Follow our public account to discover the beauty of CV technology
This article is adapted from the Frontier of Aerial Robotics, authored by Liang Jiachen, an engineer at Westlake University.
With the continuous improvement of computing power and the growth of data, deep learning algorithms have made significant advancements. These algorithms are increasingly applied across various fields, such as image recognition algorithms in autonomous driving and security scenarios, as well as speech processing and natural language processing in human-computer interaction, and the recent hot topic of AIGC, which has a significant impact on many areas.
For different platforms, how to make the inference speed of deep learning algorithms faster undoubtedly affects user experience and can even impact the effectiveness of an algorithm. This is a key issue in deep learning model deployment. Currently, model deployment frameworks include NVIDIA’s TensorRT, Google’s TensorFlow, tflite for ARM platforms, open-source Caffe, and Baidu’s PaddlePaddle.
In fields such as AIOT, mobile devices, and autonomous driving, due to cost and performance considerations, high-performance GPU servers may not be available. Therefore, NVIDIA has introduced the Jetson NX, which can be widely used in embedded devices and edge computing scenarios. At the same time, NVIDIA’s TensorRT can accelerate the inference process of deep learning models, allowing Jetson NX to utilize various deep learning algorithms and thus possess broader application value. Triton is a service framework open-sourced by NVIDIA in 2018, which can better schedule the inference engines generated by TensorRT and handle inference requests.
This article mainly introduces the process of deploying deep learning algorithm models using TensorRT and Triton on Jetson NX, with evaluations based on two commonly used algorithms in the visual domain: YOLOv5 and ResNet.
▌Model Deployment Process
Model deployment on Jetson, being ARM-based, differs slightly from traditional x86-based host or server deployments, but is fundamentally similar and mainly consists of three steps:
- Convert the model to ONNX
- Generate a TensorRT-based inference engine
- Use Triton to complete the deployment
1. Convert the model to ONNX
First, you can convert the trained model from PyTorch or other frameworks to ONNX format for subsequent deployment. PyTorch provides a function to export the model file to ONNX format. Taking YOLOv5 as an example:

You can export the original model to ONNX format, where ‘model’ is the model file to be exported, and ‘f’ is the exported ONNX model file.
2. Generate the TensorRT-based inference engine
TensorRT is primarily used to optimize model inference speed and is hardware-dependent. There are two main ways to convert a Torch-generated model into a TensorRT engine:
- Convert the model’s .pth weight file to a .wts file. Then, write a C++ program to compile the .wts file to generate a inference engine, which can be called for TensorRT inference.
- Save the network structure in ONNX format, then use the ONNX-TensorRT tool to convert the ONNX model file into a TensorRT inference engine.
Note: The inference engines generated by the two methods cannot be directly interchanged and require certain conversions.
In this article, we use the second method to generate the inference engine. That is, using the ONNX model file converted in the previous step, we will use the ONNX-TensorRT tool ‘trtexec’ to convert the ONNX model file into an inference engine.
After installing the ARM version of TensorRT on Jetson, you can use ‘trtexec’ to generate the inference engine from the ONNX model file, as follows:

