This article evaluates the performance of MindSpore and PyTorch based on Huawei’s Ascend Neural Processing Unit (Ascend NPU). Huawei’s Ascend NPU isa chip designed specifically for accelerating neural network computations, which not onlysupports the self-developed framework MindSpore but alsohas been adapted for PyTorch.
However, there is currentlya lack of comparative evaluation studies on MindSpore and other frameworks on the Ascend NPU, making it difficult to understand their actual performance.
Therefore,this article conducts comprehensive evaluation experiments at both the model and operator levels, analyzing and comparing the performance of these two frameworks. Through model evaluation experiments and operator evaluation experiments, conclusions regardingframework performance differences,initial phenomena of the first epoch,AMP performance improvements,differences in dynamic and static graph performance, andmulti-NPU parallel acceleration (Scaling) are drawn, providing references and suggestions for deep learning researchers and practitioners in framework selection and optimization strategies for Ascend NPU.

unsetunsetThis article’s directoryunsetunset
- This article’s directory
- 1. Introduction
- 2. Related Research
- A. Deep Learning Frameworks
- B. Huawei Ascend NPU
- C. Related Research on Performance Evaluation of Deep Learning Frameworks
- 3. Experimental Procedures
- A. Overall Framework of Evaluation Experiments
- B. Model Evaluation Experiment Setup
- C. Operator Evaluation Experiment Setup
- D. Fairness Settings of Evaluation Experiments
- 4. Result Analysis
- A. Hardware and Software Details
- B. Analysis of Model Evaluation Experiment Results
- C. Analysis of Operator Evaluation Experiment Results
- 5. Conclusion
- References

unsetunset1. Introductionunsetunset
Deep learning, as a branch of machine learning, primarily aims to automatically learn effective feature representations from data. With the tremendous success of deep neural networks (DNNs) in tasks such as image classification, speech recognition, and natural language processing, deep learning based on deep neural networks continues to evolve.
Training deep neural networks typically requires large-scale datasets, which places demands on the computational capabilities of devices. As a result, various types ofdeep learning processors have emerged, including NVIDIA’s graphics processing units (GPUs) and Google’s tensor processing units (TPUs). Additionally, Huawei’sAscend NPU offers powerful computational performance and is compatible with various computing scenarios. It is based on a computing architecture designed for neural networks (CANN) software stack, which supports multiple deep learning frameworks, providing new possibilities for the development of deep learning.
To assist researchers and practitioners in improving coding efficiency and effectively utilizing complex computing devices, a large number ofdeep learning frameworks that support automatic gradient computation and device resource management have emerged. These frameworks include Caffe, CNTK, MXNet, Jittor, PaddlePaddle, TensorFlow, PyTorch, MindSpore, etc. However, different deep learning frameworks havedifferent functional characteristics and optimizations, and thusperformance may vary significantly across different computing devices. Therefore, deep learning researchers and practitioners need to carefully select the framework that best meets their needs.
There is a wealth of research onevaluating different deep learning frameworks on various computing devices. However, most of this research focuses on frameworks such as TensorFlow, PyTorch, or Caffe on GPU or TPU devices, whilecomparative evaluation studies on Huawei’s Ascend NPU and the MindSpore framework are relatively scarce. In particular, there is a lack of comparative evaluation studies on MindSpore and other deep learning frameworks on the Ascend NPU, which hinders our further understanding of the adaptation of PyTorch based on the CANN software stack. This study aims to address this gap.
The main contributions of this article include:
- Training DNN models inthree typical scenarios on Ascend NPU devices using MindSpore and PyTorch,analyzing and comparing performance under different settings.
- Analyzing and comparing the operator performance of MindSpore and PyTorch on Ascend NPU under different parameter sizes, including convolution, fully connected, and batch normalization.
- Based on the results of performance evaluation experiments, providing suggestions for deep learning researchers and practitioners onframework selection on Ascend NPU and optimization strategies.
unsetunset2. Related Researchunsetunset
A. Deep Learning Frameworks
Caffe was proposed by the University of California, Berkeley, and is written in C++. It provides interfaces for Python and MATLAB. It excels in convolutional neural networks.
CNTK is an open-source deep learning toolkit proposed by Microsoft. It provides interfaces for C++,C#, Python, and a custom language called BrainScript. It has achieved significant results in speech recognition.
