Click the above Network Engineer Club Select “Add to Favorites”
First-hand news, check it in time

The story should start from the beginning.
In the summer of 1973, two young scientists, Vinton Cerf and Robert Kahn, began to work on a method for communication between different machines in the newly born computer networks.
Soon after, they sketched the prototype of the TCP/IP protocol suite on a yellow notepad.

At almost the same time, Metcalfe and Boggs from Xerox invented Ethernet.
We all know now that the earliest prototype of the internet was ARPANET created by the Americans.
Initially, ARPANET used a terrible protocol that could not meet the growing demand for computing nodes. Therefore, by the end of the 1970s, the big shots replaced ARPANET’s core protocol with TCP/IP (in 1978).
By the late 1980s, with the support of TCP/IP technology, ARPANET rapidly expanded and spawned many siblings. These siblings connected to each other and evolved into the world-renowned internet.
It can be said that TCP/IP technology and Ethernet technology are the cornerstones of the early rise of the internet. They are cost-effective, structurally simple, easy to develop and deploy, and have made significant contributions to the popularization of computer networks.

However, as the scale of networks rapidly expanded, traditional TCP/IP and Ethernet technologies began to show signs of fatigue and could not meet the high bandwidth and high-speed development needs of the internet.
The first problem that arose was with storage.
In the early days, storage was known to be the built-in hard drives in machines, connected to the motherboard via interfaces such as IDE, SCSI, and SAS, allowing the CPU and memory to access hard drive data through the bus on the motherboard.
As storage capacity needs grew, coupled with the need for secure backups (requiring RAID1/RAID5), the number of hard drives increased. When several hard drives could not handle it, there was not enough room inside the server. Thus, disk arrays emerged.

