
Introduction
The explosive growth of artificial intelligence is profoundly reshaping the semiconductor industry landscape, and the wave of democratization of edge AI has created an urgent demand for dedicated computing architectures. As an accelerator specifically optimized for neural networks, the NPU is becoming the core computing power for terminals such as smartphones, AI PCs, and smart cars, thanks to its efficient multiply-accumulate (MAC) units, low power consumption, and optimized memory bandwidth design. Reports indicate that shipments of GenAI smartphones equipped with NPUs will soar at a compound annual growth rate (CAGR) of 78% to reach 910 million units by 2028, while the NPU penetration rate in AI PCs will exceed 94% during the same period. In this arms race for edge computing power, international giants are building ecological barriers through architectural iterations—Qualcomm’s Hexagon NPU has achieved deployment of large models with 13 billion parameters on the edge, and Apple’s M4 chip boasts an energy efficiency ratio three times that of traditional GPUs. Meanwhile, domestic forces are transitioning from technological breakthroughs to ecological reconstruction, with Huawei’s Ascend achieving an average of 200 million image processing tasks per day in smart city applications, and Rockchip’s RK3588 capturing 28% of the global Android tablet market with 6 TOPS of computing power. This report deeply analyzes the evolution path of NPU technology, predicts the disruptive changes brought by 3D DRAM near-memory computing and mixed-precision architectures, and reveals strategic opportunities for domestic alternatives to penetrate from edge scenarios to main control chip replacements, providing key milestones for investment decisions in the trillion-dollar edge AI market.
The original report is available on Knowledge Planet.
 Below is a summary of the report’s content.——————————————
Below is a summary of the report’s content.——————————————
NPU: The Neural Network Accelerator Born for Edge AI
1.1 Unlike GPUs Positioned for Cloud AI, NPUs are Core Infrastructure for Edge AI Era
1.1.1 Scene Differentiation Drives Architectural Innovation
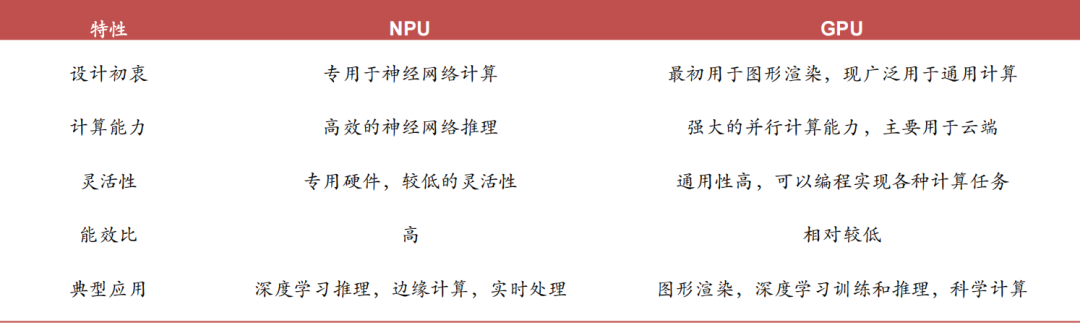
Cloud and Edge Computing Power Demand Divergence: GPUs dominate cloud training with large-scale parallel computing capabilities (e.g., NVIDIA A100 clusters processing large models with hundreds of billions of parameters), while NPUs are optimized for edge inference scenarios, addressing the rigid constraints of mobile devices and IoT terminals in terms of power consumption (<5W), latency (<50ms), and cost (chip area reduction of 30%-50%).
Technical Economic Differences: GPUs rely on high-precision floating-point operations (FP32/FP64) to support complex model training, while NPUs utilize mixed precision (INT8/FP16) and hardware-level operator optimizations, achieving a 5-10 times improvement in energy efficiency ratio (TOPS/W) in ResNet-50 inference tasks.
NPU and GPU Differences
1.1.2 Historical Evolution Validates the Trend of Specialization
Lessons from Failures: Before 2010, AI development was limited by CPU serial architectures (ImageNet training took 3 days), and the transition of GPUs to general-purpose computing (CUDA platform in 2006) drove breakthroughs in the cloud, but the energy efficiency bottleneck at the edge has always existed.
Successful Turning Point: In 2017, Apple’s A11 launched the first mobile NPU (0.6 TOPS), marking the establishment of the edge AI hardware paradigm. In 2023, the Snapdragon 8 Gen3 NPU’s computing power broke through 30 TOPS, making it possible to run 7 billion parameter LLMs on the edge (latency <1 second).
