↑ Click the above “Chinese Society of Surveying and Mapping“
to quickly follow us
Abstract
Monitoring and early warning are important means for disaster prevention and reduction of geological hazards. In real-time monitoring and early warning of landslides, the scheduling algorithm of the early warning model directly affects the success of the warning. The traditional approach is to start the early warning service at certain time intervals, which is easy to implement but is affected by the warning time interval, resulting in a certain delay in the release of warning conclusions and disposal suggestions, failing to achieve true real-time warning.
How to quickly obtain the warning level through the early warning model and real-time monitoring data, and how to control the time and frequency of sending warning information are two key issues that need to be addressed.
In order to minimize the time interval from data collection to the issuance of warning information, gaining more time for subsequent warning disposal, this study investigates time-driven and data-driven early warning model scheduling methods from the perspectives of warning process and model scheduling algorithm, combining types and characteristics of real-time monitoring data, and proposes early warning model scheduling strategies and early warning information release strategies to improve the accuracy of landslide warnings; develops a warning level solver using a multi-threaded approach, constructs a strategy-based general computational framework for early warning models, and achieves real-time process tracking warnings for landslides, fully utilizing the role of the warning platform.

China is vast, with complex terrain and geological backgrounds, and geological disasters occur frequently. Statistics show that direct economic losses caused by geological disasters in China account for more than 20% of the total economic losses from natural disasters each year, resulting in significant casualties and property losses, greatly affecting people’s production and life.
Landslides are geological disaster phenomena characterized by the sudden sliding of rock and soil bodies on the earth’s surface, and they are common geological hazards in nature. Among various geological disasters occurring in China, landslides cause the most severe losses.
For example, a landslide that occurred on April 26, 2009, in Xiaoba Village, Zhaixi Town, Weixin County, Zhaotong City, Yunnan Province, resulted in 20 deaths and 2 injuries; on August 8, 2010, a mudslide in Zhouqu County, Gansu Province, caused 1,765 deaths; on July 10, 2013, around 10:30, a large-scale landslide occurred in Wulipo, Sanxi Village, Zhongxing Town, Dujiangyan City, Sichuan Province, with approximately 2.64 million m3 of the mountain triggered by previous rainfall, resulting in 161 deaths; on June 24, 2017, a sudden large-scale high-position layered rock landslide occurred in Xinmo Village, Diexi Town, Maoxian County, Sichuan Province, which was the largest rock landslide after the Wenchuan earthquake, causing 10 deaths and 73 missing, with significant losses to the entire Xinmo Village; in 2018, the Baige landslide event in the Jinsha River led to the evacuation of 34,200 people.
On October 10, 2018, General Secretary Xi Jinping emphasized at the third meeting of the Central Financial and Economic Commission that an efficient and scientific natural disaster prevention and control system should be established, the ability to prevent and control natural disasters should be improved, and the informatization project of natural disaster monitoring and early warning should be implemented to enhance comprehensive monitoring of multiple disasters and disaster chains, early risk identification, and forecasting and warning capabilities.
Therefore, monitoring and early warning are important means for disaster prevention and reduction of geological hazards. How to minimize the loss of life and property caused by geological disasters is a long-term and urgent task facing society.
To achieve these goals, real-time dynamic tracking monitoring and early warning of landslide geological disasters must rely on the support of early warning models and early warning systems. In terms of early warning models, Xu Qiang and others proposed a real-time early warning model based on the deformation evolution process of landslides, achieving good application results.
This paper takes a different perspective, focusing on the scheduling algorithm of the landslide early warning model, which is one of the key and core issues in real-time monitoring and early warning of landslides, and is also the most easily overlooked issue.
Using a reasonable model scheduling algorithm can issue warnings in a timely manner, and an appropriate early warning information release strategy can ensure that as few erroneous and redundant warning messages as possible are issued, providing technical support for improving warning accuracy. The goal of this study is to construct a general warning level solver that intelligently selects the scheduling method of the early warning model through data analysis.
Landslide Real-Time Early Warning Process
Figure 1 shows the landslide monitoring and early warning process. The scheduling and calculation of the early warning model is the core part of the entire landslide real-time monitoring and early warning system, and monitoring data runs through the entire process, from the design of the monitoring scheme, selection and installation of monitoring equipment, to the transmission, integration, and processing of monitoring data, and finally to the calculation of the early warning model and the release of the final warning information.
