▍Review: Nvidia’s General-Purpose GPU Takes the Lead, Horizon Seizes the Window for Domestic Substitution
Background: The Evolution of Automotive EE Architecture Towards Centralization Catalyzes the Demand for Intelligent Driving SoC Chips
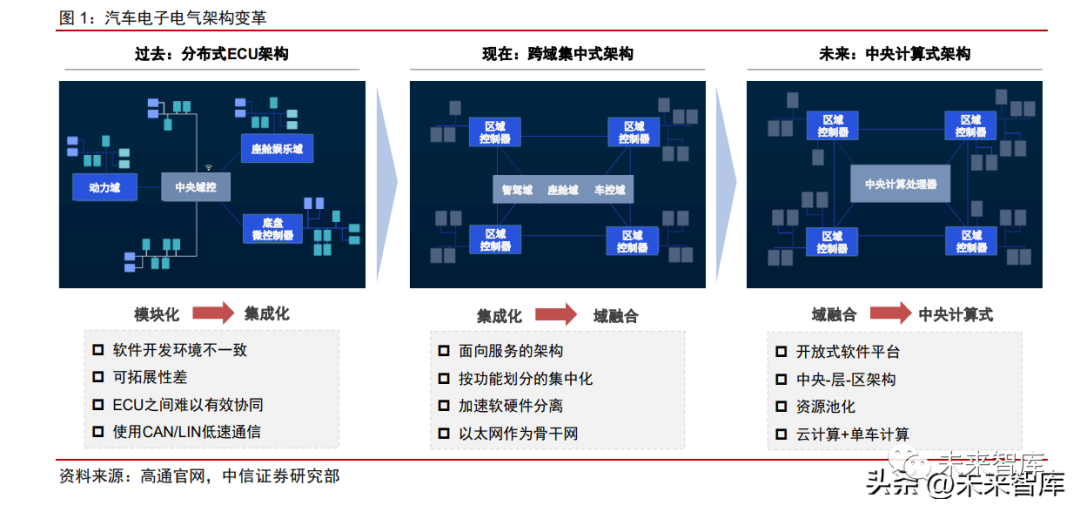
The automotive electronic and electrical (E/E) architecture is transitioning from a distributed to a centralized model, with SoC as the mainstream for autonomous driving chips. As the intelligence, connectivity, and electrification of vehicles deepen, the inefficient traditional distributed architecture can no longer meet upgrade demands. Therefore, the automotive E/E architecture is gradually shifting towards centralization to reduce vehicle wiring harnesses and improve internal information flow efficiency. In a traditional distributed architecture, each functional module of the vehicle operates independently, requiring only MCU chips to meet the computational power needed. However, as the E/E architecture evolves towards centralization, computational power also tends to centralize, making it increasingly difficult to rely solely on traditional MCUs to meet computing needs, thus catalyzing the development of SoC chips. Currently, autonomous driving chips mainly consist of SoC chips composed of CPU, GPU, and NPU AI accelerators, integrated as a computing platform within domain controllers, thereby accelerating the cross-domain integration of intelligent vehicles. Major OEMs will gradually launch models based on the next-generation E/E architecture starting in 2023. Tesla is a leader in the transformation of the EE architecture, having directly leaped from “domain centralized EE architecture” to “central + regional EEA” in defining the Model Y. The 2022 Model Y features a design comprising a Central Computing Module (CCM) + left body control module + right body control module, where the CCM integrates the Advanced Driver Assistance System (ADAS) domain and the cabin entertainment domain. Currently, major traditional OEMs and new forces in China are accelerating their layouts, generally adopting a central computing + regional control architecture scheme in hardware and a Service-Oriented Architecture (SOA) design concept in software.
We summarize the characteristics of various electronic and electrical architectures as follows:
Distributed: Each module has clearly defined functions, with strong coupling between hardware and software. Each module can be developed independently, but cannot share a single SoC, and redundancy is not achievable. The distributed architecture requires a large number of wiring harnesses to support internal communication, increasing harness costs. Moreover, updates for each sub-module require input from various suppliers, resulting in relatively low iteration efficiency.
Cross-Domain Centralized: This approach consolidates dispersed ECUs into chassis, power, cabin, and intelligent driving domains, thereby reducing the wiring costs required for internal communication. In the future, this will gradually simplify into intelligent driving, cabin, and vehicle control domains. Additionally, hardware and software can gradually decouple, offering some flexibility for OTA updates.
Central Computing: This further simplifies the architecture, significantly reducing wiring costs, introducing SOA design for an open software platform, achieving decoupling of hardware and software, and allowing different functional domains to share a central computing platform. In the future, the in-vehicle computing platform is also expected to integrate with cloud computing, realizing vehicle-cloud integration. Moreover, the centralized architecture will truly achieve “cabin and driving integration,” which also raises higher performance, safety levels, and integration requirements for in-vehicle SoC chips.
▍Landscape: Industry Landscape Undetermined, Nvidia Leads the Mid-to-High-End Market, Horizon Emerges Strongly
Autonomous driving chips have undergone a decade of development, with significant changes in the domestic landscape. We review its historical development and landscape changes, which can be divided into two phases from 2014 to the present:
2014-2018: Players mainly included Mobileye, Nvidia, and traditional MCU manufacturers, with autonomous driving functions still in the early stages and relatively few entrants in the industry. During this phase, vehicles still primarily used a distributed E/E architecture, with autonomous driving function levels ranging from L0 to L2. Smart front-view integrated machines could meet driving needs without high chip computational power. Mobileye has long focused on visual ADAS, self-developing a “visual algorithm + chip” integrated hardware and software solution, capturing the L1-L2 visual ADAS chip market with its EyeQ3/Q4, experiencing rapid revenue growth. Meanwhile, traditional MCU manufacturers like Renesas and TI, used in Bosch’s solutions, also held significant market shares. Nvidia launched the Tegra Parker SoC in 2016 based on a general-purpose GPU architecture, integrating it into Tesla’s HW2.0 platform, officially pushing the GPU route for autonomous driving SoCs into the market, but the iteration of autonomous driving SoC technology during this phase remained relatively slow.
