When building new things, we all follow some time-tested methods, approaches, and patterns.This statement is particularly true for software engineers, but it may not be the case for generative AI and AI itself.For emerging technologies like generative AI, we lack documented patterns as a foundation for solutions.
 Image source: Wang Knowledge
Image source: Wang Knowledge
Author: Zhang Changwang, Wang Knowledge, CCF Theory Computer Science Professional Committee
Here, we will share some methods and patterns for generative AI based on evaluations of countless LLM implementations. The goal of these patterns is to help mitigate and overcome some challenges in the implementation of generative AI, such as cost, latency, and hallucination. This article provides nine reference architecture patterns and thinking models for building applications using large language models (LLMs).
List of Generative AI Design Patterns:
-
Fine-tuning with a layered caching strategy
-
Multi-agent AI expert group
-
Fine-tuning LLMs for multiple tasks
-
Fusion of rule-based and generative approaches
-
Utilizing LLM knowledge graphs
-
Generative AI agent swarm
-
Modular monolithic LLM approach with composability
-
Memory cognition approach for LLMs
-
Red-blue team dual-mode evaluation
1 – Fine-tuning with a layered caching strategy
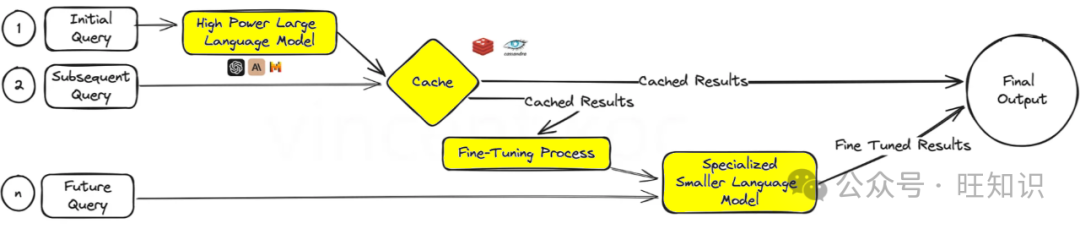
When introducing caching strategies and services for large language models, we need to address a combination of factors such as cost, redundancy, and training data.
By caching these initial results, the system can provide answers more quickly in subsequent queries, thereby improving efficiency. Once we have enough data, the fine-tuning layer will pivot, using feedback from these early interactions to refine more specialized models.
This specialized model not only simplifies the process but also adjusts the AI’s expertise according to specific tasks, making it highly effective in environments that demand precision and adaptability, such as customer service or personalized content creation.
For beginners, pre-built services like GPT Cache can be used, or common caching databases like Redis, Apache Cassandra, and Memcached can be developed independently. When adding other services, be sure to monitor and measure latency.
2 – Multi-agent AI expert group

Imagine a scenario where multiple task-specific AI generative models (“agents”) work in parallel within an ecosystem to handle a query, with each agent being an expert in its field. This multiplexing strategy can yield a range of different responses, which are then integrated to provide a comprehensive answer.
This setup is particularly suitable for solving complex problems, as different aspects of the problem require different expertise, much like a team of experts each handling one aspect of a larger issue.
Large models like GPT-4 are used to understand the context and break it down into specific tasks or information requests, which are then passed to smaller agents. These agents can be smaller language models (like Phi-2 or TinyLlama) trained for specific tasks, or general models (like GPT, Llama) with specific personalities, contextual prompts, and function calls.
3 – Fine-tuning LLMs for multiple tasks

Here, we fine-tune large language models on multiple tasks simultaneously rather than on a single task. This approach facilitates robust transfer of knowledge and skills across different domains, enhancing the model’s versatility.
This multi-task learning is particularly useful for platforms that need to handle a variety of tasks with high capability, such as virtual assistants or AI-driven research tools. It has the potential to simplify training and testing workflows in complex domains.
Some resources and packages used for training LLMs include DeepSpeed and the training capabilities in Hugging Face’s Transformer library.
4 – Fusion of rule-based and generative approaches
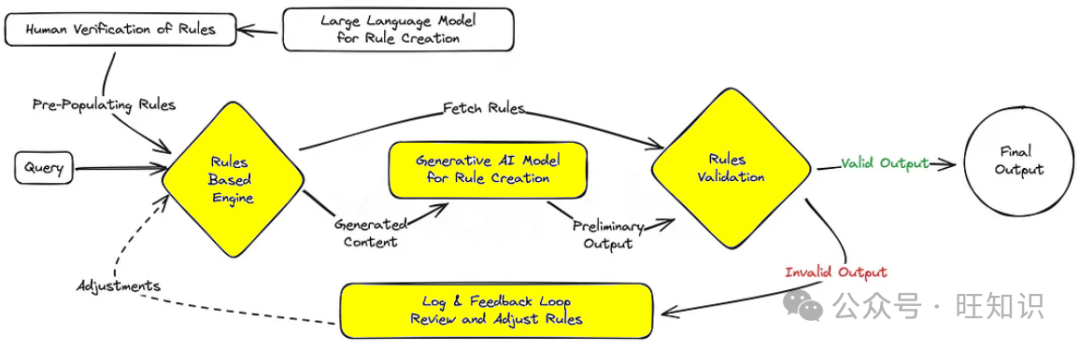
Many existing business systems and organizational applications are still to some extent rule-based. By merging generative capabilities with the structured precision of rule-based logic, this pattern aims to produce solutions that are both creative and compliant.