Disk arrays are devices specifically designed to hold disks, allowing dozens of disks to be inserted at once.
Data access for hard drives has always been a bottleneck for servers. Initially, servers and disk arrays were connected using network cables or dedicated cables, but soon it was found that this was insufficient. Therefore, fiber optics began to be used. This is known as Fibre Channel.
Around 2000, Fibre Channel was still considered a relatively high-end technology, with a significant cost.
At that time, the optical fiber technology of public communication networks (backbone networks) was at the SDH 155M and 622M stage, while 2.5G SDH and wavelength division technology had just begun and were not yet widespread. Later, optical fibers began to explode, and capacity rapidly increased, evolving towards 10G (2003), 40G (2010), 100G (2010), and 400G (now).
If optical fibers could not be used for general networks in data centers, then network cables and Ethernet had to continue to be used.
Fortunately, at that time, the communication requirements between servers were not that high. 100M and 1000M network cables could barely meet general business needs. It was not until around 2008 that Ethernet’s speed barely reached the 1Gbps standard.
Click the image | Get the latest intelligence for network engineers
After 2010, another issue arose.
In addition to storage, due to cloud computing, graphics processing, artificial intelligence, supercomputing, and various other reasons, people began to focus on computing power.
The gradual weakening of Moore’s Law can no longer support the demand for CPU computing power. It became increasingly difficult to squeeze more performance from CPUs, leading to the rise of GPUs. Using GPUs for computation became the mainstream trend in the industry.
Thanks to the rapid development of AI, major companies have also developed AI chips, APUs, and various other computing boards.
The explosive growth of computing power (over 100 times) directly resulted in an exponential increase in server data throughput.
In addition to the abnormal computing power demands brought by AI, there is also a significant trend in data centers: the data traffic between servers has increased dramatically.
The rapid development of the internet and the surge in user numbers have made traditional centralized computing architectures unable to meet demand, leading to a transition to distributed architectures.
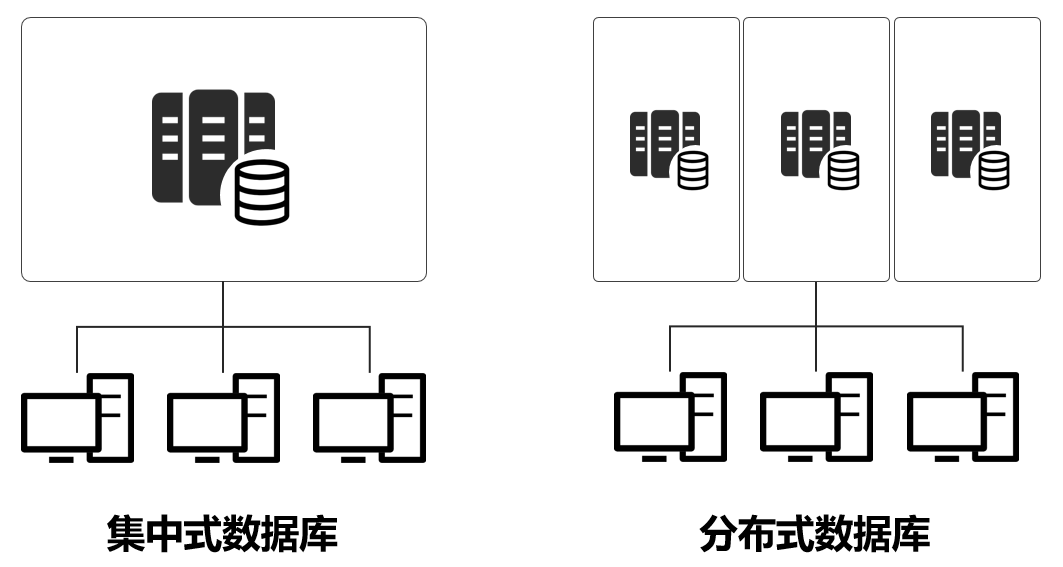
For example, during the shopping festival on June 18th, a single server can handle a hundred or so users, but for millions or billions of users, it definitely won’t suffice. Therefore, distributed architectures emerged, allowing a service to be distributed across multiple servers for processing.
Under distributed architectures, the data traffic between servers has greatly increased. The traffic pressure on the internal interconnect networks of data centers has surged, and the same goes for traffic between data centers.
These horizontal (professionally termed east-west) data packets can sometimes be particularly large, with some graphic processing data packets reaching sizes of several gigabytes.
For the above reasons, traditional Ethernet is simply unable to handle such large data transmission bandwidth and latency (high-performance computing has very high latency requirements). Therefore, a few manufacturers developed a proprietary protocol private network technology, known as Infiniband (literally translated as “infinite bandwidth” technology, abbreviated as IB).
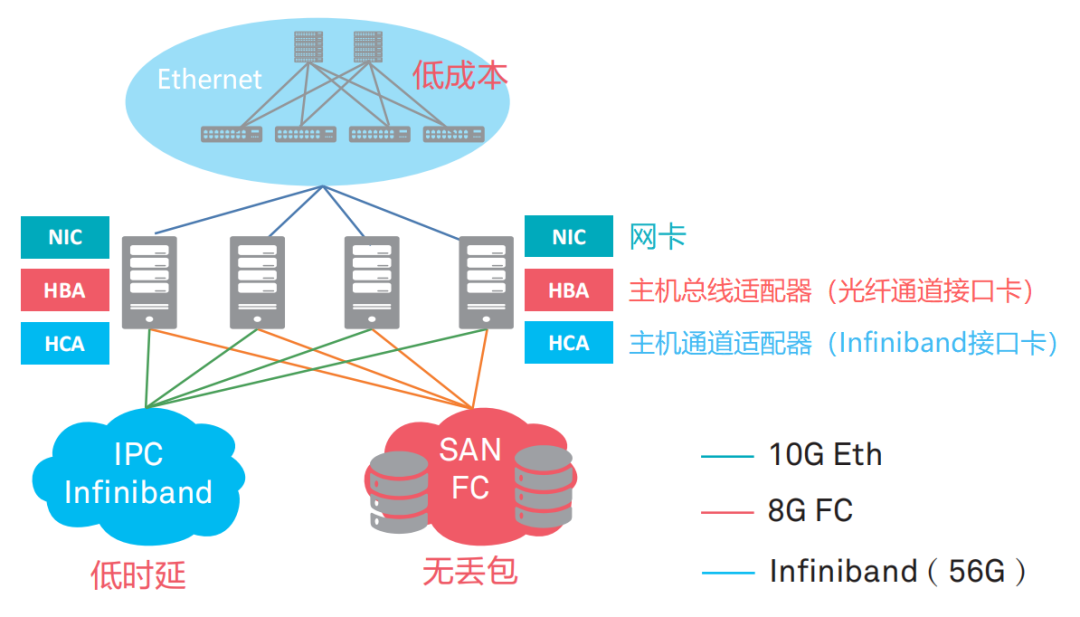
FC vs IB vs Ethernet
IB technology has extremely low latency, but its cost is high, and maintenance is complex, and it is incompatible with existing technologies. Therefore, like FC technology, it is only used under special requirements.
As computing power rapidly develops, hard drives have also evolved, introducing SSDs to replace mechanical hard drives. Memory has also progressed from DDR to DDR2, DDR3, DDR4, and even DDR5, continuously increasing frequency and bandwidth.
The explosive capabilities of processors, hard drives, and memory ultimately shifted the pressure onto network cards and networks.

