With the continuous development and popularization of large models, many people have clearly experienced that large language models (LLMs) have become very mature in simple office scenarios, but it is challenging to apply them in more complex business contexts. To achieve this goal, a lot of professional technical support is needed. This has led to a surge in demand for AI agents, but many people still have a limited understanding of agents based on past concepts. In fact, the continuous development and improvement of the technical ecosystem has entered a new phase. With the open-source release of Deepseek-R1, many traditional companies now have the opportunity to deploy large models themselves and use high-performance AI up close, which has changed many people’s perceptions. Additionally, with the release of the MCP standard by Anthropic in November 2024, the number of MCP servers has exceeded 4000 in just four months, further clearing obstacles to AI performance enhancement. This has even led to the emergence of general agents like Manus.
AI agents can be divided into two categories: vertical agents and general agents. Today, we will focus on the design and development of vertical agents.
1. Core Features and Classification of Vertical AI Agents
Vertical agents are AI application systems focused on specific scenarios, which are fundamentally different from general agents.
Their core features are first reflected in their specific goal orientation. These agents are deeply optimized for single scenarios such as medical diagnosis or financial risk control, with precision requirements far exceeding those of general agents. For example, a medical diagnosis agent needs to accurately identify clinical manifestations of specific diseases and provide evidence-based medical support for diagnostic recommendations, while a financial risk control agent needs to analyze transaction patterns in real-time and identify potential fraud based on subtle anomaly indicators. This focus allows vertical agents to achieve judgment levels close to that of professionals in specific fields.
Knowledge embedding is another core feature of vertical agents, requiring the integration of all relevant knowledge bases in the specific domain. For instance, a legal consulting agent needs to integrate legal texts, case analyses, and legal theories, using RAG (Retrieval-Augmented Generation) technology to enhance the professionalism and accuracy of responses. This process involves not only the digitization of a large amount of domain knowledge but also the establishment of an efficient semantic indexing system to ensure that the most relevant knowledge points can be quickly retrieved during user queries. A financial advisory agent, on the other hand, needs to integrate market data, company financial reports, and industry research reports to provide professional support for investment recommendations. In contrast, general agents often can only provide answers at a basic knowledge level, failing to meet the deep demands of professional scenarios.
General Classification:
|
Type |
Features |
Examples |
| Rule-driven | Tasks executed based on predefined processes | Bank compliance review agent |
| Data-driven | Decisions based on real-time data analysis | Supply chain forecasting agent |
| Hybrid-enhanced | Combines rule engines with deep learning models | Medical auxiliary diagnosis agent |
2. Full Process Analysis of Vertical Agent Development
1. Requirement Stage
-
Business Scenario Analysis: Requirement analysis is the foundational step in the development of vertical agents, and the quality of this part determines the value realization of the final product. In this stage, a thorough and detailed analysis of the business scenario is required, using the 5W1H analysis method to capture key information. For example, in the medical imaging diagnosis scenario, we need to clarify that the agent’s service targets include both radiologists and clinical doctors, who have different professional backgrounds and usage needs; core tasks include the complete process from image data preprocessing, lesion detection to structured report generation; triggering conditions include not only the uploading of DICOM format image data but also requests for historical case reviews and other scenarios. This comprehensive requirement analysis ensures that the agent’s functional design seamlessly integrates with actual medical workflows.
-
Value Quantification Model: Constructing a value quantification model is key to proving the rationality of investment. We need to establish a multi-dimensional ROI calculation, considering not only direct costs but also evaluating quality efficiency improvements and opportunity costs among other indirect benefits.
For example, in a smart customer service scenario, a mature agent system can handle 300 standardized dialogues daily, equivalent to replacing three human workers. Calculating based on an annual salary of 150,000 yuan per person, the labor cost savings reach 450,000 yuan per year; at the same time, the agent’s 24/7 service capability can reduce the average response time from 15 minutes to 30 seconds, improving customer satisfaction by about 27%, with the indirect value of increased customer retention reaching 600,000 yuan per year. Through such quantitative analysis, we can provide strong support for project decision-making while also providing clear indicators for subsequent optimization directions.
