
Introduction:
The head of the Toybrick AI development platform at Rockchip, Qiu Jianbin, conducted a live lecture on the first session of the Embedded AI series in March this year, with the theme “How AI Development Platforms Help Embedded Developers Accelerate Productization of Applications”.
In this lecture, Mr. Qiu first introduced the current status and challenges of embedded AI, then discussed the two main chips used in the Toybrick AI development platform and their advantages, and finally outlined future product plans.
Also, a preview for everyone: on July 24, the Embedded AI series will launch its 7th lecture, themed “Low-Power Intelligent Video Technology and Industry Development Status,” presented by Matrix Vision Technology CEO Bao Dunqiao. Scan the QR code on the poster at the bottom of the article or add assistant Xiao Ke (ID: zhixixi1008) to register.
This article is a textual arrangement of the main lecture segment. If you need the complete PPT, you can reply “Embedded 01” in the backend of this public account.
Hello everyone, I am Qiu Jianbin, the head of the Toybrick AI development platform at Rockchip. It is an honor to share today’s topic with you in the public lecture. The theme of today’s sharing is “How AI Development Platforms Help Embedded Developers Accelerate Productization of Applications”, which is divided into the following four parts:
1. Current status and challenges of embedded AI
2. Analysis of the Toybrick AI development platform
3. The advantages of the Toybrick series in efficient development and deployment of embedded vision applications
4. Future product planning of Toybrick
Current Status and Challenges of Embedded AI
Embedded AI is often referred to as edge computing. In the past, many algorithm companies would perform calculations on PCs or graphics cards, so the cloud computing capabilities were stronger and could handle tasks more smoothly. However, cloud computing also faces limitations, such as the timeliness of AI computation, speed, and cost constraints on computing power. Therefore, many algorithm companies need to convert some algorithms into products and hope to adopt edge computing to enhance the process of transforming R&D results into the market. Thus, many AI algorithm companies and research institutions are exploring how to quickly convert R&D results into products to gain a competitive edge in the market.
However, the current problem is that the NPU IPs from different companies are not the same. The transition from PC to edge computing poses many challenges, requiring significant time to become familiar with different platforms. Additionally, many algorithm companies and research institutions lack hardware development capabilities, and some do not even understand the underlying hardware platforms. This makes their development process relatively difficult and time-consuming.
We have made corresponding hardware platforms relatively complete and can provide some case studies to developers, allowing them to quickly evaluate existing algorithms and ultimately transform them into products swiftly.
Analysis of the Toybrick AI Development Platform
Launched in 2019, the Toybrick AI development platform provides various series of development platforms and reference designs to meet different user groups on the hardware side. On the software side, it offers a stable and reliable system platform, rich development tools, AI teaching cases, and an open-source community. Our platform aims to provide an efficient, convenient, and stable development environment, enabling developers to quickly get started with AI application development, accelerate the product R&D process in the AI industry, and enhance the application ecosystem.

Currently, the platform mainly uses our two NPU-equipped chips. The first is the RK3399Pro chip, which if any of you have used the 3399, you may be familiar with. Compared to the 3399, the 3399Pro only adds an NPU. First, let’s introduce the specifications of the NPU: this NPU has 1920 INT8 MAC computing units, 192 INT16 computing units, and 64 FP16 computing units, capable of running at a maximum of 800MHz. Other performance metrics are also strong, such as a dual-core A72+A53 CPU, a Mali 4-core T860 GPU, and support for 5.1 eMMC. In terms of video editing capabilities, it can handle 4K at 60 frames, supports decoding for both H.264 and H.265, supports 1080p encoding, and includes a secure OP-TEE architecture with support for Widevine Level 1 and PlayReady. The display interface is also quite rich, including 4K output, and there are many video input interfaces, making it applicable in various scenarios. We have two independent 13MPixel ISPs with MIPI CSI-2 interfaces, a USB processing unit, and we also have Type-C, USB 3.0, and PCIe interfaces.

The second chip is the RK1808. The RK1808 chip features a dual-core A35 and has an NPU similar to the 3399. Other specific parameter information can be seen in the image above. The RK1808 does not come with a GPU, so the difference from the 3399Pro is that apart from the NPU, the 3399Pro has stronger computing performance and video encoding and decoding capabilities. The RK1808 is relatively weaker as it is designed for enterprise processing budgets, focusing on AI NPU inference tasks. It also has some interfaces for communication, such as RGMII, PCIe, and USB 3.0.
We have two products based on the RK1808 chip: the neural network computing stick and the Mini-PCIe sub-card, primarily used for AI inference. The PCIe sub-card mainly communicates results via U3, which will be detailed later.