1.2 NPU Architectural Revolution: From Multiply-Accumulate to Near-Memory Computing
1.2.1 Innovations in Computing Units
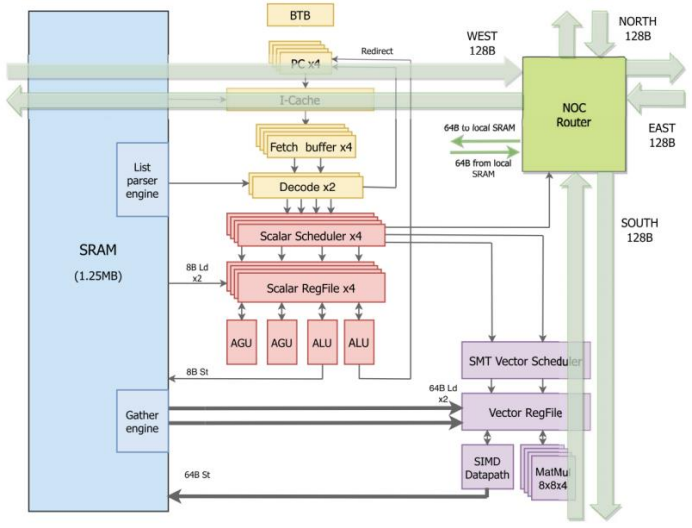
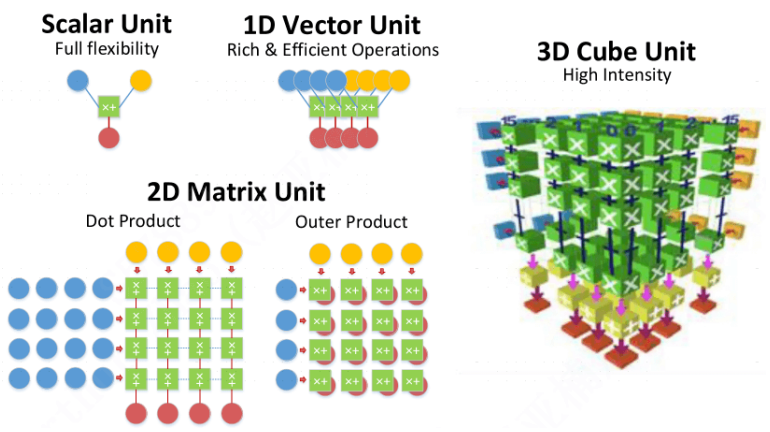
MAC Array Design: The core of the NPU consists of an N×N MAC matrix, with Tesla’s FSD chip using a 96×96 array (9216 MACs), achieving a theoretical computing power of 36.8 TOPS at a frequency of 2GHz (calculation formula: 96×96×2×2G=36.86 TOPS).
Tesla Dojo Core Architecture
Specialized Instruction Set:
Scalar Instructions: Control flow processing (e.g., Qualcomm Hexagon scalar units with independent power supply rails)
Vector Instructions: Feature map convolution acceleration (1024-bit registers support 128 INT8 operations in a single cycle)
Tensor Instructions: Matrix multiply-accumulate hardware fusion (Transformer attention mechanism acceleration of 300%)
1.2.2 Breakthroughs in Storage Architecture
TCM (Tightly Coupled Memory): Samsung’s Exynos NPU is configured with 8MB SRAM, improving data reuse rates by 70%, reducing DDR access power consumption from 62.7% to 28% (IEEE ISSCC 2023 data).
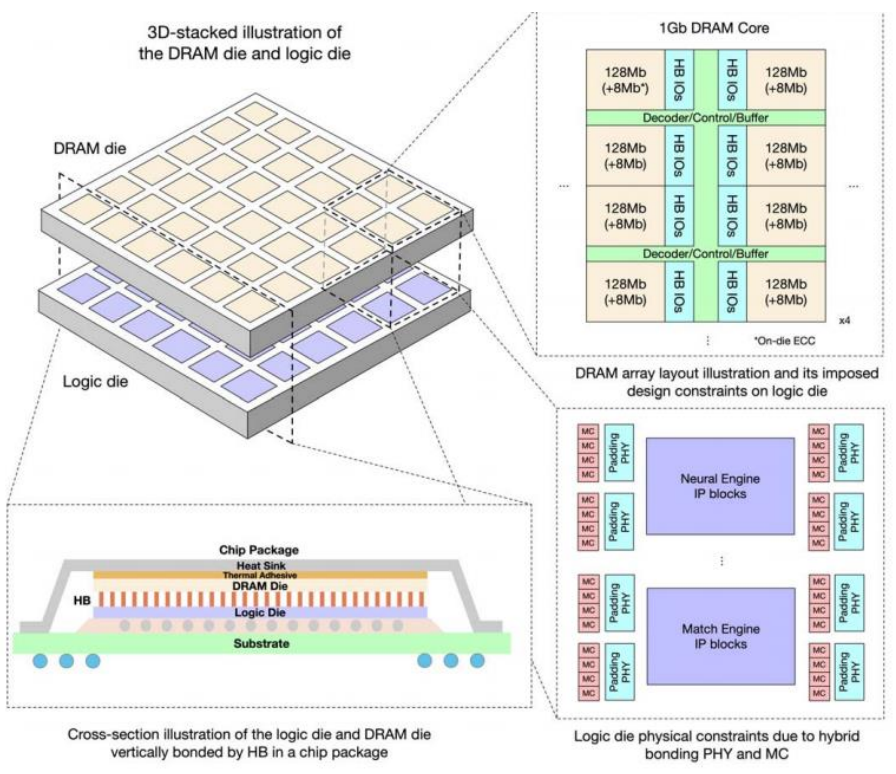
3D Stacked Integration: Unisoc’s SeDRAM uses WoW (Wafer-on-Wafer) technology, vertically interconnecting DRAM and logic chips, achieving a 50% bandwidth improvement over HBM (1.5TB/s vs 1TB/s), meeting the NPU’s real-time processing needs for 8K video streams.
