
The official price of the NVIDIA Jetson AGX Orin development kit is $1999, while the Jetson AGX Xavier development kit, released three years ago, had an official price of $899 (it is now discontinued and unavailable). Many users are surprised at the significant price increase; what exactly accounts for this difference?

Today, I found a review article online and translated an excerpt to share here for everyone’s reference.
The original article is —

It was published by SmartCow, a company specializing in artificial intelligence engineering, advanced video analytics, AI applications, and electronic manufacturing, founded in 2016.
The company states —
Throughout this article, we will share how the new NVIDIA Jetson AGX Orin module is a game changer in the field of edge devices.
 Specifications Comparison
Specifications Comparison
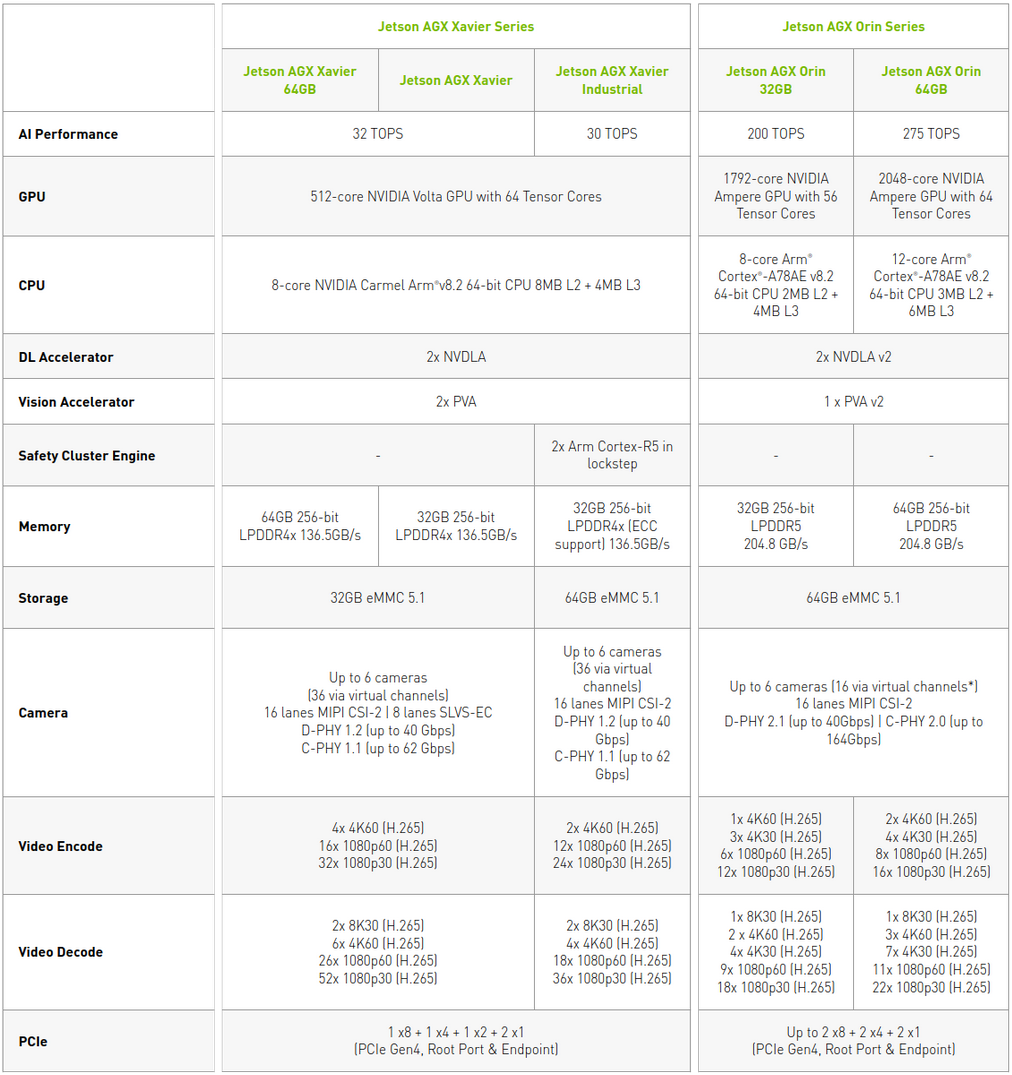
(Click the image to enlarge; it is recommended to save the image)
Comparing the specifications of Jetson AGX Orin with Jetson AGX Xavier, we can agree that Jetson AGX Orin is very promising. It boasts up to 275 TOPS, which is 8 times more powerful than the 64GB/32GB version of Jetson AGX Xavier. Additionally, it features up to 12 cores of the new Cortex CPU, LPDDR5 memory, 64GB eMMC, 2 next-generation DLA, and up to 2048 cores of NVIDIA Ampere GPU with 64 tensor cores. Clearly, having 8 times more TOPS does not necessarily mean 8 times faster inference time.