For the NPU’s budget performance, we have run some common models, such as VGG 16 achieving 46.4 FPS, ResNet50 at 70 FPS, MobileNet reaching 190 FPS, MobileNetV2_SSD achieving 84.5 FPS, and YOLO_v2 at 43.4 FPS. We also support some voice recognition models and provide tools to quickly convert mainstream framework models like Caffe, TensorFlow, and PyTorch.
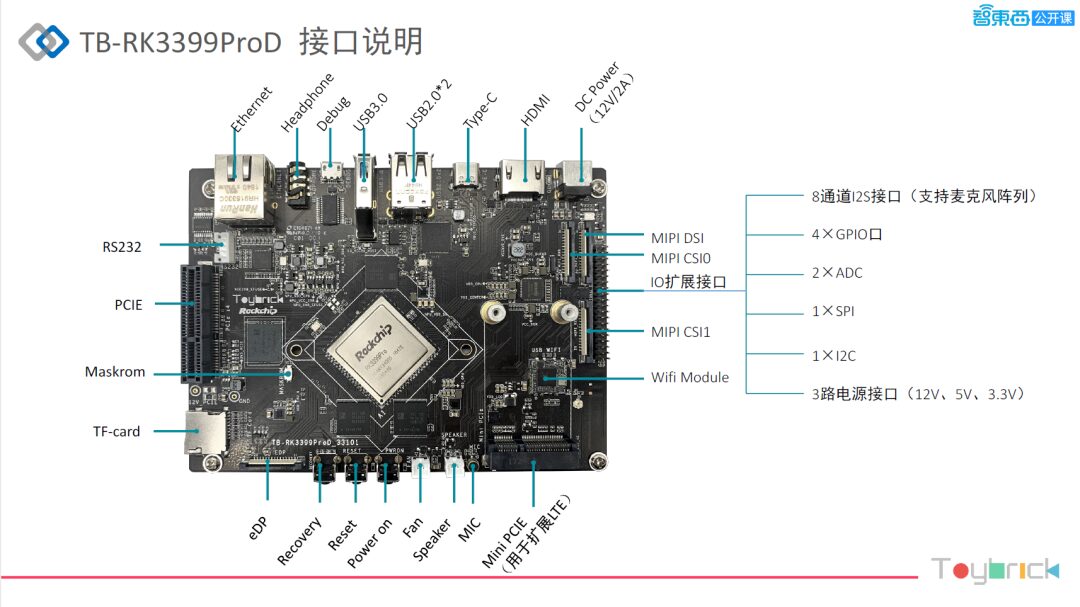
The image above shows the high-speed interfaces related to the chips that we currently have for sale online, allowing everyone to use them directly and quickly evaluate them in their products. These are high-speed interfaces, such as PCIe and USB, and it can also run Android 8.1 and Linux, with designs provided on the board. We have also conducted extensive stability tests, and both the stability of the board and the system are relatively good.
Next, let me introduce the core version of the product. Many customers lack hardware capabilities, so our core version allows customers to set up their baseboards and design different specifications based on their product forms. The core board’s dimensions are 69.6mm x 70mm, designed in a compact format.
As mentioned regarding the 1808, we currently provide the AI computing stick for developers to quickly evaluate. The AI computing stick comes with corresponding cases, allowing our customers to directly run them on different platforms, such as Windows, Android, and even lower-end platforms. We also have a Mini-PCIe form factor that can be deployed onto products. If the platform has a PCIe interface, it can smoothly upgrade the product by simply inserting it, allowing the original product to add AI functionality along with the corresponding software.
Currently, much AI is based on machine vision, particularly around cameras. Therefore, we have development kits that work with video decoding chips, with the analysis module being the 1808. It is compatible with the 38mm x 38mm security standard size, allowing security customers to easily integrate the board into their existing molds for a quick upgrade of the original product form, adding AI functionality. In contrast, other chip manufacturers may have slightly less flexibility; we are relatively more open, allowing many different models and algorithms to run on our platform.
