Source: Semiconductor Industry Review
Original Author: Feng Ning
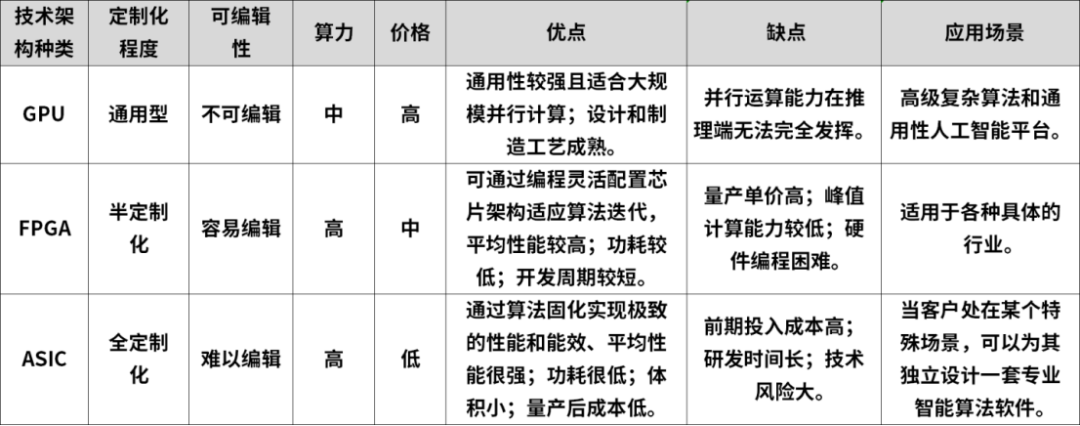
In the layout of artificial intelligence computing architecture, the collaborative working model of CPUs and acceleration chips has become a typical AI deployment solution. The CPU plays the role of providing basic computing power, while the acceleration chips are responsible for enhancing computing performance to assist algorithms in efficient execution. Common AI acceleration chips can be categorized into three main types based on their technological paths: GPUs, FPGAs, and ASICs.In this competition, GPUs have become the mainstream AI chip due to their unique advantages.So how did GPUs stand out among many options?Looking ahead to the future of AI, is GPU still the only solution?
There is a close relationship between AI and GPUs.
1.1 Powerful Parallel Computing Capability
AI large models refer to large-scale deep learning models that need to process massive amounts of data and perform complex computations. The core advantage of GPUs lies in their powerful parallel computing capabilities. Compared to traditional CPUs, GPUs can handle multiple tasks simultaneously, making them particularly suitable for processing large datasets and complex computational tasks. In fields such as deep learning, which require a substantial amount of parallel computation, GPUs exhibit unparalleled advantages.
1.2 Comprehensive Ecosystem
Secondly, to facilitate developers in fully utilizing the computing power of GPUs, major manufacturers provide a wealth of software libraries, frameworks, and tools. For example, NVIDIA’s CUDA platform offers developers a rich set of tools and libraries, making the development and deployment of AI applications relatively easier. This makes GPUs more competitive in scenarios that require rapid iteration and adaptation to new algorithms.
GPUs were initially used for graphics rendering, but over time, their application scope has gradually expanded. Today, GPUs not only play a core role in graphics processing but are also widely used in deep learning, big data analysis, and other fields. This versatility allows GPUs to meet various application needs, while dedicated chips like ASICs and FPGAs are limited to specific scenarios.
Some compare GPUs to a versatile multi-functional kitchen tool, suitable for various cooking needs. Therefore, in most AI applications, GPUs are considered the best choice. However, the wide functionality often comes with a lack of precision in specific areas.Next, let’s take a look at what challenges GPUs face compared to other types of acceleration chips.
Common AI acceleration chips can be divided into three categories based on their technological paths: GPUs, FPGAs, and ASICs.
FPGAs (Field Programmable Gate Arrays) are semi-custom chips that users can reprogram according to their needs. The advantage of FPGAs is that they solve the shortcomings of custom circuits while overcoming the limitations of the number of gate circuits in existing programmable devices. They can flexibly compile at the chip hardware level, with lower power consumption than CPUs and GPUs; however, the hardware programming language is relatively difficult, the development threshold is high, and the chip cost is also higher. FPGAs are faster than GPUs and CPUs because of their customized structure.
ASICs (Application Specific Integrated Circuits) are integrated circuits specifically designed and manufactured according to product requirements, with a higher degree of customization compared to GPUs and FPGAs. The computational power of ASICs is generally higher than that of GPUs and FPGAs, but the initial investment is substantial, and their specialization reduces versatility. Once the algorithm changes, the computing power significantly decreases, requiring re-customization.