MXNet was proposed by Amazon and provides interfaces for programming languages such as Python, C++, Julia, Go, and R. It islightweight and scalable, suitable for rapid deep learning development.
Jittor is aninstant compilation (JIT) deep learning framework proposed by Tsinghua University. It provides meta-operators similar to Numpy and a unified computation graph that combines the characteristics of static and dynamic computation graphs.
PaddlePaddle was proposed by Baidu. It dynamically describes the computation process of neural networks based on a programmatic approach.
TensorFlow was proposed by Google and represents neural network numerical computations using data flow graphs, where nodes represent operations and edges represent data (i.e., tensors). It provides interfaces for Python, Java, Go, C++, and R.
PyTorch was proposed by Facebook and is evolved from Torch as a deep learning framework. PyTorch adopts a dynamic computation graph design, allowing modification of the graph during execution, which brings simplicity and flexibility for debugging and optimization. PyTorch retains an imperative and Pythonic programming style and extends it to almost all aspects of the deep learning workflow, including layer definitions, model building, data loading, optimizer execution, and training parallelization.
Huawei’s MindSpore is a deep learning framework that supports cloud, edge, and device scenarios. MindSpore provides a unified execution mode that combines static and dynamic computation graphs and allows easy conversion from dynamic graphs to static graphs. Similar to PyTorch, it also retains an imperative and Pythonic programming style, enabling developers to effectively build neural network models.
B. Huawei Ascend NPU
Huawei’s Ascend NPU is a chip based on a domain-specific architecture (DSA), primarily designed to accelerate neural network computations. The computing core of the Ascend NPU is based on the Da Vinci architecture AI Core, which mainly includes the following units: Cube units for tensor computation mode, Vector units for vector computation mode, and Scalar units for scalar computation mode.
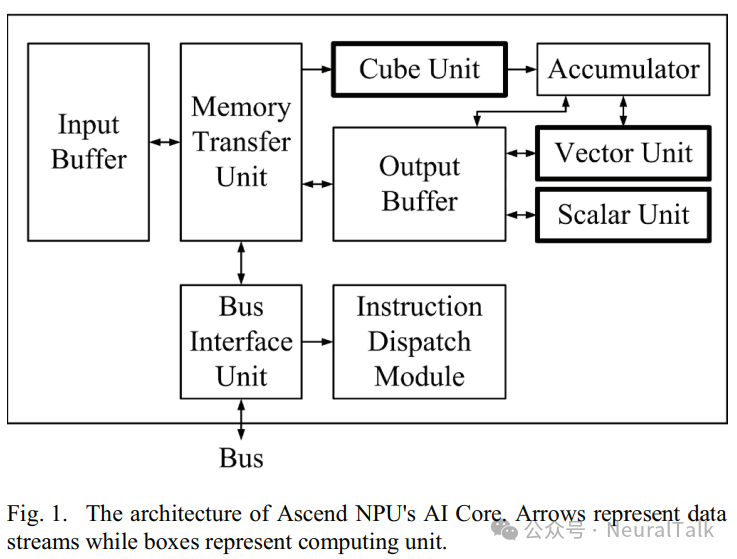
To fully leverage the performance of the Ascend NPU, Huawei proposed the Neural Network Computing Architecture (CANN) software stack, which includes neural network software processes and related toolchains to facilitate the generation, loading, and execution of DNN models. At the deep learning framework level, the CANN software stack not only supports the use of MindSpore but also provides adaptations for TensorFlow and PyTorch, enabling TensorFlow and PyTorch developers to train DNN models on the Ascend NPU.
C. Related Research on Performance Evaluation of Deep Learning Frameworks
Due to the differences between various deep learning frameworks, many research efforts have focused on evaluating the performance of deep learning frameworks.
TBD built a performance analysis toolchain for CNTK, MXNet, and TensorFlow, focusing on measuring and analyzing GPU memory consumption during DNN model training, covering mainstream deep learning applications.
DAWNBench focuses on the training time required for DNN models to reach a certain accuracy threshold, proposing a new composite metric called time to accuracy (TTA). Benchmarking experiments were conducted on TensorFlow, PyTorch, Caffe, and MXNet on GPU and TPU devices.
ParaDnn expanded the scope of benchmarking, generating thousands of parameterized DNN models and evaluating performance differences on GPU and TPU devices using TensorFlow and CUDA.
MLPerf compares the performance of different machine learning systems by benchmarking the training convergence time and throughput using various DNN models.