2. Technical Architecture Design
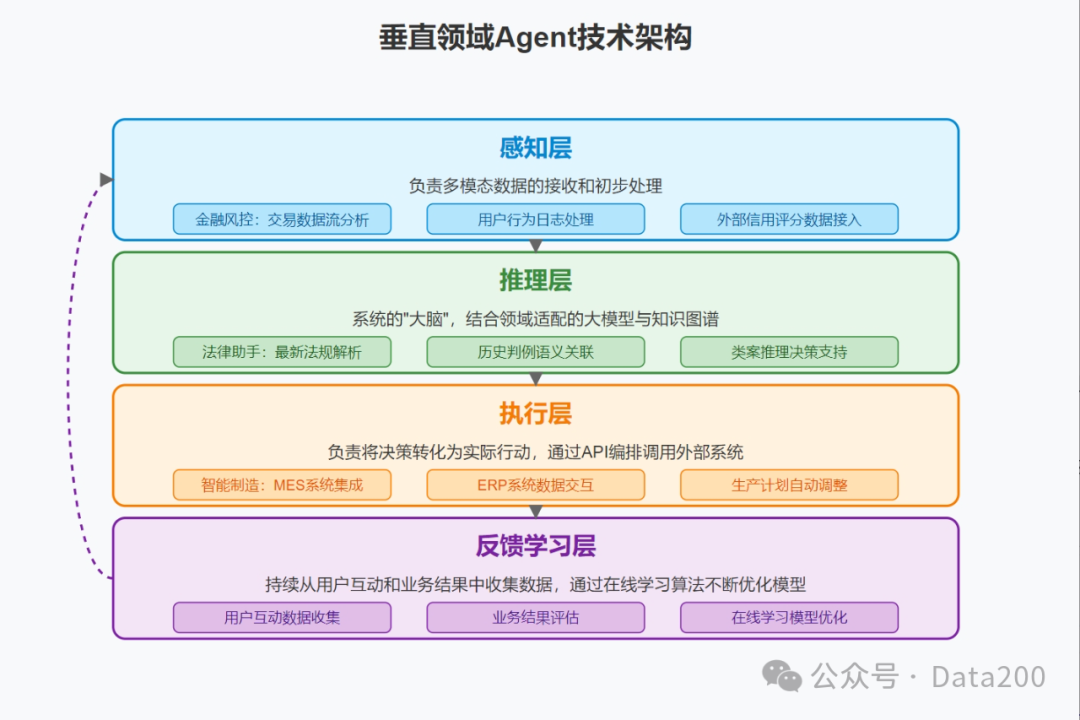
The technical architecture design of vertical domain agents needs to fully consider business characteristics and performance requirements. A typical layered architecture includes four core parts: perception layer, reasoning layer, execution layer, and feedback learning layer.
-
The perception layer is responsible for receiving and initially processing multi-modal data. For example, in a financial risk control scenario, it needs to handle multi-source heterogeneous data such as transaction data streams, user behavior logs, and external credit scores simultaneously;
-
The reasoning layer acts as the system’s “brain,” combining domain-adapted large models with knowledge graphs to understand complex scenarios and make decision reasoning. For instance, in a legal assistant application, it needs to semantically relate the latest regulations with historical cases to support case reasoning;
-
The execution layer is responsible for translating decisions into actual actions by orchestrating API calls to external systems. For example, in a smart manufacturing scenario, it needs to seamlessly integrate with multiple enterprise systems such as MES and ERP to achieve automatic adjustments of production plans;
-
The feedback learning layer continuously collects data from user interactions and business outcomes, using online learning algorithms to continuously optimize model performance.
Key technology selection needs to balance functionality completeness, development efficiency, and maintenance costs.
-
In dialogue management, the LangChain framework provides a flexible agent construction toolchain suitable for rapid prototyping; while ModelScope-Agent has advantages in Chinese scenarios and tool invocation, making it suitable for applications aimed at domestic users.
-
The memory mechanism is key to ensuring a coherent interaction experience for the agent. Using vector databases (such as Milvus or Pinecone) to store dialogue history, combined with a decay weight model, can achieve context understanding lasting several hours, allowing the agent to maintain coherence in complex consultation scenarios.