This is a powerful strategy for industries where outputs must adhere to strict standards or regulations, ensuring that AI remains within the required parameters while still being innovative and engaging. A good example is generating intents and information flows for rule-based phone IVR systems or traditional (non-LLM-based) chatbots.
5 – Utilizing LLM knowledge graphs
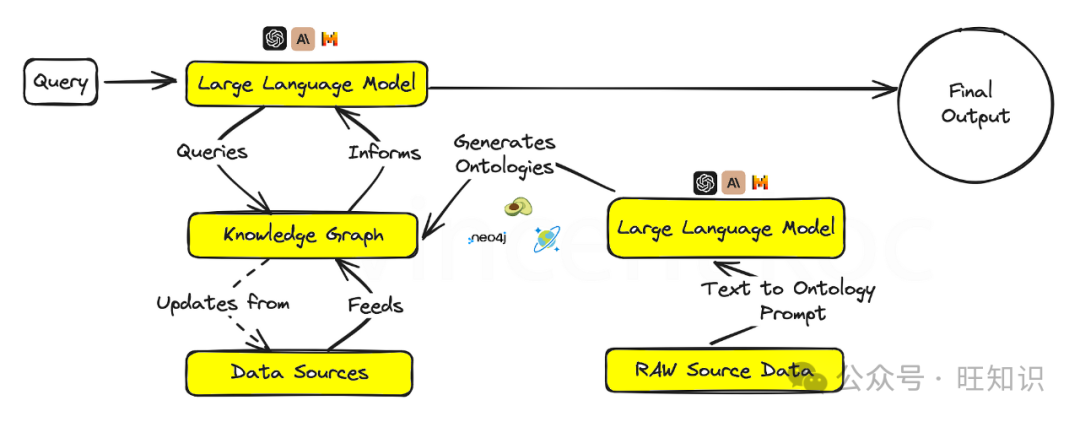
Integrating knowledge graphs with generative AI models empowers them with fact-based superpowers, enabling outputs that are not only context-aware but also more factually accurate.
This approach is crucial for application areas that demand high authenticity and accuracy, such as educational content creation, medical consultations, or any field where misinformation could have serious consequences.
Knowledge graphs and graph ontologies (the conceptual sets of graphs) can break down complex topics or organizational issues into structured formats, helping large language models establish deep context. Language models can also generate ontologies in formats like JSON or RDF.
Services available for knowledge graphs include graph database services like ArangoDB, Amazon Neptune, Azure Cosmos DB, and Neo4j. There are also broader datasets and services available for accessing wider knowledge graphs, including Google Knowledge Graph API, PyKEEN Datasets, and Wikidata.
6 – Generative AI agent swarm
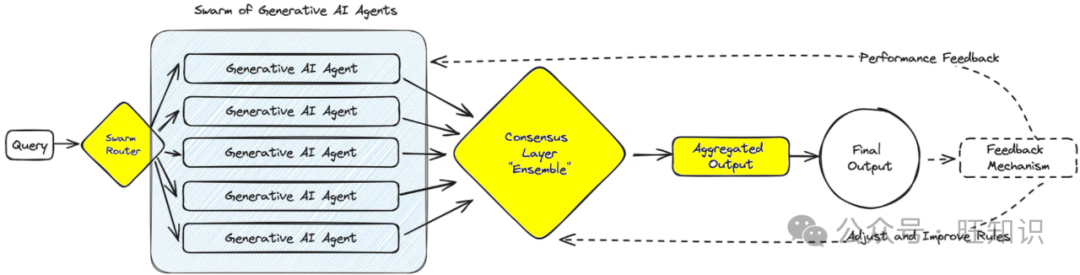
This model draws inspiration from natural swarms of bees and flocks of birds, employing numerous AI agents that collaboratively solve a problem, each agent offering its unique perspective.
The resulting aggregated output reflects a form of collective intelligence that surpasses what any single agent could achieve. This pattern is particularly advantageous in scenarios requiring a wide range of creative solutions or when navigating complex datasets.
For example, reviewing research papers from multiple “expert” perspectives or simultaneously assessing customer interactions across various use cases from fraud to promotions. We leverage these collective “agents” to combine all their inputs. For large swarms, consider deploying messaging services like Apache Kafka to handle messages between agents and services.