AI Matrix covers application areas such as computer vision, recommendation, and natural language processing, benchmarking TensorFlow and Caffe on specific e-commerce environment data on GPUs. In references [25]-[31], multiple testing experiments were conducted to compare and evaluate the performance differences of deep learning frameworks including Caffe, TensorFlow, PyTorch, Neon, CNTK, MXNet, Torch, and Theano on GPUs.
There is limited research on the performance evaluation of MindSpore. Literature [18] evaluated the performance of MindSpore on the Ascend NPU at both the model and operator levels, while also evaluating the performance of PyTorch and TensorFlow on GPUs. However, there is a lack of comparative experimental evaluations of MindSpore and other deep learning frameworks on the Ascend NPU, which hinders our further understanding of the adaptation of PyTorch based on the CANN software stack. This study aims to address this gap.
unsetunset3. Experimental Proceduresunsetunset
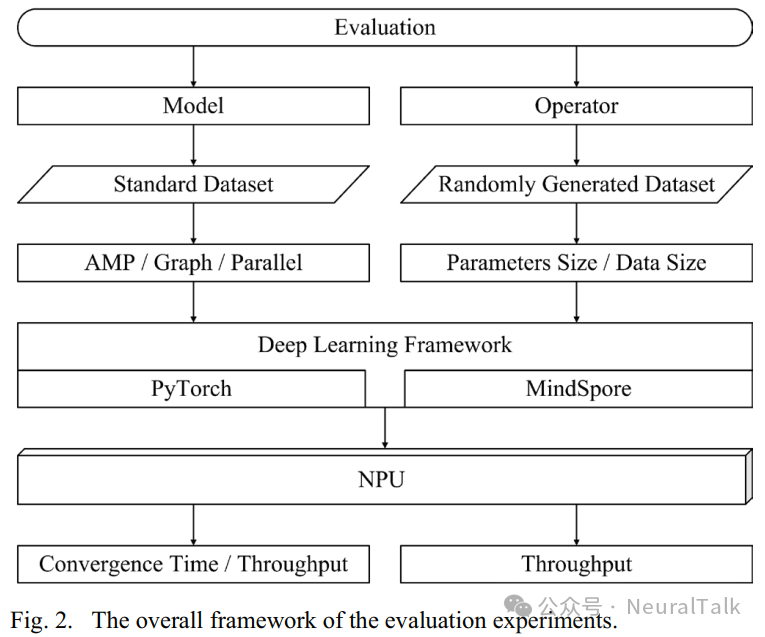
A. Overall Framework of Evaluation Experiments
The overall framework of the evaluation experiments is shown in Figure 2. It includes workloads at both the model and operator levels. Standard datasets and randomly generated datasets are used to evaluate PyTorch and MindSpore based on the Ascend NPU.
B. Model Evaluation Experiment Setup
To conduct a comprehensive analysis, the workloads we selected include residual networks (ResNet), gated recurrent units (GRU), and graph convolutional networks (GCN), covering application scenarios in computer vision, natural language processing, and graph-structured data processing. These workloads involve some mainstream architectures in current deep learning.
- ResNet: A deep convolutional neural network that introduces residual blocks to alleviate the degradation problem during the training of deep neural networks. We selected the implementation of ResNet50 and conducted image classification experiments based on the CIFAR-10 dataset.
- GRU: A variant of recurrent neural networks (RNNs) that introduces gating mechanisms to address the gradient vanishing or explosion problem when capturing long-term dependencies. We selected an encoder-decoder structure and conducted English-French translation experiments based on the Multi30K translation dataset.
- GCN: A neural network designed for graph-structured data. It utilizes graph convolution filters similar to convolutional neural networks (CNNs) to capture local information of nodes and edges in the graph structure and combines them into global feature representations. We conducted graph node classification evaluation experiments based on the Cora dataset, which contains 2708 academic papers and their citation relationships, with all papers classified into 7 categories and represented by 1433-dimensional feature vectors.
In conducting the model evaluation experiments, we considered the following settings related to automatic mixed precision (AMP), computation graph modes, and parallel acceleration:
- AMP: An optimization technique that uses both low precision and high precision during model training. Both PyTorch and MindSpore implement AMP, which can effectively improve training speed.
- Computation Graph Mode: Significantly impacts training performance. PyTorch adopts a dynamic graph mode, while MindSpore supports both dynamic graph mode (PYNATIVE_MODE in MindSpore) and static graph mode (GRAPH_MODE in MindSpore).