Additionally, in high-concurrency application scenarios, it is necessary to consider introducing memory databases like Redis as a cache layer for hot sessions to ensure millisecond-level response performance. The choice of technology stack should not only consider current needs but also evaluate future scalability, reserving sufficient technical flexibility for business growth.
3. Data Engineering Implementation
Data engineering is a key link in optimizing the performance of vertical domain agents, with the core focus on building a high-quality professional knowledge base. The knowledge base construction process begins with comprehensive raw data collection, considering various data sources such as public literature, industry standards, and internal company materials.
For example, a medical AI assistant’s knowledge base should include multi-dimensional materials such as medical textbooks, clinical guidelines, drug instructions, and anonymized typical cases. The collected data needs to undergo structured processing, converting unstructured text into standardized knowledge entries, including concept extraction, relationship identification, and attribute annotation. The subsequent data annotation phase is crucial; for structured data such as standard treatment protocols, experienced clinical experts need to review and annotate; while for unstructured data such as medical literature, a semi-automated method combining crowdsourced annotation and adversarial learning can be used, where algorithms generate preliminary annotations that are then verified and corrected by humans, resulting in high-quality annotation outcomes. Data that has undergone professional review will enter the vectorization storage phase, using domain-specific embedding models (such as MedBERT and other pre-trained models in the medical field) to generate semantic vectors and build efficient retrieval-augmented generation (RAG) indexes for millisecond-level knowledge retrieval responses.
The formulation of annotation standards needs to fully consider industry standards and application scenario characteristics. In medical scenarios, disease diagnosis must adhere to the ICD-10 disease coding system to ensure compatibility with global medical information systems; drug annotations should use the ATC classification system to support automatic detection of drug interactions; and medical procedures should be annotated according to CPT coding standards for integration with medical insurance reimbursement systems. In financial scenarios, financial data must comply with the XBRL (eXtensible Business Reporting Language) standard to support cross-institutional and cross-national financial data exchange and analysis; risk control indicators must adhere to the definitions of the Basel III framework to ensure the accuracy and consistency of risk assessments. During the annotation process, a strict quality control mechanism should be established, including random sampling, cross-validation, and expert review to ensure data quality meets industry application standards. High-quality annotated data not only enhances the agent’s professional performance but also provides a reliable foundation for subsequent model fine-tuning.
3. Typical Industry Application Models
1. Medical Field
-
Design Pattern: Multi-modal fusion (text + images + sensor data)
AI applications in the medical field are achieving unprecedented diagnostic accuracy through multi-modal fusion technology. This design pattern integrates text, medical images, and various sensor data to provide comprehensive support for clinical decision-making. For example, a chest CT image analysis agent cleverly integrates three core components: a deep learning model based on ResNet-50 responsible for image recognition, trained on over 100,000 chest CT images, capable of identifying 17 common lesions including lung nodules, emphysema, and interstitial lung disease, with an accuracy of 92.7%; the BioBERT model, specifically pre-trained on medical corpora, can generate structured reports that align with the language habits of radiologists, significantly reducing report writing time; at the same time, the system seamlessly interfaces with existing hospital information systems through FHIR standard interfaces, achieving real-time synchronization of electronic medical records, ensuring smooth transmission of diagnostic information within the medical workflow. In clinical trials at a top-tier hospital, this system reduced the average imaging diagnosis time for doctors from 15 minutes to 4 minutes, while increasing the early lung cancer detection rate by approximately 18%.
2. Education Sector
Educational technology is reshaping traditional teaching models with the help of AI technology. In the lesson preparation phase, a new generation of lesson preparation assistants significantly enhances teacher efficiency by integrating advanced models such as Stable Diffusion and GPT-4. Specifically, teachers only need to input the course topic and key concepts, and the system can automatically generate a complete lesson plan outline that includes teaching objectives, key point analysis, and teaching activity design. At the same time, the Stable Diffusion model automatically generates age-appropriate teaching illustrations based on the course content, optimized according to educational psychology principles, effectively enhancing students’ knowledge absorption rates. In the assessment phase, an intelligent evaluation system based on the Transformer architecture has completely transformed traditional essay grading methods. This system analyzes multi-dimensional indicators such as semantic coherence, argumentative logic, and vocabulary diversity, achieving automatic scoring that is highly consistent with human grading, with an error rate controlled within 3%. Application data from a key high school in Beijing shows that after teachers used this system, grading time was reduced by 78%, while students significantly improved their writing motivation and ability enhancement speed due to receiving immediate feedback.
