
Communication protocols can be understood as the rules and agreements established for information exchange between two nodes to work together, such as defining byte order, field types, and the compression or encryption algorithms used. Common protocols include TCP, UDP, HTTP, SIP, etc. Protocols have both procedural specifications and encoding specifications. The procedures include call flows and signaling flows, while the encoding specification defines how all signaling and data are packaged/unpacked.
The encoding specification is what we commonly refer to as encoding/decoding or serialization. This is not only used in communication but is also frequently applied in storage. For instance, when we want to store objects from memory onto disk, we need to perform data serialization.
This article adopts a progressive approach, starting with an example, followed by an iterative evolution of raising questions and solving them, gradually introducing a protocol’s evolution and improvement, and concluding with a summary. After reading, everyone will find it much easier to formulate and choose their own encoding protocols in their work.
1. Compact Mode
The example in this article is communication between A and B for retrieving or setting basic information. Generally, the first step for developers is to define a protocol structure:
struct userbase
{
unsigned short cmd;//1-get, 2-set, define a short to expand more commands (ideally so rich)
unsigned char gender; //1 – man, 2-woman, 3 - ??
char name[8]; //Of course, this can be defined as string name; or len + value combination, for ease of narration, a simple fixed-length data is used.
}
In this way, A does not need encoding; it directly copies from memory and just performs a network byte order conversion on cmd before sending it to B. B can also parse it, and everything is harmonious and pleasant.
The encoding result can be represented graphically (1 square is one byte)
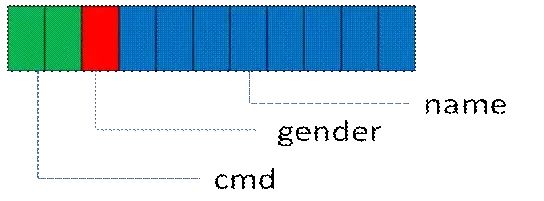
This encoding method, I call it Compact Mode, means that there is no extra redundant information besides the data itself, which can be considered as Raw Data. In the DOS era, this usage was very common, as memory and networks were calculated in K and CPUs had not yet reached 1G. Adding extra information not only consumed precious CPU resources but also strained memory and bandwidth.
2. Expandability
One day, A added a birthday field to the basic information and informed B.
struct userbase
{
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name[8];
}
B was puzzled, as upon receiving A’s data packet, it could not determine whether the third field was the name field from the old protocol or the birthday from the new protocol. After this, A and B finally realized an important characteristic of a protocol—compatibility and expandability.
Thus, A and B decided to discard the old protocol and start anew, establishing a protocol that would be compatible with each version in the future. The method was simple: add a version field.
struct userbase
{
unsigned short version;
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name[8];
}
With this, A and B breathed a sigh of relief, as they could easily expand in the future. Adding fields became very convenient. This method is still used by many people even today.
3. Better Expandability
After a long period, A and B discovered a new problem: changing the version number every time a field was added was not the main issue; the main issue was that maintaining the code became quite troublesome, with each version requiring a case branch. Eventually, the code ended up with dozens of case branches, looking ugly and costly to maintain.
A and B carefully considered and felt that relying solely on a version to maintain the entire protocol was not sufficient. They decided to add an extra piece of information—tag for each field. Although this increases memory and bandwidth usage, it is now acceptable to allow this redundancy for the sake of ease of use.
struct userbase
{
unsigned short version;
unsigned short cmd;
unsigned char gender;
unsigned int birthday;
char name[8];
}
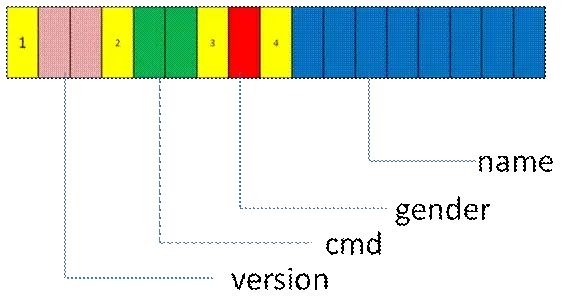
After establishing these protocols, A and B were quite pleased, believing that this protocol was good and allowed for the free addition and removal of fields. They could expand at will.
Reality is often cruel; soon a new requirement arose where the name using 8 bytes was insufficient, and the maximum length might reach 100 bytes. A and B were troubled, as they could not pack the name “steven” using 100 bytes every time, even though they could afford it; it would be a waste.
Thus, A and B searched for information and found the ASN.1 encoding specification, which was a great discovery. ASN.1 is an ISO/ITU-T standard. One of its encoding methods, BER (Basic Encoding Rules), is simple and easy to use, employing a triplet encoding known as TLV encoding.
