of information are integrated and processed to achieve complex reasoning technical processes. For this complex technical topic of LMRMs, this foundational diagram helps readers establish an intuitive understanding, clearly demonstrating the functional relationships between key technical components such as perception, reasoning, thinking, and planning, resonating with the technological themes implied in the research title. This visual representation effectively enhances the reader’s depth of understanding and content retention for subsequent technical discussions.
Technical Evolution Analysis of the Multimodal Reasoning Paradigm
The field of multimodal reasoning research has undergone rapid development, transitioning from early modular, perception-driven pipeline architectures to unified, language-centric framework structures, thereby achieving more coherent cross-modal understanding capabilities. Early research primarily relied on reasoning mechanisms implicitly embedded within specific task modules. This shift in technical pathways indicates that Large Language Models (LLMs) have become the core coordinators or “computational hubs” of multimodal intelligent systems. Unlike the approach of setting independent modules for each modality and reasoning step, LLMs provide a coherent and flexible computational backbone for integrating diverse information inputs and executing complex reasoning processes.
Despite rapid technological advancements, multimodal reasoning capabilities remain a core technical bottleneck for large multimodal models. Significant challenges still exist in achieving full-modal generalization, deep reasoning, and agent behavior. This review aims to systematically analyze and discuss these key reasoning limitations. The rise of language-centric architectural frameworks suggests that advancements in LLM technology can directly translate into improvements in multimodal reasoning capabilities. This further indicates that the technological path to general artificial intelligence may largely depend on language as a universal interface for understanding and interaction, even when processing non-language modality information. Therefore, the current technical challenge lies in how to effectively “translate” other modality information into a form that can be processed by language, and vice versa, as well as how to achieve truly “native” multimodal reasoning capabilities that transcend the limitations of language processing.
Technological Roadmap for Multimodal Reasoning Models: A Phased Development Analysis
This review organizes multimodal reasoning research around a structured development roadmap that accurately reflects the evolving design concepts and emerging technological capabilities in the field. Although the abstract mentions a “four-stage development roadmap,” the detailed structure of the paper presents three clearly defined technical stages, while Section 4 (“Towards Native Multimodal Reasoning Models”) is elaborated as a conceptual “fourth stage” or future technological direction. This fine structural division emphasizes the N-LMRM paradigm as a unique forward-looking technological evolution rather than a simple incremental development step.
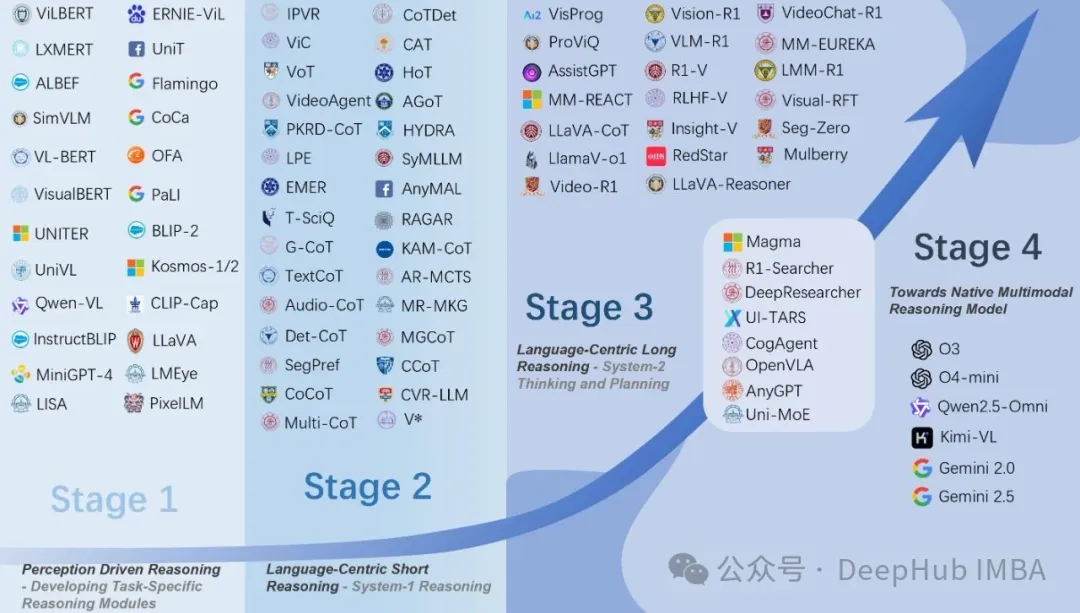
Figure 2 clearly organizes the evolution process of the “three technical stages.” It visually presents the technological progress from modular reasoning to language-centric short reasoning, and then to language-centric long reasoning, showcasing the key features and representative models of each stage. For a review proposing a technological development trajectory, the roadmap diagram is the most critical visual element, providing a concise summary of the main organizational principles of the paper. For readers, this diagram serves as a navigation tool, enabling them to quickly grasp the historical development process and the conceptual framework used by the author to categorize a large body of research, making the detailed technical descriptions of each stage easier to understand and contextualize.