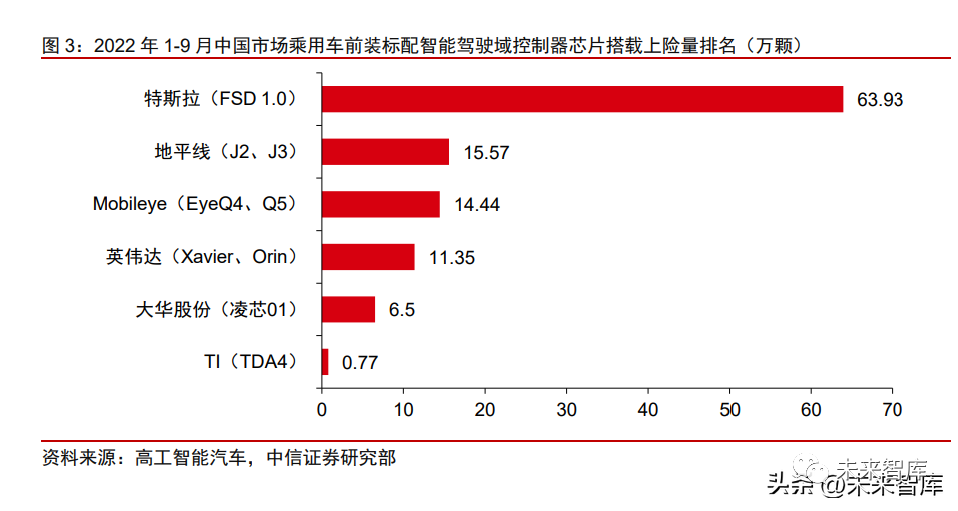
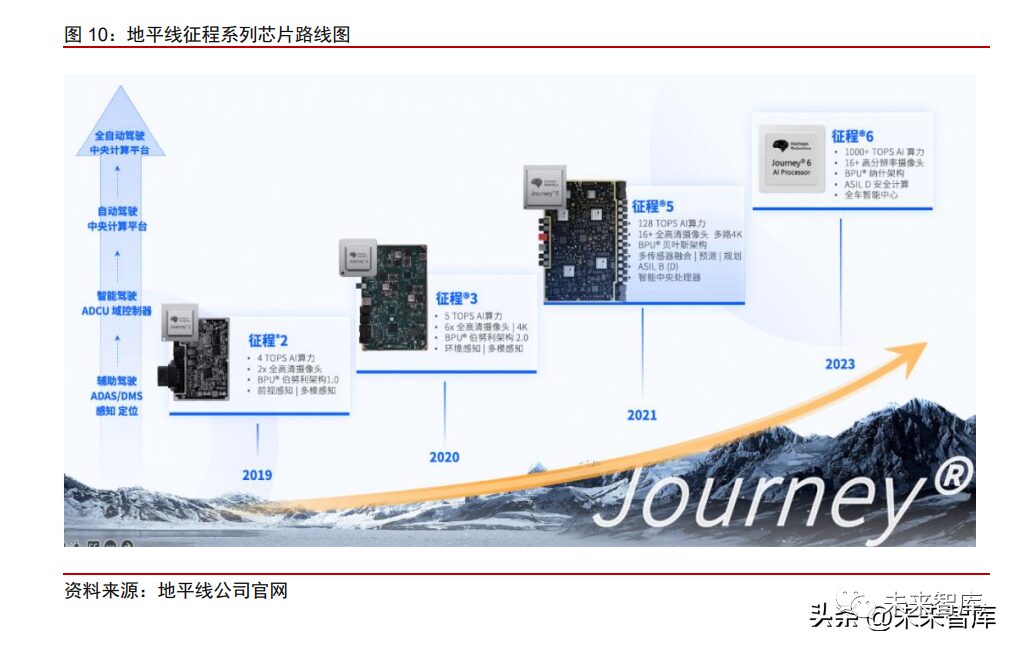
2019-2022: The industry accelerated its development, with Nvidia leading the high-computational power market while Horizon seized the window for domestic substitution. In 2019, Tesla’s first self-developed FSD chip was successful, prompting automakers to focus on building integrated hardware and software autonomous driving capabilities, marking the beginning of rapid development in the autonomous driving chip industry. In the low computational power (below 30 TOPS) market, Horizon seized the opportunity for domestic substitution, gradually capturing market share from Mobileye. In 2019, Horizon released the J2 chip (4 TOPS) ahead of schedule, achieving mass production in 2020, which was used in Changan’s main model UNI-T. In 2021, the automotive industry’s shortage of chips led to reduced vehicle production, prompting domestic automakers to prioritize the cultivation of domestic chip suppliers. Horizon achieved mass production of the J3 chip (5 TOPS) that year, thereby gaining a first-mover advantage in the autonomous driving field and gradually eroding Mobileye’s market share in China with a more open ecosystem. According to data from Gaogong Intelligent Automotive (WeChat public account, unless otherwise specified), from January to September 2022, Horizon’s shipment of intelligent driving domain controller chips for passenger vehicles in the Chinese market had risen to second place, only behind Tesla, while Mobileye dropped to third. Besides Horizon and Mobileye, chip manufacturers like TI, Xilinx, and Renesas also hold a place in the market.
In the mid-to-high computational power (30 TOPS and above) market, Nvidia took the lead based on its advanced GPU architecture, while Horizon is expected to bring domestic substitution efforts into the mid-to-high-end market. In 2020, Nvidia released the Xavier chip (30 TOPS) targeting the L2 market, which was integrated into models like Xiaopeng P7/P5; in 2022, it launched the high-computational Orin chip (256 TOPS), once again leading the industry and occupying the mainstream mid-to-high-end model market, becoming the choice for all models targeting L2+ high-level assisted driving. Meanwhile, Horizon launched the J5 chip (128 TOPS) in 2022, hoping to compete with Nvidia on a level playing field with higher cost-performance and better localized service. Additionally, many players like Qualcomm, Black Sesame, and Huizhi Intelligent are expected to officially join the competition for mid-to-high computational power chips in the coming years.
▍Outlook: Demand for Low-Power Chips Remains Strong, High-Power Chips Move Towards New Architectures
In the short to medium term, automakers’ intelligent strategies may diverge due to product pricing, leading to different computational power demands.
In the short to medium term, with the onset of price wars this year, the previous trend of piling up hardware will come to an end, and practicality and cost-effectiveness will be key to survival in the final round. Therefore, automakers’ intelligent strategies may diverge due to product pricing:
1) Models priced at 100,000-200,000 yuan: Pursuing high cost-performance intelligent driving solutions, with computational power demands ranging from 5-30 TOPS. The price cuts by Tesla have significantly increased cost pressure on domestic automakers, accelerating industry reshuffling. We believe that under cost pressure, low-end models priced at 100,000-200,000 yuan will tend to pursue high cost-performance intelligent driving solutions, mainly maintaining traditional L2 functions in the short to medium term. Some models may provide basic highway navigation functions, with computational power demands in the range of 5-30 TOPS. Traditional L2 functions typically require around 10 TOPS to meet their needs. However, as a representative function of L2+, highway navigation also tends to require lower computational configurations. Although there may be some shortcomings in safety redundancy and experience smoothness, it can still meet the basic functional needs. However, the industry generally believes that for highway navigation to be “user-friendly,” providing higher redundancy and a smoother driving experience will still require higher computational support, with mid-range computational chips of 30-60 TOPS being more suitable.
2) Models priced at 200,000-300,000 yuan: Highway navigation is gradually becoming standard, and under cost-cutting pressure, automakers are rationalizing hardware configurations, estimating computational power demands at 30-80 TOPS. Models in this price range face direct competition from Tesla Model 3/Y, with cost pressure being particularly evident. At the same time, they require a certain level of intelligence to create differentiation. We believe that highway navigation is likely to gradually become standard in models within this price range, and compared to low-end models, they can provide a better riding experience with relatively higher hardware configurations. However, under cost-cutting pressure, automakers will also become more rational and will no longer simply pile up hardware and computational power, so the estimated computational power configuration will generally rise to 30-80 TOPS, making mid-range computational chips likely to become mainstream choices.
3) Models priced above 300,000 yuan: Pursuing a better intelligent experience, chips are moving towards high computational power & new architectures. We believe that high-end models priced above 300,000 yuan are relatively less affected by price wars, with OEMs striving to create benchmark intelligent labels, likely to continue focusing on urban navigation. Current computational power configurations generally exceed 200 TOPS. To achieve better effects and improved navigation functions, “BEV + Transformer” is beginning to lead the autonomous driving perception paradigm; in the long term, “cabin-driving integration” is also expected to become the ultimate evolution of intelligent automotive E/E architecture. Driven by the above two technological trends, autonomous driving chips are moving towards high computational power & new architectures.
Low-Power Chips: Mass Production Delivery, Safety Stability, and Cost-Effectiveness are Key, Horizon and TI’s Leading Position is Relatively Stable
In the short to medium term, low-power chips are expected to enter a mass production phase alongside the rapid growth of L1-L2 functions. We believe that automakers will prefer chip manufacturers with rich mass production experience, strong delivery capabilities, high safety stability, and outstanding cost-effectiveness. Horizon and TI’s current leading positions are relatively stable, but new players continue to enter the market. In the past, assisted driving mainly focused on basic L0-L2 functions, achievable through smart front-view integrated machines, mainly using solutions from Mobileye, Bosch, Continental, and Xilinx. As the penetration of lightweight driving and parking integration and basic highway navigation functions increases, we believe that integrated SoC chips for low-power domain control platforms will become mainstream. Due to the lower technical barriers and architectural difficulties of low-power chips compared to mid-to-high power, we believe that manufacturers’ mass production delivery capabilities, safety stability, and cost-effectiveness will become the focus of automakers.
Horizon, with its first-mover advantage, ecosystem establishment, and localized service, is likely to continue leading the domestic low-power chip market; TI’s TDA4VM has significant advantages in functional completeness and automotive-grade reliability, achieving one of the few single SoC driving and parking integration solutions in low-power chips, and is expected to maintain high competitiveness.
Mobileye, due to its black box solution, finds it difficult to meet the development needs of driving and parking integration, and is likely to mainly target L1-L2 demands in the future, embedding mature perception algorithms into chips for sale, which is more friendly to automakers with weaker self-development capabilities. Additionally, manufacturers represented by Chipway, Cambricon, and Aisin Yuan Zhi, which have previously accumulated rich mass production experience in other application scenarios, may also have opportunities to enter the intelligent driving chip market, posing competitive pressure to Horizon and TI.
Horizon: J2/J3 has taken the lead in the low-power chip market, possessing first-mover advantages and is expected to benefit from the wave of domestic substitution, leading the domestic low-power chip market. Seizing the time window for domestic substitution, Horizon has a first-mover advantage and leading localized service capabilities. The Horizon J2/J3 chips respectively possess 4/5 TOPS of computational power, targeting the ADAS market where Mobileye operates, and compared to Mobileye’s EyeQ4, they offer higher computational power and openness. Therefore, leveraging chip product strength, a relatively complete toolchain, and localized service capabilities, they have quickly gained favor among many domestic automakers with software algorithm self-development needs in the context of supply chain security and controllability.