After encoding, the memory organization of each field is as follows:

Fields can be structures, allowing for nesting:

After A and B used TLV to package the protocol, the data memory organization is approximately as follows:
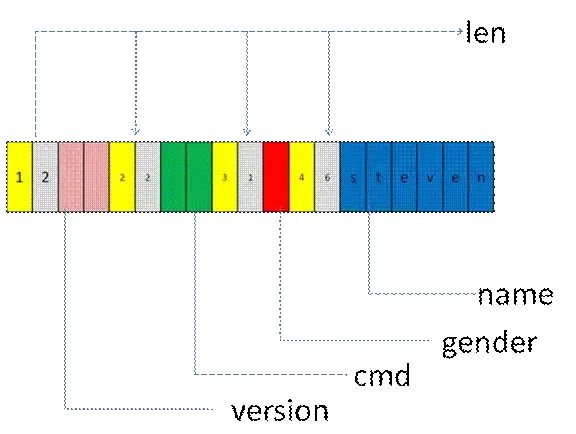
TLV provides excellent expandability and is simple to learn. However, it also has drawbacks, as it adds two extra redundant pieces of information, tag and len, especially when the protocol mainly consists of basic data types like int, short, and byte. This can waste several times the storage space. Furthermore, the specific meaning of Value requires both parties to have a prior description document; thus, TLV lacks structural and self-descriptive characteristics.
Related articles: Detailed Explanation of TLV Format Data
4. Self-Descriptiveness
After A and B adopted the TLV protocol, it seemed that all problems were solved. However, they still felt it was not perfect and decided to add self-descriptive features. This way, when capturing packets, the types of each field could be known without looking at the protocol description document. This improved type is TT[L]V (tag, type, length, value), where L is not needed when the type is a fixed-length basic data type such as int, short, or long, as its length is known.
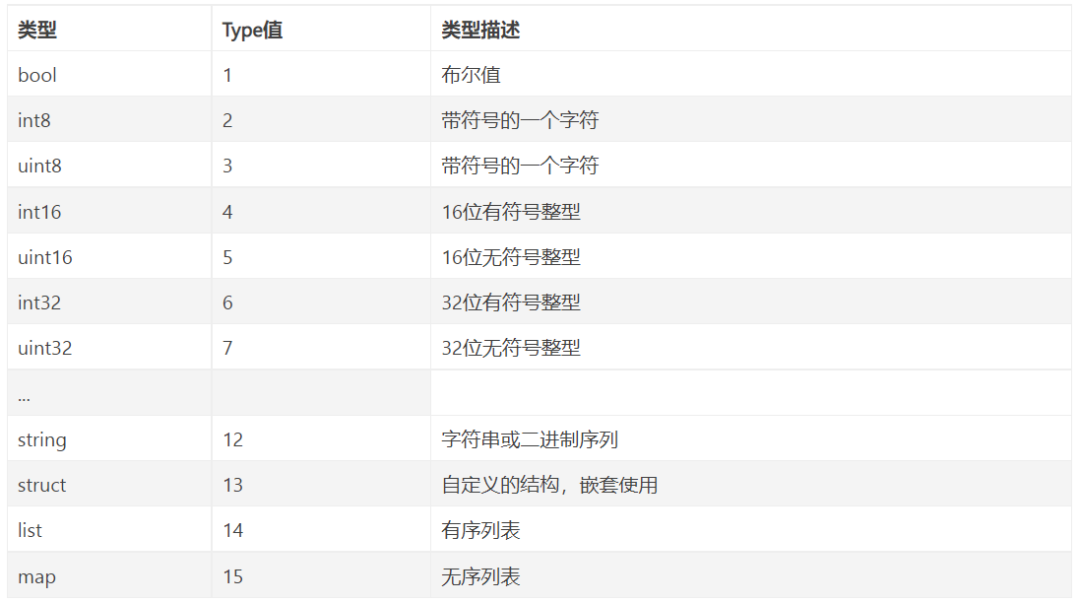
Thus, some type values were defined as follows:
After serialization according to ttlv, the memory organization is as follows:
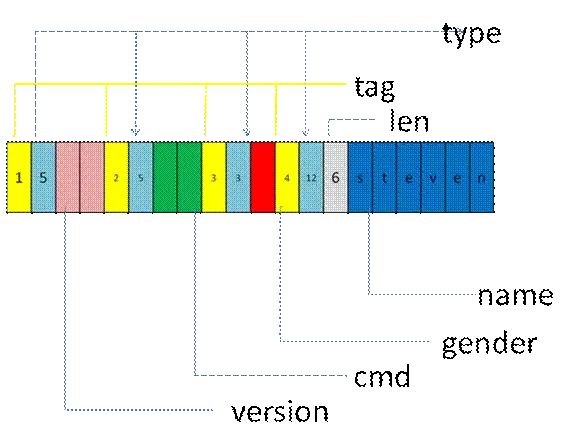
After the modifications, A and B found that it indeed brought many benefits. Not only could they freely add or delete fields, but they could also modify data types, for example, changing cmd to int cmd; they could achieve seamless compatibility. This was truly powerful.