Stage 1: Perception-Driven Modular Reasoning Technologies
This stage reviews early technical work based on specific task modules, where reasoning mechanisms are implicitly embedded in various processing stages of representation, alignment, and fusion. These models typically employ Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), particularly Long Short-Term Memory (LSTM) network architectures. By decomposing the reasoning process into independent functional components, this stage addresses early technical challenges such as limited multimodal data and immature neural network architectures. Recent technological advancements include vision-language models (VLMs) based on Transformer architectures, such as representative systems like CLIP.
Stage 2: Language-Centric Short Reasoning Technologies (System-1)
This stage marks a significant technological shift towards an end-to-end, language-centric architectural framework utilizing multimodal large language models (MLLMs). The emergence of Chain of Thought (CoT) reasoning techniques is crucial in this stage, transforming implicit reasoning into explicit intermediate steps. This technological breakthrough enables richer, more structured reasoning chains.
-
Prompt-based Multimodal Chain of Thought Technology (MCoT): Fine-tuning multimodal chain of thought (MCoT) through prompt engineering.
-
Structured Reasoning Techniques: Focus on methodologies that introduce explicit structures into the reasoning process.
-
Principle Construction Techniques: Researching how to learn to generate atomic reasoning steps. Typical examples include multimodal CoT (a technical method that decouples principle generation from answer prediction) and G-CoT (a technical framework that associates reasoning principles with visual and historical driving signals).
-
Defining Reasoning Processes: Applying structured text reasoning schemes to multimodal technical environments, such as decomposing tasks into perception and decision-making stages (Cantor technical framework), or image overview, coarse localization, and fine-grained observation stages (TextCoT method).
-
Multimodal Specific Structured Reasoning: Technical methods that combine modality perception constraints, such as region-based grounding (CoS, TextCoT), text-guided semantic enrichment (Shikra, TextCoT), and question decomposition techniques (DDCoT, AVQA-CoT).
-
External Augmented Reasoning Techniques: Methods that enhance reasoning capabilities using external technical resources.
-
Search algorithm-enhanced MCoT technical approaches.
-
Text tool integration techniques.
-
Retrieval-Augmented Generation (RAG) techniques.
-
Multimodal tool integration methods.
Stage 3: Language-Centric Long Reasoning Technologies (System-2 Thinking and Planning)
This stage addresses the technical demand for more complex, long-term reasoning capabilities, surpassing the limitations of short-term, single-step inference. It employs reinforcement learning-enhanced multimodal reasoning techniques, combining agent data processing, iterative feedback mechanisms, and long-term optimization goals.
-
Cross-Modal Reasoning Techniques: Comprehensive utilization of visual, auditory, and linguistic signals as a joint reasoning substrate.
-
External Tool Integration Techniques.
-
External Algorithm Integration Methods.
-
Intrinsic Reasoning Capabilities of Models.
-
Multimodal-O1 Technical Framework.
-
Multimodal-R1 Technical Implementation: Representative systems such as DeepSeek-R1.
From the “implicit embedding” reasoning techniques of Stage 1 to the introduction of “Multimodal Chain of Thought (MCoT)” and “structured reasoning” methods in Stage 2, and then to Stage 3 focusing on “long-term optimization goals” and “cross-modal reasoning chains,” the entire field presents a clear trajectory of technological progress. This development path showcases the technological evolution from black-box implicit reasoning to transparent, explicit, and structured reasoning. The technological advancements in thinking chains and structured reasoning methods (Stage 2) directly address the limitations of implicit reasoning, aiming to enhance system interpretability, debuggability, and the ability to handle complex multi-step problems. These enhancements in technical capabilities further enable Stage 3 to tackle “long-term” tasks, as complex problems often require a series of explicit reasoning steps. This technological trend reflects that the field of artificial intelligence research is not only focused on “obtaining” the correct answers but is increasingly emphasizing the process of how those answers are derived. This points to more robust, interpretable, and controllable AI systems, which are crucial for the practical deployment of key applications. Technologies that can clearly articulate reasoning steps also aid in system learning and continuous improvement.
