Source: Datawhale
Datawhale Insights
Author: Chen Andong, Datawhale Member
Datawhale Insights
Author: Chen Andong, Datawhale Member
Introduction
Through this open-source course, readers will gain a comprehensive understanding of agents, mastering their design principles, advantages, application scenarios, and current limitations. We hope this course can provide value to a wide range of learners,promoting in-depth learning and application of the theoretical foundations of large models, while also inspiring more innovation and exploration.
Overview
Throughout the history of technological development, humans have always attempted to create an agent or entity that can autonomously accomplish preset goals, namely intelligent agents (AI Agents or Agents), to assist humans with various tedious tasks. Over the years, agents have attracted continuous research and exploration as an active application area of artificial intelligence. Today, large language models are flourishing and evolving rapidly.
In the implementation of agent technology, especially in the construction of agents based on Large Language Models (LLMs), LLMs play a crucial role in the intelligence of agents. These agents can perform complex tasks by integrating LLMs with planning, memory, and other key technology modules. In this framework, LLMs act as the core processing unit or “brain”, responsible for managing and executing a series of operations required for specific tasks or responding to user queries.
To demonstrate the potential of LLM agents with a new example, imagine we need to design a system to respond to the following inquiry:
What is the most popular electric vehicle brand in Europe currently?
This question can be directly answered by an LLM updated with the latest data. If the LLM lacks real-time data, it can utilize a RAG (Retrieval-Augmented Generation) system, where the LLM can access the latest car sales data or market reports.
Now, let’s consider a more complex query:
What has been the growth trend of the electric vehicle market in Europe over the past decade, and what impact has it had on environmental policies? Can you provide a chart of market growth during this period?
Relying solely on the LLM to answer such complex questions is insufficient. Although the RAG system, which combines LLMs with external knowledge bases, can provide some assistance, a more advanced operation is required to fully answer this question. This is because answering this question requires first breaking it down into multiple sub-questions, and then solving them through specific tools and processes to ultimately obtain the desired answer. One possible solution is to develop an LLM agent that can access the latest literature on environmental policies, market reports, and public databases to gather information on electric vehicle market growth and its environmental impact.
Furthermore, LLM agents also need to be equipped with “data analysis” tools, which can help agents create intuitive charts using the collected data, clearly illustrating the growth trend of the electric vehicle market in Europe over the past decade. Although these advanced functionalities of such agents currently remain idealistic, they involve several important technical considerations, such as planning solutions and potential memory modules, which help agents track operational processes, monitor, and evaluate overall progress.