TI: TDA4VM excels in architectural completeness and functional safety, likely becoming one of the mainstream choices for lightweight driving and parking integration solutions in the 100,000-200,000 yuan models. TDA4VM has a computational power higher than J3 and EyeQ4, achieving a single SoC lightweight driving and parking integration solution. TI launched its core product TDA4VM in 2020, with a computational power of 8 TOPS, exceeding Horizon’s J3 (5 TOPS) and Mobileye’s EyeQ4 (2.5 TOPS), and stable supply. Currently, players like DJI, MAXIEYE, Nullmax, Hedo Technology, and Zongmu Technology are developing driving and parking integration solutions based on TDA4.
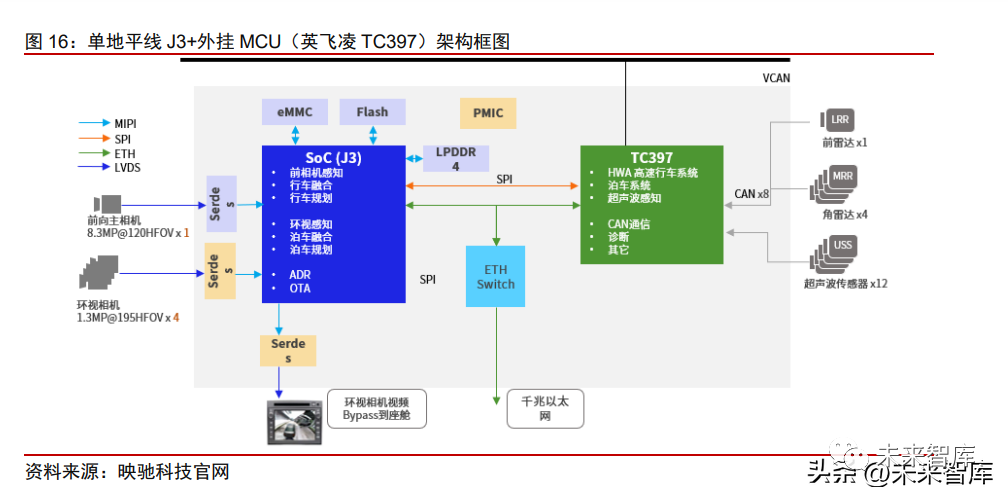
With a complete architecture and high integration, TDA4 is beneficial for automakers and solution providers to conduct secondary development. TDA4 adopts a multi-core heterogeneous architecture, integrating ARM CPU, digital signal processors (DSP), deep learning accelerators (DLA), MCU, and other units, with corresponding cores or accelerators processing different tasks such as logical computation and AI computation. TI’s AI computational power comes from its self-developed matrix multiplication accelerator MMA (comparable to Horizon’s BPU), capable of providing flexible matrix multiplication operations. Its versatility lies between GPU and ASIC, thus possessing stronger scalability and parallel processing capabilities. Notably, TDA4 is one of the few intelligent driving SoCs with an integrated ASIL-D level MCU. As most intelligent driving SoCs cannot meet high functional safety level requirements, a common practice is to externally connect a standalone MCU chip, such as Infineon’s TC297/397, to provide state monitoring, vehicle chassis control, and execute minimal safety risk strategies. To simplify system design, reduce communication delays, and save hardware costs, some chip manufacturers have started integrating MCU cores (Safety Island) within SoCs. TI’s TDA4 series is a typical representative with an integrated MCU, which is an ASIL-D level Arm Cortex-R5F, designed with separate voltage and clock, using dedicated memory and interfaces to ensure isolation from the rest of the SoC. Therefore, automakers do not need to connect an external MCU for development. Despite the trend of integrating MCUs, the functional safety, real-time performance, and reliability of internal safety islands still lag behind traditional external MCUs in practical applications. Therefore, domain control manufacturers often choose to attach an external MCU for safety redundancy when using chips like Horizon’s J3 or Black Sesame’s A1000.
However, TI’s relative disadvantage lies in the fact that due to the integration of numerous processing units like GPUs, MMA, and DSPs, TDA4VM can consume power as high as 20W under high loads, posing high engineering requirements for Tier 1 and OEMs in terms of heat dissipation. Additionally, compared to pure ASIC routes, TI’s computational efficiency on specific algorithms may not match that of Horizon.
Mobileye: The traditional visual ADAS leader is experiencing rapid erosion of market share due to its black box model and slow iteration. However, its “visual algorithm + chip” integrated front-view machine solution offers high cost performance, and it may mainly target L1-L2 demands in the future, being more friendly to automakers with weaker self-development capabilities. Due to its black box model and slow iteration, its market share is rapidly being eroded. Mobileye was once a major pioneer and leader in the ADAS field, providing an integrated hardware and software solution composed of algorithms and the EyeQ series chips. With the help of Mobileye’s solutions, automakers can efficiently and cost-effectively adapt to L1-L2 level basic assisted driving functions. However, as the intelligence level of vehicles increases, automakers are beginning to hope for greater control and autonomy over their intelligent solutions, and Mobileye’s full-stack black box model can no longer meet the self-development needs of most automakers. Furthermore, unlike mainstream CPU architectures (ARM, X86), Mobileye’s EyeQ4 chip uses multiple MIPS processors, resulting in poor versatility and developability, making it difficult to form a good software ecosystem. Therefore, in recent years, the attractiveness of Mobileye’s intelligent integrated machine solutions has begun to decline. In response to the crisis, it is actively seeking change and gradually opening up its ecosystem, but the competitive landscape is far more intense than before. In 2021, Mobileye launched the EyeQ5 chip, which for the first time provided a single chip (silicon-only) version, opening the SDK, OpenCL environment, and TensorFlow, thereby allowing customers to deploy self-developed algorithms. However, the EyeQ5 chip has only attracted the attention of Zeekr thus far. The competitive environment for autonomous driving chips is becoming increasingly fierce, with numerous domestic and international automakers migrating their platforms from Mobileye’s EyeQ series to Nvidia, Horizon, Huawei, Qualcomm, and other players. We believe that Mobileye’s “visual algorithm + chip” integrated front-view machine solution still possesses high cost-performance advantages and is more friendly to automakers with weaker self-development capabilities. However, as automotive intelligence capabilities gradually improve, whether Mobileye can keep up with the rapidly iterating demands of OEMs and further open its ecosystem will be the key to not falling behind.
Black Sesame: Based on the A1000L for driving and parking integration solutions, it has secured the next-generation FEEA3.0 architecture model from FAW Hongqi, but the relevant model plans are set for SOP in 2024, which is relatively behind Horizon and TI in terms of timing. The company launched the A1000L chip back in 2020, featuring an 8-core ARM Cortex A55 CPU, ARM GPU, 3 high-performance DSPs, a CV acceleration engine, and its self-developed DynamAINN engine, achieving AI computational power of 16 TOPS, with industry-leading functional integrity and computational performance. The Drive Sensing solution based on the A1000L chip can achieve a single SoC chip driving and parking integration solution, supporting L2+ highway navigation NOA, parking HPA/AVP, 3D 360-degree panoramic views, and multi-channel DVR functions. In May 2023, the company announced that the A1000L had secured the production of intelligent driving chips for the next-generation FEEA3.0 electronic architecture platform project from FAW Hongqi. FAW Hongqi will develop a non-time-sharing driving and parking integrated autonomous driving domain control platform based on the A1000L, which will be applied to about 80% of FAW Hongqi’s models, with the E001 and E202 models expected to be mass-produced as early as 2024. The core competitive advantage comes from two self-developed IPs: the image signal processing ISP and the neural network accelerator NPU. The ISP is responsible for “seeing clearly” and can process every frame of raw image data collected by the camera, while the NPU is responsible for “understanding” and integrates multiple functions such as image classification, spatial segmentation, and specific target analysis into a single neural network, enabling structured cropping, thus enhancing the neural network’s computational capabilities and reducing power consumption.
