
On Jetson: Mastering Large Models Day 9: Setting Up EffectiveViT Testing Environment
On Jetson: Mastering Large Models Day 10: OWL-ViT Application
On Jetson: Mastering Large Models Day 11: SAM2 Application
On Jetson: Mastering Large Models Day 12: NanoLLM Development Platform (1): Python API Interface Explanation
On Jetson: Mastering Large Models Day 12: NanoLLM Development Platform (2): Voice Dialogue Assistant
On Jetson: Mastering Large Models Day 14: NanoLLM Development Platform (3): Multimodal Voice Assistant
On Jetson: Mastering Large Models Day 15: NanoLLM Development Platform (4): Visual Analysis Assistant
On Jetson: Mastering Large Models Day 16: NanoLLM Development Platform (5): Visual Database Analysis Assistant

Although large language models open a new era for AI, we can only view these models as a source of energy for AI, and there is still a gap with the application processes we need. Because even the most powerful language models have their strengths, building a complete application requires more supporting components to work together.
For example, in the previous Llamaspeak voice intelligent assistant project we built, it was not just about choosing different large language models as the intelligent core. We also needed to integrate many other supporting technologies, including audio input/output technologies (websocket or usb/i2s), data transmission technologies (gRPC), speech recognition technologies (RIVA ASR), speech synthesis technologies (Piper TTS), and so on.
The following diagram is a simple illustration of the technical Llamaspeak project:
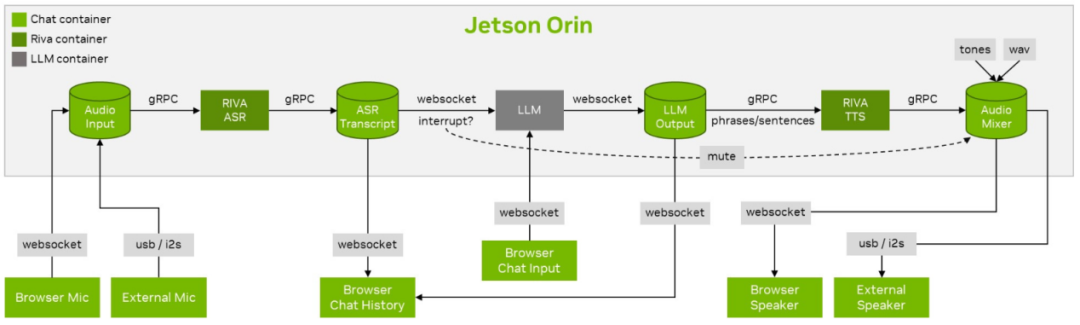
In real-time, there are many fixed links in this process, and the main differences lie in the following parts:
-
Model Selection: According to the previous project cases, if we choose a model that supports multimodal functionality, then this application will have multimodal recognition capabilities; otherwise, it can only provide simple dialogue functionality;
-
ASR/TTS Voice Types;
-
Video Sampling Parameters;
-
Transmission Protocols required for Web Applications.
Thus, we can package the technologies needed here into an executable unit, using parameter passing to give it different capabilities, which is the prototype of an agent.