LLM Agent Architecture
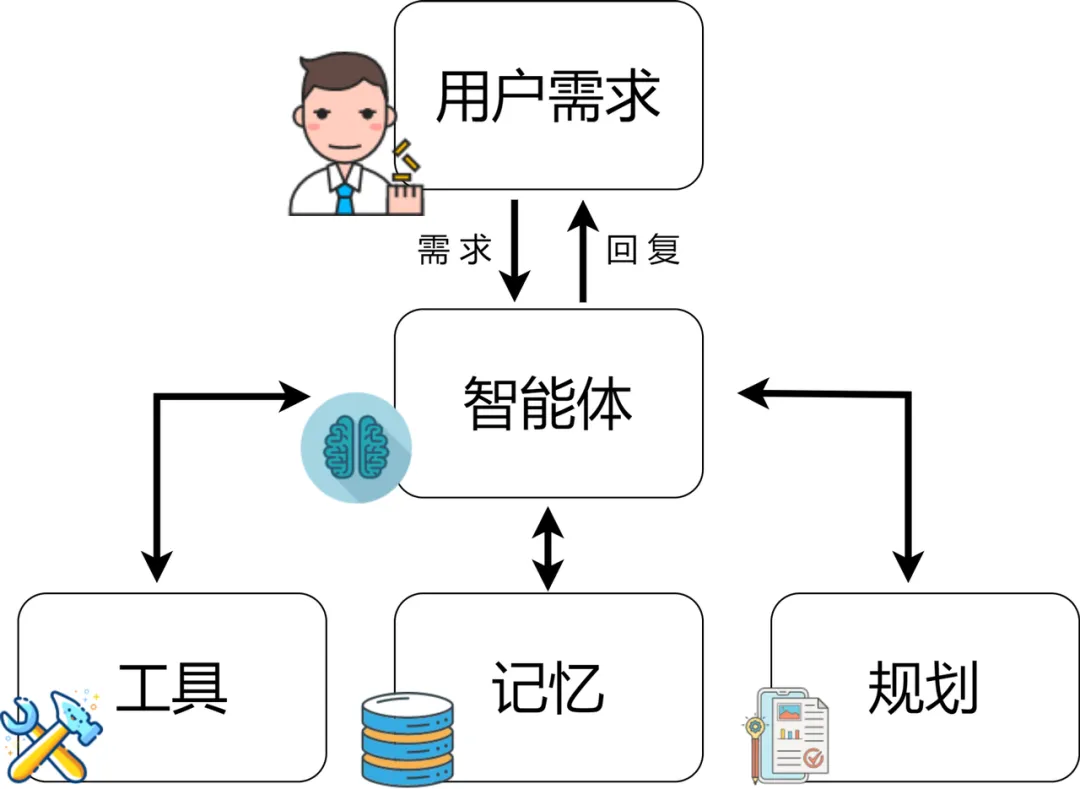
Generally speaking, the framework of LLM-based agents includes the following core components:
-
User Request – The user’s question or request -
Agent/Brain – The core of the agent acting as the coordinator -
Planning – Assisting the agent in planning future actions -
Memory – Managing the agent’s past actions
Agent
In building an agent system centered on Large Language Models (LLMs), LLMs are crucial, serving as the brain and core of multi-task coordination for the system. This agent parses and executes instructions based on prompt templates, which not only guide the LLM’s specific operations but also define the agent’s role and personality in detail, including background, character, social environment, and demographic information. This personalized description allows the agent to understand and execute tasks more accurately.
To optimize this process, system design needs to consider several key aspects:
-
First, the system must possess rich context understanding and continuous learning capabilities, not only processing and remembering a large amount of interaction information but also continuously optimizing execution strategies and predictive models. -
Second, introducing multimodal interaction, integrating various input and output forms such as text, images, and sound, allows the system to handle complex tasks and environments more naturally and effectively. Additionally, the agent’s dynamic role adaptation and personalized feedback are also key to enhancing user experience and execution efficiency. -
Finally, strengthening security and reliability, ensuring stable system operation, and gaining user trust. By integrating these elements, LLM-based agent systems can demonstrate higher efficiency and accuracy when handling specific tasks, while also exhibiting stronger adaptability and sustainability in user interactions and long-term system development. Such systems are not just tools for executing commands but intelligent partners that can understand complex instructions, adapt to different scenarios, and continuously optimize their behavior.
Planning
Non-Feedback Planning
The planning module is crucial for the agent to understand problems and reliably find solutions; it responds to user requests by breaking them down into necessary steps or sub-tasks. Popular techniques for task decomposition include Chain of Thought (COT) and Tree of Thought (TOT), which can be classified as single-path reasoning and multi-path reasoning, respectively.
First, we introduce the “Chain of Thought (COT)” method, which breaks complex problems down into a series of smaller, simpler tasks step-by-step, aiming to handle the problem by increasing the computational testing time. This not only makes large tasks manageable but also helps us understand how models solve problems step by step.
Next, researchers have proposed the “Tree of Thought (TOT)” method, which explores multiple possible paths at each decision step, forming a tree structure diagram. This method allows for different search strategies, such as breadth-first or depth-first search, and utilizes classifiers to evaluate the effectiveness of each possibility.
