Gift to Readers

Conducting research involves a profound system of thought, requiring researchers to be logical, meticulous, and earnest. However, effort alone is not enough; leveraging resources is often more important. Additionally, one must have innovative and inspirational points of view. It is recommended that readers browse through the content in order to avoid suddenly falling into a dark maze without finding their way back. This article may not reveal all the answers to your questions, but if it can clarify some of the doubts that arise in your mind, it may create a beautiful sunset of colors. If it brings you a storm in your spiritual world, then take the opportunity to brush off the dust that has settled on your ‘lying flat’ mindset.
Perhaps, after the rain, the sky will be clearer…



01

Overview

This article is aimed at implementing research on cognitive radio networks. As the measurement of end-user quality plays an increasingly important role in the development of wireless communication towards the 5G era, the Mean Opinion Score (MOS) has become a widely used metric. This is not only because it reflects the subjective quality experience of end users but also because it provides a universal quality assessment metric for different types of traffic. This article proposes a distributed Dynamic Spectrum Access (DSA) scheme based on MOS, which integrates traffic management and resource allocation for different types of traffic (real-time video and data traffic). The scheme maximizes overall MOS through reinforcement learning, suitable for systems where primary users and secondary users share the same frequency band while satisfying total interference constraints for primary users. Using MOS as a universal metric allows nodes carrying different types of traffic to learn from each other without degrading performance. Therefore, this article applies a ‘guidance paradigm’ to the proposed scheme, studying the impact of different guidance scenarios on overall MOS, where new nodes are guided by senior nodes carrying similar and different traffic.