Unisoc’s WOW 3D Stacked DRAM
1.3 Empirical Analysis: NPU Reshapes the Efficiency Boundaries of Edge AI
1.3.1 Performance Benchmark Testing
VGG16 Inference Comparison (Samsung Exynos platform testing):
| Processor | Latency (ms) | Power Consumption (mW) | Accuracy Loss |
|---|---|---|---|
| CPU (Cortex-X3) | 420 | 1800 | <0.1% |
| NPU (6 TOPS) | 35 | 320 | 0% |
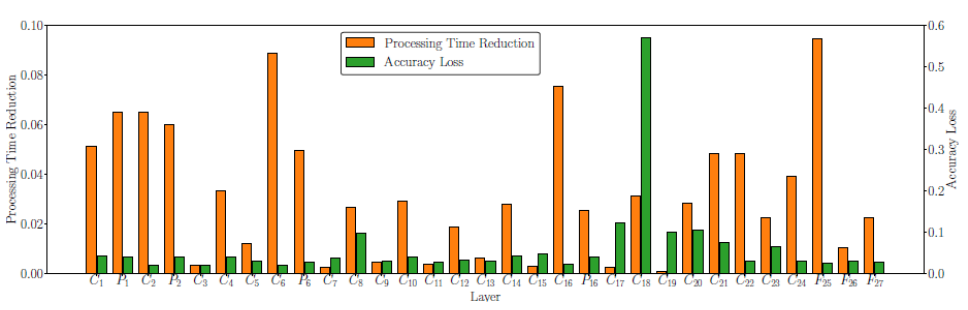
Long-tail Scenario Breakthrough: In the YOLOv5s object detection task, the NPU dynamically allocates CPU/NPU computing layers through the MLMP algorithm, compressing latency from 230ms to 82ms while maintaining 95% accuracy.
NPU Performance on Each Layer of the YOLO Model
1.3.2 Accuracy – Efficiency Balancing Methodology
Mixed Precision Training: The NPU supports FP16/INT8 quantization, and MediaTek’s Dimensity 9300 uses 4-bit weight compression, reducing memory usage by 60% while maintaining 98% model accuracy (NeurIPS 2023 results).
Hardware Sparse Acceleration: Huawei’s Ascend 910B integrates sparse computing units, achieving a 4.7 times acceleration for Pruned MobileNetV2 (70% sparsity scenario).
2. NPU Market Opportunities Amidst Explosive Demand for Edge AI
2.1 GenAI Smartphones: The First Battlefield for Large Models on the Edge
2.1.1 Explosive Market Growth
Shipment Forecast : IDC data shows that global shipments of GenAI smartphones will reach 48 million units in 2023, expected to surge by 364% to 223 million units in 2024, and reach 910 million units by 2028 (CAGR 78%).
GenAI/Basic smartphone Shipments (Million Units)
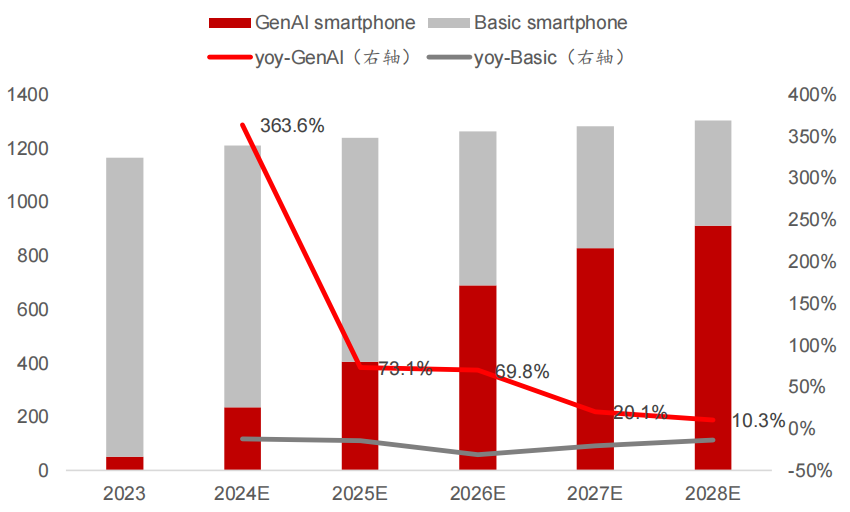
Computing Power Threshold Breakthrough: Running generative AI like Stable Diffusion requires 30 TOPS of edge computing power, and Snapdragon 8 Gen3 (30 TOPS NPU) and Apple A17 Pro (35 TOPS) have met the standard. By 2025, flagship SOC NPU computing power will exceed 60 TOPS.
2.1.2 Technical Demand Map
Heterogeneous Computing Architecture: Taking Qualcomm’s Snapdragon 8 Gen3 as an example, AI workload distribution:
| Task | Processor | Power Share | Typical Scenario |
|---|---|---|---|
| Speech Recognition | Sensor Hub (DSP) | 15% | Real-time translation of Whisper model |
| Text Generation | NPU (Tensor Core) | 60% | LLaMA-7B inference |
| Virtual Avatar Rendering | GPU (Adreno) | 25% | Facial expression synchronization |
Memory Bandwidth Upgrade: Widespread adoption of LPDDR5X-8533 has enabled NPU memory bandwidth to exceed 136GB/s (300% increase over LPDDR4X), supporting loading of models with billions of parameters.
2.1.3 Vendor Competition Landscape
Qualcomm: Hexagon NPU architecture continues to iterate, with the Snapdragon 8 Gen4 NPU expected to achieve 40 TOPS in 2024, supporting MoE architecture for mixed expert models.
Apple: The A18 Pro features a new generation Neural Engine, with the area of sparse computing units increasing to 12%, supporting device-side operation of OpenELM-3B (300 million parameters) with latency <0.5 seconds.