7 – Modular monolithic LLM approach with composability
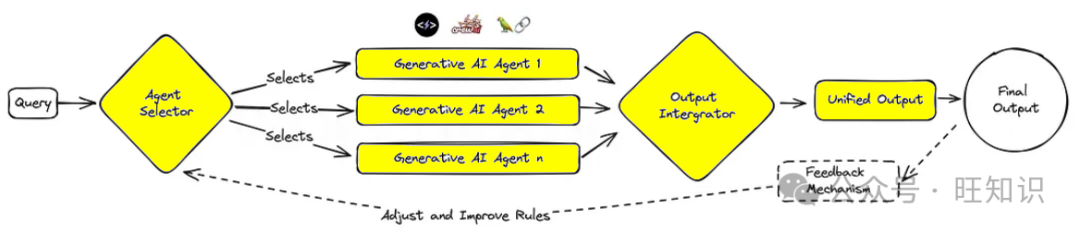
This design advocates for adaptability, characterized by modular AI systems that can be dynamically reconfigured for optimal task performance. It is like a Swiss Army knife, where each module can be selected and activated as needed, making it highly effective for businesses that require tailored solutions for different customer interactions or product demands.
Various autonomous agent frameworks and architectures can be deployed to develop each agent and its tools. Example frameworks include CrewAI, PromptAppGPT, Langchain, Microsoft Autogen, and SuperAGI.
For a modular monolith, there could be an agent focused on leads, one handling bookings, one generating information, and another updating the database. In the future, when specialized AI companies offer specific services, modules can be swapped out for external or third-party services tailored to specific task sets or domain-specific issues.
8 – Memory cognition approach for LLMs
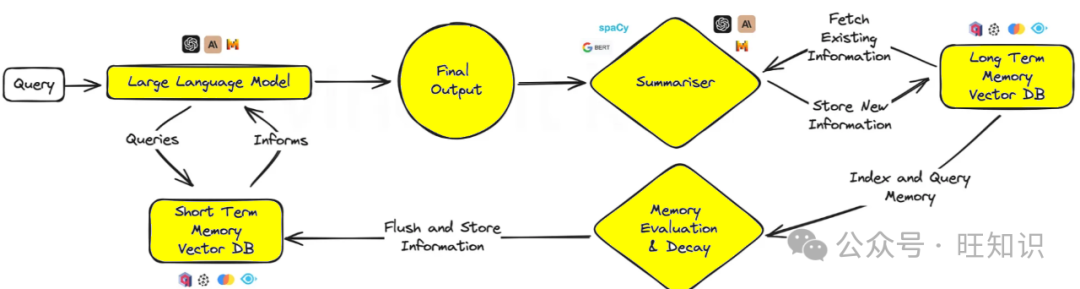
This approach introduces elements akin to human memory into AI, allowing models to recall and respond with greater nuance based on previous interactions.
This is particularly useful for ongoing conversations or learning scenarios, as the AI develops a deeper understanding over time, much like a dedicated personal assistant or adaptive learning platform. Over time, the memory cognition approach can be implemented by summarizing key events and discussions and storing them in a vector database.
To reduce the computational load of summarization, smaller NLP libraries (like spaCy) or BART language models (for handling large amounts of information) can be utilized. The database used is vector-based, and during the prompt phase for short-term memory, retrieval uses similarity search to locate key “facts”. For workable solutions, an open-source solution with a similar pattern called MemGPT can be adopted.
9 – Red-blue team dual-mode evaluation
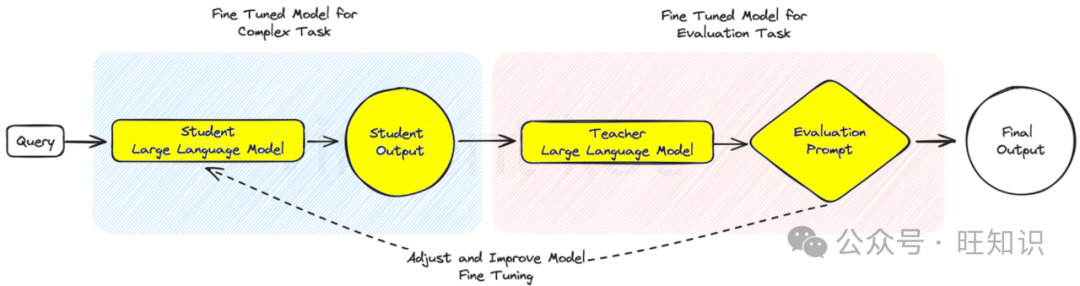
In the red-blue team evaluation model, one AI generates content while another AI rigorously evaluates it, similar to a strict peer review process. This dual-mode setup is excellent for quality control, making it highly suitable for content generation platforms that demand high credibility and accuracy, such as news aggregation or educational material production.
This method can be used to replace some human feedback with fine-tuned models in complex tasks, mimicking the human review process and refining the evaluation of complex language scenarios and outputs.
Conclusion
These design patterns for generative AI are not just templates but frameworks upon which future intelligent systems will be built. As we continue to explore and innovate, the architectures we choose will clearly determine not only the capabilities of AI but also the characteristics of the AI we create.
This list is by no means exhaustive; as generative AI patterns and use cases expand, we will see further developments in this field.
References:
-
2023 Guide to LLM Fusion Technology Research and Practice
-
2024 Comprehensive Outlook on Trends in Generative AI (GenAI): Business, Enterprises, Investment, R&D, Applications, Security
-
Vincent Koc, Generative AI Design Patterns: A Comprehensive Guide
-
2023 Top 10 Most Transformative AI Research – Illuminating the Path to AI Breakthroughs