Students who have studied the basics of computer networks know that traditional Ethernet is based on the “Carrier Sense Multiple Access/Collision Detection (CSMA/CD)” mechanism, which is prone to congestion, leading to increased dynamic latency and frequent packet loss.
As for the TCP/IP protocol, it has been in service for too long, over 40 years old, and has numerous issues.
For example, when the TCP protocol stack receives/sends packets, the kernel requires multiple context switches, with each switch causing a delay of about 5us to 10us. Additionally, at least three data copies are needed, relying on the CPU for protocol encapsulation.
The accumulated latency from these protocol processing times, while seemingly small at a few microseconds, is intolerable for high-performance computing.
In addition to latency issues, TCP/IP networks require the host CPU to participate in memory copying for the protocol stack multiple times. The larger the network scale and the higher the bandwidth, the greater the scheduling burden on the CPU during data transmission, leading to sustained high CPU loads.
According to industry estimates: transmitting 1bit of data requires consuming 1Hz of CPU. Therefore, when network bandwidth reaches over 25G (full load), the CPU needs to consume 25GHz of computing power to handle the network. Users can check their computer’s CPU frequency to see how it compares.

Click the image to get the latest industry news
So, is it possible to simply switch to a different network technology?
While it is possible, the difficulty is too great.
CPUs, hard drives, and memory are internal server hardware; replacing them is straightforward and does not involve external factors.
However, communication network technology is external interconnection technology, requiring consensus for a switch. If I switch and you do not, the network will fail.
Is it feasible for the entire internet worldwide to simultaneously switch technology protocols?
It is not feasible. Therefore, just like the current transition from IPv4 to IPv6, it is a gradual process, starting with dual-stack (supporting both v4 and v6) and then slowly phasing out v4.
Replacing the physical channels of data center networks, switching from network cables to optical fibers, is somewhat easier; it can start small and then gradually expand. Once fiber optics are in place, the issues with network speed and bandwidth can be progressively alleviated.
The issue of insufficient network card capabilities can also be resolved relatively easily. Since the CPU cannot handle it, the network card can do the computation instead. This has led to the rise of intelligent network cards. In a way, this represents a shift in computing power.
Colleagues working on 5G core networks should be familiar with this; the UPF media plane network element in the 5G core network bears all the business data coming from the wireless side and faces significant pressure.