 Aisin Yuan Zhi: Having accumulated rich delivery experience and a complete toolchain in the smart city field, it is expected to leverage this to enter the low-power intelligent driving chip market. Aisin Yuan Zhi was established in 2019 and has successfully launched two generations of four edge-side AI visual perception chips, achieving large-scale mass production supply. Currently, Aisin Yuan Zhi’s main downstream business is smart city, with Dahua Technology, a leading solution provider for smart IoT, being one of its important clients. The self-developed chips AX630A and AX620A have been applied as main control SoCs in multiple product lines of Dahua Technology and have been rated as Dahua Technology’s strategic supplier in 2021. Based on its own ISP and NPU joint architecture design, Aisin Yuan Zhi can significantly enhance the performance of multiple key modules in traditional ISPs, achieving high energy efficiency and high computational power utilization. Currently, the company is also starting to venture into the intelligent driving field, having participated in the investment of ADAS solution provider MAXIEYE in August 2022, and the two may collaborate on vehicle integration in the future. We believe that Aisin Yuan Zhi’s mass production experience in the smart city field and the established toolchain can empower its intelligent driving business, especially in the low-power chip market, where automakers will place more emphasis on suppliers’ delivery capabilities and product ease of development. From 2019 to 2022, Aisin Yuan Zhi completed nearly 2 billion yuan in financing, with investors including major internet giants like Meituan, Meituan Longzhong Capital, Tencent Investment, and Lenovo Star, as well as well-known institutions like Qiming Venture Partners, GGV Capital, and Yaotu Capital.
Chipway: Cabin chips benchmark against Qualcomm, and rich mass production experience and partnerships with automakers are expected to assist in the adaptation of intelligent driving chips, but rational allocation of internal resources across different product lines is key. Chipway was established in 2018, as one of the few “full-scenario, platform-based” chip and technology solution providers in China, with products including domain control chips E3, cabin chips X9, intelligent driving chips V9, and gateway chips G9. Currently, apart from intelligent driving chips, the other three chips have achieved large-scale mass production. Especially in the intelligent cabin chip field, the company’s X9 series cabin chips can match Qualcomm in performance. We believe that Chipway’s mass production delivery experience and industry chain ecosystem construction in cabin chips will assist the penetration of its intelligent driving chips, but the product architecture and software algorithms of cabin chips and intelligent driving chips still differ significantly. Even Qualcomm’s current progress in the intelligent driving field has not been as expected, and as a startup, whether it can rationally allocate limited resources across different products remains to be seen.
Aisin Yuan Zhi: Having accumulated rich delivery experience and a complete toolchain in the smart city field, it is expected to leverage this to enter the low-power intelligent driving chip market. Aisin Yuan Zhi was established in 2019 and has successfully launched two generations of four edge-side AI visual perception chips, achieving large-scale mass production supply. Currently, Aisin Yuan Zhi’s main downstream business is smart city, with Dahua Technology, a leading solution provider for smart IoT, being one of its important clients. The self-developed chips AX630A and AX620A have been applied as main control SoCs in multiple product lines of Dahua Technology and have been rated as Dahua Technology’s strategic supplier in 2021. Based on its own ISP and NPU joint architecture design, Aisin Yuan Zhi can significantly enhance the performance of multiple key modules in traditional ISPs, achieving high energy efficiency and high computational power utilization. Currently, the company is also starting to venture into the intelligent driving field, having participated in the investment of ADAS solution provider MAXIEYE in August 2022, and the two may collaborate on vehicle integration in the future. We believe that Aisin Yuan Zhi’s mass production experience in the smart city field and the established toolchain can empower its intelligent driving business, especially in the low-power chip market, where automakers will place more emphasis on suppliers’ delivery capabilities and product ease of development. From 2019 to 2022, Aisin Yuan Zhi completed nearly 2 billion yuan in financing, with investors including major internet giants like Meituan, Meituan Longzhong Capital, Tencent Investment, and Lenovo Star, as well as well-known institutions like Qiming Venture Partners, GGV Capital, and Yaotu Capital.
Chipway: Cabin chips benchmark against Qualcomm, and rich mass production experience and partnerships with automakers are expected to assist in the adaptation of intelligent driving chips, but rational allocation of internal resources across different product lines is key. Chipway was established in 2018, as one of the few “full-scenario, platform-based” chip and technology solution providers in China, with products including domain control chips E3, cabin chips X9, intelligent driving chips V9, and gateway chips G9. Currently, apart from intelligent driving chips, the other three chips have achieved large-scale mass production. Especially in the intelligent cabin chip field, the company’s X9 series cabin chips can match Qualcomm in performance. We believe that Chipway’s mass production delivery experience and industry chain ecosystem construction in cabin chips will assist the penetration of its intelligent driving chips, but the product architecture and software algorithms of cabin chips and intelligent driving chips still differ significantly. Even Qualcomm’s current progress in the intelligent driving field has not been as expected, and as a startup, whether it can rationally allocate limited resources across different products remains to be seen.
Cambricon Xingge: The parent company Cambricon’s rich AI chip technology accumulation is expected to migrate to vehicle terminals, with a unified eco-architecture integrating cloud, edge, and vehicle, helping to build a closed loop of inference at the vehicle end and training at the cloud end. Cambricon Xingge was established in 2021 as a subsidiary of Cambricon Holdings, focusing on the research and development of autonomous driving chips. Currently, it is developing several intelligent driving chips covering L2-L4: 1) The SD5223 chip, which is nearing mass production, targets L2+ driving and parking integration solutions, with high energy efficiency, doubling the computational power compared to TDA4VM (16 TOPS). 2) Based on SD5223, Cambricon launched the low-power low-consumption SD5223C, with a computational power of 6 TOPS, supporting 8M front-view integrated machines and automatic parking functions, potentially penetrating the front-view integrated machine market previously occupied by Mobileye. 3) The company also stated that it will launch the SD5226 chip aimed at the L4 market in the future, planning for computational power exceeding 400 TOPS, 300K+ DMIPS, using a 7nm process, and supporting vehicle-side training. However, it should be noted that the company’s chip foundry may be affected by geopolitical factors, impacting actual mass production timelines. Since its establishment, Cambricon Xingge has signed autonomous driving cooperation agreements with companies like Jingwei Hengrun and FAW and has received significant backing from major industry capital such as SAIC, NIO, and CATL.
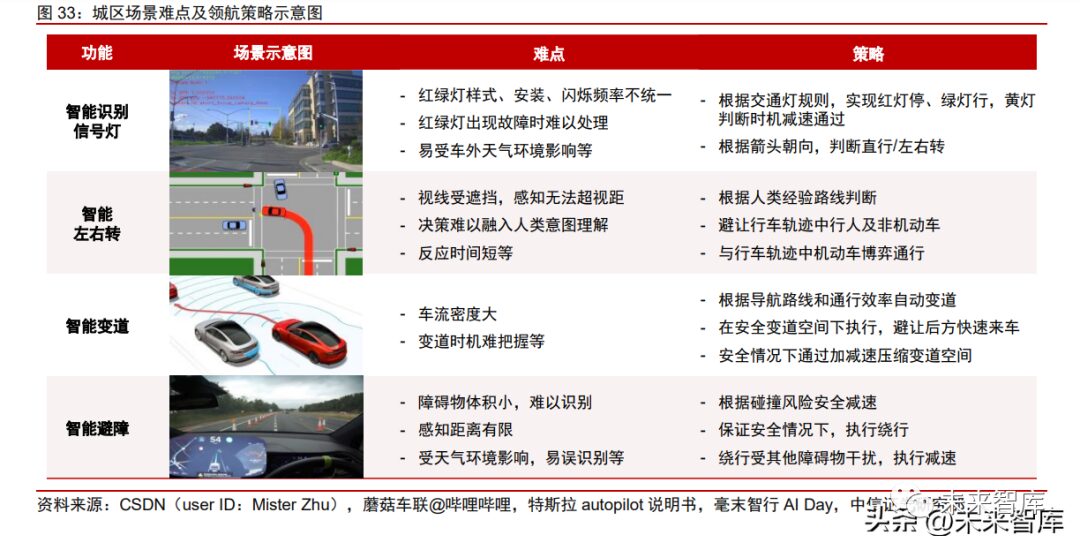
Mid-Range Computational Power Chips: Highway Navigation Brings Development Opportunities, All Players Have the Potential to Break Through
The mid-range computational power chip (30-100 TOPS) market was previously relatively empty, primarily dominated by Nvidia’s Xavier. However, as automakers become more rational, mid-range models are no longer simply participating in the arms race for high computational power chips, while also hoping to achieve optimal highway navigation functions, leading to an increase in demand for mid-range computational power chips. Currently, Nvidia’s Xavier, Orin NX/Nano, TI TDA4VH, and Black Sesame A1000 have targeted this market and are beginning to make moves, but it cannot be ruled out that other manufacturers like Horizon may also introduce corresponding products in the future to complete their product matrix. Therefore, overall, we believe that the competition in the mid-range computational power chip market is just beginning. Compared to low and high computational power, the mid-range market may require higher comprehensive capabilities from chip manufacturers, and existing players all have the potential to break through.