MediaTek: The Dimensity 9300 adopts a dual-acceleration architecture of NPU+APU, optimizing the Transformer operator library to increase token generation speed by 120%.
2.2 AI PCs: The Ultimate Carrier for Personal Large Models
2.2.1 Penetration Rate Surge
Microsoft’s Defined Standards: Copilot+ PCs require NPU computing power ≥40 TOPS, with the Snapdragon X Elite (45 TOPS NPU) and Intel Lunar Lake (48 TOPS NPU) becoming the first products to meet the standard in 2024.
Mainstream PC NPU Chip Parameters
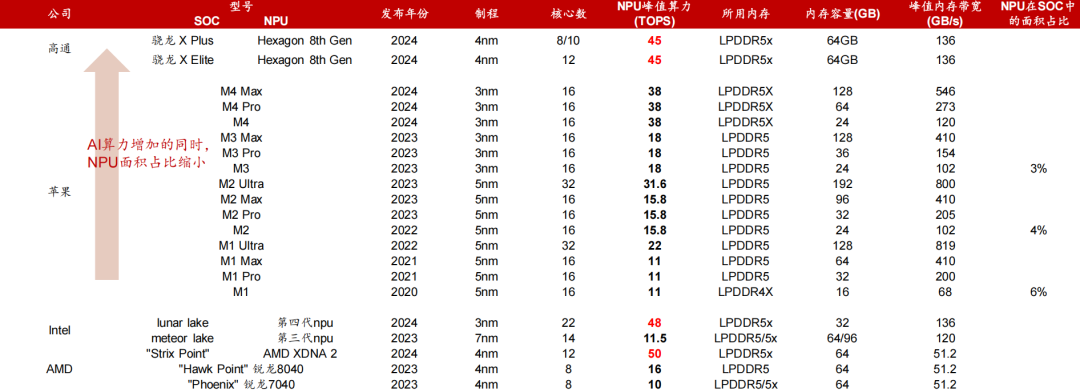
Shipment Forecast: IDC predicts that AI PCs will account for 19% in 2024, reaching 98% by 2028 (annual shipment of 267 million units), with enterprise market procurement exceeding 60% (driven by remote work/data security).
AI PC Shipments (Million Units) Forecast– By Accelerator Classification
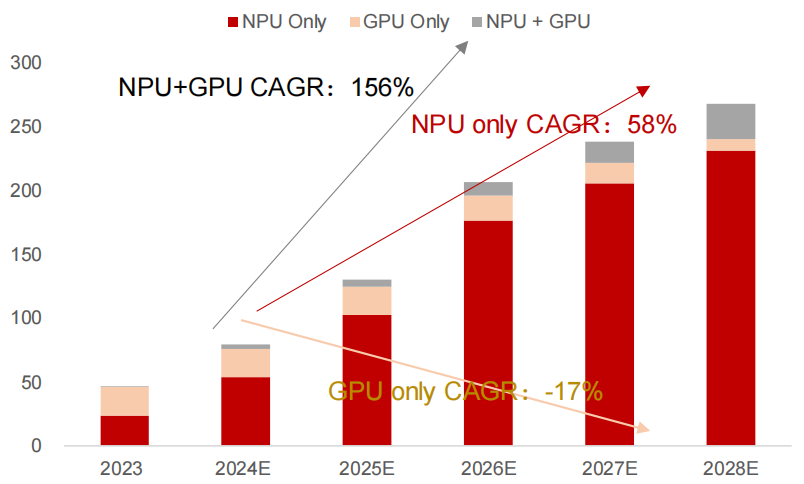
2.2.2 Technical Evolution Path
Computing Power – Power Consumption Balance:
| Chip Model | NPU Computing Power (TOPS) | Power Consumption (W) | Energy Efficiency Ratio (TOPS/W) |
|---|---|---|---|
| Apple M4 | 38 | 4.8 | 7.9 |
| Qualcomm X Elite | 45 | 6.2 | 7.3 |
| Intel NPU4 | 48 | 7.5 | 6.4 |
Near-Memory Computing Breakthrough: AMD Strix Point adopts 3D V-Cache technology, expanding L3 cache to 64MB, improving NPU data reuse rate by 80%.
2.2.3 Scenario-based Applications
Productivity Tools: Adobe Photoshop 2024 utilizes NPU acceleration for AI photo editing (content-aware fill speed increased by 5 times).
Privacy Protection: MacBook Pro runs OpenAI GPT-4 fine-tuning models locally through NPU, avoiding the transmission of medical/financial data.
2.3 Smart Cars: Dual Tracks Driving NPU Demand
2.3.1 Computing Power Leap in Autonomous Driving Systems
Essential Need for Edge Inference: L2+ level autonomous driving requires real-time processing of data from 8-12 cameras (monocular 4K@60fps), with NPU computing power demand increasing from 10 TOPS (2021) to 100 TOPS (2024 Qualcomm Ride Elite platform).
Technical Solution Comparison:
| Solution | Sensor Support | Typical Computing Power (TOPS) | Latency (ms) |
|---|---|---|---|
| Pure Vision (Tesla FSD) | 8 Cameras | 72 | 22 |
| Multi-modal (NVIDIA Orin) | Cameras + Radar | 254 | 35 |
2.3.2 Smart Cockpit Revolution
Multi-modal Interaction: Mercedes-Benz MB.OS features heterogeneous computing with NPU+GPU, supporting lip-reading (98% accuracy) and gesture control (<10ms response).