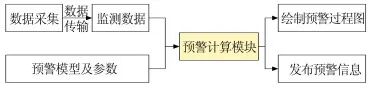
Figure 1 Landslide Monitoring and Early Warning Process
Therefore, achieving automatic, real-time, and stable scheduling of early warning models based on real-time monitoring data and early warning models is an essential technology. The early warning calculation module needs to preprocess the real-time monitoring data received by the system, including removing abnormal data, data smoothing, data fitting, etc., and then quickly calculate the warning level in conjunction with the early warning model, parameters, thresholds, etc., and further release the warning information.
The research content of this paper mainly focuses on the early warning model scheduling link, that is, ensuring that the entire monitoring and early warning process can process monitoring data in real-time and stably, and quickly release warning information. By optimizing the scheduling algorithm of the early warning model and the early warning process, it meets the timeliness requirements of monitoring and early warning, achieving the goal of not missing, not over-releasing, and timely issuing warning information.
Early Warning Model Scheduling Methods1Time-Driven Early Warning Model Scheduling
The landslide monitoring and early warning system is an effective measure for managing landslide geological disaster information and predicting landslides in real-time. Under the condition of monitoring one or more landslide variables, it can quickly and effectively issue warning information when a variable undergoes a sudden change.
Scholars at home and abroad have constructed various monitoring and early warning systems based on different monitoring indicators, achieving many results. For example, based on rainfall monitoring data, Keefer et al. and Segoni et al. developed a real-time landslide early warning system using the I-D model (I is rainfall intensity, D is rainfall duration) and rainfall thresholds, achieving good applications; the real-time meteorological information and geological disaster spatial information spatiotemporal coupling model constructed by the sudden geological disaster real-time early warning and forecasting system in Zhejiang Province can achieve real-time release of geological disaster early warning and forecasting information; the real-time monitoring system for geological disasters in Wushan County, based on real-time monitoring data and early warning models, publishes and shares early warning results; the geological disaster monitoring and early warning and decision support system developed by the National Key Laboratory of Geological Disaster Prevention and Geological Environment Protection in recent years has achieved real-time integration and processing of monitoring data, enabling online release of warning information.
The core of the landslide real-time monitoring and early warning system is to calculate the warning level based on real-time monitoring data combined with the early warning model. The early warning model itself is very important, and the scheduling of the early warning model is equally important, that is, how to start the landslide monitoring and early warning module for warning calculations and how to release warning information.
Currently, a widely used and easily implemented early warning model scheduling method in the industry is time-driven, as shown in Figure 2, which repeatedly starts the warning program at certain time intervals (e.g., 5 min, 10 min, 1 h, etc.) through scheduled tasks, cyclically processing monitoring data, calculating warning levels, and publishing warning results.
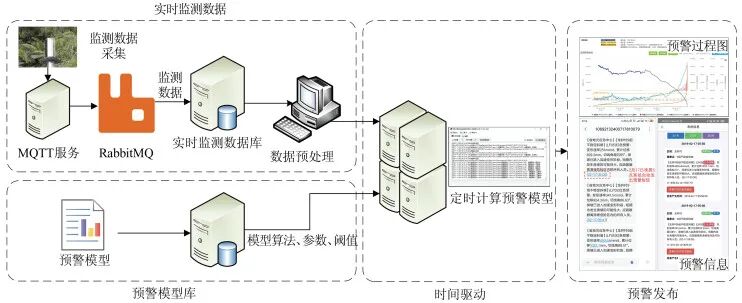
Figure 2 Time-Driven Monitoring and Early Warning Process
However, the time-driven scheduling method has two obvious problems:
1) Warning Delay. It cannot achieve real-time warnings, and is affected by the time interval of the early warning model scheduling, resulting in a certain delay for each warning, which may often miss the best warning time window and lead to warning failure.
2) Waste of Computing Resources. If there is no new monitoring data input during a certain time period, but the early warning calculation still needs to be started, it will waste computing resources, occupy computing resources, and affect the next warning task.