Nvidia: Xavier and Orin NX are expected to occupy a large share of the mid-range computational power market. In 2020, Nvidia released the Xavier chip (30 TOPS) targeting the L2 market, which was integrated into models like Xiaopeng P7/P5; in 2022, it launched the high-computational Orin chip (256 TOPS), once again leading the industry and occupying the mainstream mid-to-high-end model market, becoming the choice for all models targeting L2+ high-level assisted driving. However, as the industry returns to rationality, the Orin configuration may be too high for most mid-range models priced at 200,000-300,000 yuan. Therefore, Nvidia has been gradually introducing Orin NX (70/100 TOPS) and Orin Nano (20/40 TOPS) to complete its product matrix. Given that Orin X has already been successfully integrated into many models and verified for mass production reliability, we believe that the lower configurations of Orin NX and Nano series are also likely to share the same Nvidia development toolchain and ecosystem, penetrating the mainstream mid-range model market.

Black Sesame: The A1000 chip with a computational power of 58 TOPS precisely fills the gap in the 50-100 TOPS chip market, and we expect it to be integrated into models like JAC’s Sihao and Lynk & Co 08 in 2023. In terms of GPU, the A1000 comes with an integrated GPU, capable of performing panoramic algorithms for parking scenarios, thus supporting a single chip driving and parking integration solution, while Horizon’s J5 requires an external GPU for 3D rendering. In terms of CPU, the A1000 is equipped with an octa-core ARM Cortex A55, featuring multi-level cache, which can adapt to a large volume of data preprocessing tasks. In terms of CV acceleration, the A1000 includes a 5-core DSP chip, of which 4 cores can be called by customers, thus providing more CPU resources to customers, compared to the J5, which only includes a dual-core DSP. Since many algorithm designs require substantial CPU performance scheduling, the A1000 may be more beneficial for customers to develop and deploy algorithms flexibly. Thanks to its high functional integrity, the A1000’s driving and parking integration and other solutions offer high cost performance. The company announced in April 2023 that it will launch a driving and parking domain control solution with a BOM cost below 3000 yuan, supporting 10V configurations and physical computational power of 50-100 TOPS.
TI: The TDA4 series is advancing towards mid-range computational power to complete its product matrix, having reached cooperation with mainstream Tier 1 suppliers. Previously, many Tier 1 suppliers successfully developed domain controllers for L2 scenarios based on TDA4VM, which has become one of the mainstream choices for single SoC lightweight driving and parking integration solutions. Due to its relatively limited computational power (8 TOPS), TDA4VM achieves a “time-sharing” driving and parking integration solution, with sensor configurations of 5V5R or 6V5R. In contrast, a single TDA4VH (32 TOPS) or TDA4VM Plus (24 TOPS) can achieve a non-time-sharing driving and parking integration solution, supporting higher-order sensor configurations like 10V5R, helping TI further penetrate the L2+ market. We believe that due to TDA4VM’s success in the low-power market, TI has accumulated rich mass production experience, and automakers can use the same toolchain to achieve lower migration and development costs, thus giving TI a certain advantage in the mid-range computational power market. Currently, companies like Desay SV, Furey Tech, and Baidu have announced plans to develop domain controllers based on TI’s mid-range SoCs, with Furey Tech’s ADC30 domain controller based on two TDA4VH and three Horizon J5 chips, expecting mass production in 2023.
High Computational Power Chips: BEV/Transformer + Cabin-Driving Integration Drive Chips Towards High Computational Power & New Architectures
Under the impetus of the two technological trends of “BEV + Transformer” and “cabin-driving integration,” autonomous driving chips are beginning to move towards high computational power & new architectures. Currently, Nvidia and Qualcomm are at the forefront of the transformation, with Horizon leading the mass production progress in the domestic market, while Huawei’s MDC may be making a comeback, and domestic manufacturers like Huizhi Intelligent also have opportunities to break through under changing architectures.
Trend 1: Urban Navigation Begins to Roll Out This Year, “BEV + Transformer” Leads the Autonomous Driving Perception Paradigm. In this trend, the complexity of algorithms, data scale, and model parameters are all increasing exponentially, thus imposing higher requirements on the AI computational power, data throughput, and architectural innovation of in-vehicle autonomous driving chips.
Xiaopeng and Huawei lead the way, with urban navigation beginning to land this year. Currently, urban navigation is still in the early stages of development, with Xiaopeng and Huawei’s solutions having begun rolling out in September 2022 and gradually expanding their open areas. Xiaopeng’s urban NGP (Navigation Guided Pilot) function was piloted in Guangzhou in September 2022 and fully rolled out in October 2022; on March 17, 2023, Xiaopeng announced that the urban NGP function was opened to the Shenzhen area, later expanding to Shanghai. BAIC’s Arcfox and Changan Avita have both chosen the HI (Huawei Inside) model, relying on Huawei’s full-stack high-level autonomous driving solution to create urban NCA functions, respectively named α-Pilot Advanced Intelligent Driving Assistance and AVATRANS Intelligent Navigation System. The Arcfox urban NCA has been opened in Shenzhen, Shanghai, and Guangzhou, covering the Arcfox Alpha S new HI version. Avita also announced on March 9, 2023, that it would begin test driving the urban NCA (Navigation Cruise Assist) in Shanghai and Shenzhen, covering the Avita 11 model, with experiences in Guangzhou and Chongqing soon to follow. Additionally, according to announcements from various companies, Li Auto, Jidu, and Great Wall are also planning to launch their urban navigation functions in 2023.
Urban navigation is seen as the ultimate expression of L4 autonomous driving capabilities in passenger cars, with implementation difficulties and barriers far exceeding those of highway navigation. Current computational power demands generally exceed 200 TOPS. Although 95% of the underlying architecture and foundational issues of autonomous driving have been solved at the system training level, the remaining 5%, which are corner cases, represent the biggest bottleneck restricting the realization of fully autonomous driving. Compared to highway navigation, which has relatively regular scenarios and single working conditions, urban navigation involves many intersections, lane changes, and congested situations, significantly increasing the number and complexity of corner cases, which involve various subjects such as different types of vehicles, pedestrians, and obstacles, as well as irregular driving phenomena such as cutting in and sudden stops by the vehicle in front. According to Xiaopeng’s introduction during the 2022 1024 Technology Day, the code volume for urban NGP is six times that of highway NGP, the data for perception models is four times that of highway NGP, and the code related to prediction/planning/control is 88 times that of highway NGP.
Urban navigation poses higher requirements for autonomous driving perception algorithms, and the “BEV + Transformer” paradigm is being introduced. Large models are one of the hottest frontiers in the current AI field, capable of empowering multiple core aspects of autonomous driving such as perception, labeling, and simulation training. In the perception layer, led by Tesla, the “BEV + Transformer” paradigm has begun to be widely used in the autonomous driving field, effectively enhancing perception accuracy and facilitating the implementation of subsequent planning and control algorithms, promoting the development of end-to-end autonomous driving frameworks.
BEV stands for Bird’s Eye View, an algorithm aimed at projecting the image information collected by multiple sensors into a unified 3D space, which is then input into a single large model for overall reasoning. Compared to traditional camera images, BEV provides a unified space closer to the actual physical world, facilitating the subsequent development of multi-sensor fusion and planning control modules. Specifically, the advantages of BEV perception include:
1) Unified the multi-modal data processing dimensions, converting data from multiple cameras or radars to a 3D perspective for tasks such as object detection and segmentation, thereby reducing perception errors and providing richer outputs for downstream prediction and planning control modules;
2) Implemented temporal information fusion, where the 3D perspective under BEV effectively reduces scale and occlusion issues compared to 2D information, even allowing for the “imagination” of occluded objects using prior knowledge, effectively improving the safety of autonomous driving;
3) Perception and prediction can be implemented in a unified 3D space, allowing for end-to-end optimization through neural networks, effectively reducing the error accumulation in traditional perception tasks where perception and prediction are performed serially.
