Overview
In this project, we encountered a need for Optical Character Recognition (OCR).
However, the best-performing <span>PaddleOCR</span> can only run on Baidu’s <span>PaddlePaddle</span> framework.
In common projects, the more widely used Pytorch framework is often preferred. Installing PaddlePaddle separately not only makes the project overly bulky but may also lead to conflicts.
In the previous breakdown of the MinerU structure, it was found that it used a torch version of PaddleOCR2Pytorch converted from PaddleOCR-v4.
Thus, this part was extracted separately, and some decoupling optimizations were made, resulting in a standalone repository for easier integration with other projects.
Repository link: https://github.com/zstar1003/PaddleOCR-Torch-Infer
Models Used
-
Detection Model: ch_PP-OCRv4_det_infer.pth
-
Recognition Model: ch_PP-OCRv4_rec_infer.pth
-
Dictionary File: ppocr_keys_v1.txt
Usage Instructions
Install Dependencies
1. Install the uv package manager
It is recommended to use uv to manage the dependency environment. If uv is not installed, it can be installed via pip:
pip install uv
2. Create a virtual environment
uv venv --python 3.10
3. Activate the virtual environment
.\.venv\Scripts\activate
4. Install dependencies according to <span>uv.lock</span>
uv sync
Command Line Parameters
<span>--data_path</span>:Required parameter, specifies the input image path or directory path<span>--save_path</span>:Optional parameter, specifies the path or directory to save results<span>--show_confidence</span>:Optional parameter, whether to display confidence in the result image (default is not displayed)
Single Image Processing
python infer.py --data_path test_img/general_ocr_rec_001.png --save_path output/result.png
Directory Batch Processing
python infer.py --data_path test_img --save_path output
Recognition Effect Display



PP-OCRv5 Preview
Introduction to PP-OCRv5
Interestingly, just as I finished writing this article yesterday, I suddenly saw the release of <span>PP-OCRv5</span> (the last release of v4 was on 2024.02.20).
According to the official introduction, PP-OCRv5 has the following main advantages:
-
1. A single model supports five types of text (Simplified Chinese, Traditional Chinese, Chinese Pinyin, English, and Japanese)
-
2. Supports recognition of complex handwriting
-
3. Recognition accuracy improved by 13 percentage points compared to the previous version PP-OCRv4
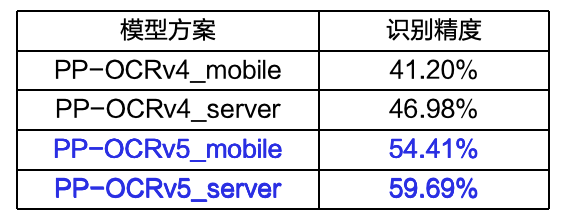
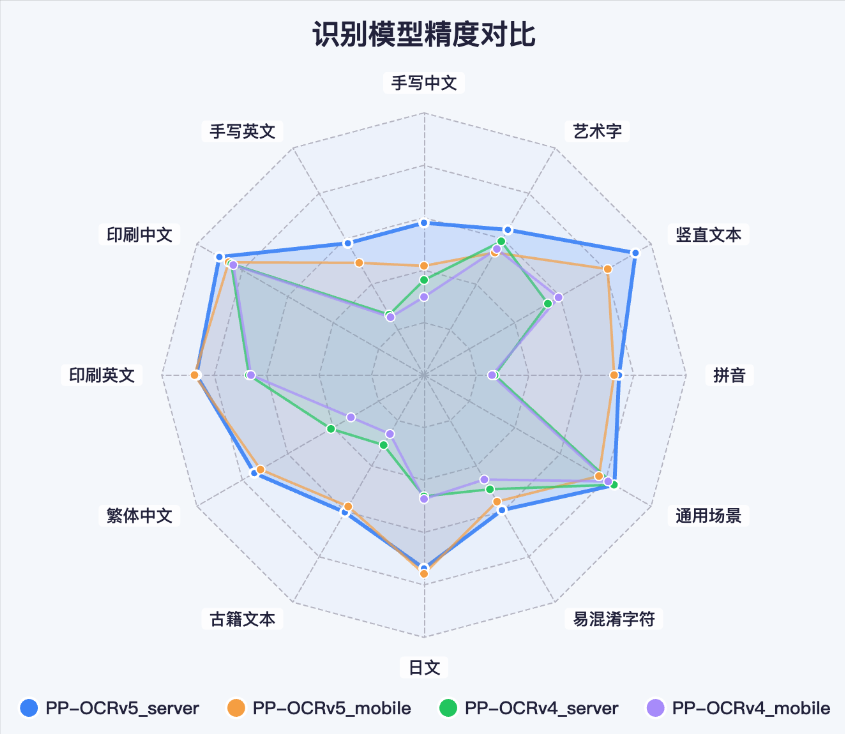
PP-OCRv5 Model Structure
According to the model’s structure configuration file, it can be seen that there are no significant differences in the algorithm and <span>Head</span> part between v5 and v4; the core modification is in the <span>Backbone</span> network structure.

The new <span>PPHGNetV2_B4</span> structure is located in <span>ppocr\modeling\backbones\rec_pphgnetv2.py</span>
Theoretically, if this backbone is re-implemented in Pytorch, model conversion can be performed.
Thus, I forked the PaddleOCR2Pytorch repository and attempted to use Agent to convert it.
Repository link: https://github.com/zstar1003/PaddleOCR2Pytorch
It was found that it could be converted to a pth file, but there were many parameter alignment issues.
After tinkering for a whole night, I realized that a lot of effort is needed to deeply understand and fine-tune the parameter structure, so I gave up and will wait for someone more skilled to solve it.
References
1. PP-OCRv5 Official Documentation: https://github.com/PaddlePaddle/PaddleOCR/blob/main/docs/version3.x/algorithm/PP-OCRv5/PP-OCRv5.md
2. PaddleOCR: https://github.com/PaddlePaddle/PaddleOCR
3. PaddleOCR2Pytorch: https://github.com/frotms/PaddleOCR2Pytorch
4. MinerU: https://github.com/opendatalab/MinerU