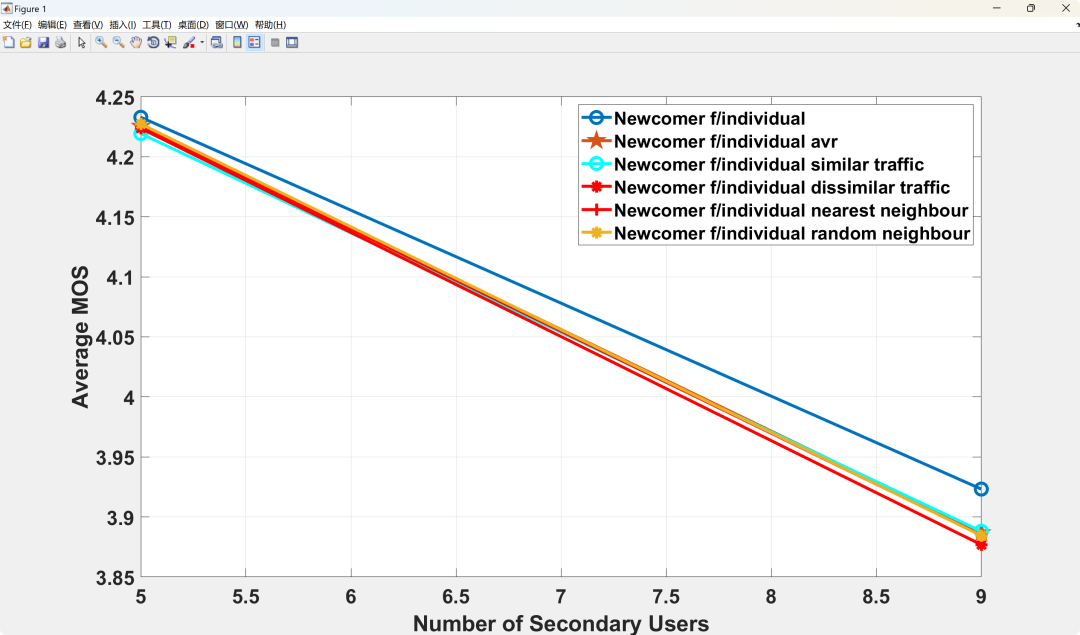
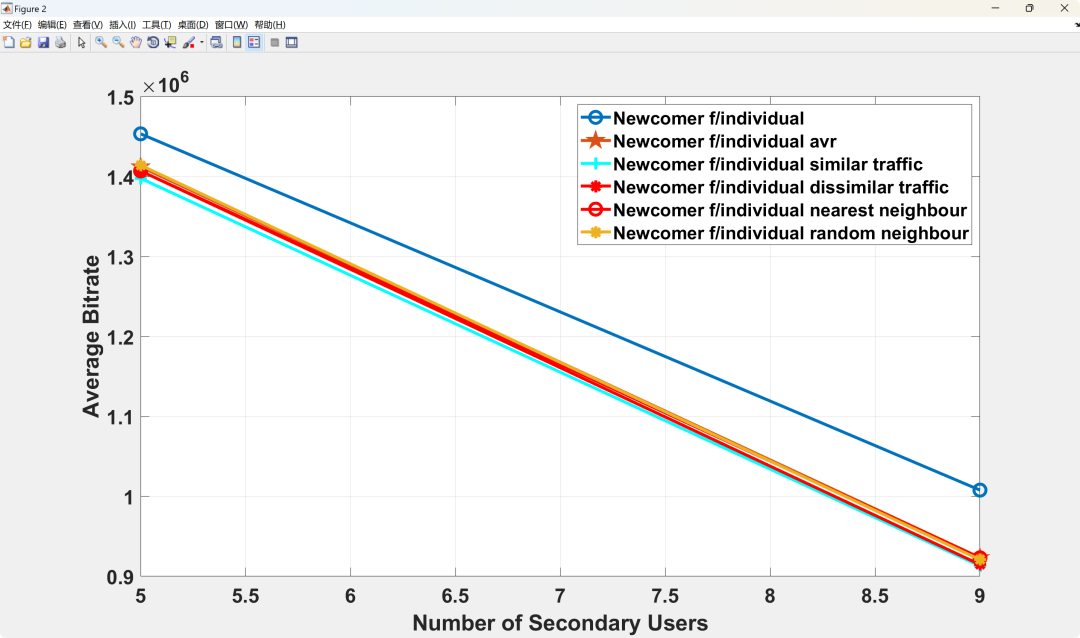
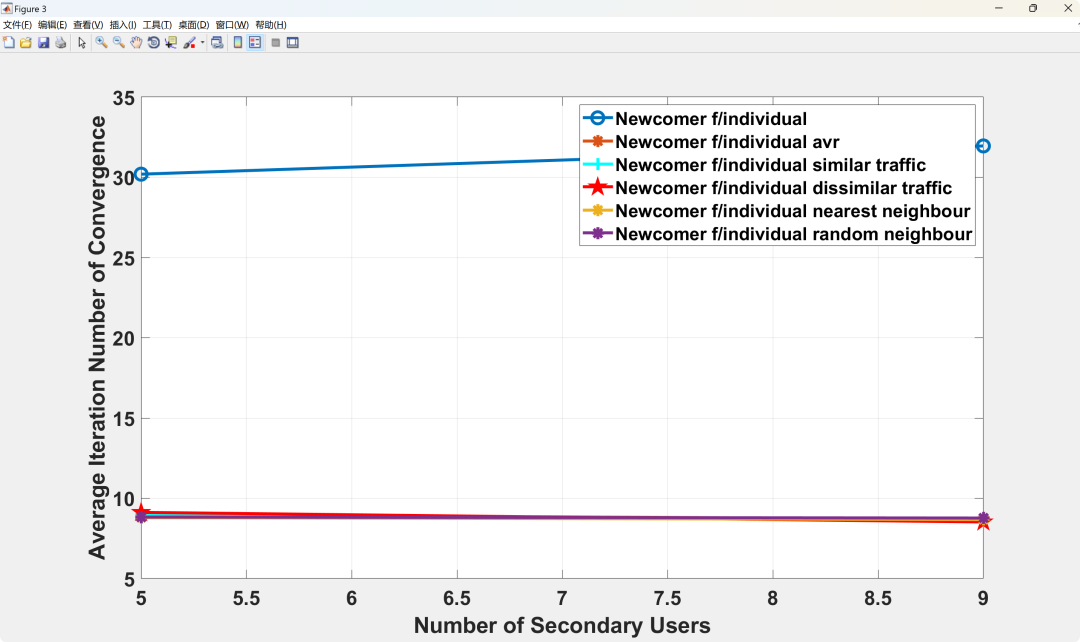
Abstract: As the measurement of end-user quality plays an increasingly important role in the development of wireless communication towards the 5G era, the Mean Opinion Score (MOS) has become a widely used metric. This is not only because it reflects the subjective quality experience of end users but also because it provides a universal quality assessment metric for different types of traffic. This article proposes a distributed Dynamic Spectrum Access (DSA) scheme based on MOS, which integrates traffic management and resource allocation for different types of traffic (real-time video and data traffic). The scheme maximizes overall MOS through reinforcement learning, suitable for systems where primary users and secondary users share the same frequency band while satisfying total interference constraints for primary users. Using MOS as a universal metric allows nodes carrying different types of traffic to learn from each other without degrading performance. Therefore, this article applies a ‘guidance paradigm’ to the proposed scheme, studying the impact of different guidance scenarios on overall MOS, where new nodes are guided by senior nodes carrying similar and different traffic. Simulation results show that guidance can reduce the number of iterations required for convergence by about 65%, while maintaining overall MOS above an acceptable level (MOS > 3) under different secondary network loads. In terms of applying guidance to nodes carrying similar and different traffic, simulation results indicate that all different guidance scenarios perform consistently in terms of MOS performance.