For monitoring equipment, using a higher sampling frequency can capture the complete deformation process, gaining time for warnings. If the sampling time interval is too large, it may happen that no changes were detected during the last sampling, and before the next sampling, the landslide has already occurred. The same issue exists for the landslide early warning system; if a fixed time interval is used, the scheduling of the early warning model may find the landslide in a stable state during the last warning, and before the next warning, the landslide has already deformed and become unstable.
As shown in Figure 3, the monitoring data time interval of the GNSS (global navigation satellite system) monitoring device (GP02) in the landslide in Qinjiao Group, Lianhe Village, Shaopu Town, Zhijin County, Guizhou, is 1 h (Figure 3(a)), and the last recorded data time in the system is 04:00. Before 05:00, the collapse has already occurred, failing to capture the complete deformation curve. The landslide real-time monitoring and early warning system based on the 04:00 monitoring data only issued a yellow warning (Figure 3(b)). If the monitoring sampling frequency could be increased after 04:00 to obtain a complete monitoring curve, a red warning could have been successfully issued. Therefore, the sampling frequency of monitoring data and the scheduling frequency of the early warning model are also of great significance during the critical sliding phase, directly affecting the success of the warning.
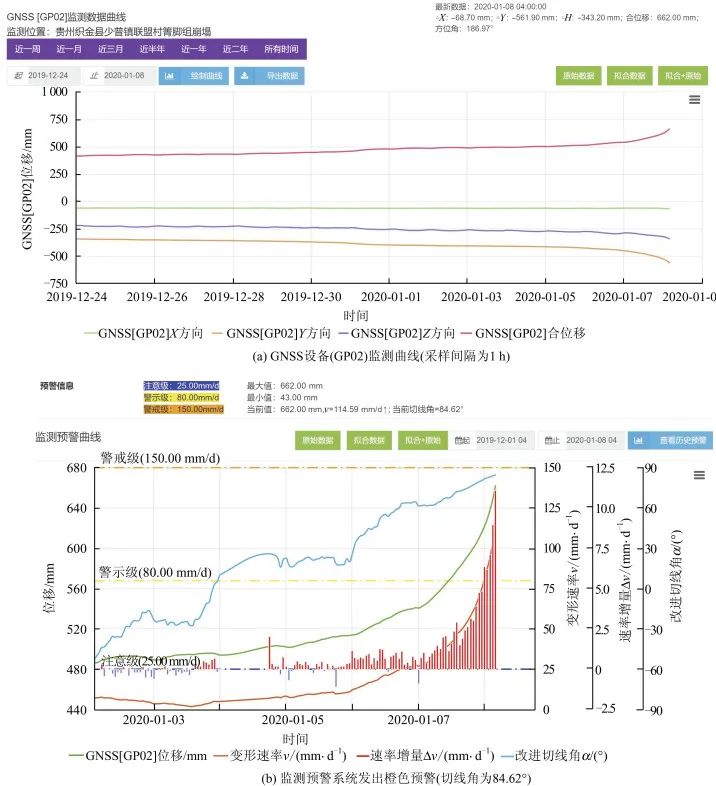
Figure 3 Qinjiao Group Collapse (GP02) Warning Process
2Data-Driven Early Warning Model Scheduling
From the perspective of time-driven methods, it cannot achieve true real-time warnings due to the influence of the warning time interval. To address the shortcomings of time-driven methods, this paper proposes a new early warning model scheduling idea, namely data-driven, which is dominated by the monitoring data stream. Once new monitoring data is received by the monitoring and early warning platform, the early warning program is immediately activated, and early warning calculations are performed through the data-driven program.
The data-driven early warning process is shown in Figure 4, where the on-site monitoring data is transmitted using message queuing telemetry transport (MQTT) technology, meaning that the on-site data is transmitted to the monitoring center server via the MQTT protocol, and then enters the RabbitMQ (an open-source middleware implementing the Advanced Message Queuing Protocol) queue.
On one hand, the real-time integration service of data integrates monitoring data into the database by subscribing to the RabbitMQ queue; on the other hand, the early warning service subscribes to real-time monitoring data in RabbitMQ, and once there is monitoring data in the message queue, it immediately calls the corresponding early warning model to enter the early warning process. Thanks to message queue technology, the entire process from on-site data collection to the issuance of warning information can be controlled within tens to hundreds of milliseconds, thus achieving true second-level response for warnings.