3. Industrial Manufacturing
AI applications in the industrial manufacturing sector are leading the smart manufacturing revolution with their outstanding real-time performance and reliability. To meet the stringent demands of modern factories, engineers have developed efficient edge computing deployment solutions, particularly suitable for predictive maintenance scenarios. This solution implements core logic in Rust, ensuring memory safety while providing performance close to that of C language. The system achieves millisecond-level data collection through a distributed sensor network, covering multi-dimensional parameters such as temperature, vibration, sound, and current, and then inputs the data into a quantization-optimized ONNX format model for anomaly detection inference. When the system detects potential fault signs, it immediately triggers a maintenance API for intelligent intervention. The entire process’s end-to-end response time is controlled within 50 milliseconds, and the system architecture supports production line-level concurrent processing capabilities, monitoring the operational status of over 1000 devices simultaneously. In a certain automotive parts manufacturer’s production line, after deploying this system for a year, unexpected equipment downtime was reduced by 43%, maintenance costs decreased by 28%, and the first-pass yield rate improved by 7.5%, fully demonstrating the practical value of AI in industrial scenarios.
4. Key Challenges and Breakthrough Paths
1. Small Sample Learning Dilemma
AI applications often face challenges of data scarcity during actual implementation, particularly evident in specialized fields and vertical industries, where the cost of obtaining a large amount of labeled data is high. In response to this issue, the industry has developed a series of solutions. Contrastive learning techniques perform particularly well in scenarios with extremely limited labeled data, learning feature representations by constructing similarity relationships between samples, allowing model accuracy to improve by 15-20% even with fewer than 100 labeled data points. The introduction of frameworks like SimCLR and MoCo enables models to learn meaningful feature representations from unlabeled data, significantly reducing reliance on labeled data. In device-to-device model transfer scenarios, meta-learning methods such as MAML (Model-Agnostic Meta-Learning) enable models to quickly adapt to new environments through a “learn how to learn” strategy, improving convergence speed by about three times and significantly shortening model deployment cycles. For compliance-sensitive fields like finance and healthcare, synthetic data augmentation techniques provide a feasible path to bypass data privacy restrictions by generating diverse synthetic data, increasing dataset diversity by 40% and effectively preventing model overfitting.
Solutions:
|
Method |
Applicable Scenarios |
Effectiveness Improvement |
|
Contrastive Learning |
Labelled data < 100 |
Accuracy ↑ 15-20% |
|
Meta-Learning (MAML) |
Cross-device transfer |
Convergence speed ↑ 3 times |
|
Synthetic Data Augmentation |
Compliance-sensitive fields |
Data diversity ↑ 40% |
Case Study: In the power industry, these technologies have achieved significant results. For example, a provincial power grid company faced a shortage of rare fault samples in their power equipment fault detection project, particularly for specific fault types of high-voltage transformers, with only a few historical records. The engineering team cleverly applied GAN-based data synthesis technology, learning the feature distribution of limited real fault infrared thermal images to generate hundreds of physically plausible simulated fault thermal images. These synthetic data not only visually matched real data but also accurately simulated thermal distribution changes under different load conditions. The fault detection model trained with these synthetic data successfully identified two potential transformer faults in actual deployment, avoiding potential economic losses of millions of yuan.
2. Multi-modal Alignment Challenges
As AI application scenarios become more complex, processing information from a single modality is increasingly insufficient to meet actual needs, making multi-modal fusion a key path to enhance system performance. However, the heterogeneity and temporal inconsistency between different modality data pose severe alignment challenges. The industry has formed a relatively clear technical route to address this issue, mainly focusing on hierarchical fusion and attention mechanisms. In hierarchical fusion, research shows that a progressive strategy from early fusion to late fusion can balance computational complexity and fusion effectiveness. Early fusion retains the integrity of original information by directly concatenating at the pixel or feature level, but incurs higher computational costs; while late fusion integrates predictions from each modality at the decision level through weighted voting or ensemble learning methods, which is more computationally efficient but may lose complementary information between modalities. In practice, multi-level fusion architectures often achieve the best balance, performing preliminary fusion at the intermediate feature layer and then fine-tuning at the decision layer.