Now let’s look at the disadvantages of GPUs compared to these two types of chips.
First, the theoretical performance of GPUs per unit cost is lower than that of FPGAs and ASICs.C.
From a cost perspective, the three types of hardware—GPUs, FPGAs, and ASICs—gradually decrease in versatility from left to right, while customization increases. Correspondingly, the design and development costs increase, but the theoretical performance per unit cost is higher. For example, for classic algorithms or deep learning algorithms that are still in the laboratory stage, using GPUs for software exploration is very suitable; for technologies that have gradually become standards, FPGAs are appropriate for hardware acceleration deployment; for standard computing tasks, dedicated chips ASICs should be directly launched.
Second, the computing speed of GPUs is inferior to that of FPGAs and ASICs.
FPGAs, ASICs, and GPUs all contain a large number of computing units, so their computing power is strong. During neural network computations, all three are much faster than CPUs. However, due to the fixed architecture of GPUs, the supported instructions are also fixed, while FPGAs and ASICs are programmable. Their programmability is key because it allows software and terminal application companies to provide solutions different from their competitors and flexibly modify circuits for the algorithms they use.
Therefore, in many application scenarios, the computing speed of FPGAs and ASICs significantly outperforms that of GPUs.
In specific application scenarios, GPUs excel in floating-point computing capabilities, making them suitable for high-precision neural network calculations; FPGAs are not good at floating-point calculations but can perform strong pipelining for network data packets and video streams; ASICs can achieve almost unlimited computing power based on cost, depending on the hardware designer.
Third, the power consumption of GPUs is much higher than that of FPGAs and ASICs.
Looking at power consumption, GPUs are notoriously high, with a single chip reaching 250W or even 450W (RTX4090). In contrast, FPGAs only consume about 30-50W. This is mainly due to memory reading. The memory interfaces of GPUs (GDDR5, HBM, HBM2) have extremely high bandwidth, about 4-5 times that of traditional DDR interfaces of FPGAs. However, in terms of the chip itself, the energy consumed in reading DRAM is more than 100 times that of SRAM. The frequent reading of DRAM by GPUs results in extremely high power consumption. Additionally, the operating frequency of FPGAs (below 500MHz) is lower than that of CPUs and GPUs (1-3GHz), which also contributes to lower power consumption.
As for ASICs, their performance and power consumption optimization are targeted at specific applications, so they typically achieve higher performance and lower power consumption for specific tasks. Since their design is targeted at specific functions, ASICs usually outperform FPGAs in terms of execution efficiency and energy efficiency.
For example, in fields such as autonomous driving, deep learning applications like environmental perception and object recognition require faster computation responses while keeping power consumption low; otherwise, it would significantly impact the range of smart cars.
Fourth, the latency of GPUs is higher than that of FPGAs and ASICs.
FPGAs have lower latency compared to GPUs. GPUs typically need to divide different training samples into fixed-size “batches” to maximize parallelism, requiring several batches to be collected and processed together.
The architecture of FPGAs is batch-less. Each time a data packet is processed, it can be immediately output, giving it an advantage in latency. ASICs are another technology that achieves extremely low latency. After optimization for specific tasks, ASICs can usually achieve lower latency than FPGAs because they can eliminate any additional programming and configuration overhead that may exist in FPGAs.
Given this, why have GPUs become a hot topic in AI computing today?
In the current market environment, the demands from various manufacturers regarding cost and power consumption have not yet reached a stringent level. Coupled with the long-term investment and accumulation in the GPU field, GPUs have become the most suitable hardware product for large model applications today. Although FPGAs and ASICs theoretically have potential advantages, their development processes are relatively complex, and they still face many challenges in practical applications, making it difficult to achieve widespread adoption. Therefore, many manufacturers choose GPUs as their solution, which has also led to the issue of tight supply for high-end GPUs, necessitating the search for alternative solutions.
END
The reproduced content only represents the author’s views
It does not represent the position of the Institute of Semiconductors, Chinese Academy of Sciences
Editor: March
Responsible Editor: Mu Xin
Submission Email: [email protected]
1. The Semiconductor Institute has made progress in research on bionic covering neuron models and learning methods.
2. The Semiconductor Institute has made significant progress in inverted structure perovskite solar cells.
3. Why are copper interconnects used in chips?
4. What exactly is 7nm in chips?
5. Silicon-based integrated photonic quantum chip technology.
6. How abnormal is the quantum anomalous Hall effect? It may bring about the next information technology revolution!