- Communication: Achieved through the CANN software stack and Huawei Collective Communication Library (HCCL) to enable communication between Ascend NPU devices, facilitating accelerated parallel training across multiple devices and improving performance.
The evaluation metrics for the model evaluation experiments include convergence time and throughput. Convergence time indicates the time required for the DNN model to reach a certain evaluation metric threshold, while throughput indicates the number of samples processed per second during training. By considering these two metrics, we can comprehensively evaluate the performance of models built using PyTorch and MindSpore on the Ascend NPU.
C. Operator Evaluation Experiment Setup
In addition to model evaluation, we also conducted evaluation experiments on some commonly used operators, including convolution, fully connected, and batch normalization. Specifically, the API implementation for convolution is Conv2d in both PyTorch and MindSpore; for fully connected, it is Linear in PyTorch and Dense in MindSpore; for batch normalization, it is BatchNorm2d in both PyTorch and MindSpore.
In the evaluation experiments, we combined different hyperparameters (such as batch size, input channels, and output channels) to generate operators of different parameter scales. Subsequently, we conducted experimental analysis of these operators under various parameter scales.
The operator evaluation experiments primarily measure the throughput ratio of operators under the two deep learning frameworks, thereby obtaining performance information of operators in different scenarios to provide a basis for optimizing operators.
D. Fairness Settings of Evaluation Experiments
To ensure the fairness of the evaluation experiments, we set parameters, operator implementations, computing devices, caching, and warming up. During the training process of the DNN model, we strictly unified hyperparameters such as learning rate, batch size, weight decay, and optimizer.
For the different implementations of operators under the two frameworks, we referred to the PyTorch and MindSpore API mapping table, selected matching APIs, and adjusted for differences between APIs. In the evaluation experiments, we ensured that the computing devices were completely idle to prevent memory scheduling from affecting the experimental results. To further improve the accuracy of the experimental results, we cached the data and performed training warm-up before the formal experiments.
unsetunset4. Result Analysisunsetunset
A. Hardware and Software Details
The model and operator evaluation experiments were conducted on a computing server equipped with 8 Huawei Ascend 910 NPUs and 4 Huawei Kunpeng 920 CPUs.
Each Huawei Ascend 910 NPU has a storage capacity of 32GB HBM, a bandwidth of 1200GB/s, and can achieve a computational capability of 320TFLOPS at FP16 precision. Each Huawei Kunpeng 920 CPU has 48 cores, with a typical frequency of 2.6 GHz / 3.0 GHz. The server’s RAM storage capacity is 768GB, and the SSD storage capacity is 1.5TB.
On the computing server, the operating system version is EulerOS 2.0 (SP8), the version of CANN is 5.1.RC2.1, the version of Python is 3.7.10, the version of PyTorch is 1.8.1+ascend.rc2, and the version of MindSpore is 1.8.1.
B. Analysis of Model Evaluation Experiment Results
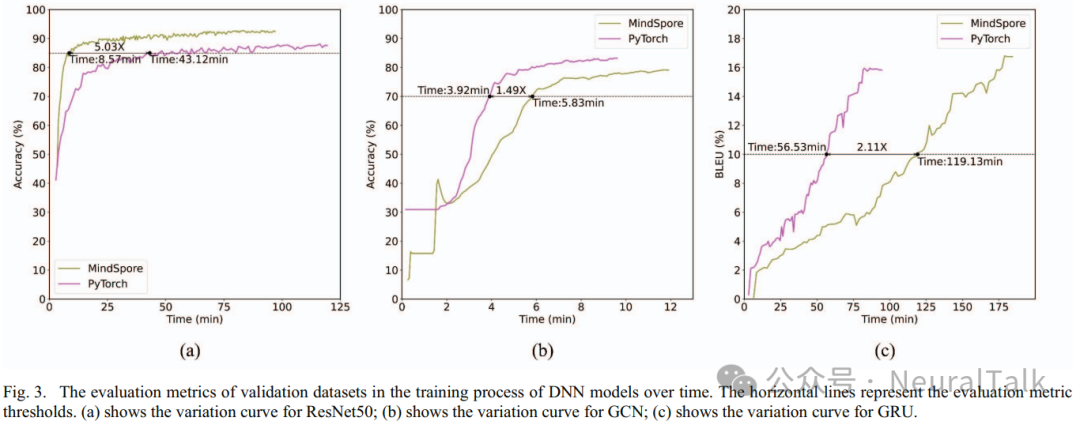
We plotted the evaluation metrics of the validation dataset during the training of DNN models over time, as shown in Figure 3. The evaluation metrics for ResNet50 and GCN are accuracy, while the evaluation metric for GRU is BLEU. Each evaluation metric has different thresholds set: the accuracy threshold for ResNet50 is 85%, the accuracy threshold for GCN is 70%, and the BLEU threshold for GRU is 10%.