As mentioned earlier, NanoLLM currently provides five basic agents: ChatAgent, VoiceChat, WebChat, VideoStream, and VideoQuery. Although we only call nano_llm.agents.web_chat in the Llamaspeak project, it directly includes the functionality of the VoiceChat agent, allowing us to interact directly using the microphone and speakers specified by the browser.
A basic structure of an agent based on a large language model is as follows:
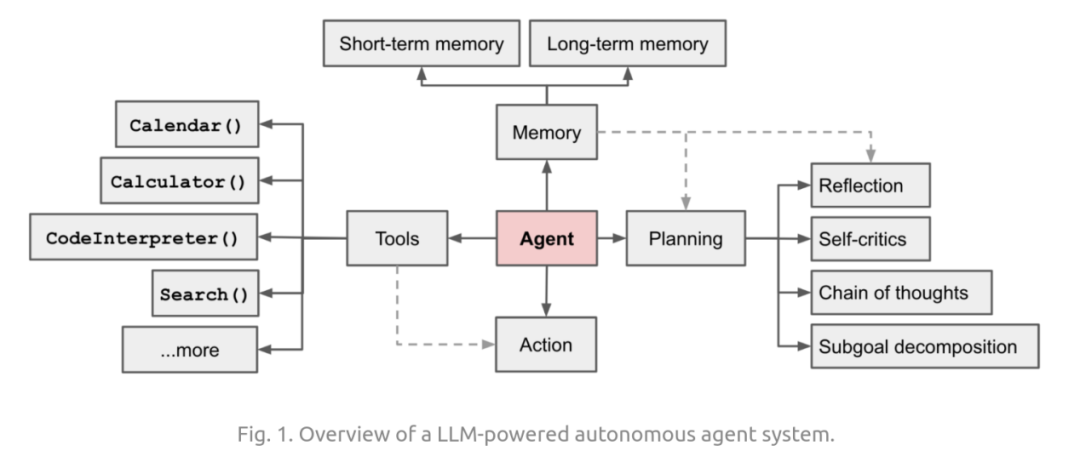
It can be seen that constructing an agent is not a simple task, and this is not the focus of this article. There is a wealth of information online regarding AI agent knowledge and technology, so please search and learn on your own.
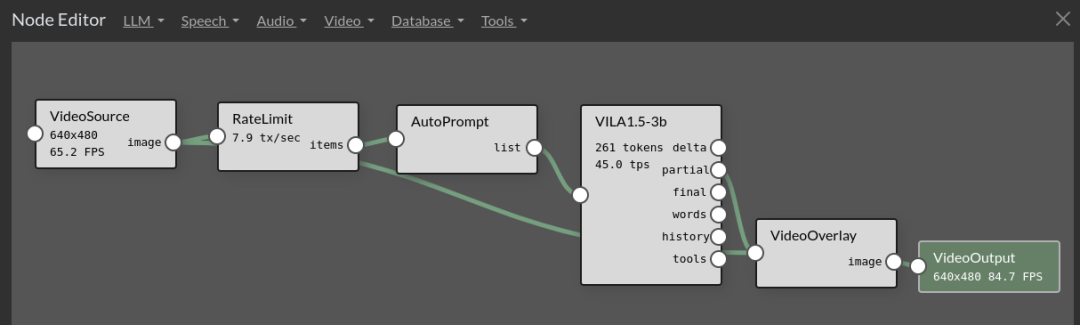
The focus of this article is to teach you how to use the AgentStudio tool provided by NanoLLM (as shown in the figure below), which allows you to easily and quickly build AI applications that meet your needs by dragging and dropping agents and plugins created by the system, creating interactive relationships, and adjusting parameters flexibly.
Now, let’s start by launching the AgentStudio interface, and then introduce the related resources built into the application. Please execute the following command to enter the NanoLLM container:
$ jetson-containers run --env HUGGINGFACE_TOKEN=$HUGGINGFACE_TOKEN
$(autotag nano_llm)Since subsequent applications will need to download related models and resources from HuggingFace, you still need to fill in the secret key obtained from HuggingFace here, or an error will occur.
Then execute the following command to start AgentStudio:
$ python3 -m nano_llm.studioAfter starting the service, you can enter “https://<IP_OF_ORIN>:8050” in your computer’s browser to see the following interface:

We can see that the upper right corner will display the computing resource usage status of the running device (here using Jetson Orin). The options that appear next to “NodeEditor” such as “LLM”, “Speech”, “Audio”, “Video”, “Database”, and “Tools” provide the functionalities listed below:

Due to the large amount of content, there is not enough space to explain in detail. Interested friends can refer to https://github.com/dusty-nv/NanoLLM/tree/main/nano_llm/plugins, which lists all the plugin source codes for your reference:

Now let’s load a pre-existing project called “VILA3B V4L2”, based on the VIAL 3B multimodal large language model, which describes the scenes seen by the camera. Please click the upper right corner “Agent”->”Load”->”VILA3B V4L2″. The interface will not respond immediately because the backend is still processing or downloading. At this time, you can see the resource usage status in the upper right corner is fluctuating.
The execution screen after loading is as follows (already manually adjusted):
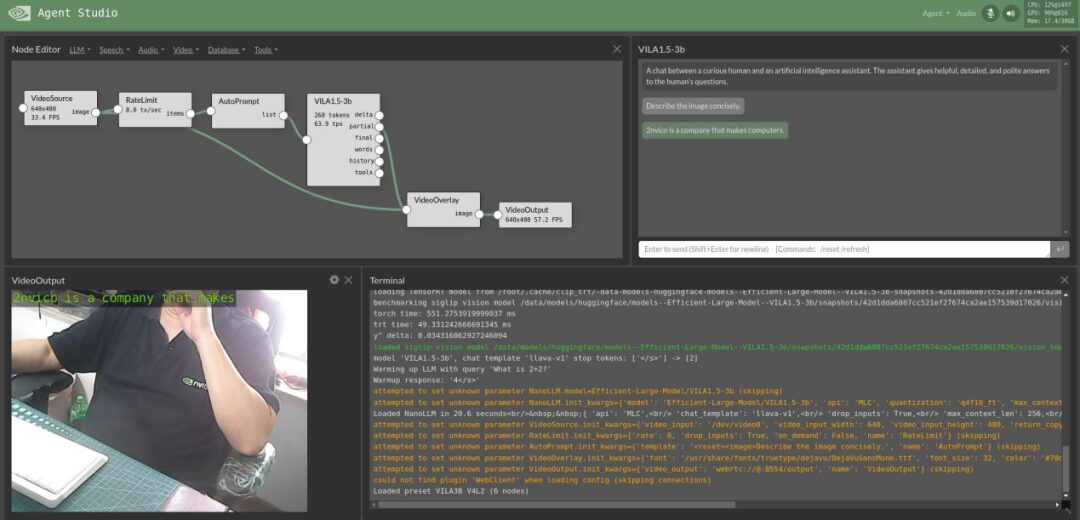
The upper left corner shows the process arrangement of the agents from VideoSource -> RateLimit -> AutoPrompt -> VILA1.5-3b -> VideoOverlay -> VideoOutput. The upper right corner displays the description of the camera by VILA1.5-3b, the lower left corner shows the camera output, and the lower right corner displays the information from the execution terminal.
Now try deleting the “AutoPrompt” from the process (click the Agent box, and an “X” symbol will appear in the upper left corner), and then select “User Prompt” from the “LLM” dropdown options to replace the original position and connection relationship.
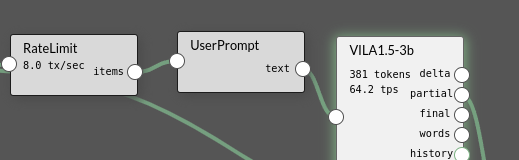
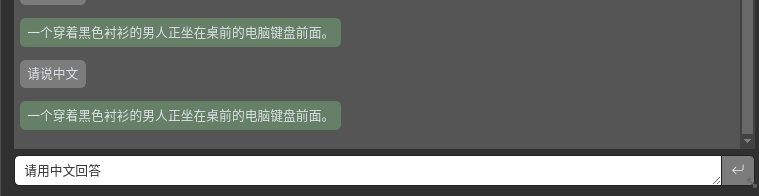
Now enter “Please answer in Chinese” in the dialogue box on the right, and you will see that the response above changes to Chinese information, but the video output on the lower left will show garbled characters.
How is it? This AgentStudio tool is very easy to use! For the vast majority of people who do not know how to create an Agent, it is really convenient. Currently, NanoLLM provides a wealth of Agent plugins, and of course, it also allows developers to create targeted plugins to complete specific tasks.

Come join our event!
Register as a new NVIDIA DLI user and receive a free course worth 600 yuan. Write a review for a gift.