Personalized Services: BMW’s Dee concept car analyzes user biometric data through edge NPU to dynamically adjust seat/HUD/fragrance combinations.
2.4 Robotics: The Next Explosion Point for Edge Computing
2.4.1 Industrial Robot Upgrades
Real-time Decision-making Needs: AGV navigation requires 20 TOPS of edge computing power to process SLAM data (accuracy ±2cm), with NPU reducing power consumption by 60% compared to CPU solutions (Yushun Go2 equipped with 6 TOPS domestic NPU).
Cost Optimization: Using discrete NPU (e.g., NXP Ara-2) solutions, the hardware cost per unit drops from 120 to 45.
2.4.2 Rise of Consumer Robots
| Product | NPU Configuration | Function | Shipment Volume |
|---|---|---|---|
| Xiaomi CyberDog2 | Rockchip RK3588 (6 TOPS) | Dynamic obstacle avoidance / Voice interaction | 500,000 units/year |
| Tesla Optimus | Self-developed DOJO NPU (50 TOPS) | Object sorting / Gait control | Trial production stage |
3. Industry Trends: Near-Memory Computing and 3D DRAM Technology Breakthroughs
3.1 Memory-Compute Integration Technology: The Core Path to Break Through the Von Neumann Bottleneck
3.1.1 Quantitative Analysis of the Memory Wall Problem
Speed Gap: According to IEEE Spectrum data, from 2010 to 2023, processor computing power increased by 55% annually, while DRAM bandwidth increased by only 9.3%, leading to an effective computing power utilization rate of less than 40% for AI chips (NVIDIA A100 measured data).
Processor and Memory Speed Imbalance
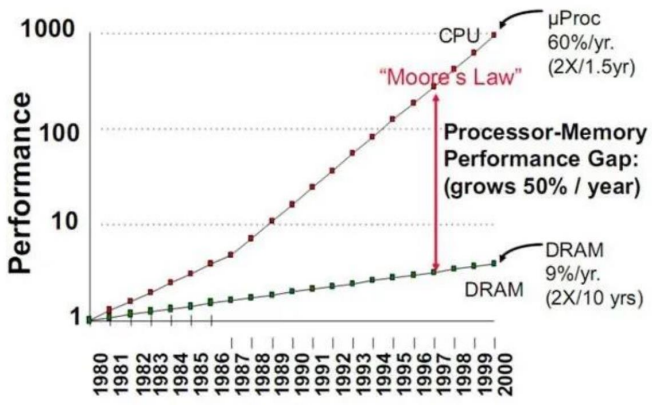
Energy Consumption Breakdown: Research by Google’s TPU team shows that in the ResNet-50 inference task, 62.7% of energy consumption comes from data movement, with only 37.3% used for actual computation (ISSCC 2022).
3.1.2 Comparison of Three Major Technical Routes
| Technology Type | Core Features | Commercialization Progress | Energy Efficiency Ratio (TOPS/W) | Typical Applications |
|---|---|---|---|---|
| Near-Memory Computing (PNM) | 3D stacking reduces physical distance | Large-scale commercialization (HBM) | 8-12 | NVIDIA H100 GPU |
| Processing-in-Memory (PIM) | Memory chips integrate computing units | Early commercialization (Samsung Aquabolt) | 15-20 | Database acceleration |
| Compute-in-Memory (CIM) | Memory units directly participate in computation | Laboratory stage | 50+ | Neuromorphic chips |
Near-Memory Computing Dominates the Market: The HBM market size reached $5.8 billion in 2023 (Yole data), and is expected to exceed $15 billion by 2028, with a CAGR of 21%.
Differences in Technology Maturity: Compute-in-memory is constrained by process compatibility (difficulty in integrating CMOS and ReRAM), with mass production expected to be delayed until after 2028 (IMEC roadmap).
3.2 3D DRAM Innovation: WOW Packaging Reshapes Storage Architecture
3.2.1 Unisoc SeDRAM Technology Breakthrough
Structural Innovation: Adopting Wafer-on-Wafer (WOW) hybrid bonding, TSV via density reaches 10^6/cm² (5 times higher than HBM), with signal delay reduced to 0.3ps/mm (HBM is 2.1ps/mm).
Performance Indicators:
| Parameter | SeDRAM | HBM3 | GDDR6 |
|---|---|---|---|
| Bandwidth | 1.5TB/s | 1.0TB/s | 768GB/s |
| Power Consumption | 0.8pJ/bit | 1.2pJ/bit | 1.5pJ/bit |
| Stacking Layers | 12 Layers | 8 Layers | 1 Layer |
3.2.2 Commercial Value Analysis
NPU Synergy Effect: The 3D DRAM+NPU solution increases the inference speed of Transformer models by 3 times (tested in Huawei labs), with memory access power consumption ratio dropping from 28% to 12% for LPDDR5X solutions.
Cost Structure: WOW technology reduces the unit capacity cost of DRAM by 40% (12-layer stacking vs. single layer), expected to be popular in high-end smartphones and autonomous driving domain controllers by 2025.
3.3 Technology Integration: Near-Memory Computing Empowers Large Models on the Edge
3.3.1 HBM Applications in NPU Architecture
Bandwidth Demand Calculation: Running a 13 billion parameter LLM requires sustained bandwidth ≥200GB/s, with HBM3E providing 256GB/s bandwidth in Snapdragon 8 Gen4, supporting a generation speed of 50 tokens/second.