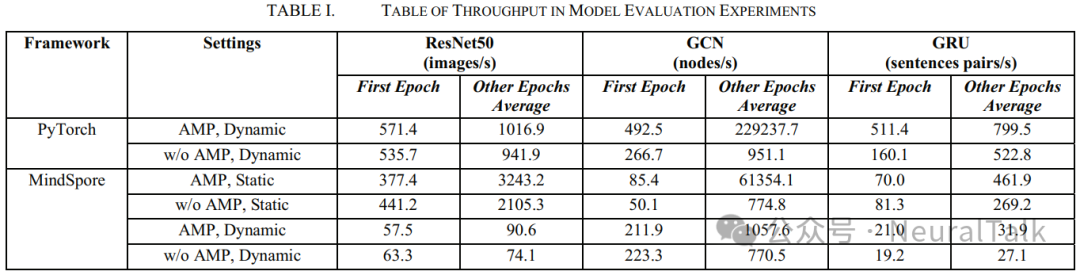
Additionally, we also plotted the throughput graphs for each epoch under different training settings, as shown in Table I. The training settings include training in dynamic computation graph or static computation graph, as well as training with or without AMP. We distinguished the throughput of the first epoch from the average throughput of other epochs. In terms of throughput units, ResNet50 is measured in images/s, GCN in nodes/s, and GRU in sentence pairs/s.
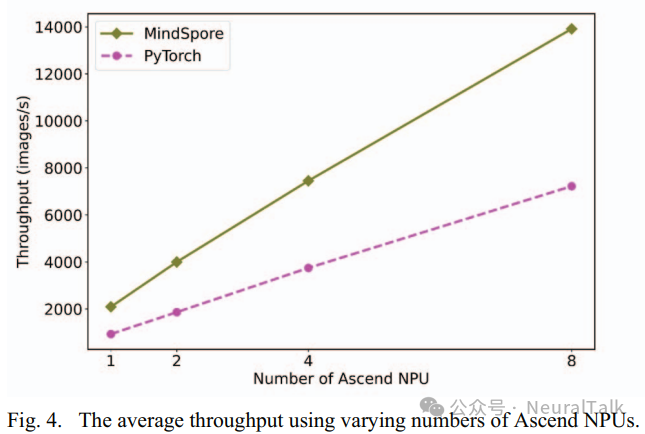
Finally, to evaluate the scalability of parallel acceleration on the Ascend NPU, we trained the ResNet50 model implemented in MindSpore and PyTorch using different numbers of Ascend NPUs and plotted the average throughput during training, as shown in Figure 4.
Based on the analysis of the above graphs and tables, we draw the following conclusions:
- On the Ascend NPU, PyTorch performs worse than MindSpore in dense computation scenarios, while in sparse computation scenarios, its performance is better than MindSpore. The computational core of ResNet50 includes convolution, batch normalization, and activation functions, which are all computation-intensive operations. The computational core of GCN and GRU involves sparse graph matrix computations and gated recurrent mechanisms with temporal dependencies. In Figure 3, the training of ResNet50 implemented in PyTorch took 5.03 times longer to reach the accuracy threshold compared to the MindSpore implementation. The training of GCN and GRU implemented in PyTorch reached the accuracy and BLEU thresholds 1.49 times and 2.11 times faster than the MindSpore implementations, respectively.
- Both PyTorch and MindSpore exhibit significant first epoch initialization phenomena on the Ascend NPU. According to the results in Table I, it can be observed that the throughput of the first epoch is lower than the average throughput of other epochs under all training settings. This can be attributed to the Ascend NPU and CANN software stack performing operations such as context creation and optimization compilation during the first epoch to optimize the construction of the computation graph for the model, thereby improving training efficiency in subsequent epochs.