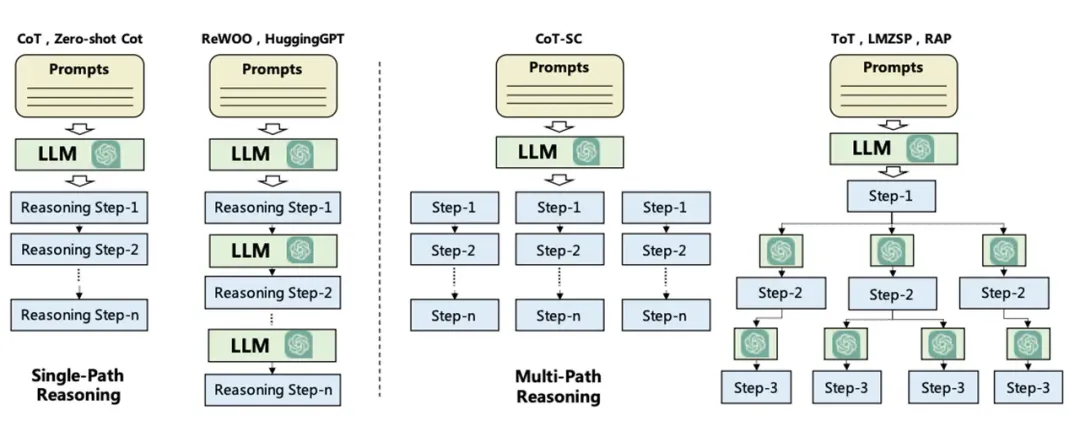
For task decomposition, it can be achieved through different approaches, including directly utilizing LLMs for simple prompts, adopting task-specific instructions, or combining direct human input. These strategies can flexibly adjust task solutions according to different needs. Another method combines classical planners with LLMs (referred to as LLM+P), which relies on external planners for long-term planning. This method first converts the problem into PDDL format, then uses the planner to generate solutions, and finally translates this solution back into natural language. This is suitable for scenarios requiring detailed long-term planning, although reliance on specific domain PDDL and planners may limit its applicability.
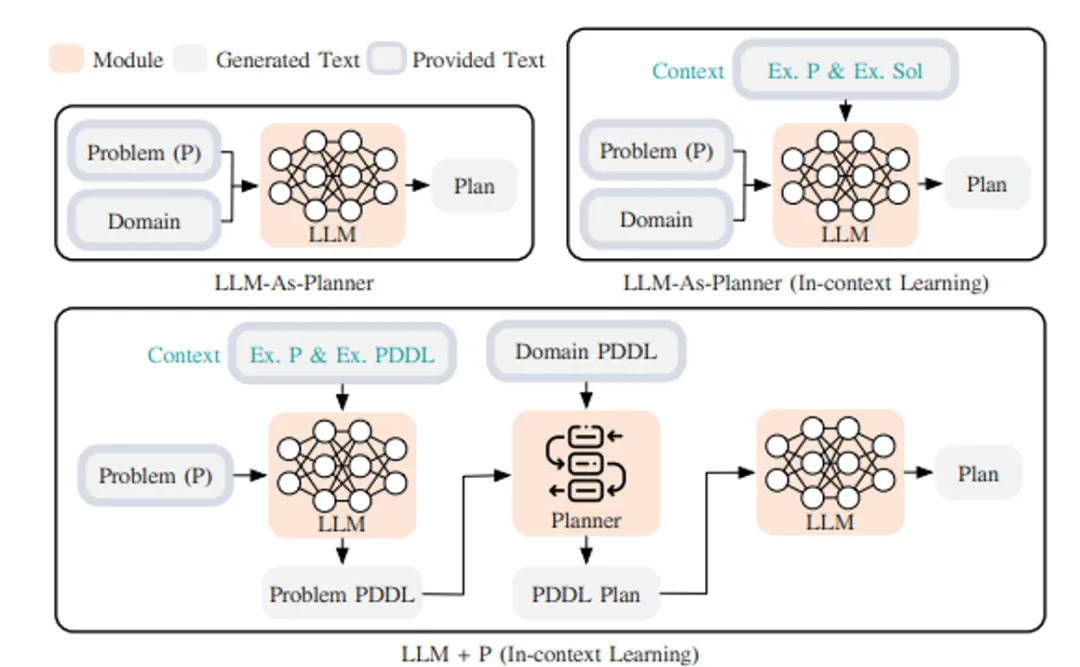
These innovative methods not only demonstrate the diversity and flexibility of problem-solving but also provide us with new perspectives on understanding how LLMs handle complex tasks.