In terms of attention mechanisms, cross-modal Transformer architectures achieve dynamic alignment between different modalities through self-attention and cross-attention mechanisms, particularly excelling in processing complex temporal and spatial relationships in multi-modal data such as speech-text-video. This technology can automatically learn the correspondence between different modalities without the need for manually designed complex alignment rules. In a smart city security project, researchers applied this technology to an anomaly behavior detection system, processing monitoring videos, environmental audio, and historical text records simultaneously. Through a carefully designed cross-modal attention network, the system could capture subtle abnormal patterns that single modalities struggled to identify, such as normal walking in video accompanied by abnormal sounds. Actual evaluations showed that the multi-modal fusion method significantly improved the F1-score of anomaly behavior detection from 0.72 in single modality to 0.89, reducing the false positive rate by nearly 60%, greatly alleviating the workload of security personnel and enhancing system reliability. This successful case fully demonstrates the enormous potential of multi-modal fusion technology in complex scenarios.
5. Deployment and Optimization Strategies
1. Robustness Verification System
When AI systems transition from the laboratory to production environments, robustness verification becomes a key step to ensure system stability and reliability. In the financial risk control field, due to the high concurrency characteristics of the business and strict real-time requirements, stress testing is particularly important. For example, in a certain internet finance company’s risk control agent:
# Stress Testing Script Framework (for Financial Risk Control Agent)locust -f stress_test.py \ --users 1000 \ # Simulate concurrent users --spawn-rate 10 \ # New users per second --host https://api.risk-control.com \ --csv=report # Output performance reportThis stress testing scheme verified that the system’s response time was controlled within 150ms under a thousand-level concurrency, ensuring system stability under extreme conditions. In addition to basic performance testing, security verification is equally important. Engineers built an adversarial sample generation framework based on the FGSM algorithm to test the model’s resistance to malicious inputs. The model enhanced through adversarial training reduced the attack success rate by about 65%, significantly improving system security.
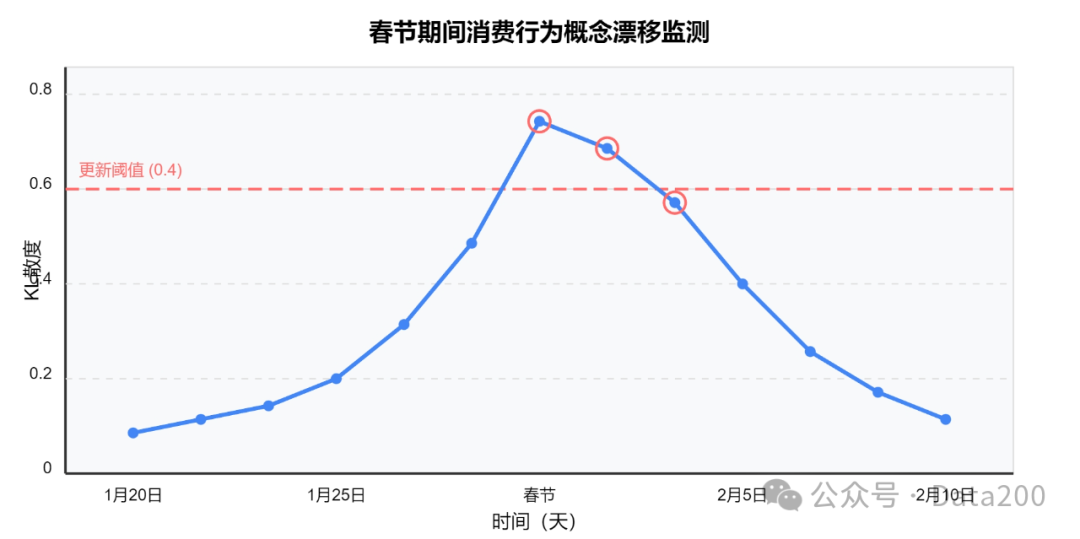