Keywords: Quality of Experience Measurement, Interference, Resource Management, Signal-to-Noise Ratio, 5G Mobile Communication, Quality Assessment
1. Basic Principles and Challenges of Dynamic Spectrum Access (DSA)
1. Core Mechanism of DSA
DSA allows secondary users (SU) to dynamically utilize the unoccupied spectrum ‘gaps’ (white spaces) of primary users (PU). Its core technologies include:
Spectrum Sensing: Real-time monitoring of spectrum occupancy through techniques such as energy detection and cyclostationary feature detection.
Dynamic Decision Making: Selecting available channels based on sensing results and adjusting parameters such as adaptive modulation and power control to avoid interference with PUs.
Spectrum Sharing: Coordinating resource allocation in multi-user scenarios to ensure fairness and efficiency.
2. Key Challenges
Interference Management: Need to avoid interference from SUs to PUs and channel competition among SUs simultaneously.
Dynamic Environment Adaptation: Rapid changes in channel conditions, PU behavior, and network topology require real-time responses.
High-Dimensional Optimization Problems: Spectrum allocation needs to balance multiple objectives such as throughput, delay, and energy consumption, which is an NP-hard problem.
2. Application Framework of Q-Learning in DSA Resource Allocation
1. Algorithm Principles
Q-Learning is a model-free reinforcement learning algorithm that iteratively updates the Q-value table (value of state-action pairs) to find the optimal policy:
State: Includes current channel occupancy, channel quality of SUs (e.g., SINR), network load, etc.
Action: Selecting the frequency band to access, adjusting transmission power, or switching channels.
Reward: The design must consider spectrum utilization (e.g., throughput), interference penalties (e.g., PU activity detection), energy consumption, etc.
Update Rule:
Q(s,a)←Q(s,a)+η[r+γmaxa′Q(s′,a′)−Q(s,a)]
where, η is the learning rate, γ is the discount factor.
2. Typical Application Scenarios
Single User Dynamic Access: SU independently learns the optimal channel selection strategy, suitable for decentralized networks.
Multi-User Cooperative Allocation: Coordinating spectrum competition among SUs through multi-agent Q-Learning to reduce conflict probability.
Energy Efficiency Optimization: Combining energy harvesting technologies to balance throughput and energy consumption in spectrum access decisions.
3. Key Parameters and Model Design
1. State Space Definition
Spectrum sensing data: Includes channel occupancy status, Signal-to-Noise Ratio (SNR), interference levels, etc.
Network context information: Such as SU location, service type (real-time/non-real-time), QoS requirements.
2. Action Space Design
Discrete Actions: Selecting specific frequency bands or power levels, suitable for low-complexity scenarios.
Continuous Actions: Adjusting power or frequency bands through parameterized policies (e.g., Actor-Critic framework), requiring deep learning integration.
3. Reward Function Design
Positive Incentives: Throughput gains from successfully transmitted data packets, improved spectrum utilization.
Negative Penalties: Interference penalties from detected PU activity, delays caused by channel switching.
Multi-Objective Trade-offs: Using weighted summation or hierarchical priorities to integrate multiple optimization objectives.
4. Research Progress and Optimization Methods
1. Improvements to Classic Q-Learning
Deep Q-Networks (DQN): Replacing the Q-value table with neural networks to solve high-dimensional state space problems, introducing experience replay and double networks to enhance stability.
Cooperative Learning: Multiple agents share Q-values or policies to reduce conflicts and accelerate convergence (e.g., distributed Q-Learning).
Transfer Learning: Transferring policies from historical environments to new scenarios to reduce training costs.