The attention mechanism of the Transformer can help achieve the conversion of 2D image data to 3D BEV space. The Transformer is a neural network model proposed by the Google Brain team in 2017, initially used for machine translation, and has since evolved into the field of image vision, successfully addressing classification, detection, and segmentation of images. According to the WeChat public account of Auto Heart, the principle of traditional CNN models involves constructing generalized filters through convolutional layers to continuously select and compress elements in images, hence the receptive field to some extent depends on the size of the filters and the number of convolutional layers. As the amount of training data increases, the gains of CNN models tend to exhibit saturation. The Transformer’s network structure, when grafting 2D images and 3D spaces, draws on the attention mechanism of the human brain, allowing it to select only key information for processing when handling large amounts of information, thus enhancing the efficiency of neural networks. Therefore, the saturation interval for Transformers is much larger, making it more suitable for large-scale data training needs. In the autonomous driving field, Transformers possess stronger sequence modeling capabilities and global information perception capabilities compared to traditional CNNs, and are currently widely used for the conversion of visual 2D image data to 3D space.
Under the trends of “BEV + Transformer,” the complexity of algorithms, data scales, and model parameters are all increasing exponentially, pushing autonomous driving chips towards high computational power, new architectures, and storage-computation integration.
1) High Computational Power: Progressing towards hundreds of TOPS in computational power. The data volume and algorithm models required for traditional L1/L2 assisted driving are small and relatively simple, therefore a single-camera vision + chip algorithm strongly coupled integrated machine solution represented by Mobileye can meet the demand. However, as a representative of high-level assisted driving, navigation functions require “stronger computational power + decoupled hardware and software chips + domain controllers” to meet the needs for massive data processing and subsequent continuous OTA iterations. Highway navigation is beginning to penetrate models priced under 200,000 yuan, with 15-30 TOPS meeting basic requirements, but for it to be “user-friendly,” 30-80 TOPS may be needed. The complexity of urban navigation scenes and the technical challenges of implementation are higher, generally requiring LIDAR, with chips like Nvidia’s Orin, Huawei’s MDC, and Horizon’s J5 being the primary options, with computational power configurations generally exceeding 200 TOPS. With the application of the “BEV + Transformer” technology, the pre-fusion of multi-sensors and the conversion from 2D to 3D space require AI chips to possess stronger reasoning capabilities, thus requiring more substantial computational support, including higher AI computational power, CPU computational power, and GPU computational power.
2) New Architectures: Enhancing parallel computing capabilities and floating-point operation capabilities. Compared to CNN/RNN, Transformer possesses stronger parallel computing capabilities, allowing for the inclusion of time series vectors, with significant differences in data flow characteristics. Floating-point vector matrix multiplication and accumulation operations are more suitable for BF16 precision. The Transformer allows data to be computed in parallel while retaining a global perspective, whereas the data flow of CNN/RNN can only be computed serially, lacking global memory capabilities. Most traditional AI inference-specific chips are primarily designed for CNN/RNN, exhibiting poor performance in parallel computing, and generally target INT8 precision, rarely considering floating-point operations. Therefore, to better adapt to Transformer algorithms, AI inference chips need to undergo a complete architectural innovation at the hardware level, incorporating accelerators specifically designed for Transformers or using more potent CPU computational power to shape the data, which poses higher requirements for chip architecture, ASIC development capabilities, and cost control.
3) Storage-Computing Integration: SoC chips need to be equipped with high-bandwidth memory (HBM) or SRAM, accelerating towards storage-computing integration to solve the data throughput bottleneck under high computational power. The larger the model, the more critical memory becomes for AI accelerators, as it frequently reads weight matrices or trained model parameters. According to Zuo Si Automotive Research, the weight model in Transformers exceeds 1GB, while traditional CNN weight models typically do not exceed 20MB. The larger the model parameters, the higher the bandwidth needed to read more parameters at once. Storage-computing integration can be divided into near-storage computing (PNM), in-storage processing (PIM), and in-memory computing (CIM), with in-memory computing being closest to storage-computing integration. Currently, PNM is widely used in high-performance chips, utilizing HBM stacking and 2.5D packaging to integrate with CPUs, while PIM and CIM are still in development. For example, Tesla’s FSD SoC employs a total bandwidth of 68GB/s with eight LPDDR4 memories, while the SRAM integrated into the NPU can reach 32MB L3 cache, with a bandwidth of 2TB/s, far exceeding similar chips on the market. According to the WeChat public account of Auto Heart, Tesla’s latest HW4.0 uses 16 GDDR6 memories for its second-generation FSD SoC, continuing to lead the industry in memory materials.
Trend 2: In the long term, with the support of cross-domain integration + centralized computing trends, the multi-domain computing control architecture supporting “intelligent driving + intelligent cabin” may become the ultimate demand, and we expect initial mass production to begin after 2025. Cabin-driving integration can effectively reduce development costs and communication delays, optimize computational power utilization and functional experience, propelling intelligent vehicle applications to a new level. According to statistics from Gaogong Intelligent Automotive, from January to October 2022, the simultaneous installation rate of “L2 level assisted driving + intelligent cabin + vehicle networking + OTA” in new passenger vehicles in China reached 18.01%; it is predicted that by 2025, the simultaneous installation of “intelligent driving + intelligent cabin” will exceed 3.5 million vehicles. We summarize the main advantages of cabin-driving integration as follows:
Cost Reduction: In terms of materials, compared to multi-SoC solutions, a single chip with higher integration uses fewer materials and shares a cooling system, reducing cooling costs. In terms of development, the current realization of intelligence still requires automakers to select from different chip combinations, leading to multi-platform cost consumption for hardware and software development. Using a single SoC can save such additional development costs and the hidden procurement management costs of multiple suppliers, while sharing some underlying software can also reduce the speed of vehicle integration and software development costs across different platform models.
Reducing Communication Delays, Optimizing Functional Experience: Using a single SoC can transform the data transmission between the cabin and driving from inter-board communication to intra-chip communication and shared memory, thereby reducing communication delays and achieving smoother cabin-driving functions. For example, Nvidia’s Thor SoC supports the integration of all displays and sensors into a single SoC, greatly simplifying the complex processes of automotive manufacturing and aiding in the timely and sufficient reuse of sensor data, realizing smoother automotive intelligence functions.
However, the realization of “cabin-driving integration” is still some distance away, as both hardware and software technologies and engineering face challenges. On one hand, the application scenarios, functional definitions, and performance boundaries that the cabin and intelligent driving target are different. If they are integrated, the chip selection, peripheral circuit design, computational power demand focus, and safety level requirements will differ, making it challenging to balance cost and performance. On the other hand, most manufacturers are still limited by software and hardware technologies, their understanding of overall architecture, and supply chain factors, making it difficult to achieve single SoC integration of cabin and intelligent driving functions. Therefore, currently, more manufacturers still adopt a “multi-SoC + multi-domain controller” solution. Some manufacturers have already deployed cabin and intelligent driving SoCs on different mainboards or the same mainboard within a single domain controller. For example, Tesla is the earliest practitioner of the “central computing + regional control” concept, based on a fully self-developed system architecture, clarifying the connections between cabin, intelligent driving, and vehicle control systems, while fully reserving interfaces in the early stage. In the Model 3, which was mass-produced in 2019, the central computing unit CCM integrated the audio-visual entertainment module (cabin), the driving assistance system module (intelligent driving), and the vehicle communication module, sharing a liquid cooling system. However, these three modules are still deployed on different PCB boards, each running independently, thus not representing a strict cabin-driving integration or centralized architecture. To achieve true cabin-driving integration, i.e., deploying a single SoC on a single PCB board, continuous improvements in software and hardware technologies and engineering capabilities are required.
We believe that once the EE architecture evolves to a centralized integrated computing architecture stage and the industry gradually completes the underlying software and hardware layout, cabin-driving integration is expected to begin to be integrated into vehicles after 2025, while also driving autonomous driving SoC chips towards the following trends:
1) High Computational Power: Progressing towards thousands of TOPS, including CPU computational power, GPU computational power, and AI computational power. The CPU is primarily responsible for logical operations and decision control, needing to simultaneously manage the scheduling of intelligent driving and cabin domain systems, data processing, and instruction computation. As the data processing volume increases under cabin-driving integration, the CPU will require greater computational power support. GPUs excel in image rendering, graphics processing, and large-scale parallel AI computing, and as the level of autonomous driving continues to rise and cabin entertainment trends towards large-screen and multi-screen setups, as well as the gradual enhancement of human-computer interaction functions, the demand for GPU computational power will also continue to increase. Additionally, current autonomous driving SoCs generally include AI accelerators such as neural network processors (NPU) on top of CPUs and GPUs. According to company announcements, Nvidia’s Thor and Qualcomm’s Snapdragon Ride Flex SoC are both planned for mass production around 2025, targeting cabin-driving integration scenarios, with computational power reaching 2000 TOPS.