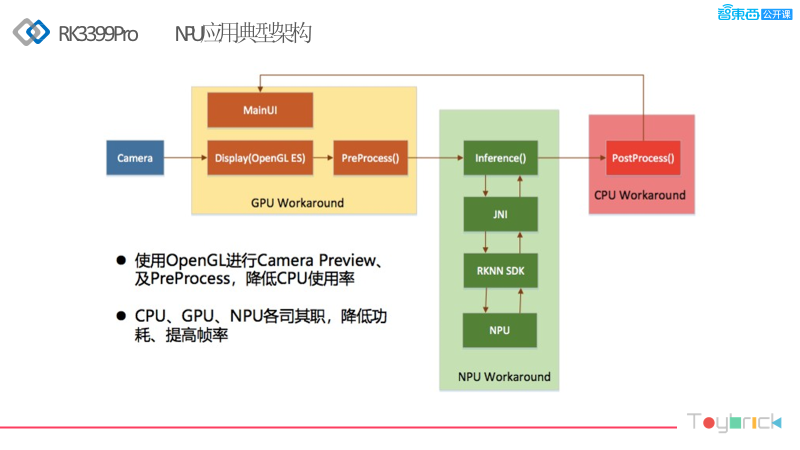
Next, I will briefly introduce the typical architecture of the RK3399Pro NPU application. The camera input goes to the GPU for pre-processing, with OpenGL responsible for rendering and display. The NPU primarily handles inference, while the CPU manages system scheduling. This coordination allows for lower power consumption and higher frame rates, as it does not require assistance for inference, which also helps reduce the load on the CPU and GPU. This is a significant advantage of the NPU, as it can greatly alleviate the burden on the CPU and GPU.
Regarding the data processing flow, the entire process is relatively simple. It transfers model data through the USB host, which could be a PC or our board or an existing platform, then sends the data to our computing stick for inference, obtains results, and finally processes them for display.
For our NPU, we provide the RKNN ToolKit, which is a set of conversion tools. Since different frameworks like Caffe, TensorFlow, and PyTorch are different, we first convert them into RKNN models. The toolkit provides model conversion, inference, and performance evaluation. As a tool, it allows for simulation debugging, performance estimation, and memory estimation, which will be essential during development.
The development process is also relatively simple. The first step is to convert the deep models from different frameworks, such as TensorFlow, Caffe, TF Lite, ONNX, and Darknet, using our tools. After conversion, the resulting RKNN model is loaded into the NPU’s budget unit, and then we load the model file. After that, we input data, like audio or video images, which may require some pre-processing, such as scaling or cropping the images. Then, we call a function interface for model inference, and once processed, we can obtain an output interface. For example, if you input an image of a license plate, you can get the license plate number, which outlines the general development process.
Different models can be called after conversion to RKNN through Python or C++ interfaces. The development tool is designed for rapid model conversion, performance evaluation, and progress prediction, allowing for final debugging and verification of accuracy.
Advantages of the Toybrick Series in Efficient Development and Deployment of Embedded Vision Applications
In the AI domain, we have also developed some preliminary demos, which we call the Rock-X AI SDK. We have accomplished many things, such as common model algorithms, including human skeletal key points, facial feature points, finger key points, face detection, face recognition, liveness detection, head detection, facial attribute analysis, and license plate recognition.
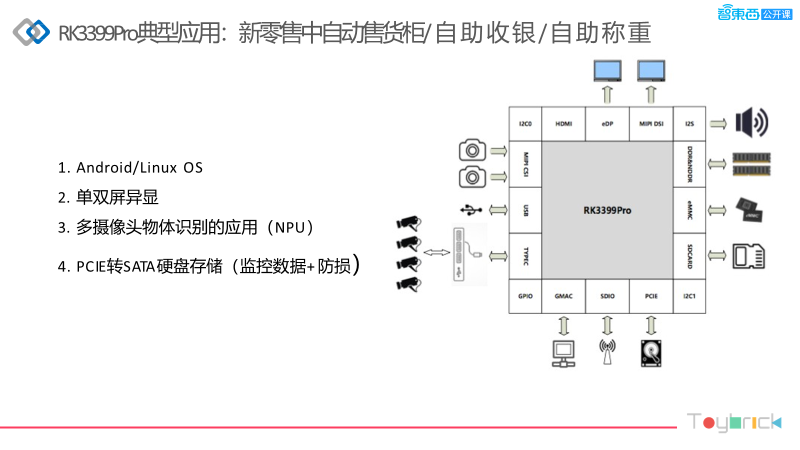
For new retail, there are currently two directions: automated vending machines, self-service checkouts, and self-service weighing. Many now have a dual-screen display requirement, as they may promote advertisements. From the block diagram above, we can see that the primary function is camera acquisition. We can support MIPI interfaces for cameras, connect multiple USB cameras, and even camera data can come in through the network port. The display interfaces are also quite diverse, supporting eDP and HDMI. We support default systems DDR&NDDR and eMMC SD cards, along with PCIe interfaces for SATA hard drive storage.