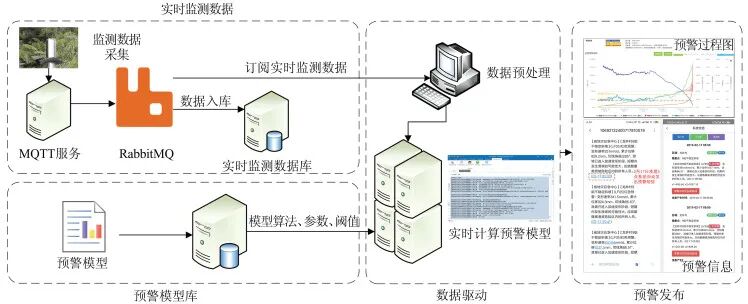
Figure 4 Data-Driven Monitoring and Early Warning Process
Of course, data-driven methods cannot completely replace time-driven modes. Depending on actual needs, a hybrid computational scheduling mode combining both methods can be adopted, that is, using data-driven methods to process state and cumulative data, and using time-driven methods to process rainfall data. Both time-driven and data-driven methods have their advantages and are suitable for different early warning calculation needs. A comparison of the two early warning model scheduling methods is shown in Table 1.
Table 1 Comparison of Time-Driven and Data-Driven Scheduling Methods

Optimization of Early Warning Model Scheduling1Classification of Monitoring Data
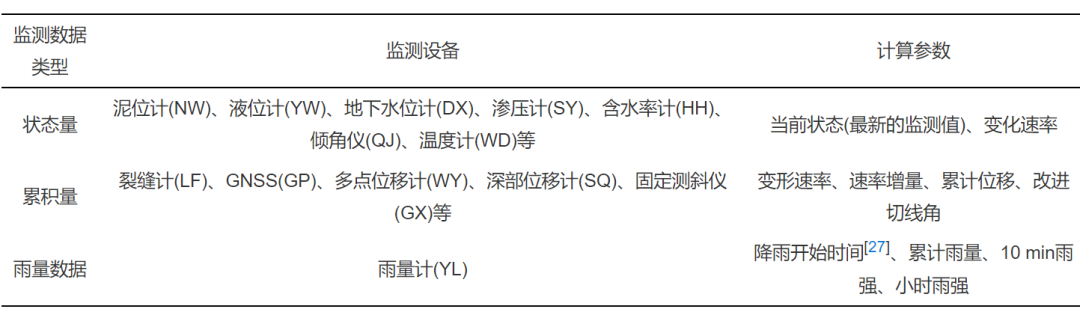
In geological disaster monitoring work, monitoring indicators usually include surface displacement, deep displacement, crack width, liquid level, seepage pressure, rainfall, etc. Based on the characteristics of these monitoring data and equipment, monitoring data used for conventional early warning model calculations can be divided into three categories: state variables, cumulative quantities, and rainfall data.
1) State variables represent the measured monitoring values at the corresponding monitoring moment, and the current sampling value is not affected by the previous sampling time, such as the monitoring values of devices like mud level gauges, seepage pressure gauges, moisture content gauges, thermometers, etc., which only represent the state of the monitored object at the time of sampling.
2) Cumulative quantities represent the measured monitoring data as a cumulative amount over a time period, such as crack gauges and displacement gauges, which focus more on the rate of change of monitoring values during early warnings.
3) Rainfall data can be considered a special cumulative parameter, where the current sampling value is affected by the previous sampling time, and the measured rainfall value is the cumulative rainfall between the last sampling time and the current sampling time. However, since the parameters solved by the rain gauge are different from other cumulative quantities, it is classified separately.
Based on the different data characteristics and solving parameters of these three types of data, different early warning models are used for early warning calculations. The main types of monitoring data are shown in Table 2.
Table 2 Common Monitoring Data Classification and Calculation Parameters
2Strategy-Based Early Warning Model Scheduling
The monitoring data streams based on time-driven and data-driven methods are shown in Figures 5 and 6, respectively. In the time-driven mode (Figure 5), the early warning module obtains monitoring data from the database at certain time intervals for early warning analysis and information release.