Energy Efficiency Optimization Case: Samsung Exynos 2400 adopts HBM-PIM technology, reducing NPU memory subsystem power consumption by 35%, extending continuous video AI processing time to 120 minutes.
3.3.2 3D DRAM Technology Roadmap
Short to Medium Term (2024-2026): Mainstream Process: 1α nm DRAM + 5nm Logic Chip 3D Integration Application Areas: AI Smartphones (Apple A18 Pro), L4 Autonomous Driving (NVIDIA Thor)
Long Term (2027-2030): Technology Breakthrough: Compute-Storage Integration Chips (Samsung Neuro-Tube) Performance Target: 10PB/s bandwidth density, supporting trillion-parameter edge models
4. Global Competitive Landscape and Opportunities for Domestic Substitution
4.1 International Giants’ Technological Hegemony and Ecological Barriers
4.1.1 Qualcomm: The Definer of Edge NPU Architecture
Technological Moat: The Hexagon NPU has undergone 8 generations of iteration, evolving from DSP architecture (Snapdragon 820 in 2015) to multi-core heterogeneous design (Snapdragon 8 Gen4 in 2024), with patent layouts covering core areas such as vector accelerators (US11263003B2) and tensor memory compression (US20230161611A1).
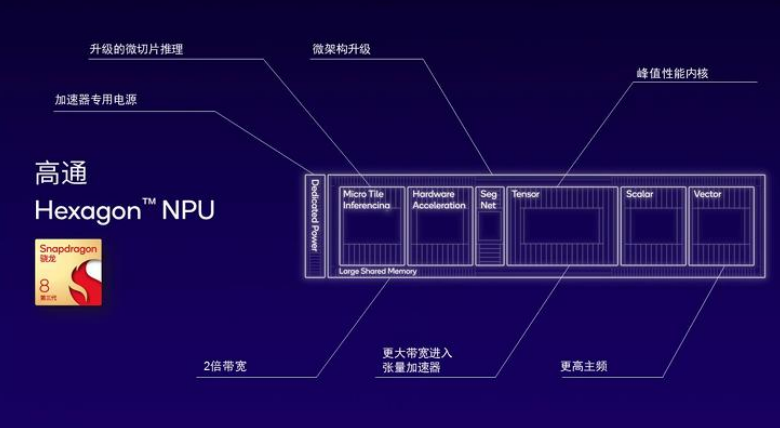
Ecological Control Power: The AI Stack toolchain supports TensorFlow Lite/ONNX/PyTorch across all frameworks, with downstream customers OPPO/Xiaomi/Honor relying on its NPU SDK to develop edge large model applications.
4.1.2 Apple: The Ceiling of Software-Hardware Integration
Vertical Integration Advantage: The M4 chip’s NPU is deeply integrated with the Metal API, and the Core ML framework optimization allows Stable Diffusion XL edge inference speed to reach 2.5 seconds/image (compared to Snapdragon 8 Gen3’s 4.1 seconds).
Closed Ecological Premium: In 2023, 210 million iOS devices equipped with NPUs were shipped, with developers required to pay a 30% “Apple Tax” to access NPU acceleration features (e.g., Adobe Firefly AI photo editing).
4.1.3 Intel: x86 Ecological Counterattack
Process Breakthrough: Intel’s 3-node mass production enables NPU4 to achieve an energy efficiency ratio of 6.4 TOPS/W, surpassing competitors using TSMC’s 4nm process (AMD XDNA2 at 5.8 TOPS/W).
Developer Alliance: The OpenVINO toolkit covers 87% of global industrial vision enterprises, compressing cloud PyTorch models to run on edge NPUs through transfer learning tools.
Intel NPU 4 VS NPU 3 Architecture

4.2 Domestic NPUs: From Technological Breakthroughs to Ecological Breakthroughs
4.2.1 Huawei Ascend: A Benchmark for Fully Autonomous and Controllable Technology
Da Vinci Architecture’s Hard Power:
| Parameter | Ascend 310 | Ascend 910 |
|---|---|---|
| MAC Array Scale | 64×64 | 128×128 |
| FP16 Computing Power | 16 TOPS | 320 TOPS |
| Energy Efficiency Ratio | 4 TOPS/W | 2.8 TOPS/W |
Scenario-based Implementation: Smart Cars: The MDC 810 computing platform is equipped with 4 Ascend 910 chips, supporting L4 level autonomous driving (GAC AION LX Plus implementation). Robots: Huawei’s AI robot “Cloud Ben” uses Ascend 310 to achieve real-time obstacle avoidance decision-making at the 20ms level.