–onnx represents the input model file, –fp16 indicates the use of half-precision floating-point data, and –saveEngine specifies the name of the saved inference engine. You can use ‘trtexec -h’ to see more parameter descriptions. After execution, you can obtain a performance report similar to the following:
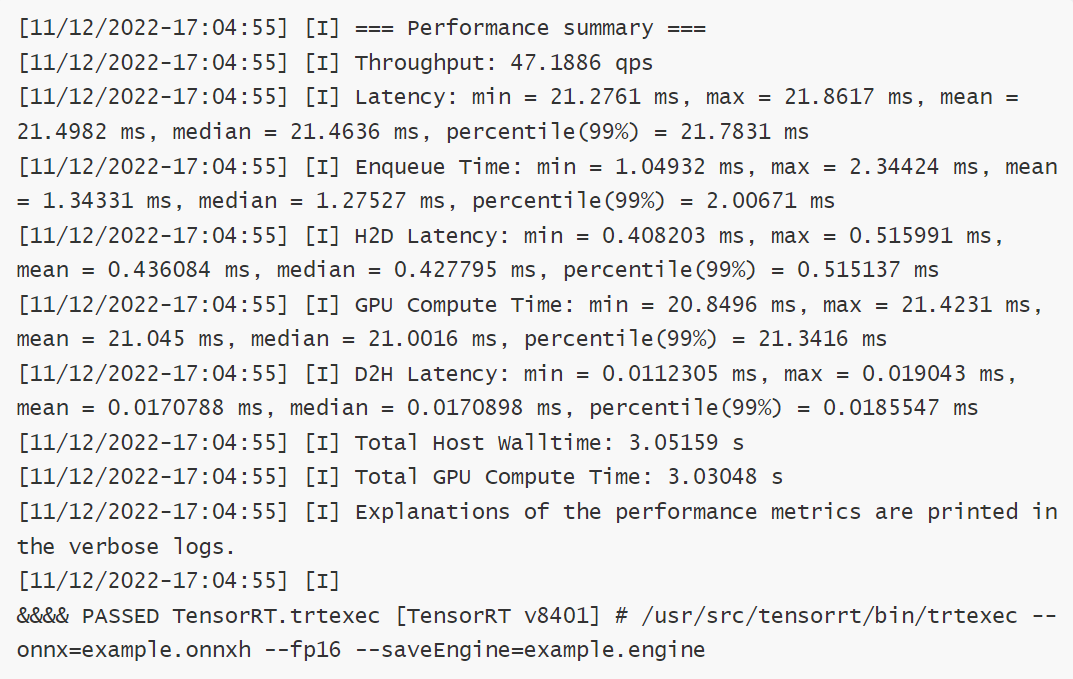
If the final display shows PASSED, it indicates that the inference engine was successfully generated, with 2-9 being the performance test results using pseudo data.
3. Use Triton to complete the deployment
After obtaining the inference engine using TensorRT in the previous step, you can use Triton for further deployment. The installation of the Jetson version of Triton Server can refer to [Triton Inference Server Support for Jetson and JetPack][1]. After installation, configuring the model will complete the deployment. More information can be found in the [Triton Model Configuration Documentation][2].
This article uses the following configuration process as an example:

The directory format of the configuration file is as follows:

That is, build the model file directory and configuration file, and copy the inference engine obtained in the previous step to the corresponding directory as model.plan. A simple configuration file config.pbtxt can be set as follows:

After completing the above configuration, you can use ‘tritonserver’ for deployment:

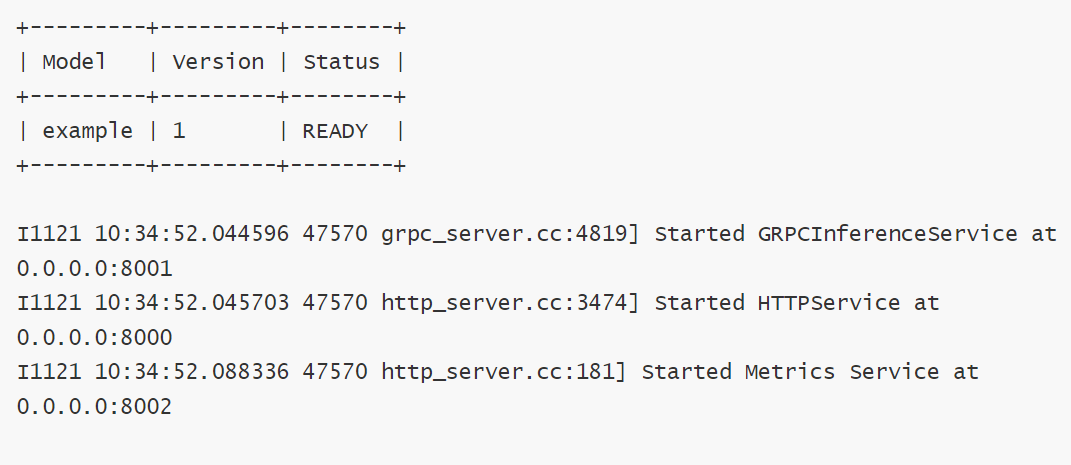
After successful deployment, the results are as shown in the above images. You can use ‘pytritonclient’ to preprocess the data that needs to be predicted and access port 8001 for inference calls.
▌Performance Evaluation
This article evaluates the performance of two commonly used algorithms in the visual domain, YOLOv5 and ResNet, and quantitatively assesses the acceleration provided by TensorRT.
ResNet
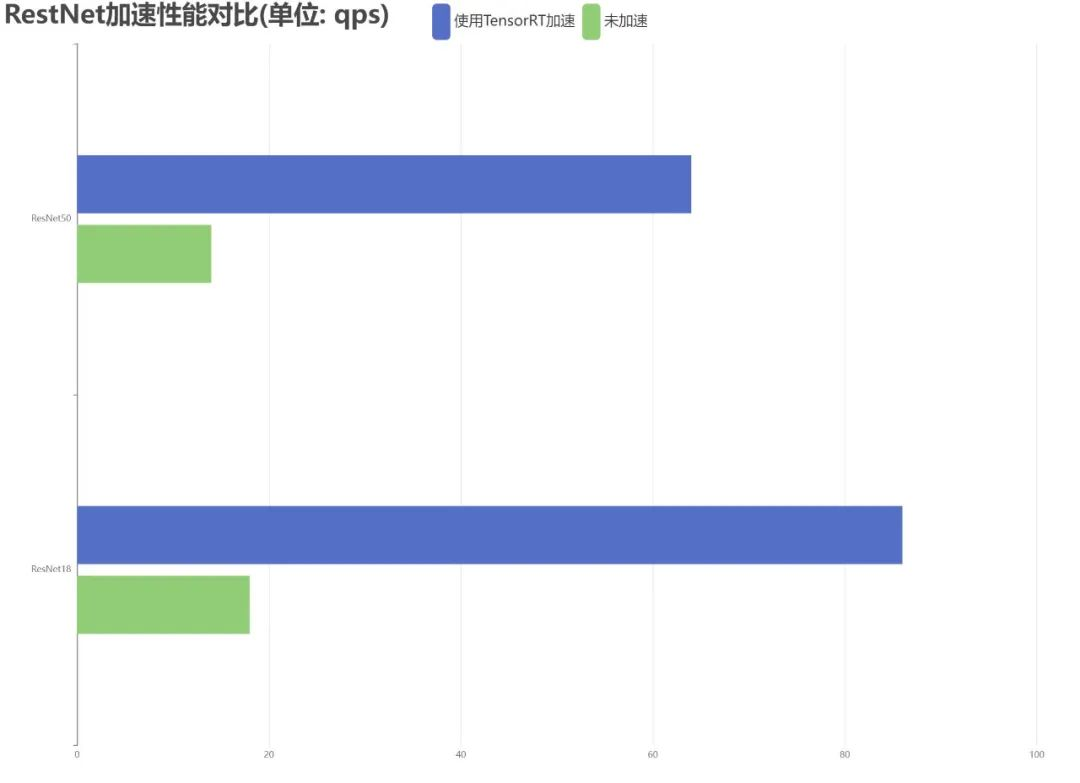
This article tests two common network structures of ResNet, ResNet18 and ResNet50, with experimental results shown in Figure 1. The settings used for the accelerated and non-accelerated versions are consistent, and the measured metric is queries per second (qps), with a batch size of 1, resulting in an acceleration ratio of approximately 6.02.
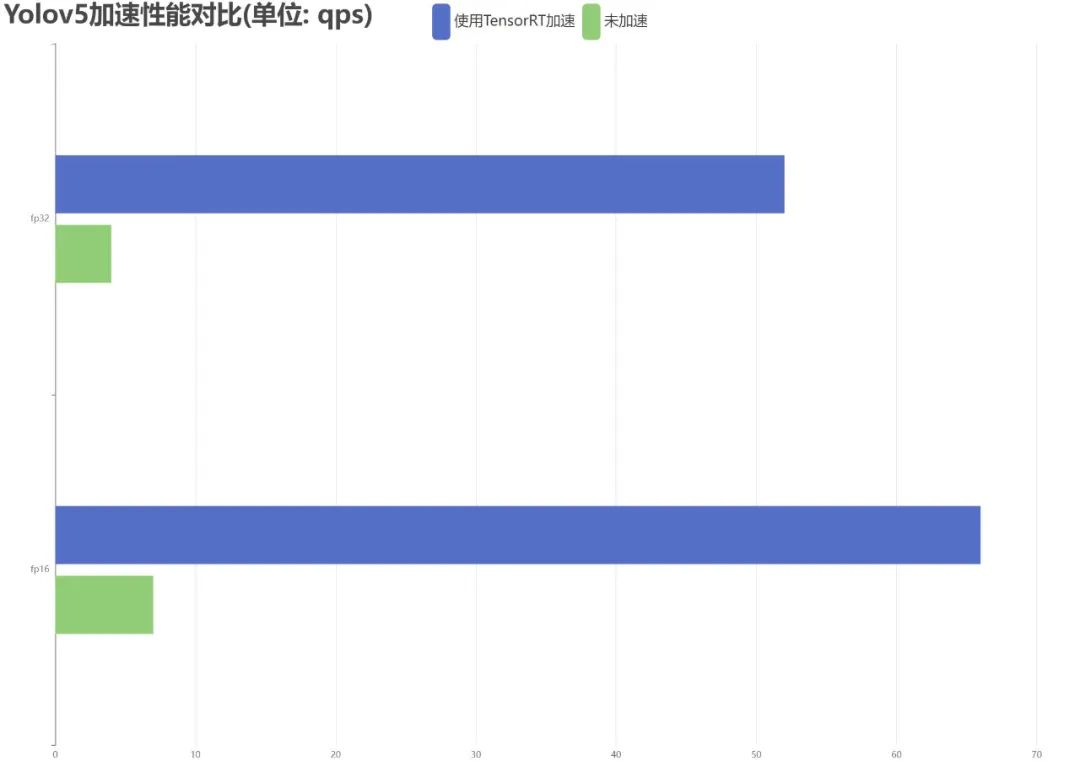
YOLO is a commonly used object detection algorithm in the visual domain. This article tests the acceleration performance of YOLOv5, conducting experiments on both half-precision floating-point and full-precision floating-point types. The experimental results are shown in Figure 2, where the settings for the accelerated and non-accelerated versions are consistent, with an image input size of 320×320, and the performance metric measured is qps. It can be seen that the object recognition algorithm can only achieve real-time object detection after acceleration, with an acceleration ratio of approximately 10.96.
▌Conclusion
This article mainly introduces the methods and overall process of deploying deep learning algorithm models using TensorRT and Triton on Jetson NX, with evaluations based on two commonly used algorithms in the visual domain: YOLOv5 and ResNet. Without significant loss of accuracy, TensorRT can effectively accelerate common deep learning algorithm models and deploy them on Jetson.
Utilizing this technology allows Jetson to operate independently of servers, enabling real-time execution of common deep learning tasks locally. It has significant application value in edge computing and mobile device computing scenarios.
▌References
[1]https://github.com/triton-inference-server/server/blob/r22.10/docs/user_guide/jetson.md[2]https://github.com/triton-inference-server/server/blob/main/docs/model_configuration.md#model-configuration[Cover]https://developer.nvidia.com/tensorrt

END
Welcome to join the “Model Deployment” group chat👇 Please note:Deployment