In the data-driven mode (Figure 6), the Fanout mode (broadcast mode) in RabbitMQ is used to send messages from the exchange to all queues bound to that exchange, ensuring that the data in each queue is consistent. The early warning module subscribes to the monitoring data in the queue, and once there is new monitoring data in the queue, it immediately activates the early warning analysis and information release function, operating independently of the real-time integration service.
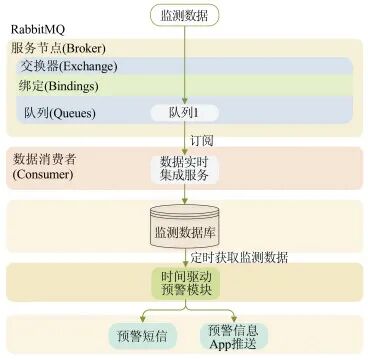
Figure 5 Time-Driven Monitoring Data Flow
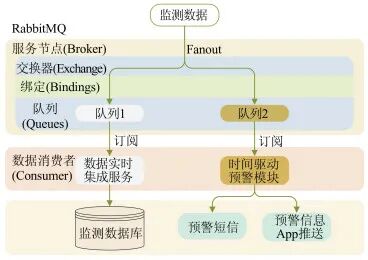
Figure 6 Data-Driven Monitoring Data Flow
To save computing resources and avoid data congestion, this paper proposes the following early warning model scheduling strategies based on summarizing historical warning data:
1) State variable data adopts a data-driven mode. Since the early warning model based on state variable data only needs to compare monitoring data with thresholds, and each data point may contain abnormal information about the monitored object, the time-driven method cannot be used for scheduling.
2) Rainfall data adopts a time-driven mode. Since the early warning model based on rainfall data mainly analyzes historical rainfall data to obtain parameters such as cumulative rainfall and rainfall intensity, it cannot be calculated in real-time through data-driven methods.
3) For displacement data, if the landslide is in a stable state, the time-driven mode is adopted; otherwise, the data-driven mode is used. The evolution process from deformation to instability of a landslide has a universal characteristic, and capturing this characteristic can achieve process warnings for landslides. If monitoring data indicates that the landslide is in a stable state, real-time monitoring is not necessary; only periodic calculations of relevant parameters and monitoring of deformation trends are needed. Specific strategies are shown in Table 3.
Table 3 Data-Driven Strategy for Cumulative (Displacement) Data

4) Simplification of time-driven tasks. In actual early warning calculations, for the same set of monitoring equipment, if no new monitoring data has been collected since the last warning ended, the current warning result will be the same as the last warning result. In this case, the early warning calculation for that monitoring device can be automatically skipped, greatly reducing the number of database accesses and computational tasks, thus saving warning time.
General Warning Level Solver1Solver Calculation Process for Warning Levels
This paper adopts a four-level warning system (C1~C4). To standardize the output of the solver, a safety level (C0, which does not strictly belong to the warning level) is defined, indicating that the monitored object is in a stable state and does not require special attention. The warning levels are shown in Table 4.
Table 4 Warning Level Table

Warning calculation involves combining monitoring data, early warning models, warning parameters, etc., to calculate the warning level. To handle various types of monitoring data and different early warning models, a general warning level solver is designed, which returns the warning level based on input monitoring data and early warning models, as shown in Figure 7.
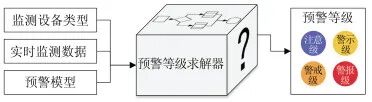
Figure 7 Warning Calculation Diagram
The warning level solver is designed based on the common types of monitoring data characteristics in geological disaster monitoring, considering not only the calculations applicable to landslide monitoring and early warning but also the expansion of the entire early warning system, supporting other types of geological disaster warnings, such as mudslides and collapses.
Generally, monitoring data in geological disaster monitoring and early warning can be divided into three main categories: state data, cumulative (displacement) data, and rainfall data. The calculation of warning levels is performed based on the characteristics of these three types of data. The calculation process of the warning level solver is shown in Figure 8.