- Properly setting AMP can improve the performance of both PyTorch and MindSpore. Analyzing the results in Table I reveals that when training with AMP, the average throughput of DNN training is improved, leading to significant performance enhancements. Further experiments indicate that setting the AMP level of PyTorch to ‘O2’ and the AMP level of MindSpore to ‘O3’ not only improves training throughput but also ensures stable convergence of training loss.
- MindSpore performs poorly in dynamic graph mode. MindSpore is a deep learning framework that supports both dynamic and static computation graphs, and its training performance is significantly affected by the computation graph mode used. As shown in Table I, when other training settings remain unchanged, the throughput of MindSpore in dynamic graph mode is significantly lower than its throughput in static graph mode and also lower than that of PyTorch. It is analyzed that the MindSpore compiler utilizes graph optimization techniques to a greater extent in static graph mode, thereby improving training performance. Therefore, it is recommended to use MindSpore’s dynamic graph mode for debugging networks, while using static graph mode for formal training.
- Compared to PyTorch, MindSpore better leverages the computational power enhancement brought by multiple Ascend NPUs. As shown in Figure 4, with the help of the CANN software stack and HCCL, increasing the number of Ascend NPUs significantly improves the training of DNN models in both PyTorch and MindSpore frameworks. However, as the number of Ascend NPUs increases, the improvement in training throughput of MindSpore is more significant than that of PyTorch, thereby better utilizing the computational power enhancement brought by multiple Ascend NPUs.
C. Analysis of Operator Evaluation Experiment Results
We plotted the throughput ratio graphs of convolution, fully connected, and batch normalization operators on the Ascend NPU for MindSpore and PyTorch under different parameter counts, as shown in Figure 5. The vertical axis in the figure represents their throughput ratios, while the horizontal line indicates the case where the ratio equals 1.
- When the value is above the horizontal line, it indicates that MindSpore has higher throughput;
- When the value is below the horizontal line, it indicates that PyTorch has higher throughput.
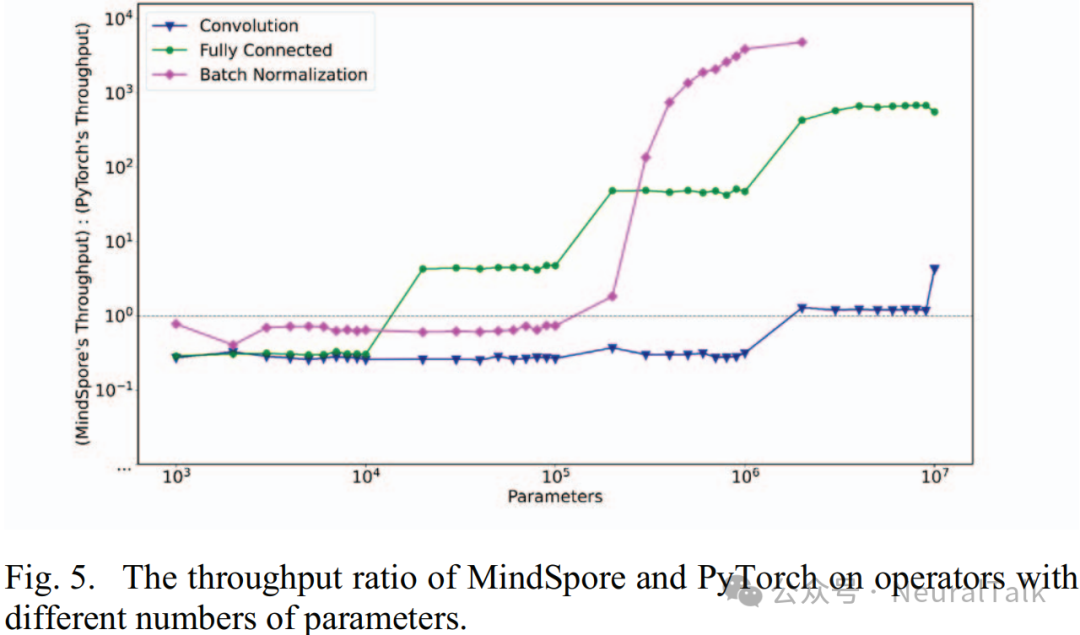
From the figure, it can be seen that PyTorch has higher operator throughput with fewer parameters, while MindSpore has higher operator throughput with a larger number of parameters.
Additionally, different operators are affected differently by the number of parameters. For example:
- MindSpore’s batch normalization operator can exceed PyTorch even with fewer parameters;
- While MindSpore’s convolution operator can only exceed PyTorch when the number of parameters is larger.