Feedback Planning
The aforementioned planning module does not involve any feedback, making it challenging to achieve long-term planning for complex tasks. To address this challenge, a mechanism can be employed that allows the model to reflect and refine execution plans based on past actions and observations. The goal is to correct and improve past mistakes, which helps enhance the quality of the final outcome. This is especially important in complex real-world environments and tasks where trial and error is key to task completion. Two popular methods for this reflective or critique mechanism include ReAct and Reflexion.

ReAct method proposes to achieve the ability to merge reasoning and execution in Large Language Models (LLMs) by combining discrete actions of specific tasks with language descriptions. Discrete actions allow LLMs to interact with their environment, such as using the Wikipedia search API, while the language description part facilitates LLMs in generating reasoning paths based on natural language. This strategy not only enhances LLMs’ ability to handle complex problems but also strengthens the model’s adaptability and flexibility in real-world applications through direct interaction with the external environment. Additionally, the natural language reasoning paths increase the interpretability of the model’s decision-making process, allowing users to better understand and verify the model’s behavior. The design of ReAct also emphasizes the transparency and controllability of model actions, aiming to ensure the safety and reliability of the model when executing tasks. Therefore, the development of ReAct provides a new perspective for the application of large language models, opening new avenues for solving complex problems through its integration of reasoning and execution.
Reflexion is a framework designed to enhance the reasoning skills of agents by granting them dynamic memory and self-reflection capabilities. This method adopts a standard reinforcement learning (RL) setup, where the reward model provides simple binary rewards, and the action space follows the setup in ReAct, enhancing the action space of specific tasks through language to achieve complex reasoning steps. After each action is executed, the agent computes a heuristic evaluation and may selectively reset the environment based on the results of self-reflection to start new attempts. Heuristic functions are used to determine when trajectories are inefficient or when hallucinations should be stopped. Inefficient planning refers to trajectories that have not successfully completed for a long time. Hallucinations are defined as encountering a series of identical actions that lead to the same result observed in the environment.
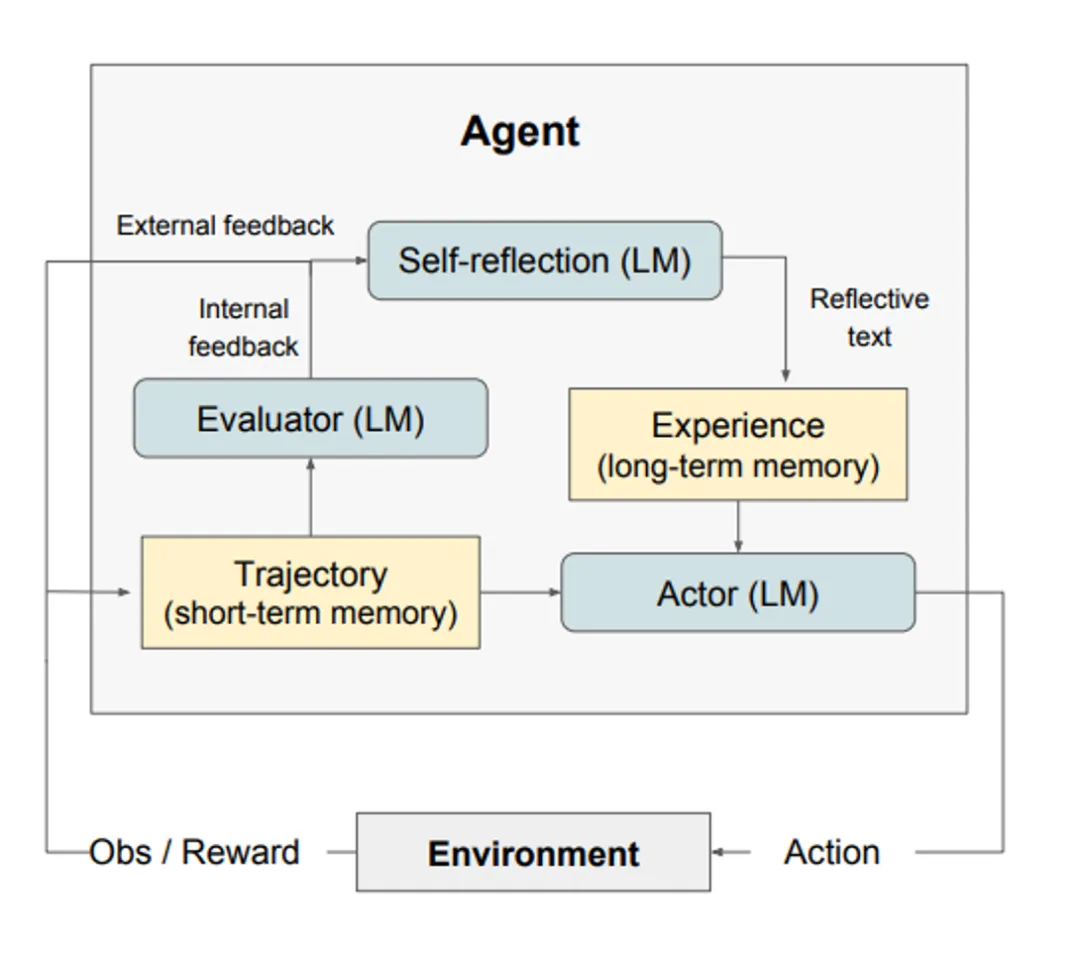
Memory
The memory module is a key component of the agent responsible for storing internal logs, including past thoughts, actions, observations, and interactions with users. It is crucial for the agent’s learning and decision-making processes. According to the literature on LLM agents, memory can be divided into two main types: short-term memory and long-term memory, as well as a hybrid memory that combines both to enhance the agent’s long-term reasoning capabilities and experience accumulation.
-
Short-term Memory – Focused on the contextual information of the current situation, it is temporary and limited, usually achieved through learning constrained by context windows. -
Long-term Memory – Stores the historical behaviors and thoughts of the agent, implemented through external vector storage for quick retrieval of important information. -
Hybrid Memory – By integrating short-term and long-term memory, it not only optimizes the agent’s understanding of the current situation but also enhances the utilization of past experiences, thereby improving its long-term reasoning and experience accumulation capabilities.