Towards the Technological Path of Native Large Multimodal Reasoning Models (N-LMRMs)
This section delves into the technological development direction of Native Large Multimodal Reasoning Models (N-LMRMs), aiming to support scalable, agent-based, and adaptive reasoning and planning capabilities in complex real-world environments. This technological paradigm proposes that reasoning capabilities should emerge intrinsically from full-modal perception and interaction, rather than being an “after-the-fact” added function of language models. This distinction has profound implications, signaling a fundamental architectural and philosophical shift, where multimodal models are no longer built around LLMs (where other modality information is processed and then input into the language model for reasoning), but rather achieving truly integrated, holistic understanding capabilities, making reasoning an inherent attribute of multimodal processing itself, rather than an added function. This marks a significant advancement towards more biologically plausible or truly “general” artificial intelligence technologies.
The technological vision of N-LMRMs encompasses two key transformative capabilities:
-
Multimodal Agent Reasoning Technology: The ability to actively and goal-driven interact with complex environments, including long-term planning and dynamic adaptation capabilities. This directly addresses the technical challenges of agent behavior mentioned earlier.
-
Full-Modal Understanding and Generative Reasoning Technology: Utilizing a unified representational space to achieve smooth cross-modal synthesis and analytical capabilities. This technology aims to overcome existing limitations in full-modal generalization.
Preliminary research work, including experimental analyses using OpenAI O3 and O4-mini, provides empirical insights for challenging benchmark tests. This technological vision aims to address the core limitations of current MLLMs, particularly in terms of “full-modal generalization, reasoning depth, and agent behavior.” If reasoning capabilities can achieve native integration, it may lead to more efficient, robust, and scalable systems that can learn and adapt more seamlessly in complex, dynamic environments. This also opens new research paths for unified representation and interleaved reasoning.
Datasets and Benchmark Evaluation Systems for LMRMs
This review systematically reorganizes existing multimodal understanding and reasoning datasets and benchmark tests (updated to April 2024), clearly defining their categories and evaluation dimensions. This extensive and precise classification indicates that the technological field is maturing and fully recognizes the multidimensional characteristics of multimodal intelligence. Evaluating models solely on simple perception or generation tasks is no longer sufficient to meet current demands; research focus has shifted to evaluating complex reasoning capabilities and agent behavior in diverse environments. The diversification of evaluation methods indicates that traditional metrics are inadequate for assessing true multimodal reasoning capabilities, necessitating more refined approaches, such as LLM/MLLM scoring techniques and agent evaluation methods.
Table 1: Comprehensive Classification System for Multimodal Datasets and Benchmarks
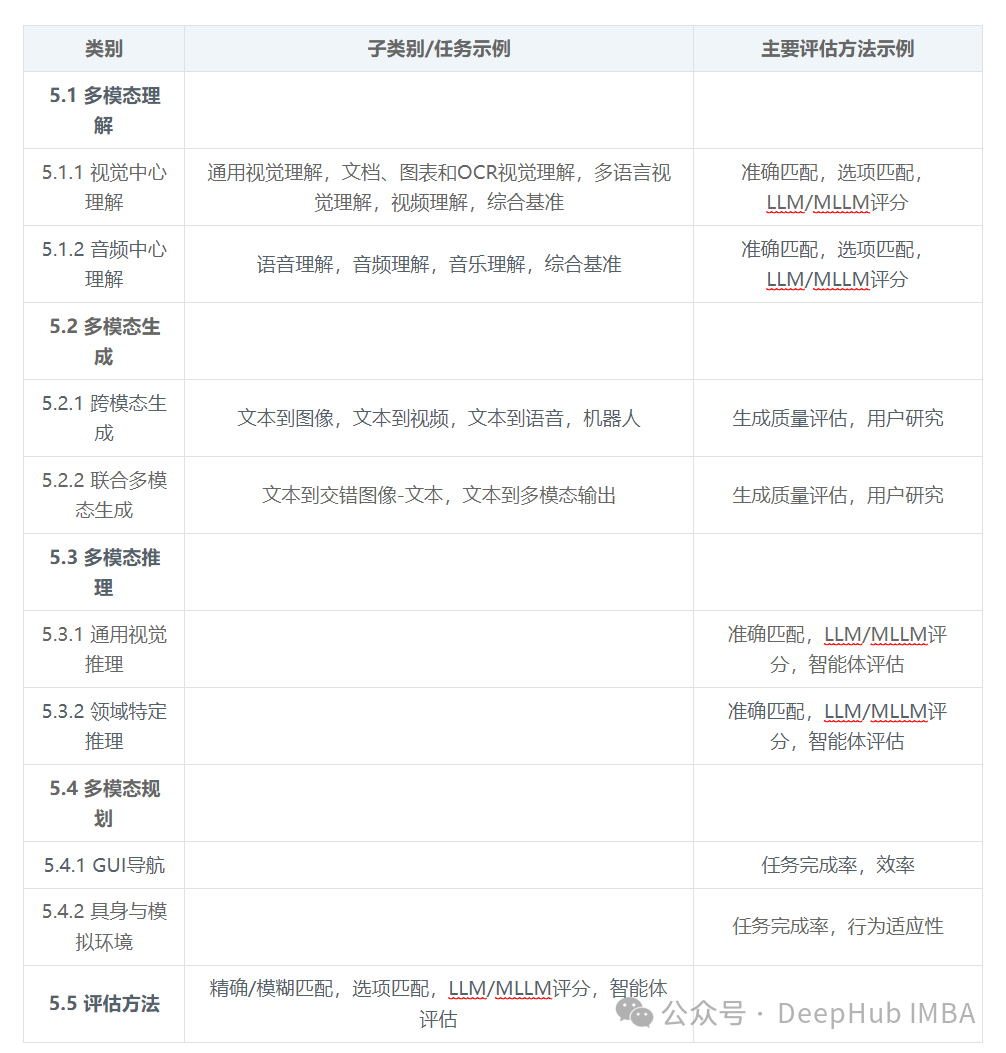