These characteristics provide us with optimization insights when building DNN models on the Ascend NPU.
unsetunset5. Conclusionunsetunset
To address the lack of evaluation of deep learning frameworks on the Ascend NPU, this article conducts performance evaluations of MindSpore and PyTorch at both the model and operator levels based on the Ascend NPU.
- In model-level evaluations, three typical DNN models (ResNet, GCN, GRU) were constructed and analyzed and compared under different training settings (such as AMP, graph modes, and multi-NPU parallelism).
- In operator-level evaluations, different parameter counts were set to evaluate the operator performance of MindSpore and PyTorch on the Ascend NPU (convolution, fully connected, batch normalization).
Through the analysis of the evaluation results, we have drawn the following conclusions:
- On the Ascend NPU, PyTorch performs worse than MindSpore in dense computation scenarios, while in sparse computation scenarios, its performance is better than MindSpore;
- Both PyTorch and MindSpore exhibit significant first epoch initialization phenomena on the Ascend NPU;
- Properly setting AMP can improve the performance of both PyTorch and MindSpore;
- MindSpore performs poorly in dynamic graph mode;
- Compared to PyTorch, MindSpore better leverages the computational power enhancement brought by multiple Ascend NPUs.
Based on these conclusions, this study provides references and suggestions for deep learning researchers and practitioners in framework selection and optimization strategies on the Ascend NPU.
unsetunsetReferencesunsetunset
- I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT press, 2016.
- A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, May 2012.
- C. Szegedy et al., “Going deeper with convolutions,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–9, 2015.
- K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778, Jun. 2016.
- “Strategies for training large scale neural network language models,” IEEE Xplore, Dec. 01, 2011.
- G. Hinton et al., “Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups,” IEEE Signal Processing Magazine, vol. 29, no. 6, pp. 82–97, Nov. 2012.
- R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu, and P. Kuksa, “Natural Language Processing (Almost) from Scratch,” arXiv.org, Nov. 2011.
- N. P. Jouppi et al., “In-Datacenter Performance Analysis of a Tensor Processing Unit,” in Proceedings of the 44th Annual International Symposium on Computer Architecture – ISCA’17, 2017.
- Y. Jia et al., “Caffe: Convolutional Architecture for Fast Feature Embedding,” in Proceedings of the ACM International Conference on Multimedia – MM’14, 2014.
- F. Seide and A. Agarwal, “CNTK: Microsoft’s Open-Source Deep Learning Toolkit” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Aug. 2016.
- T. Chen et al., “MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems,” arXiv.org, Dec. 2015.
- S. M. Hu, D. Liang, G. Y. Yang, G. W. Yang, and W. Y. Zhou, “Jittor: a novel deep learning framework with meta-operators and unified graph execution,” Science China Information Sciences, vol. 63, no. 12, Nov. 2020.
- Y. Ma, D. Yu, T. Wu, and H. Wang, “PaddlePaddle: An Open-Source Deep Learning Platform from Industrial Practice,” Frontiers of Data and Computing, vol. 1, no. 1, pp. 105–115, Oct. 2019.
- M. Abadi et al., “TensorFlow: A system for large-scale machine learning,” Google Research, 2016.
- A. Paszke et al., “PyTorch: An Imperative Style, High-Performance Deep Learning Library,” in Proceedings of the 33rd International Conference on Neural Information Processing Systems – NIPS’19, 2019.
- F.Yu, “Research on the next-generation deep learning framework,” Big Data Research, 2020.
- R. Collobert, K. Kavukcuoglu, and C. Farabet, “Torch7: A Matlab-like Environment for Machine Learning,” NIPS Workshop BigLearn, Jan. 2011.
- W. Z. Lu, F. Zhang, Y. X. He, Y. G. Chen, J. D. Zhai, and X. Y. Du, “Evaluation and Optimization for Huawei Ascend Neural Network Accelerator,” vol. 45, no. 8, pp. 1618–1637, Chinese Journal of Computers, Aug. 2022.
- X. Y. Liang, Ascend AI Processor Architecture and Programming: Principles and Applications of CANN. THU press, 2019.
- H. Zhu et al., “Benchmarking and Analyzing Deep Neural Network Training,” in 2018 IEEE International Symposium on Workload Characterization, Dec. 2018.