In fact, NVIDIA has made a comparison of inference times in this specification sheet.
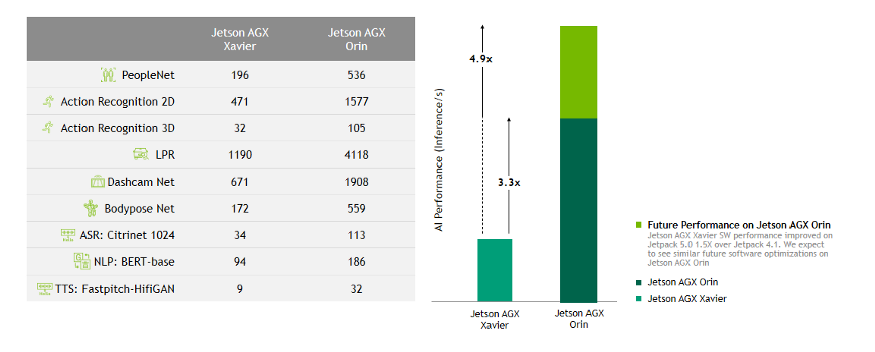
According to the table above and using currently available software, we can expect up to a 3.3 times improvement compared to AGX Xavier, and we can anticipate even better performance in future updates. The Jetson AGX Orin module included in the development kit has the same specifications as the production Jetson AGX Orin 64GB module, except for the memory: it has a 12-core Cortex CPU and a 2048-core GPU with 64 tensor cores, but with 32GB LPDDR5 memory instead of 64GB.
Running deviceQuery allows us to obtain more detailed specifications of the GPU:
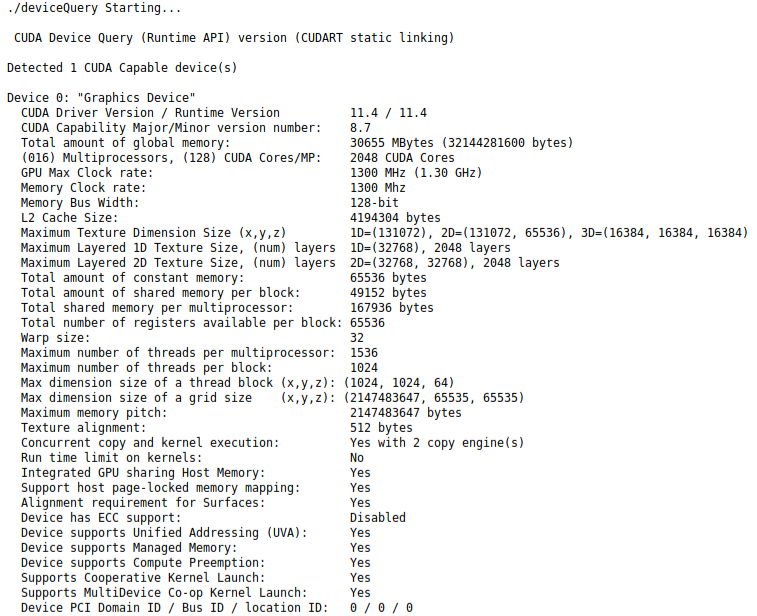
For comparison, we will use the Jetson AGX Xavier development kit (equipped with a 512-core Volta GPU, 32GB LPDDR4x memory, 32GB internal storage, 8-core Carmel CPU, and 2 DLA V1 cores, with AI performance measured at 32 TOPS).