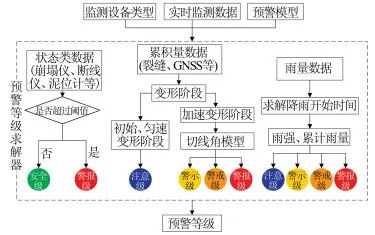
Figure 8 Calculation Process of the Warning Level Solver
(1) State Data
State data, as the name implies, represents the state at a certain moment. The monitoring data from collapse instruments and line break instruments has only two states: 0 indicates normal, and 1 indicates an emergency (collapse, mudslide), with their warning levels defined as safety level (C0) and alarm level (C4), respectively. Other types of state monitoring devices, such as mud level gauges, groundwater level gauges, moisture content gauges, etc., define different warning levels based on corresponding warning parameters and thresholds. This type of data processing is relatively simple, requiring only a comparison of monitoring data with preset thresholds to derive the warning level.
(2) Cumulative Data
Cumulative data mainly refers to monitoring data related to deformation and displacement. Displacement data is an important monitoring indicator in real-time monitoring and early warning of landslides, reflecting the evolution of landslide deformation most intuitively and is the most commonly used means in landslide monitoring. To achieve process warnings for landslides, the analysis is primarily based on landslide displacement monitoring data.
The calculation of warning levels for displacement data is mainly based on the current displacement-time curve, combined with early warning models to calculate various warning parameters, such as deformation rate, deformation acceleration, deformation rate increment, improved tangent angle model, etc., to comprehensively assess the deformation evolution process and trend of the landslide, obtaining the final warning level. Additionally, the displacement monitoring curve can automatically identify the uniform deformation stage of the landslide, further dividing the deformation evolution stages.
(3) Rainfall Data
Rainfall data is also a common type of data in monitoring various geological disasters, especially in mudslides and rainfall-induced landslide monitoring. Rainfall data is a cumulative quantity, meaning that the monitoring data value is the cumulative rainfall over the time period between two adjacent data points (the cumulative rainfall here is different from the cumulative rainfall of a single rain event).
The key indicators of early warning models based on rainfall data are to solve parameters such as rainfall intensity, cumulative rainfall, and rainfall duration based on historical rainfall data, and the calculation of cumulative rainfall and rainfall duration relies on determining the start time of a rain event. There are many methods to define a rain event, and the automatic search for the start time of rainfall and the automatic division of rain events have been implemented in the early warning system, combined with corresponding early warning models (such as I-D, E-I, E-D models, where E is cumulative rainfall) to obtain the final warning level, thus achieving early warnings for mudslides and rainfall-induced landslides.
2Multi-Threaded Warning Technology
To quickly obtain the warning level results for landslides, a warning task allocation scheduling manager is developed, constructing a multi-threaded warning calculation framework based on the relevant algorithms of early warning models.
A thread is the smallest unit in an application program. When the real-time warning module is activated, a process is generated, and the execution of related calculation tasks depends on threads, meaning that the smallest execution unit in the process is a thread, and there is at least one thread in a process.
Generally, single-threaded programs execute in a serial manner, where the next warning task is executed only after the previous one is completed (Figure 9(a)). To accelerate warning calculations and improve the overall system efficiency, a multi-threaded parallel execution method can be adopted (Figure 9(b)).
By opening multiple threads within a process, calculation tasks are dynamically allocated to different threads according to certain strategies, allowing each thread to execute simultaneously. However, having too many threads is not always better; it is necessary to balance the execution rate of warning tasks with the read and write rate bottlenecks of the database.
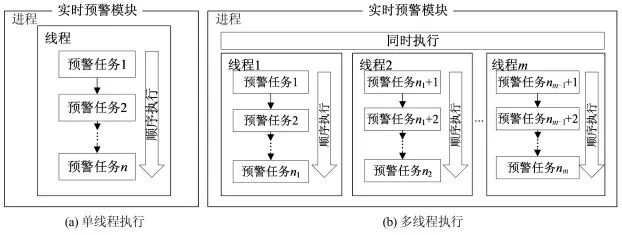
Figure 9 Single-Threaded vs Multi-Threaded Execution Process
Each warning involves a large number of calculations and database read and write accesses. To better optimize the calculation process, this study constructs an intelligent warning strategy based on warning task volume, computing node resources, warning time consumption, etc., dynamically allocating warning tasks to each thread, and implementing data sharing and communication between threads through an asynchronous lock mechanism to ensure data security among threads. Additionally, a Redis high-speed cache is used to alleviate the read and write pressure on the central database, achieving distributed computing and significantly shortening the time required for a complete warning, meeting the performance requirements of large-scale (especially provincial-level platform) landslide real-time monitoring and early warning application scenarios.