2) Advanced Processes: Chiplet technology may be adopted. To achieve cabin-driving integration, high computational power support (typically exceeding 1000 TOPS) is needed while controlling power consumption within a reasonable range. Autonomous driving chips need to develop towards more advanced processes to place more computing units in the same wafer area, providing additional computational power. Currently, automotive AI chips have been developed down to 5nm, but few companies possess advanced manufacturing capabilities, and domestic manufacturers face capacity limitations from TSMC. For example, Horizon’s J5 still adopts 16nm, partly due to the use of ASICs with better power/computational ratios and partly in preparation for domestic foundries. In this context, Chiplet technology is expected to become an important path for intelligent driving chips to achieve performance leaps, meeting the demands for increasing computational power, efficiency, and power consumption. Chiplets, also known as small chips, are combined with special packaging technologies to form larger ICs. Compared to directly producing a single SoC, using small chips enhances wafer area utilization and allows for repeated reuse of small chips, thus lowering total design and validation costs. Additionally, after adopting Chiplet technology, manufacturers can focus on their chiplets and IPs, saving on unnecessary IP costs. The yield of small chips is also generally higher. However, it should be noted that Chiplet technology still faces issues related to industry chain maturity and engineering challenges in integrating cabin and intelligent driving.
3) New Architectures: Domain isolation. When the functions of the cabin and intelligent driving domains are integrated into a single SoC, due to the different needs of the two domains, when allocating hardware resources, it is necessary to define the priority of applications while ensuring that each has sufficient resources, which poses higher requirements for the underlying chip architecture. At the same time, the safety levels of the intelligent driving and cabin domains differ, and the operating systems running on them are also different, requiring proper security isolation to ensure functional safety and information security between different applications. Currently, the cabin entertainment module needs to reach ASIL A, the instrument module needs to reach ASIL B, while the driving module needs to reach ASIL D, which presents significant challenges for how to effectively isolate accelerator resources at the chip level. Additionally, cabin-driving integration requires virtualization technology at the operating system level, which will also incur additional hardware overhead but ensures functional and information security among the domains.

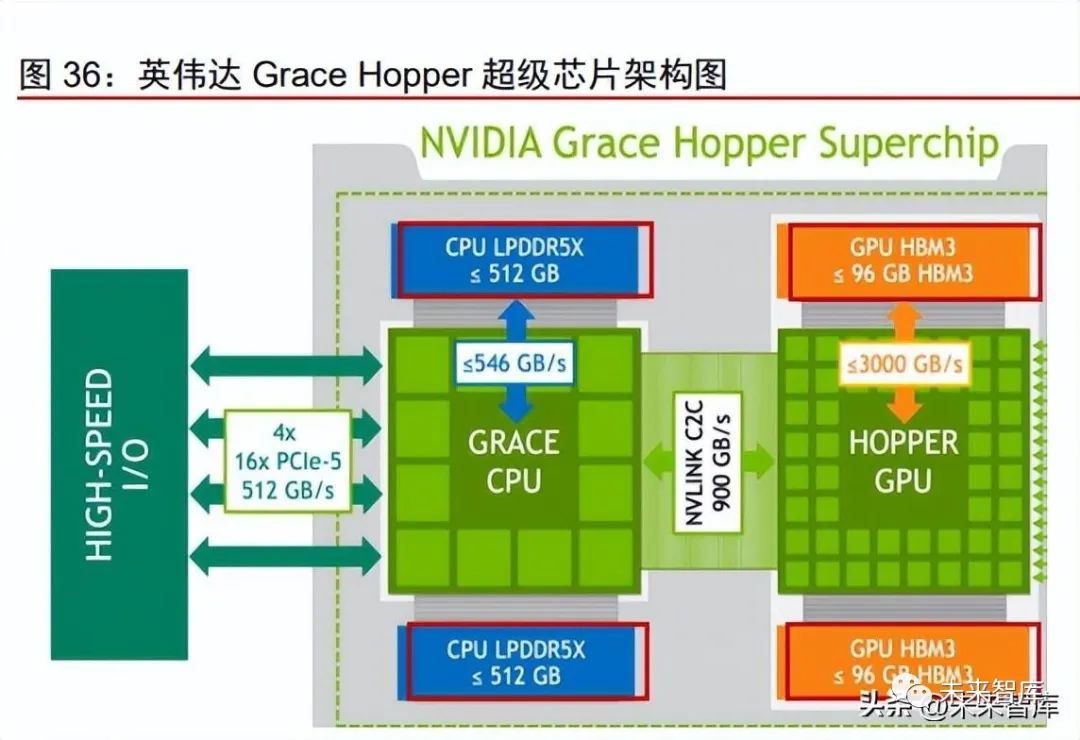
Nvidia: Based on its high GPU technology barrier, Nvidia continues to lead the technological innovation of intelligent driving chips. The Orin X is currently the only mass-produced chip with computational power exceeding 200 TOPS, occupying the largest market share of mainstream mid-to-high-end intelligent driving chips. In September 2022, Nvidia released the Thor SoC, which achieves 2000 TFLOPS@FP8, designed for centralized computing architectures, supporting cloud integration, multi-purpose use of a single chip, and cross-domain computing, which is considered to define the industry’s development direction for the next three years, with plans for mass production in 2025, having already announced Zeekr as its first model. Regarding BEV + Transformer: Nvidia has integrated a Transformer inference engine into the Hopper GPU architecture, significantly enhancing AI computing efficiency. GPUs are inherently suitable for the floating-point operations and high bandwidth demands of Transformer models, and Nvidia has further boosted its AI computing efficiency by incorporating the Transformer inference engine into Thor. This engine was integrated into the H100 training server by Nvidia in 2022, utilizing Nvidia’s Hopper Tensor Core technology, which can apply FP8 and FP16 mixed precision to greatly accelerate AI computing for Transformer models. The Tensor Core operations using FP8 are twice as fast in throughput compared to 16-bit operations. Additionally, Thor aims to unify the precision at both training and inference ends, with the Transformer engine capable of producing FP8 outputs without any data format conversion during inference. Notably, Nvidia canceled the Atlan chip announced at the 2021 GTC conference, and we believe one of the main reasons was that Atlan did not consider the need for a dedicated Transformer engine and did not support FP8 format.
Regarding cabin-driving integration: Nvidia’s Thor SoC proposes “one chip solves all,” with unmatched computational power, continuously leading the industry in architecture. Thor can leverage NVLink-C2C technology to integrate Grace GPU, Hopper GPU, and next-generation GPUs (ARM’s latest server architecture V2 or Poseidon platform), achieving 2000 TOPS of FP8 performance and supporting a single SoC to realize functions of both cabin and intelligent driving. DRIVE Thor can conduct multi-domain computing, allowing autonomous driving, in-vehicle infotainment, and other functions to be divided into different task intervals, running simultaneously without interference, and can centralize all display and sensor computing demands into a single SoC. The ability to isolate multiple computing domains supports time-critical processes running continuously at the same time, enabling the simultaneous operation of Linux, QNX, and Android on a single SoC. In the future, OEMs can utilize Thor’s ability to isolate specific tasks, moving away from distributed electronic control units and integrating all vehicle functions.

Qualcomm: Leveraging its position in intelligent cabins, it is expected to quickly join the first tier of autonomous driving. For the intelligent cabin market, Qualcomm quickly captured the mid-to-high-end market with the Snapdragon SA8155, while the SA8295 continues to represent the forefront of cabin SoC technology. For the autonomous driving market, Qualcomm has made a significant entry into high-performance autonomous driving chips with the Snapdragon Ride autonomous driving platform and the Snapdragon Ride Flex SoC released last year. Regarding BEV + Transformer: Based on its chip development experience accumulated in the consumer electronics and intelligent cabin fields, Qualcomm continues to make breakthroughs in CPU computational power, floating-point operation capabilities, and memory bandwidth, aligning with the trend of deploying Transformers. In early 2020, Qualcomm launched the Snapdragon Ride autonomous driving platform, equipped with SA8540P SoC and AI accelerator SA9000P, offering several combinations of SoCs and ASICs to cover the computational power needs from ADAS to L4 (10-700+ TOPS). According to an article published on the WeChat public account of Zuo Si Automotive Research, the SA8540 in Snapdragon Ride may be the automotive version of Snapdragon 865, while S9000 may be the automotive version of the Cloud AI100 acceleration chip. The Snapdragon 865 is equipped with Adreno 650 GPU, significantly enhancing 16-bit/32-bit floating-point operation capabilities, and has specifically added the Hexagon 698 tensor accelerator, providing high-efficiency AI inference capabilities for Transformer models at the vehicle end.