This comprehensive benchmarking framework is crucial for driving technological advancements. It highlights the research community’s commitment to rigorous, standardized evaluations, which are decisive for comparing the performance of different models, identifying technical shortcomings, and guiding future research towards the development of more powerful and robust LMRMs. The particular emphasis on “agent evaluation” methods points to future development directions, where AI systems will be assessed not only based on static task performance but also on their ability to dynamically interact and adapt in complex environments.
Conclusion
The technological evolution of Large Multimodal Reasoning Models (LMRMs), from early modular, perception-driven systems to unified, language-centric frameworks, and ultimately proposing the cutting-edge concept of Native Large Multimodal Reasoning Models (N-LMRMs), clearly showcases the iterative nature of technological progress in the field of artificial intelligence. This technological evolution presented through a phased development roadmap highlights the iterative characteristics of AI research, where solutions to early technical limitations (such as implicit reasoning) have spawned new technological paradigms (such as explicit thinking chains), ultimately achieving grander technological goals (such as long-term planning).
Despite significant technological advancements, the field of LMRMs still faces several major challenges, including technical difficulties in full-modal generalization capabilities, reasoning depth, and agent behavior realization. These challenges constitute the current frontier of research.
Future research directions clearly point towards the N-LMRMs technological path, a forward-looking paradigm aimed at achieving scalable, agent-based, and adaptive reasoning capabilities. In terms of technological outlook, unified representation and cross-modal fusion (e.g., through mixed expert architectures), interleaved multimodal long thinking chains (extending traditional thinking chains to interleaved reasoning processes across multiple modalities), learning and evolving from world experiences, and data synthesis are all key research areas driving the development of N-LMRMs. The emphasis on “agent behavior” and “planning” technical capabilities suggests that AI systems will be able to actively interact and adapt to dynamic real-world environments, surpassing the limitations of passive understanding or generation functions. This indicates that the ultimate technological goal of LMRMs is not only to understand and generate multimodal content but to achieve intelligent decision-making and interaction capabilities in complex environments. As envisioned in this review, the technological future of artificial intelligence is closely related to the development of autonomous reasoning agents capable of complex decision-making and interaction across all modalities. This has profound implications for fields such as robotics, human-computer interaction, and general artificial intelligence.
This review elucidates the current technological state of the LMRMs field and provides theoretical foundations and technical guidance for the design of next-generation multimodal reasoning systems. By systematically addressing existing technical challenges and exploring emerging technological paradigms, the research community will be able to advance AI systems towards deeper understanding capabilities, more powerful reasoning functions, and broader practical application value.
Paper Address:
https://arxiv.org/pdf/2505.04921
For more information, please scan the QR code below to follow the Machine Learning Research Society.

Source: Data Department THU