Benchmarking
In this section, we will run the same script on both devices. Before looking at the charts and actual metrics, let’s review the software environment. Our Jetson AGX Orin runs Jetson Linux 34.0, CUDA 11.4, and TensorRT 8.4.0 Early Access with JetPack 5.0 Early Access. On the other hand, Jetson AGX Xavier uses JetPack 4.6 with Jetson 32.6.1, CUDA 10.2, and TensorRT 8.0.1. The main difference between the two is the version of TensorRT, which may affect the engine building process. This must be kept in mind when interpreting the results.
First, we will run a mask detection pipeline with two models: a face detection model and a classification network that takes the detected face as input and determines whether the person is wearing a mask. Both models run in fp16 mode using TensorRT. Don’t worry, tests for int8 quantized models are coming soon.
Based on the above video, we cannot easily distinguish any visual differences. However, from the FPS count, it is clear that AGX Orin is more capable of generating inferences on the input video.
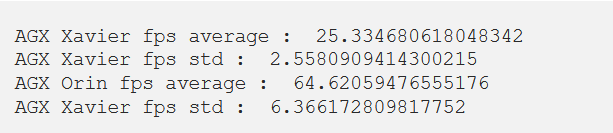
Thus, we can conclude that in this case, Jetson AGX Orin is 2.66 times faster than Jetson AGX Xavier, although the current software is in preview mode and slightly less stable.
The next test is a pure TensorRT-based classification model inference benchmark. For those familiar with edge classification, the EfficientNet series may ring a bell. This well-known classification model is known for providing incredible accuracy with very low latency. It is a well-known fact that after quantization, the vanilla EfficientNet model will lead to a loss of accuracy because the Swish activation function and SENet keep your model in fp16 until mastering QAT. We will consider both fp16 and int8 models. For these tests, we will use two different EfficientNet series — the vanilla versions from B0 to B4 and the lite versions from lite0 to lite4. If you are curious about the implementation of these networks, I strongly encourage you to check out this EfficientNet-lite repository. Additionally, in real-life scenarios, the quantization methods differ between standard models (QAT) and lite models (PTQ), so we decided to use the same PTQ method (same images, parameters…) to quantize both model families. This will yield comparable results.
When deploying classification models on embedded devices, we typically convert them to fp16 or int8 and change the input size. This is done because it has been proven that there is a correlation between input size, accuracy, and inference time. This means that the larger the input size, the more accurate the model may be, but at the cost of significantly longer inference times. Another parameter affecting inference time and accuracy is the size of the model itself (B0, B1,…). Therefore, it is best to benchmark all combinations before selecting the one that suits your needs.
For example, an EfficientNet-B2 with an input size of 100×100 can be as fast as an EfficientNet-B0 with an input size of 224×224, but B2’s accuracy will improve by 0.5%; balancing inference time and accuracy is a huge challenge. This is why in this section, we decided to showcase multiple models based on the same architecture, with multiple batch sizes and multiple input sizes.