When designing the memory module of the agent, it is necessary to choose the appropriate memory format according to task requirements, such as natural language, embedding vectors, databases, or structured lists. These different formats directly impact the agent’s information processing capabilities and task execution efficiency.
Tools
Tools enable Large Language Models (LLMs) to obtain information or complete subtasks through external environments (such as the Wikipedia search API, code interpreters, and mathematical engines). This includes the use of databases, knowledge bases, and other external models, significantly expanding the capabilities of LLMs. In our initial inquiry related to car sales, implementing intuitive charts through code is an example of using tools, executing code to generate the necessary chart information requested by the user.
LLMs utilize tools in different ways:
-
MRKL: An architecture for autonomous agents. The MRKL system aims to include a series of “expert” modules, while the general Large Language Model (LLM) acts as a router, directing queries to the most suitable expert module. These modules can be large models or symbolic (e.g., mathematical calculators, currency converters, weather APIs). They conducted fine-tuning experiments on calling calculators with arithmetic as a test case. The experiments showed that solving verbal math problems is more challenging than solving explicitly stated math problems because the Large Language Model (7B Jurassic1-large model) failed to reliably extract the correct parameters needed for basic arithmetic operations. The results emphasize the importance of knowing when and how to use these tools when external symbolic tools can work reliably, which is determined by the LLM’s capabilities. -
Toolformer: This academic work trained a large model to decide when to call which APIs, what parameters to pass, and how best to analyze the results. This process trains the large model through fine-tuning, requiring only a few examples for each API. This work integrates a series of tools, including calculators, Q&A systems, search engines, translation systems, and calendars. Toolformer achieves significantly improved zero-shot performance in various downstream tasks, often competing with larger models without sacrificing its core language modeling capabilities. -
Function Calling: This is also a strategy to enhance the tool usage capabilities of Large Language Models (LLMs) by defining a series of tool APIs and providing these APIs as part of the requests to the model, enabling the model to call external functions or services while processing text tasks. This method not only expands the LLM’s functionality, allowing it to handle tasks beyond its training data range but also improves the accuracy and efficiency of task execution. -
HuggingGPT: It is driven by Large Language Models (LLMs), designed to autonomously handle a series of complex AI tasks. HuggingGPT combines the capabilities of LLMs with the resources of the machine learning community, such as the combination of ChatGPT and Hugging Face, enabling it to handle inputs from different modalities. Specifically, the LLM plays the role of the brain here, breaking down tasks according to user requests while selecting suitable models based on the model descriptions to execute tasks. By executing these models and integrating the results into the planned tasks, HuggingGPT can autonomously fulfill complex user requests. This process demonstrates the complete workflow from task planning to model selection, execution, and response generation. First, HuggingGPT uses ChatGPT to analyze user requests to understand their intentions and breaks them down into possible solutions. Next, it selects the most suitable expert model hosted on Hugging Face to execute these tasks. Each selected model is called and executed, and its results are fed back to ChatGPT. Finally, ChatGPT integrates the predictions from all models to generate responses for users. The way HuggingGPT works not only expands the capabilities of traditional single-mode processing but also provides efficient and accurate solutions in cross-domain tasks through its intelligent model selection and task execution mechanisms.