2. Performance Comparison
Compared to traditional algorithms: Q-Learning outperforms static allocation (e.g., FSA) and heuristic algorithms (e.g., genetic algorithms) in dynamic environments, but has higher computational complexity.
Compared to other RL algorithms: DQN performs better than SARSA in complex scenarios but requires more training data.
3. Typical Research Achievements
Dynamic Spectrum Access and Energy Harvesting: Combining DQN with sleep mechanisms to reduce energy consumption by over 30% while ensuring throughput.
Multi-Channel MAC Protocol Optimization: Using Q-Learning to alleviate control channel bottlenecks, improving network throughput by 20%.
Applications in Vehicular Networks: In mobile vehicular networks, Q-Learning dynamically allocates channels, reducing switching delays and improving link stability.
5. Challenges and Future Directions
1. Existing Issues
Exploration vs. Exploitation Balance: ε-greedy strategies may lead to slow convergence or local optima.
Partial Observability: SUs may not obtain global state information, requiring integration with partially observable Markov decision processes (POMDP).
Security and Privacy: Need to defend against primary user emulation attacks (PUEA) and other security threats.
2. Future Research Directions
Heterogeneous Network Integration: Integrating DSA with edge computing and intelligent reflecting surfaces (IRS) in 6G smart endogenous networks.
Federated Reinforcement Learning: Protecting privacy through distributed training and enhancing model generalization capabilities.
Quantum Reinforcement Learning: Utilizing quantum computing to accelerate Q-value updates and solve ultra-large-scale network optimization problems.
6. Conclusion
Q-Learning provides an adaptive, low-prior dependency solution for dynamic spectrum access, demonstrating significant advantages in complex dynamic environments. Future research should further integrate deep learning, multi-agent collaboration, and new network architectures to promote the practical deployment of DSA in scenarios such as 6G and the Internet of Things.





02
Running Results

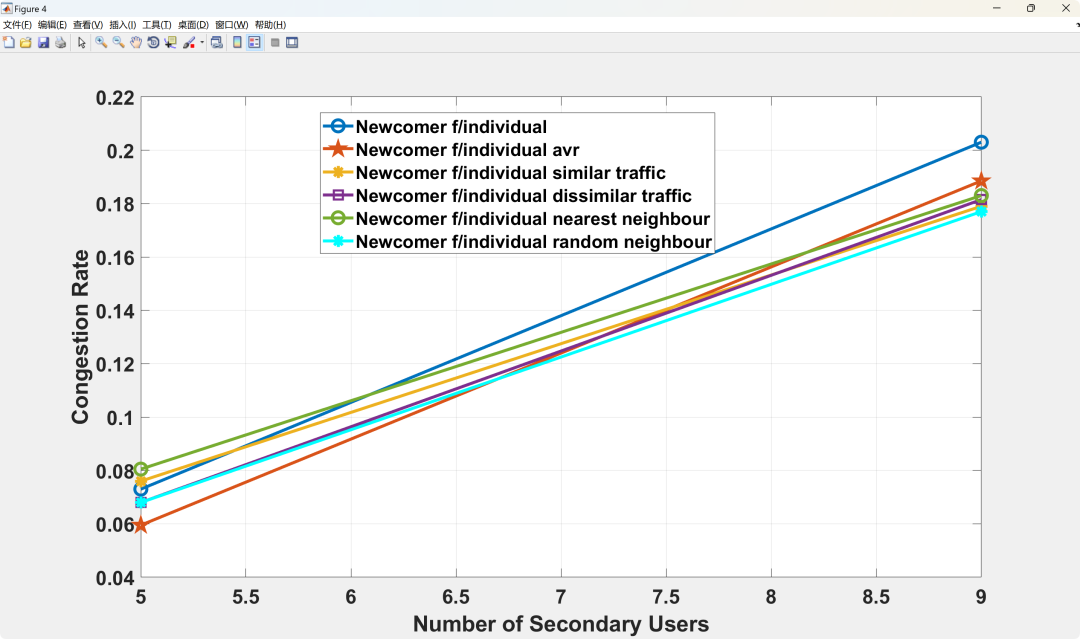
03
Partial Code
flag_phase1 = 1; % add-one newcomer not learning
flag_phase2= 1; % add-one newcomer learning from/using individual learning
flag_phase3 = 1; % add-one newcomer learning from/using individual learning dissimilar traffic
flag_phase4= 1; % add-one newcomer learning from/using individual learning similar traffic
flag_phase5= 1; % add-one newcomer learning from/using individual learning nearest neighbour
flag_phase6=1; %add-one newcomer learning from/using individual learning random neighbour
% system setups
Distortion_table
% Q-learning setups
learner_setup(1)= 0.01; %delta
learner_setup(2)= 0.8; %epsilon-greedy
learner_setup(3)= 0.4; %discounting factor
learner_setup(4)= 0.1; %learning rate
learner_setup(5)= 1; %cooperation flag
learner_setup(6)=0;
sys_setup(1) = 1e-9; %noise power 1nW
sys_setup(2)= 1e-2; %transmit power 10mW
sys_setup(3)= 10e6; %Hz