- C. Coleman et al., “Analysis of DAWNBench, a Time-to-Accuracy Machine Learning Performance Benchmark,” ACM SIGOPS Operating Systems Review, vol. 53, no. 1, pp. 14–25, Jul. 2019.
- Y. Wang, G. Y. Wei, and D. Brooks, “A SYSTEMATIC METHODOLOGY FOR ANALYSIS OF DEEP LEARNING HARDWARE AND SOFTWARE PLATFORMS.” Accessed: Jun. 29, 2023. [Online]. Available: https://vlsiarch.eecs.harvard.edu/files/vlsiach/files/mlsys 2020-a-systematic-methodology-for-analysis-of-deep-learning-hardware-and-software-platforms-paper.pdf
- P. Mattson et al., “MLPerf: An Industry Standard Benchmark Suite for Machine Learning Performance,” IEEE Micro, vol. 40, no. 2, pp. 8–16, Mar. 2020.
- W. Zhang, W. Wei, L. Xu, L. Jin, and C. Li, “AI Matrix: A Deep Learning Benchmark for Alibaba Data Centers,” arXiv.org, Sep. 2019.
- L. Liu, Y. Wu, W. Wei, W. Cao, S. Sahin, and Q. Zhang, “Benchmarking Deep Learning Frameworks: Design Considerations, Metrics and Beyond,” IEEE Xplore, Jul. 2018.
- S. Shi, Q. Wang, P. Xu, and X. Chu, “Benchmarking State-of-the-Art Deep Learning Software Tools,” IEEE Xplore, Nov. 2016.
- H. Dai, X. Peng, X. Shi, L. He, Q. Xiong, and H. Jin, “Reveal training performance mystery between TensorFlow and PyTorch in the single GPU environment,” Science China Information Sciences, vol. 65, no. 1, Dec. 2021.
- A. Shatnawi, G. Al-Bdour, R. Al-Qurran, and M. Al-Ayyoub, “A comparative study of open source deep learning frameworks,” IEEE Xplore, Apr. 2018.
- Y. Wu, W. Cao, S. Sahin, and L. Liu, “Experimental Characterizations and Analysis of Deep Learning Frameworks,” in 2018 IEEE International Conference on Big Data (Big Data), Dec. 2018.
- S. Bahrampour, N. Ramakrishnan, L. Schott, and M. Shah, “Comparative Study of Deep Learning Software Frameworks,” arXiv.org, 2015.
- A. Karki, C. P. Keshava, S. M. Shivakumar, J. Skow, G. M. Hegde, and H. Jeon, “Detailed Characterization of Deep Neural Networks on GPUs and FPGAs,” in Proceedings of the 12th Workshop on General Purpose Processing Using GPUs – GPGPU’19, Apr. 2019.
- K. Cho et al., “Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014.
- H. Zhang, G. Lu, M. Zhan, and B. Zhang, “Semi-Supervised Classification of Graph Convolutional Networks with Laplacian Rank Constraints,” Neural Processing Letters, Jan. 2021.
- A. Krizhevsky, “Learning Multiple Layers of Features from Tiny Images,” Semantic Scholar, 2009.
- J. Elman, “Finding structure in time,” Cognitive Science, vol. 14, no. 2, pp. 179–211, Jun. 1990.
- I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proceedings of the 27th International Conference on Neural Information Processing Systems – NIPS’14, Dec. 2014.
- D. Elliott, S. Frank, K. Sima’an, and L. Specia, “Multi30K: Multi lingual English-German Image Descriptions,” arXiv.org, May 2016.
- A. K. McCallum, K. Nigam, J. Rennie, and K. Seymore, “Automating the Construction of Internet Portals with Machine Learning”, Information Retrieval, vol. 3, no. 2, pp. 127–163, 2000.
- Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, “Gradient-based learning applied to document recognition,” in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998.
- G. E. Hinton, “Reducing the Dimensionality of Data with Neural Networks,” Science, vol. 313, no. 5786, pp. 504–507, Jul. 2006.
- S. Ioffe, and C. Szegedy, “Batch normalization: accelerating deep network training by reducing internal covariate shift,” in Proceedings of the 32nd International Conference on International Conference on Machine Learning – ICML’15, vol. 37, pp. 448–456, Jul. 2015.
- K. Papineni, S. Roukos, T. Ward, and W. J. Zhu, “Bleu: a Method for Automatic Evaluation of Machine Translation” in Proceedings of the 40th Annual Meeting on Association for Computational Linguistics – ACL ’02, 2001.