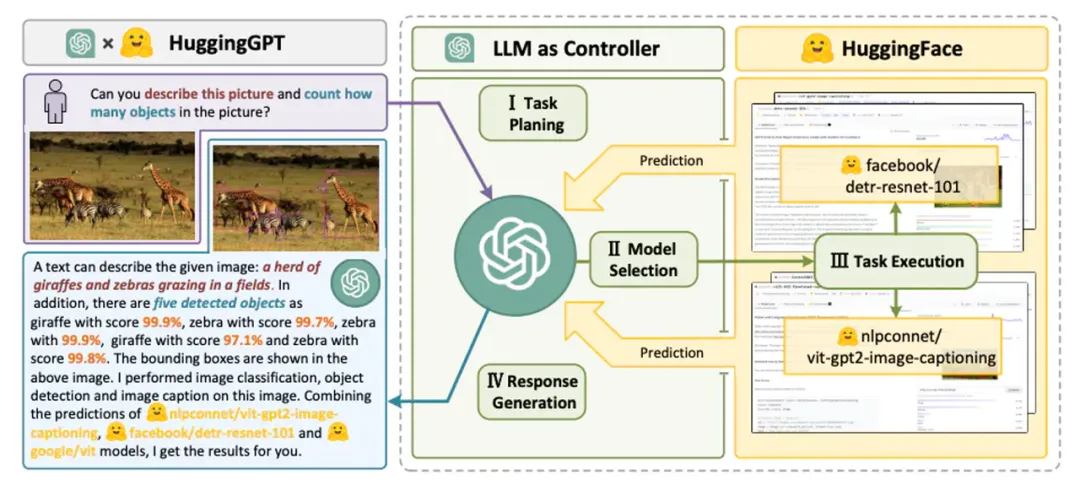
These strategies and tools not only enhance the interaction capabilities of LLMs with external environments but also provide strong support for addressing more complex, cross-domain tasks, opening a new chapter in agent capabilities.
Challenges of Agents
Building agents based on Large Language Models (LLMs) is an emerging field facing numerous challenges and limitations. Here are several major challenges and possible solutions:
Role Adaptability Issues
Agents need to work effectively within specific domains, and for roles that are difficult to characterize or transfer, performance can be improved by specifically fine-tuning LLMs. This includes enhancing the ability to represent uncommon roles or psychological traits.
Context Length Limitations
Limited context length restricts the capabilities of LLMs, although vector storage and retrieval offer the possibility of accessing larger knowledge bases. System design needs to innovate to operate effectively within limited communication bandwidth.
Robustness of Prompts
The design of prompts for agents needs to be robust enough to prevent small changes from leading to reliability issues. Possible solutions include automatically optimizing prompts or using LLMs to generate prompts automatically.
Control of Knowledge Boundaries
Controlling the internal knowledge of LLMs and avoiding the introduction of biases or using knowledge unknown to users is a challenge. This requires agents to be more transparent and controllable when processing information.
Efficiency and Cost Issues
The efficiency and cost of LLMs when processing a large number of requests are important considerations. Optimizing inference speed and cost efficiency is key to improving the performance of multi-agent systems.
Overall, constructing agents based on LLMs is a complex and multifaceted challenge that requires innovation and optimization in multiple areas. Ongoing research and technological development are crucial for overcoming these challenges.