Disassembly of Da Vinci Architecture Core
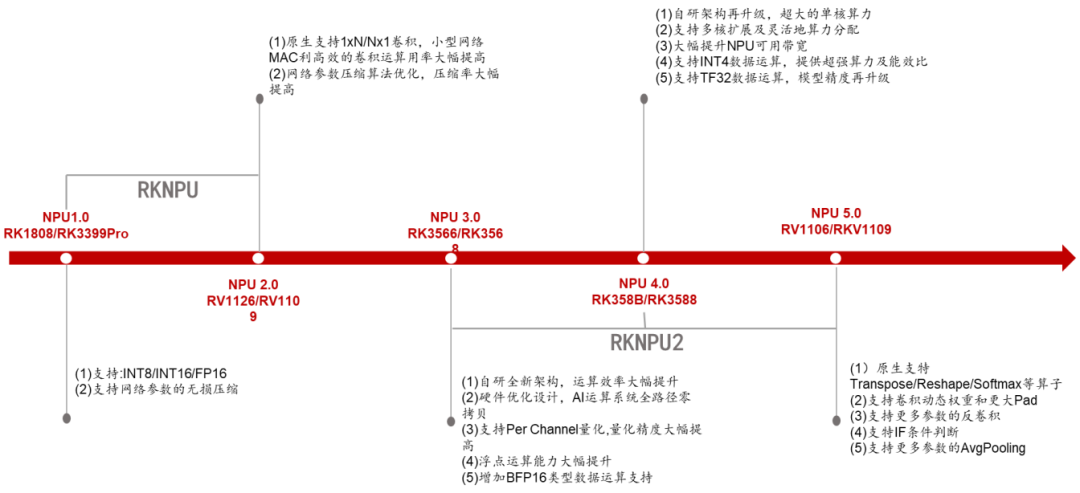
4.2.2 Rockchip: Pioneer in Democratizing Edge Computing Power
Technology Iteration Map:
| Generation | Computing Power (TOPS) | Architectural Innovation | Typical Products |
|---|---|---|---|
| RKNPU1.0 | 1 | Fixed-function acceleration core | RK3399Pro |
| RKNPU3.0 | 4 | Supports INT4 quantization / Dynamic voltage frequency adjustment | RK3568 |
| RKNPU4.0 | 6 | Multi-core expansion / Transformer operator library optimization | RK3588 |
Market Penetration: In 2023, AIoT devices equipped with RKNPU shipped over 12 million units, covering more than 20 sub-sectors including smart access control (Dahua), industrial cameras (Hikvision), etc.
Rockchip NPU Architecture Development History
4.2.3 Other Domestic Forces
Allwinner Technology: The T527 chip NPU supports 2 TOPS of computing power, entering the supply chain of Xiaotiancai watches through Alibaba’s Pingtouge authorized IP (2 million units shipped in 2023).
Cambricon: The Siyuan 220 chip adopts a 7nm process, with 16 TOPS of computing power + 4MB of on-chip cache, used in BYD’s intelligent cockpit DLink 5.0 system.
Domestic Manufacturers Accelerate Edge NPU Layout
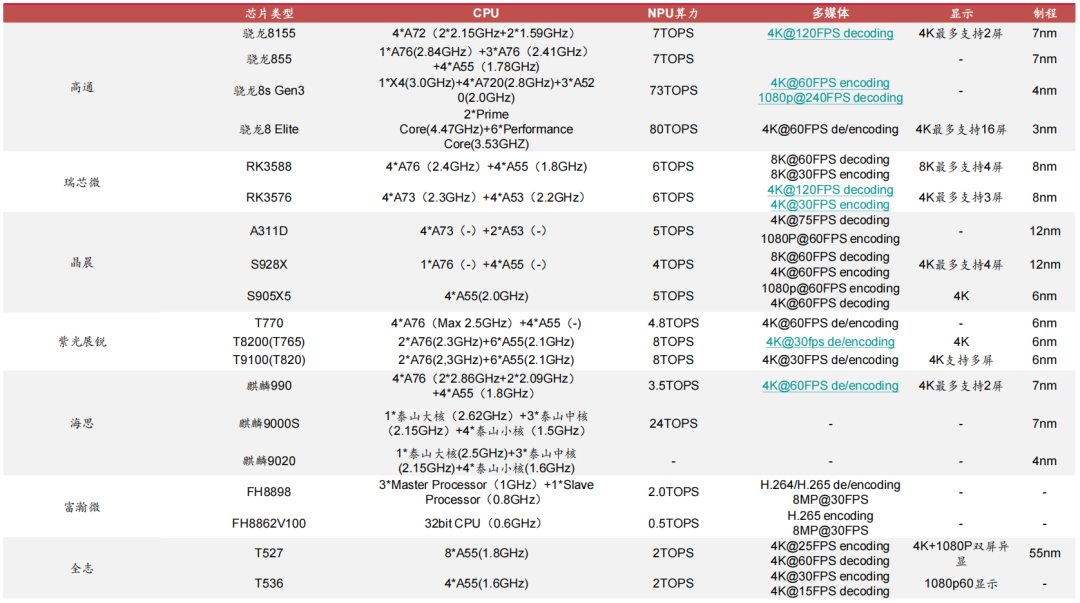
4.3 Discrete NPU: A Path to Differentiated Competition
4.3.1 International Camp
NXP Strategy: After acquiring Kinara, NXP launched the Ara-2 chip (40 TOPS), reducing the threshold for AI transformation of industrial equipment through a plug-and-play USB 4.0 solution (single module priced at $59).
Ara-2 connects to NXP FRDM* i.MX 95 to run LLaVA

Tesla’s Layout: The Dojo NPU adopts a 2.5D packaging integrating 12 self-developed D1 chips, improving training efficiency by 4.3 times compared to GPU clusters (revealed by Musk at 2023 AI Day).
4.3.2 Opportunities for Domestic Substitution
Industrial Automation: Horizon’s Sunrise 3 chip (5 TOPS) replaces NVIDIA’s Jetson Nano, reducing costs in AGV navigation systems by 60% (case study of Siasun Robotics).