Now, the UPF network element employs intelligent network card technology, allowing the network card to handle protocol processing, relieving pressure on the CPU and enhancing throughput speed.
How to solve the problems of data center communication network architecture? Experts pondered for a long time and ultimately decided to tackle the architecture head-on. They redesigned a solution from the perspective of internal server communication architecture.
In the new plan, application data no longer passes through the CPU and complex operating systems; instead, it communicates directly with the network card.
This is a new communication mechanism—RDMA (Remote Direct Memory Access).
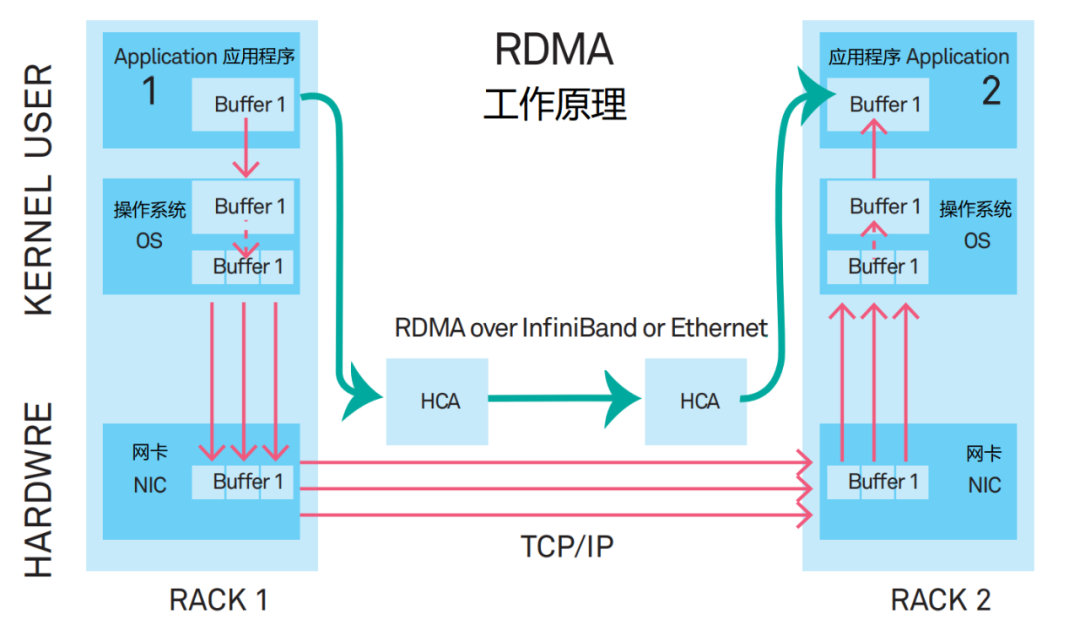
RDMA is essentially a technology that “eliminates the middleman” or a “backdoor” technology.
The kernel bypass mechanism of RDMA allows direct data read/write between applications and the network card, reducing data transfer latency within the server to nearly 1us.
At the same time, the zero-copy memory mechanism of RDMA allows the receiving end to directly read data from the sending end’s memory, significantly reducing the burden on the CPU and improving CPU efficiency.
RDMA’s capabilities far exceed those of TCP/IP and are gradually becoming the mainstream network communication protocol stack, and it will eventually replace TCP/IP.
RDMA has two types of network carrying solutions: dedicated InfiniBand and traditional Ethernet.