Based on the above ideas, a multi-threaded warning calculation framework is developed using system service technology (Figure 10), constructing a strategy-based real-time process warning module for landslides, which can achieve scheduled warnings, data-driven warnings, and can also manually trigger the warning module.
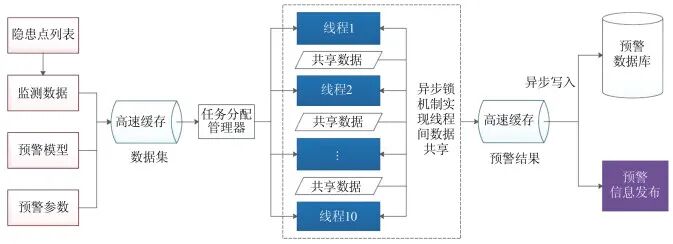
Figure 10 Multi-Threaded Warning Calculation Framework Diagram
3Warning Information Release Strategy
The release of warning information also requires the formulation of relevant strategies to control the frequency of warning message sending, avoiding the recipients from frequently receiving warning messages and generating spam (as this would counteract the intended warning effect). Therefore, the release strategy for warning information is crucial, and it is the most critical outlet in the monitoring and early warning system. Relevant strategies are shown in Table 5, where the priority of the warning level upgrade rule is the highest, meaning that as long as the warning level increases compared to the last time, the warning information must be sent regardless of whether other conditions are met.
Table 5 Warning Information Release Strategy
 Application Effect Analysis
Application Effect Analysis
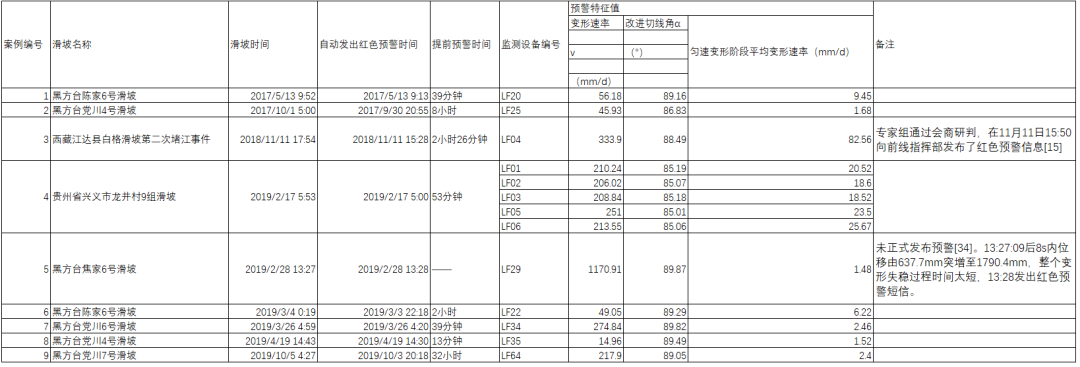
In recent years, through extensive practical applications, this system has collected a lot of monitoring data, and based on the early warning model proposed in this paper, multiple landslides have been successfully warned, as shown in Table 6. However, some landslides could not be warned in advance due to the short time (as in case 5 of Table 6), thus the timeliness of warnings is very important.
Table 6 Successful Warning Cases of This System in Recent Years
Currently, the monitoring and early warning process is roughly divided into five steps:
1) On-site monitoring equipment collects monitoring data.
2) Data is transmitted back to the monitoring data receiving server via GPRS (general packet radio service)/Beidou and other transmission means.
3) After operations such as rough error filtering and abnormal data identification on the monitoring data, it is integrated into the database of the early warning platform.
4) The automatic early warning system reads the monitoring data and performs early warning calculations to obtain the warning level and warning messages.
5) The warning messages are sent to the responsible person’s mobile phone by the SMS sending service.
From the overall process, the strategy-based early warning model scheduling algorithm proposed in this paper significantly shortens the processing time of steps 3) and 4).