5. Cross-Language Features
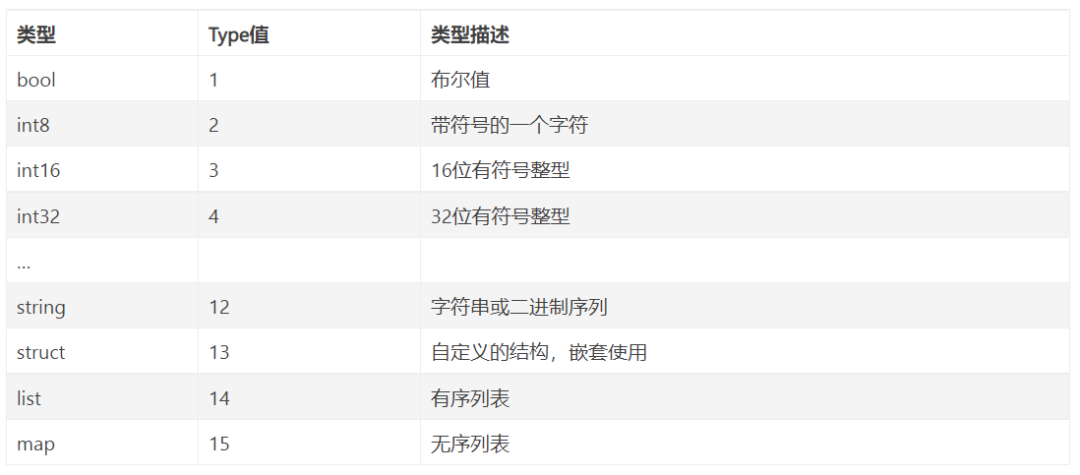
One day, a new colleague C joined, who needed to write a new service that communicated with A. However, C was using Java or PHP, which do not have unsigned types, causing negative number parsing to fail. To solve this issue, A re-planned the protocol types, stripping away some language-specific features and defining some commonalities. Although this brought constraints, it also brought generality, simplicity, and cross-language compatibility, which everyone agreed upon, leading to the establishment of a type specification.
6. Code Automation—The Birth of IDL Language
However, A and B discovered a new annoyance: every time a new protocol was developed, they had to start from scratch to encode and decode, and debug. Although TLV is simple, writing encoding and decoding is a tedious task with no technical content. A very obvious problem is that due to a lot of copy/pasting, it is easy for both newcomers and veterans to make mistakes; once an error occurs, locating and troubleshooting can be very time-consuming. Thus, A thought of using tools to automatically generate code.
IDL (Interface Description Language) is a description language and an intermediate language. One of the missions of IDL is to standardize and constrain, just as mentioned earlier, to standardize type usage and provide cross-language features. By analyzing IDL files through tools, code in various languages can be generated.
Gencpp.exe sample.idl outputs sample.cpp sample.h
Genphp.exe sample.idl outputs sample.php
Genjava.exe sample.idl outputs sample.java
Isn’t it simple and efficient!
7. Conclusion
After reading this, do you feel it is very familiar? Yes, by the end of the protocol discussion, it is actually quite similar to Facebook’s Thrift and Google’s Protocol Buffers. Including the JCE protocol used by the company. Upon examining the IDL files of these protocols, it was found that they are almost identical, with only minor differences.
Related articles: A Lighter Data Format—protobuf
These protocols add certain features in some details:
1. Compression: Here, compression does not refer to general compression like gzip, but rather integer compression. For instance, in many cases, the value of int types is less than 127 (especially the case of value 0), so it does not need to occupy 4 bytes. Therefore, these protocols have made some refinements to use only 1/2/3/4 bytes for int types based on the situation, which is still a type of ttlv protocol.
2. require/option features: This feature serves two purposes: 1. It is still compression. Sometimes a protocol has many fields, and some fields can be included or excluded. When a value is not assigned, it is still necessary to include a default value, which is a waste. If the field has the option feature and is not assigned a value, it does not need to be packed. 2. It has a logical constraint function, specifying which fields must be present, enhancing validation.
Serialization is the foundation of communication protocols, whether in signaling channels, data channels, or RPC, it is essential. Considering expandability and cross-language features early in protocol design can save a lot of trouble later on.
Ps
This article mainly introduces binary communication protocol serialization and does not discuss text protocols. In a certain sense, text protocols inherently possess compatibility and expandability, unlike binary protocols which require consideration of many issues. Text protocols are easy to debug (for instance, visible characters during packet capture, telnet can be used for debugging, and data packets can be manually generated without special tools), and their simplicity and ease of learning are their greatest advantages.
Binary protocols have the advantages of performance and security, but debugging can be troublesome.
Both have their pros and cons, so choose according to your needs. (stevenrao)
Author: stevenrao
Original article: http://blog.chinaunix.net/uid-27105712-id-3266286.html
This article is sourced from the internet, conveying knowledge for free, and the copyright belongs to the original author. If there are any copyright issues, please contact me for deletion.
Previous Recommendations
“Comprehensive Guide to Embedded Linux Drivers”