sys_setup(4)= 10^(1/10); %primary user SINR requirement, from 1 dB
%create a set of possible transmit rate
[bitrate_set, beta_set, D_at_beta_br, Psi] = create_state_set(sys_setup(3));
Distortion_table{1} = bitrate_set;
Distortion_table{2} = beta_set;
Distortion_table{3} = D_at_beta_br;
Distortion_table{4} = Psi;
sz_I = 2; %binary set {0,1}
sz_L = 2; %binary set {0,1}
sz_br_set = size(bitrate_set, 2);
sz_beta_set = size(beta_set, 2);
flag_plot = 0;
t_max = 100;%maximum q-learning iterations
avg_time_max = 2000; %maximum q-learning iterations for a single setup
n_su =[48]; % No. of SUs
learner_setup_new = learner_setup;
sz_n_su = size(n_su,2);
for i=1:sz_n_su
%Initialization before iterations
% expt = zeros(1, n_su); %accumulated expertness
c = zeros(1, n_su); % immediate cost function
weight_exp = zeros(1, n_su);
D = zeros(1, n_su); % part of the cost function(distortion)
% Initialize the state-actions, {r, beta, I, L}, I={0,1}, L={0,1};
S = zeros(n_su, 2);
S_new = zeros(n_su, 2);
% A = repmat([beta_set(end)], n_su, 1); %old actions
A_new = zeros(n_su, 1); %new actions
Current_Q = zeros(1, n_su); % Set the required transmit rate randomly
[tran_rate_level, beta_idx] = set_reqired_trans_rate(bitrate_set, n_su);
A = ([beta_set(beta_idx)]'); %old actions
A = repmat([beta_set(end)], n_su, 1); %old actions
if learner_setup(6)
for ii=1:n_su
[A(ii),Q_max] = argmin_Q(Q_table(ii,:,:,:), S(ii,:),beta_set);%find an action
end
end
%fill up Q-table with the first observation
[I, L, psi_su] = observe_state(BW, A ,bitrate_set,beta_set, delta, coeff_psi); %bitrate_set, beta_set, Psi_set, n_su (obsolete parameters)
S(:,1) = I;
S(:,2) = L;% for testing purpose TO BE DELETED
% beta_idx(:,:)=1;
% Q-learning begin
% Building up Q-table hierarchies for each SU, permutations of state and
% action (initial value = 0), dementionality is:
% #(bit_rate)*#(beta_vector)*#(I)*#(L)
%Q_table = zeros(n_su, sz_br_set, sz_beta_set, sz_I, sz_L);
%set Q_tables elements lower than the minimum transmit rate level to some
%large value
% if ~ learner_setup(6)
% if I+L>=1
% for ii=1:n_su
% if(beta_idx(ii)>1)
% Q_table(ii, 1:beta_idx(ii)-1, :, :) = -1;
% end
% end
% end
% end
if ~ learner_setup(6)
04
References
Some content in this article is sourced from the internet, and references will be noted. If there are any inaccuracies, please feel free to contact us for removal.
[1] Jiang Weiheng. Research on Dynamic Resource Management and Allocation Algorithms for Cognitive Radio Networks [D]. Chongqing University [2025-02-18].
[2] Huang Yunxia. Research on Dynamic Spectrum Access Algorithms for Cognitive Wireless Networks Based on Improved Q-Learning [D]. University of Electronic Science and Technology [2025-02-18].
[3] Li Nan. Research on Dynamic Spectrum Access Schemes for Cognitive Radio Networks [D]. Xi’an University of Electronic Science and Technology, 2014.
[4] Zhang Yazhou, Zhou Youling. Research on Dynamic Spectrum Access Algorithms Based on Q-Learning [J]. Journal of Hainan University: Natural Science Edition, 2018, 36(1):7.
05
Download Matlab Code