Initially, RDMA was proposed to be carried over InfiniBand networks.
However, InfiniBand is a closed architecture, with switches being proprietary products provided by specific manufacturers, using private protocols that are incompatible with existing networks. Additionally, the maintenance requirements are overly complex, making it an unreasonable choice for users.
Thus, experts planned to transplant RDMA to Ethernet.
The awkward part is that RDMA has significant issues when paired with traditional Ethernet.
RDMA has extremely high requirements for packet loss rates. A 0.1% packet loss rate will lead to a drastic decrease in RDMA throughput, while a 2% packet loss rate will reduce RDMA throughput to zero.
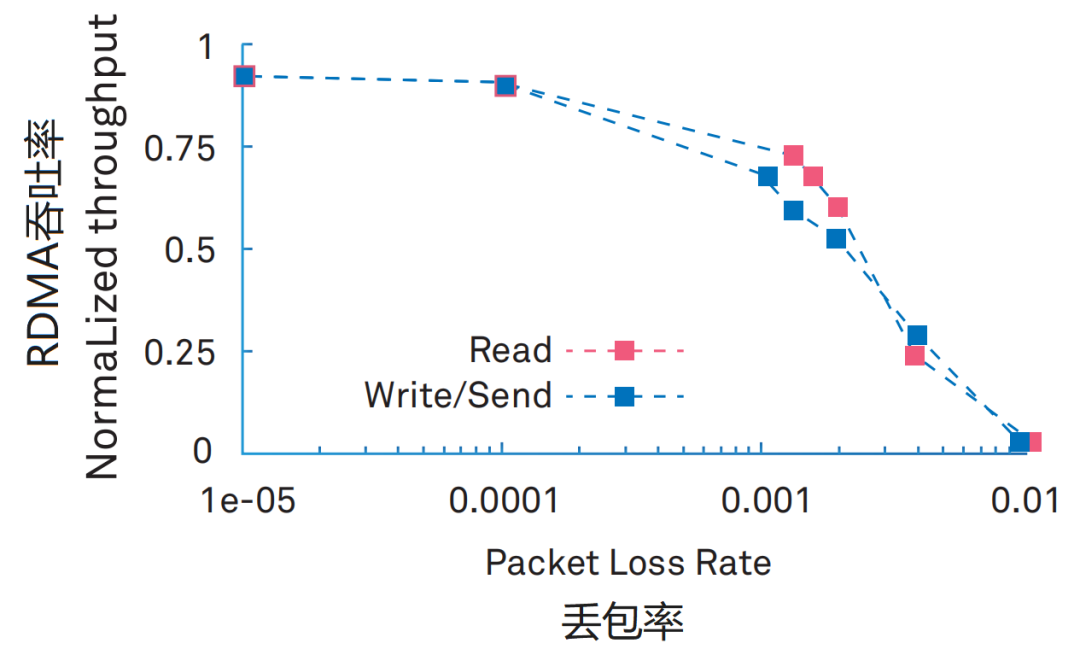
Although InfiniBand networks are expensive, they can achieve lossless and no packet loss. Therefore, RDMA paired with InfiniBand does not require a well-designed packet loss protection mechanism.
Now, transitioning to a traditional Ethernet environment, the Ethernet philosophy is simply two words—”let it be”. Ethernet’s packet transmission follows the principle of “best effort”, and packet loss is commonplace; if packets are lost, they are simply retransmitted.
Thus, experts must resolve the packet loss issue in Ethernet to enable the migration of RDMA to Ethernet. Consequently, there emerged the intelligent lossless technology for hyper-converged data center networks mentioned in the article a couple of days ago from Huawei.
In simple terms, this technology allows Ethernet to achieve zero packet loss, thus supporting RDMA. With RDMA, hyper-converged data center networks can be realized.
As for the details of zero packet loss technology, I will not elaborate further; everyone can refer to the article from a couple of days ago (here is the link again: here).
It is worth mentioning that the introduction of AI-driven intelligent lossless technology is a pioneering effort by Huawei, but the concept of hyper-converged data centers is public. Other manufacturers (such as Sangfor, Lenovo, etc.) also discuss hyper-converged data centers, and this concept has been popular since 2017.
What is hyper-convergence?
To be precise, hyper-convergence refers to a single network that accommodates multiple business types, including HPC (high-performance computing), storage, and general business. Processors, storage, and communication are all resources managed under hyper-convergence, treated equally.
Hyper-convergence must not only meet the extreme demands for low latency and high bandwidth in terms of performance but also be cost-effective and easy to maintain.
In the future, data centers will follow a single path in overall network architecture, namely leaf-spine networks (what exactly is a leaf-spine network?). In routing and switching scheduling, SDN, IPv6, and SRv6 will gradually develop. In micro-architecture, RDMA technology will evolve to replace TCP/IP. At the physical layer, full optical networks will continue to develop, moving towards 400G, 800G, 1.2T…
Personally, I speculate that the current mix of electrical and optical layers will eventually lead to a unified optical layer. Once optical channels transition to full optical cross-connects, they will penetrate into the server interior, where server motherboards will no longer be ordinary PCBs, but optical fiber backplanes. Between chips, there will be optical channels, and potentially even within chips.

Optical channels are the way to go
In routing and scheduling, the future will be dominated by AI, managing all network traffic and protocols without human intervention. A large number of communication engineers will be laid off.
Well, that concludes the introduction to data center communication networks. I wonder if you understood it?
If you didn’t understand it, watch it again.
What is the most valuable Cisco/Huawei certification in the network engineering field?
After obtaining Cisco/Huawei certification, as a network engineer, you can:
-
Cross 90% of the hiring barriers in enterprises
-
Increase 70% employment opportunities
-
Get a stepping stone to the top 100 companies in China, such as BAT
-
Systematically gain hard skills in network technology
-
Top industry professionals can earn over 300,000 annually
How to understand and learn systematically?
-
Scan the QR code below to add Lao Yang as a friend
-
Please note “Certification” when verifying friends
-
Get 1v1 exclusive consultation + discount voucher for class registration

The first 30 fans will receive a free opportunity to ask Lao Yang
– Recommended Reading –