FP16
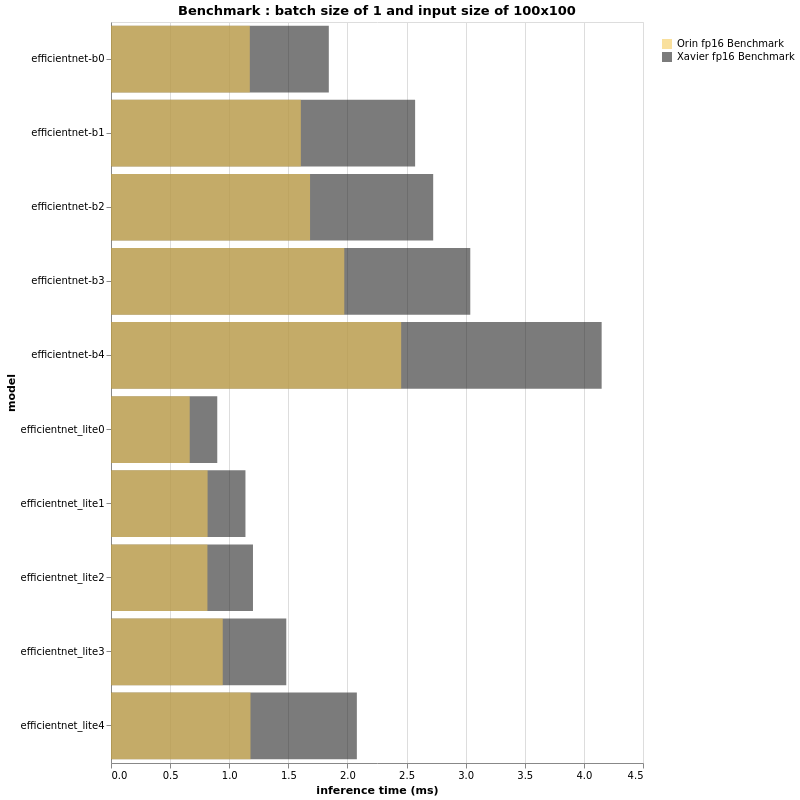
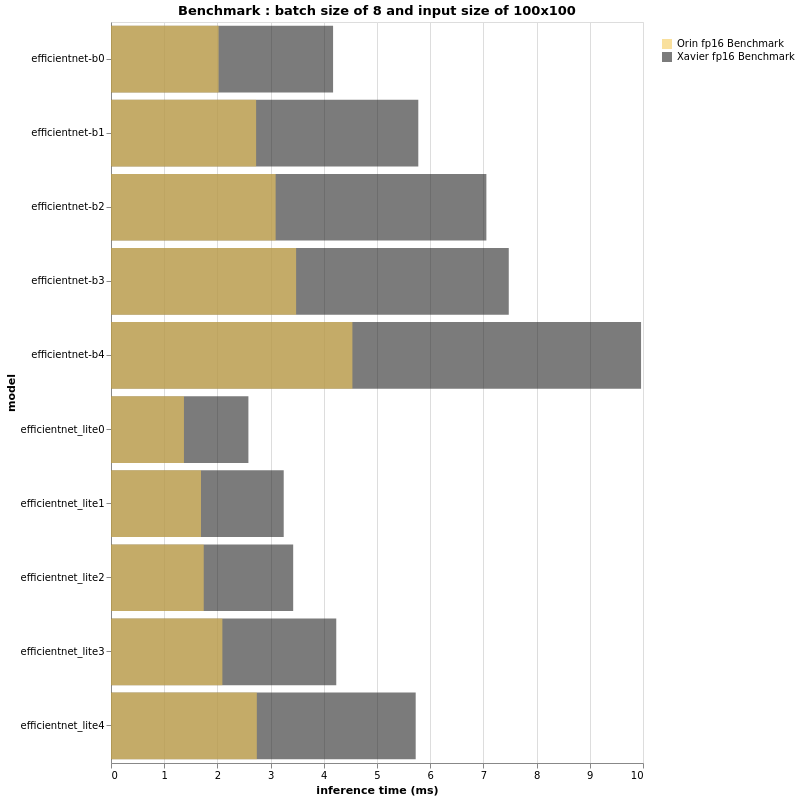
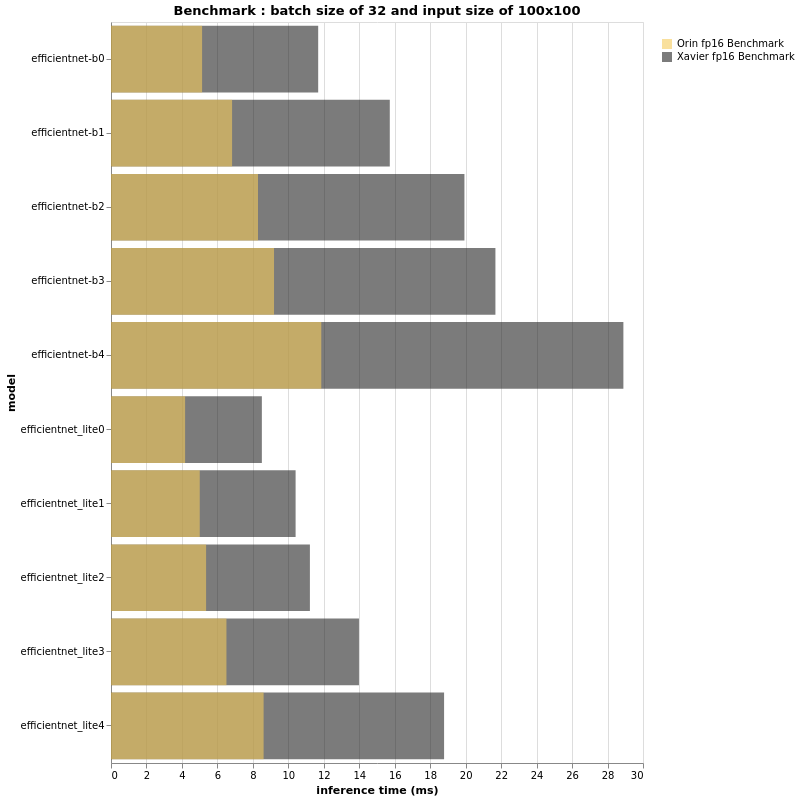
(More test results can be found in the original article)
Based on the beautiful bar charts above, we can definitely draw some conclusions. First, as expected, Jetson AGX Orin is significantly faster than its sibling Jetson AGX Xavier. That said, it again proves that relying solely on TOPS or FLOPS does not provide us with true performance insights. The EfficientNet-B4 with a batch size of 32 and an input size of 224×224 runs as fast on Jetson AGX Orin as the EfficientNet-B0 with the same configuration on Jetson AGX Xavier. Furthermore, B4 achieves a top-1 accuracy of 82.9% on ImageNet, while B0’s accuracy is 77.1%. Therefore, if the FPS performance of your project running on Jetson AGX Xavier is acceptable and does not require more features, you can deploy larger models with Jetson AGX Orin and have a more accurate pipeline.