Horizon: The Horizon J5 is currently the only domestically produced high-computational power chip in mass production, boasting a computational power of 128 TOPS and a low power consumption of 30W, leading its class with a real computing performance of 1531 FPS and ultra-low latency perception capability of 60ms. Based on large-scale heterogeneous near-storage computing, high-flexibility large-concurrent data bridges, and pulsating tensor computing cores, the J5 can execute more tasks with less memory and higher MAC utilization, maximizing the effective use of computational power. This also allows the chip to deliver maximum actual AI performance without stacking area and limited power consumption. The J5 outperformed Nvidia’s Orin and Xavier in FPS metrics during EfficientNet model testing. The J5 has already been integrated into high-end models like Li Auto’s L7 and L8 Pro, and is expected to further capture market share from Nvidia’s Orin.
Black Sesame: Holds certain advantages in functional integrity and cost performance, compared to some ASIC route companies’ products, and may better adapt to the new trends of BEV + Transformer. Black Sesame primarily targets the mid-to-high computational power market, with its Huashan series A1000, A1000 Pro, and A2000 having computational powers of 58, 106, and 256 TOPS, respectively. Previously, the mass production process of Black Sesame A1000 faced delays, but it is now expected to be integrated into models like JAC’s Sihao and Lynk & Co 08, officially starting its commercialization journey. Regarding BEV + Transformer: Black Sesame’s self-developed NPU has good compatibility and can accommodate Transformer algorithms. Black Sesame’s self-developed neural network accelerator NPU and image signal processing ISP are two core IPs that enable the A1000 to achieve high performance & high energy efficiency, achieving an average MAC array utilization of 80% in convolutional layers, assisting customers in more efficiently developing under large models and complex algorithm scenarios.
Huizhi Intelligent: Aiming at the new trends in the BEV + Transformer industry, it is entering the high-computational power chip market and hopes to seize the window of opportunity before hardware and software become solidified, achieving breakthroughs. The company was established in 2022, with a founding team having backgrounds in Microsoft Research Asia, Baidu, SenseTime, SAIC, NIO, and Shanghai Jiao Tong University, possessing deep experience in chip & autonomous driving system research and development, as well as mass production adaptation. The company’s first product, the R1 SoC, is designed for the new trends of BEV + Transformer and cabin-driving integration, planning for computational power exceeding 260 TOPS, expected to SOP in the first half of 2024, and supporting the latest architecture for BEV + Transformer. The company emphasizes “data closed-loop defining chips,” based on its self-developed high-computational architecture, positioned between ASIC and GPU, thus having high algorithm flexibility and versatility, capable of supporting large model algorithms and cross-domain computing demands in terms of AI computational power, CPU/GPU performance, memory bandwidth, and overall architecture. In terms of toolchain & ecosystem, the company is actively building a toolchain ecosystem to accelerate customers’ migration to domestic platforms. Huizhi provides a complete toolchain, RhinoRT, achieving CUDALike support for deploying BEV/Transformer algorithms, while also supporting common AI stacks and customers’ custom operators, facilitating the migration efficiency of existing Nvidia product customers.
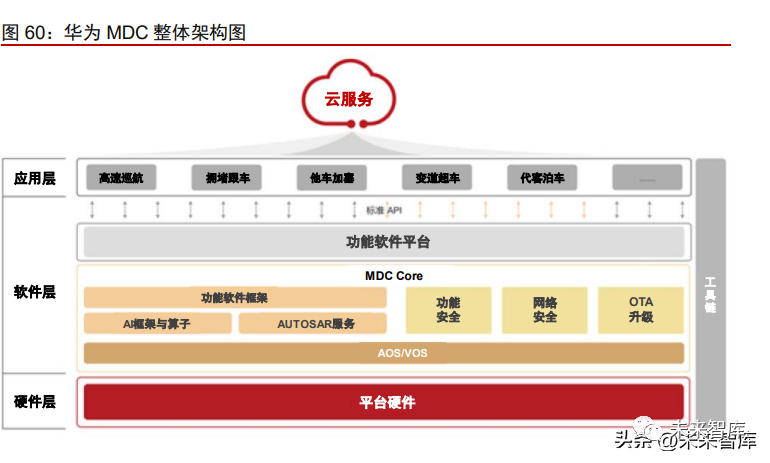
Huawei: Positioned as a Tier 1 supplier, it empowers automakers from multiple dimensions, with its self-developed MDC computing platform demonstrating outstanding performance in architecture and computational power. We believe that based on the MDC computing platform, communication technology, large model accumulation, and the underlying HarmonyOS ecosystem, Huawei will continue to lead the foundational hardware and software industry for autonomous driving. However, its ability to expand to a broader range of automakers remains to be observed. The MDC platform provides scalable and flexible computational power support for autonomous driving. The Huawei MDC platform is based on a combination of multiple Kunpeng CPUs and Ascend AI chips’ SoCs, launching MDC210, MDC300F, MDC610, and MDC810, achieving computational power ranging from 48 TOPS to 400+ TOPS, covering L2+ to L4 level autonomous driving. The MDC platform follows the principles of platformization and standardization, enabling support for different hardware configurations with a single software architecture, achieving decoupling of hardware and software. Additionally, the MDC platform fully considers the different needs for CPU and AI computational power for perception, decision-making, planning, and control, with self-developed Kunpeng SoCs providing CPU power and Ascend SoCs providing AI power. In April 2021, Huawei announced that the MDC810 had achieved mass production and was officially integrated into the BAIC Arcfox Alpha S Hi version and Changan Avita 11 in 2022, while the MDC610 also achieved mass production in 2022.
Market Space: The Chinese Autonomous Driving Chip Market is Expected to Exceed 70 Billion Yuan by 2030
In the short to medium term, with the price war igniting, the intelligent solutions for models at different price points may diverge, leading to different demands for chip computational power and architecture. In the long term, the penetration rate of intelligence determines demand, and new paradigms like centralized computing and large models determine technological routes, while mass production experience, toolchains, and cost-effectiveness determine scale and competitive landscape. Autonomous driving chips will be the most stable link in the entire industry chain, with the highest concentration. We estimate that globally, 4-5 companies and 3-4 domestic companies may occupy 80%-90% of the market share in the industry. At the same time, we project that the market scale for autonomous driving chips in the domestic market will exceed 10 billion yuan by 2025 and exceed 70 billion yuan by 2030. The core assumptions of our estimates are as follows: 1) Passenger car sales: We assume that from 2023 to 2030, passenger car sales in China will grow at an average annual rate of 1%. 2) Functional penetration rates: For traditional L1/L2 functions, we expect the next 2-3 years to be a phase of rapid scaling, reaching peak penetration rates in 2024 and 2026 (25%/40%), and then gradually declining to approximately 3% and 30% by 2030. For NOA functions, we expect that highway NOA will accelerate deployment starting in 2023, while urban NOA will only officially begin to roll out this year, requiring about three years to transition from “available to optimal.” Therefore, we assume that by 2025, the penetration rates for highway/urban NOA will reach 15%/1%, and by 2030, they will reach 45%/20%. As for L4, achieving large-scale deployment remains a distant goal, as the widespread rollout of Robotaxis requires the introduction of pre-installed mass-produced models, with current operational models still being retrofitted vehicles. According to our industry chain research, leading L4 players plan to launch pre-installed mass-produced models around 2025, which may lead to fleet sizes exceeding 10,000 and 500,000 vehicles by 2025/2030, respectively. 3) Chip configurations: We assume that traditional L1/L2 functions will equip 1/1.5 low-power autonomous driving chips per vehicle, while vehicles with highway NOA (L2+) will equip 1 mid-power autonomous driving chip, and vehicles with urban NOA (L2++/L3) will equip 2 high-power chips. Fully autonomous L4/L5 vehicles will require an average of 4 high-power chips. 4) Chip prices: L1/L2 level autonomous driving systems typically equip mid-to-low power chips represented by Mobileye EyeQ3 and Horizon J2/J3, estimating prices of around 20-30 USD for J2 and about 50 USD for J3. We assume that the average price for L1/L2 autonomous driving chips will be around 100/200 yuan. For models equipped with highway NOA functions, we reference Black Sesame A1000 at around 100 USD and Nvidia Xavier at around 150 USD, assuming an average price of 1000 yuan per chip. For models with urban NOA and L4/L5 functions, we estimate the average price per chip to be around 2500 yuan, referencing Nvidia Orin X at around 400 USD. These prices are based on assumptions for 2022, and as mass production scales up, we believe that chip prices will gradually decline, particularly for mid-to-low power chips.
Open and Inclusive, Hand in Hand Cooperation
Sharing Opportunities and Achievements of Industrial Transformation