To address the decline in model performance due to changes in data distribution over time, the team designed a real-time monitoring mechanism based on KL divergence, which automatically triggers model hot updates when distribution differences exceed a threshold. The following figure shows the concept drift detected by a payment platform during holiday periods:
2. Continuous Learning Mechanism
Continuous optimization of AI systems after deployment is key to maintaining competitiveness, especially in data-sensitive industries. Federated learning effectively addresses the contradiction between privacy protection and model iteration by using a “model to data” rather than “data to model” approach. Its core implementation logic is as follows:
class FederatedAgent { public void train(Model globalModel) { List<ClientData> clients = getEdgeNodes(); // Get edge nodes for(ClientData client : clients) { Model localModel = downloadModel(globalModel); localModel.train(client.data); // Local training uploadGradients(localModel); // Gradient upload } aggregateGradients(); // Global aggregation }}The advantage of this architecture is that data always remains local, with only model parameters transmitted over the network, greatly reducing the risk of data leakage. In a medical application, a lung nodule detection system constructed by a top-tier hospital in collaboration with several medical institutions in the region adopted this architecture, resulting in a stable weekly improvement of 0.5-0.8% in model AUC, accumulating approximately 8.5% improvement over three months. The following figure shows the performance improvement curve of federated learning in medical scenarios:
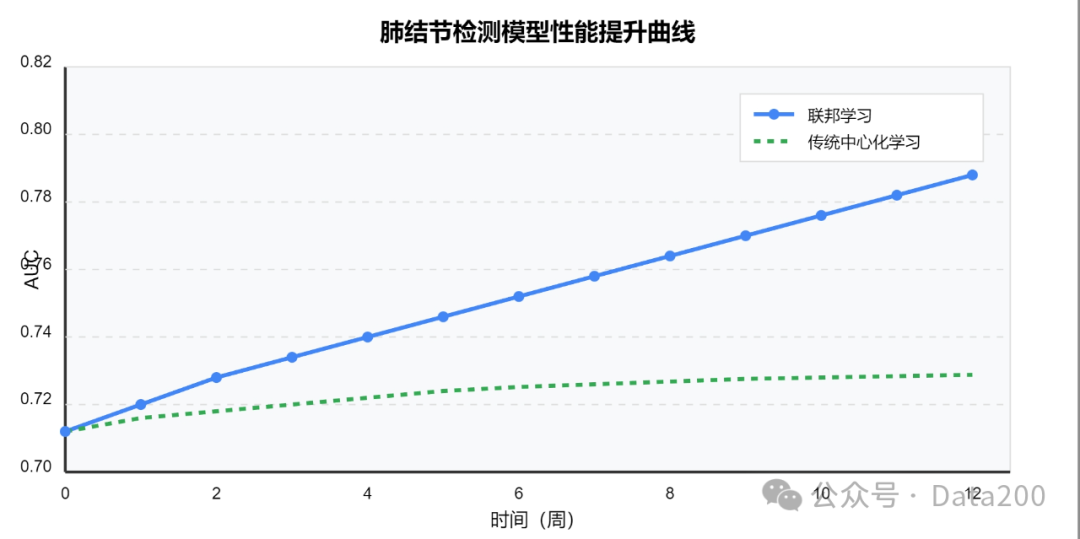
The federated learning architecture not only protects patient privacy but also fully utilizes the data value dispersed across various institutions, significantly exceeding the performance limits of traditional centralized learning methods. This continuous learning mechanism provides an effective way for AI systems to maintain competitiveness in practical applications.
Based on the above information, the development of vertical AI agents can break through the “laboratory-to-production line” conversion bottleneck. In the technological ecosystem of 2025, it is recommended to prioritize fields with clear ROI measurement scenarios such as healthcare, education, and smart manufacturing, while emphasizing the integration and innovation of knowledge engineering and reinforcement learning.
Source | DATA Data Community (ID: Data200)
Author | Qianbao Zhang Wei ; Editor | Xia Jiao
The content only represents the author’s independent views and does not represent the position of the Early Reading Course.