To compare and analyze the impact of different scheduling algorithms of early warning models on warning lag time, this paper selects part of the measured monitoring curves of the Heifangtai Chenjia No. 6 landslide, processing monitoring data using different scheduling methods. Figure 11 shows the timeliness comparison results of warning information generated by time-driven (with a time interval of 5 min), data-driven, and intelligent strategy methods.
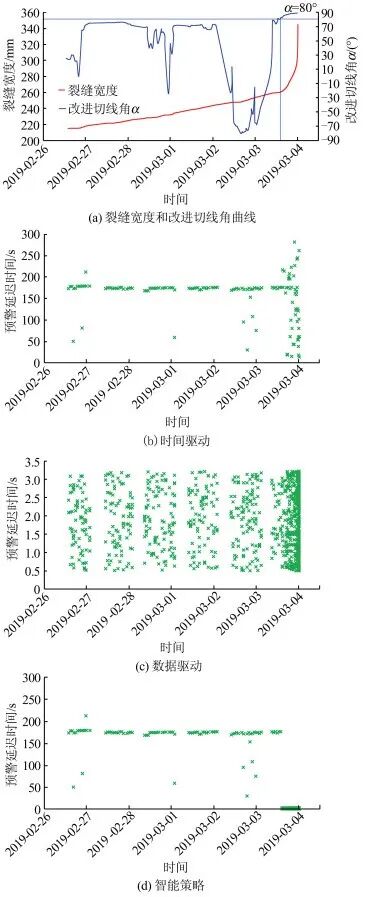
Figure 11 Timeliness Comparison of Different Scheduling Methods of Early Warning Models
In this study, warning delay time is defined as the warning information generation time (tw) minus the monitoring data storage time (t0), that is, the time is counted from the storage of monitoring data until the warning information is generated. Table 7 shows the timeliness statistics of different scheduling methods of early warning models. From Table 7, it can be seen that the time-driven early warning calculation has the fewest calculations, and due to the influence of the time interval, the warning delay time is relatively large, making it easy to miss key deformation information for some sudden landslides. The intelligent strategy mode can reduce the number of early warning calculations while switching to the data-driven mode during the landslide acceleration phase, allowing timely capture of deformation information.
Table 7 Data-Driven Monitoring and Early Warning Process Diagram
 Conclusion
Conclusion
In real-time monitoring and early warning of landslides, the selection and scheduling of early warning models are very important, and the timeliness of warnings cannot be ignored. If the delay time for issuing red warning information is too long, it will reduce its timeliness and even lead to warning failure. This paper analyzes the time in the entire monitoring and early warning process, studies the scheduling algorithm of early warning models, and seeks to minimize warning time to issue warning information in a timely manner, achieving true real-time warnings, and draws the following conclusions and insights:
1) Based on the characteristics of monitoring data, monitoring data used for conventional early warning model calculations can be divided into three categories: state variables, cumulative quantities, and rainfall data.
2) The scheduling algorithms of early warning models mainly include time-driven and data-driven methods, each with its advantages, suitable for different scenarios. Fully combining the two scheduling algorithms can achieve more reasonable and rapid warnings.
3) For displacement monitoring data, the intelligent scheduling method based on strategy can adopt a time-driven mode in the early stage of landslide deformation, and switch to a data-driven mode for early warning model scheduling during the acceleration phase, which can greatly reduce the number of early warning calculations while ensuring timely capture of key deformation information. For state data, a data-driven mode can be used for early warnings to ensure timeliness. For rainfall data and rainfall early warning models, it is recommended to use a time-driven approach for warnings, determining the time interval based on data characteristics.
4) This paper has developed a general warning level solver, constructing a general computational framework for early warning models based on the above strategies using a multi-threaded approach, achieving real-time warnings for landslides, and proposing warning information release strategies to avoid generating excessive warning information while not losing critical warning information, truly realizing dynamic real-time tracking process warnings for landslides.
END
Citation Format: He Chaoyang, Xu Qiang, Ju Nengpan, Xie Mingli. Research on Optimization of Landslide Real-Time Monitoring and Early Warning Model Scheduling Algorithm [J]. Journal of Wuhan University · Information Science Edition, 2021, 46(7): 970-982. doi: 10.13203/j.whugis20200314
Source: Jingwei Stone Side Talk Telemetry
Editor: Zhang Yongchao
Initial Review: Qi Yang
Review: Peng Zhenzhong