INT8
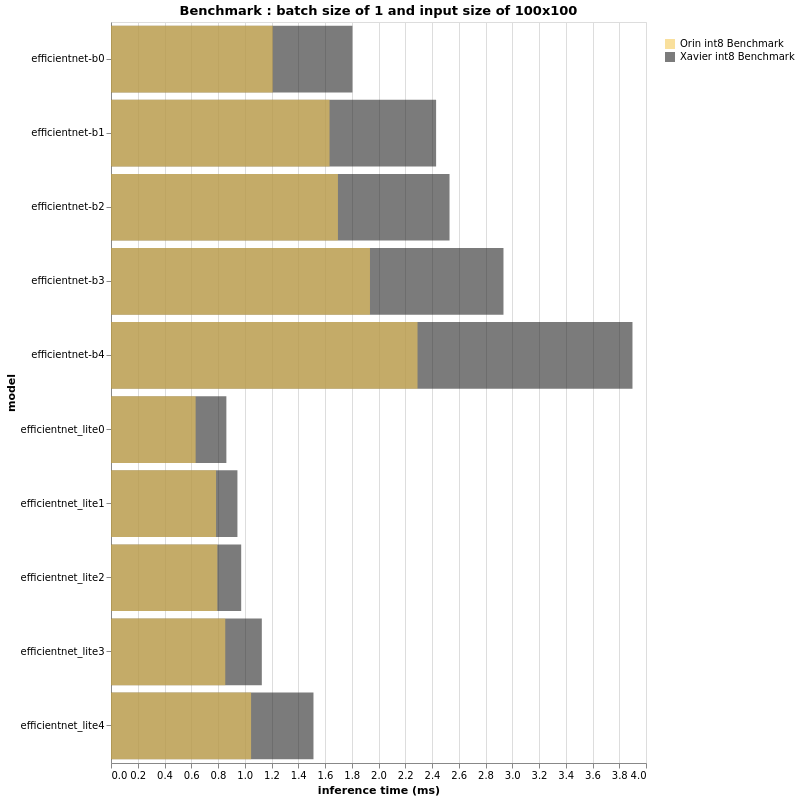
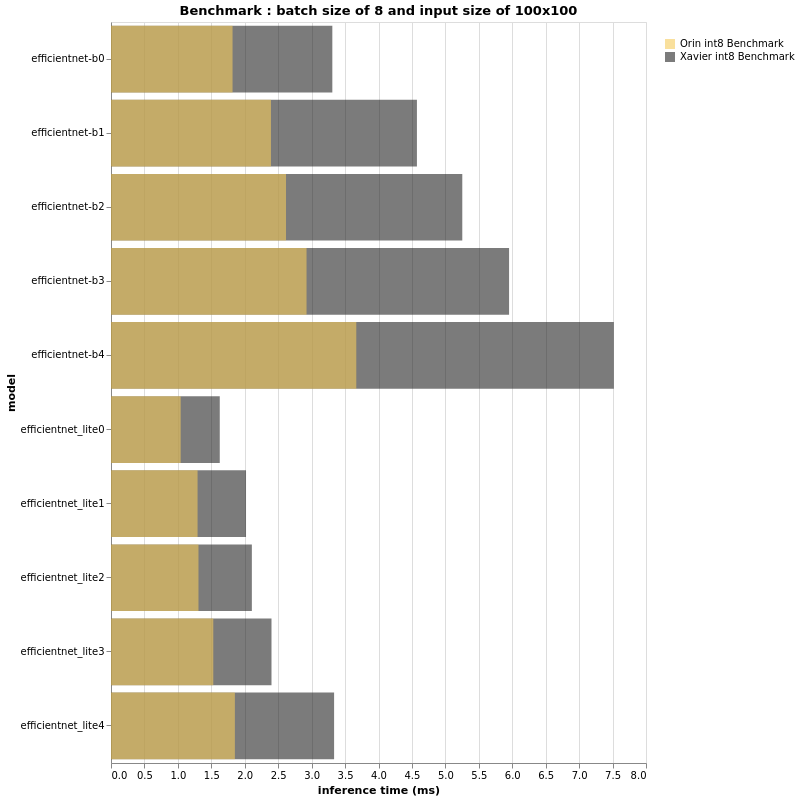
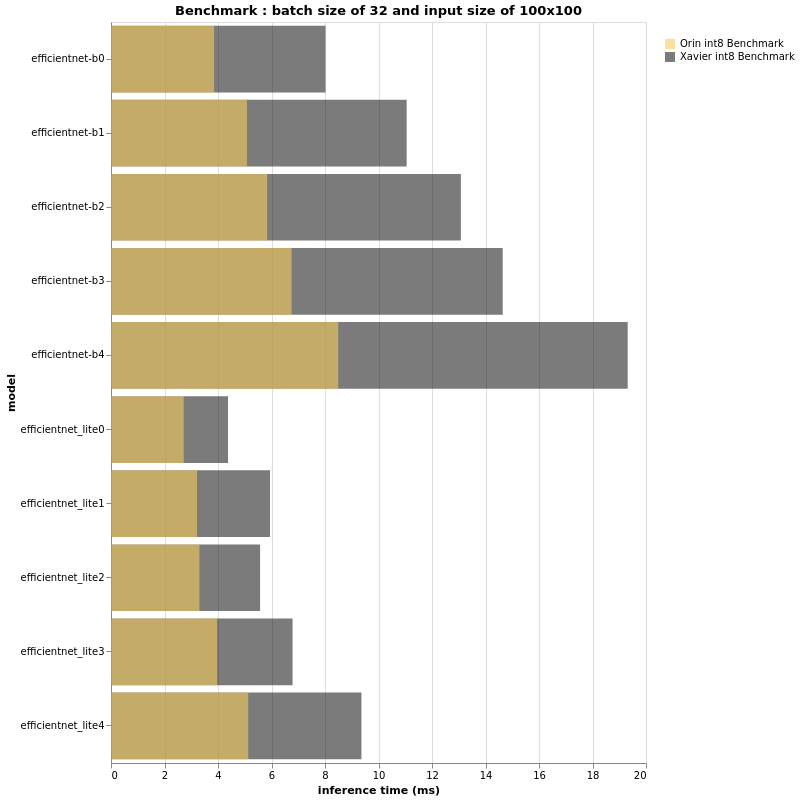
(More test results can be found in the original article)
The charts above look very similar to the results for fp16, don’t they? In fact, the performance ratio of Jetson AGX Orin and Jetson AGX Xavier in this int8 context seems to be the same as for fp16. However, if the performance ratios are roughly the same, a closer look at the x-axis measuring inference time is expected to show differences, especially when the batch size and/or input size are larger. For both fp16 and int8, the larger the input size and batch size, the greater the gap between Jetson AGX Xavier and Jetson AGX Orin. In summary, small input sizes and small batch sizes may not