Currently, automated vending machines in new retail typically have 4-6 cameras. Customers often perform object recognition, and a single camera can achieve around 30 frames. We can decode 4K at 60 frames, and you can calculate other resolutions based on that, with a maximum of 4K at 60 frames for multi-channel video.
The second application is self-service checkouts in large supermarkets, which can directly recognize objects without needing the traditional scanning action. It can also use cameras and algorithms to prevent product loss. The interface differences can obtain data through network ports, as the cameras may be positioned high. Compared to traditional solutions, using graphics card servers in large supermarkets can complicate wiring and reduce flexibility. Using edge computing simplifies deployment and reduces costs, which is why many companies are developing in this direction, utilizing the 3399Pro to achieve such functionalities.
Another application is the use of the 3399 Pro and 1808 for many edge computing servers, performing NVR and AI gateway functions at the terminal. It can run Linux OS directly. Android has the advantage of appearing more polished than Linux, unlike the new retail scenarios requiring advertisements or other components. The interface differences are that camera data comes through the network, while other peripherals are relatively few. Local data can also be stored internally, converting through PCIe’s SATA interface to hard drive storage.
Its application scenarios are quite broad, such as using NVR and AI for edge servers, including smart streetlights. One edge computing server can handle multiple cameras, not just one, processing multiple data streams simultaneously.

The image above illustrates some application scenarios, such as using the 1808 in security cameras for face detection and tracking, intelligent motion detection, area intrusion detection, tripwire detection, and license plate recognition. This is also why we developed a security kit, as a large proportion of embedded AI products focus on machine vision, primarily relying on cameras.
Retail cameras can perform crowd statistics, hotspot analysis, and action detection, including behavioral analysis. For home security cameras, they can detect and recognize people, pets, and vehicles, as well as detect when packages are placed or taken. Edge computing has advantages in these products, allowing direct processing of raw data, resulting in richer features compared to previous cloud computing, reducing network transmission, speeding up response times, lowering power consumption, and reducing costs.
Another direction is the DMS, which focuses on safety in passenger buses. A vehicle may have multiple cameras to detect actions such as the driver yawning, smoking, dozing off, using a phone, or talking. Bus companies can use this data for inspections and can also implement some ADAS functions, such as lane departure warnings, collision warnings, traffic sign recognition, as well as blind spot detection, driving records, and voice interaction. We can connect multiple cameras; for example, an N4 board can connect up to six streams, and we can encode 6-8 streams.
With minor modifications to your original product form, you can achieve good product design with the 1808. If you have a PCIe module or a small designed module, you can integrate it into your existing product platform, transforming it into a product that supports AI functionality, making product upgrades easier. For example, a vacuum cleaner can achieve object detection and intelligent obstacle avoidance through laser navigation and camera integration, while a children’s story machine can implement fingertip recognition and support microphone voice arrays.
For NPU, some customer models may be large or require multiple camera streams, necessitating strong computing power. We can achieve computational power stacking through multiple computing sticks or platform modules. For example, one NPU or one 1808 computing stick may only handle a few streams, which depends on the actual model’s requirements. If there are many streams, multiple units may be needed, which is why we also have a multi-stream demo.
Future Product Planning of Toybrick
Future planning mainly focuses on RKNN. For instance, Pytorch is already supported, and previous work involved mixed quantization, online debugging, and optimizations to accelerate model loading times. We will also interface with TensorFlow 2.0 and eventually optimize TF-Keras. We will provide some cases, such as barcode and QR code recognition, OCR, and voice recognition.
In the future, we will introduce some hardware platforms based on our new products, chips, and different product directions to enable our developers to quickly develop.
Click the bottom of the article to 【read the original text】 to watch the complete replay.
PPT Access👇👇
Reply “Embedded 01” in the backend of this public account to obtain the complete lecture PPT.
Free Course Materials


Previous Highlights

-
Leading Baidu Algorithm Expert Explains Enterprise-Level High-Precision AI Models Based on EasyDL Training and Deployment in 35-Page PPT [Includes PPT Download and Practical Video]
-
SenseTime Executive Research Director Explains the Four Major Challenges of Image Understanding Algorithms in 22-Page PPT [Includes PPT Download]
-
80-Page PPT Explaining SenseTime’s Latest Research and Progress in AutoML [Includes PPT Download]
END
Live Preview
On July 24 at 7 PM, the 7th lecture of the Embedded AI series will officially begin online! Matrix Vision Technology CEO Bao Dunqiao will explain low-power intelligent video technology and industry development status.
Scan the QR code in the poster below to register quickly👇👇👇

Your every “look” is regarded as a like by me
▼