Technical Challenges:
| Indicator | International Leading Level | Domestic Level (2024) | Gap Analysis |
|---|---|---|---|
| Computing Power Density | 8 TOPS/mm² (Qualcomm) | 2.5 TOPS/mm² (Ascend) | Process Limitations (7nm vs 3nm) |
| Toolchain Completeness | 100+ Pre-trained Models | 30+ Model Adaptations | Weak Developer Ecosystem |
| Memory Subsystem | 256bit LPDDR5X | 128bit LPDDR4X | Bandwidth Bottleneck |
4.4 Feasibility Roadmap for Domestic Substitution
4.4.1 Short-term Strategy (2024-2026)
IP Authorization Breakthrough: Chipone collaborates with the Chinese Academy of Sciences to develop the NPU-V3 architecture, supporting dynamic sparse computing (Huawei/Rockchip have already purchased authorization).
Scene Focus: Concentrate on tackling policy-protected markets such as security (Hikvision/Dahua) and educational hardware (BuBuGao) to build a stronghold.
4.4.2 Long-term Challenges (2027-2030)
Advanced Process: SMIC’s N+2 process mass production supports the target of 5 TOPS/mm² computing power density.
Standard Setting: The Ministry of Industry and Information Technology leads the formulation of “Edge NPU Computing Architecture Standards” to break the reliance on ARM instruction sets.
5. Future Trends and Outlook
5.1 Technological Evolution: From Dedicated Acceleration to General Intelligence
5.1.1 Paradigm Upgrade of NPU Architecture
Computing Power Density Leap: From 2025 to 2030, NPU computing power is expected to increase at an annual growth rate of 45% (TechInsights), with processes below 3nm driving the TOPS/mm² metric from the current 0.8 to 3.5 (compared to GPU’s 1.2).
Dynamic Reconfigurable Design: An open-source NPU architecture based on the RISC-V instruction set (e.g., Alibaba’s Xuantie C930) supports runtime reconfiguration of MAC arrays, achieving multi-modal compatibility for CNN/Transformer/SNN (spiking neural networks), with hardware utilization rates exceeding 90% (MIT experimental validation).
5.1.2 Industrialization of Compute-Storage Integration Technology
3D DRAM Large-scale Implementation: By 2026, the global 3D stacked DRAM market is expected to reach $8.2 billion (Yole forecast), with NPU+3D DRAM solutions penetrating over 30% in smartphones (currently <5%).
Mixed Precision Computing Breakthrough: Intel’s Lunar Lake NPU supports FP8/INT4 mixed precision, improving energy efficiency ratio for large model edge inference by 3 times (12 TOPS/W→36 TOPS/W).
5.2 Market Explosion: The Trillion-Dollar Edge AI Ecosystem
5.2.1 Core Track Growth Forecast
| Application Area | 2024 Scale (Billion USD) | 2028 Scale (Billion USD) | CAGR | Driving Factors |
|---|---|---|---|---|
| GenAI Smartphones | 12 | 91 | 65% | Widespread adoption of edge agents, multi-modal interaction |
| AI PCs | 8 | 52 | 59% | Localization of personal large models, privacy compliance |
| Smart Cars | 4.5 | 38 | 71% | Iteration of L3+ autonomous driving algorithms, cabin-driving integration |
| Industrial Robots | 2.8 | 21 | 68% | Flexible manufacturing demand, acceleration of domestic substitution |
5.2.2 Disruptive Opportunities in Emerging Scenarios
Spatial Computing Terminals: Apple’s Vision Pro 2 will feature a dual-chip M4+NPU, achieving 6DoF gesture recognition latency <5ms (current model 15ms), with a shipment target of 20 million units in 2026.
Ubiquitous AIoT: Rockchip RK3576 chip (6 TOPS) drives the penetration rate of NPU in smart home devices from 12% (2023) to 55% (2027), activating the value of home edge computing nodes.
5.3 Domestic Substitution: From Supply Chain Security to Technology Export
5.3.1 Rise of Autonomous Technology Standards
Instruction Set Breakthrough: Huawei’s Da Vinci architecture NPU instruction set has been included in the China Electronics Standardization Institute’s “Technical Specifications for Edge AI Chips”, covering over 85% of domestic AIoT devices.
Ecological Alliance Formation: The combination of Ascend + MindSpore + Euler OS has achieved a market share of 67% in government cloud (IDC 2024Q2), building a domestic AI foundation for edge and cloud integration.
5.3.2 Global Breakthrough Pathways
Emerging Market Substitution: Rockchip RK3588 has entered the Indian security market through OpenCV optimization, with shipments exceeding 4 million units in 2023 (29% market share).
Automotive-grade Export: Horizon Journey 5 chip has received orders from Southeast Asian automotive companies (VinFast/Proton), with L2+ level ADAS solutions costing 40% less than Mobileye.
5.4 Risks and Challenges
5.4.1 Technological Cliff Effect
International giants’ 2nm GAA process NPU energy efficiency ratio is expected to reach 15 TOPS/W (TSMC roadmap), while domestic 14nm process (SMIC N+2) gap widens to over 3 times.
5.4.2 Geopolitical Games
New US BIS regulations restrict the export of EDA tools below 14nm to China, causing Huawei’s Ascend 910B production yield to drop to 65% (originally 75%), compressing the window for domestic substitution.
5.4.3 Structural Demand Differentiation
Consumer electronics edge AI penetration exceeds expectations (2024 smartphone NPU adoption rate 78%), but industrial edges lag in substitution progress due to fragmented standards (penetration rate only 19%).