show us a 3x performance difference. We have seen through experiments that in the case of larger models, Jetson AGX Orin’s performance can reach or even exceed 3 times that of AGX Xavier.
Based on our tests so far, Jetson AGX Orin appears to be a very promising new member of the Jetson family. However, we have not yet conducted the final test. Due to the different DLA cores, we will attempt to use NVIDIA AI IOT jetson_benchmarks for a fair and reliable comparison. Although not designed to support AGX Orin, we can run benchmarks and obtain the following results after making some modifications to the scripts:
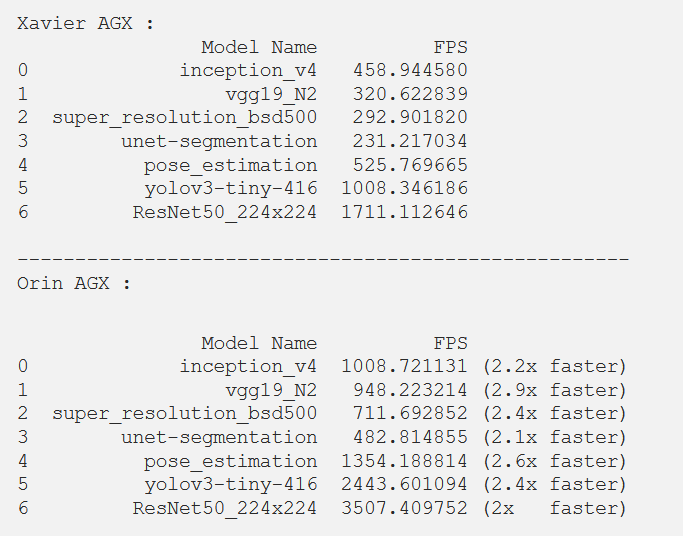
Conclusion
Through these benchmarks, we demonstrate that Orin is a very promising new member of the Jetson series, and we can expect better results in the near future through software updates. With the release of NVIDIA Jetson AGX Orin, NVIDIA has undeniably taken a significant step forward in the embedded AI world. The Jetson Xavier devices are already powerful and full of potential, and Orin now paves the way for the continued growth of embedded AI. We can now plan and undertake larger and more complex projects that we previously could not even imagine. For those limited by the number of tasks, NVIDIA has raised the bar even higher. In fact, just a few days after using Jetson AGX Orin, we at SmartCow are already reconsidering our embedded solutions to propose more features, better accuracy, and reliability; this is a significant game changer.
Original article:
https://medium.com/@Smartcow_ai/is-the-new-nvidia-jetson-agx-orin-really-a-game-changer-we-benchmarked-it-b3e390f4830a
(Requires VPN to access)
More about the AGX Orin development kit:
Interface Introduction —
Flashing —