Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., … & Duchesnay, É. (2011). Scikit-learn: Machine learning in Python. the Journal of machine Learning research, 12, 2825-2830.
Abstract Scikit-learn is a Python module that integrates a variety of advanced machine learning algorithms for medium-scale supervised and unsupervised learning problems. The toolkit aims to bring machine learning to non-specialists through a general-purpose high-level programming language. Its development focuses on usability, performance, documentation quality, and API consistency. Scikit-learn has minimal dependencies and is released under a simplified BSD license, encouraging its widespread use in academia and industry. Source code, binaries, and documentation can be downloaded from http://scikit-learn.sourceforge.net.
Introduction
The Python programming language is gradually becoming one of the most popular languages in the field of scientific computing. Thanks to its high-level, interactive features and an increasingly mature ecosystem of scientific computing libraries, it is highly attractive for algorithm development and exploratory data analysis (Dubois, 2007; Milmann and Avaizis, 2011). However, as a general-purpose language, Python’s use cases are increasingly extending beyond academic environments and are widely adopted in industry.
Scikit-learn leverages this rich environment to provide advanced implementations of many well-known machine learning algorithms while maintaining a tightly integrated and user-friendly interface with the Python language. This meets the growing demand for statistical data analysis among non-specialists in the software and web industries, as well as related needs in fields outside of computer science, such as biology and physics. Scikit-learn differs from other machine learning toolboxes in Python in several ways:
i) It is released under the BSD license;
ii) It introduces compiled code for efficiency, unlike MDP (Zito et al., 2008) and pybrain (Schaul et al., 2010);
iii) It relies only on numpy and scipy, making it easy to distribute, unlike pymvpa (Hanke et al., 2009), which has optional dependencies like R and shogun;
iv) It focuses on imperative programming, while pybrain adopts a data flow framework. Although the package is primarily written in Python, it integrates C++ libraries LibSVM (Chang and Lin, 2001) and LibLinear (Fan et al., 2008), providing reference implementations of SVM and generalized linear models under compatible licenses. Its binary packages are available on various platforms, including Windows and any POSIX platform. Additionally, due to its permissive license, it has been widely distributed as part of major free software distributions, such as Ubuntu, Debian, Mandriva, NetBSD, and Macports, as well as commercial distributions like “Enthought Python Distribution.”
Project Vision
Code quality. Compared to simply piling on features, the project’s goal is to provide solid and reliable implementations. Code quality is ensured through unit testing—version 0.8 has a test coverage of 81%—and supplemented by static analysis tools such as pyflakes and pep8. Finally, we strive for consistency in function and parameter naming while strictly adhering to Python coding standards and numpy style documentation.
BSD licensing. Most projects in the Python ecosystem adopt non-copyleft licenses. While such strategies facilitate the adoption of these tools in commercial projects, they also impose certain limitations: for example, we cannot use certain existing scientific computing codes, such as GSL.
Bare-bone design and API. To lower the barrier to use, we avoid framework-style code and try to keep the variety of different object types to a minimum, relying on numpy arrays for data containers. Community-driven development. We conduct development work based on collaborative tools such as git, github, and public mailing lists, welcoming and encouraging external contributions.
Documentation. Scikit-learn provides approximately 300 pages of user guides, including narrative documentation, class references, tutorials, installation instructions, and over 60 examples, some of which come from real application scenarios. We strive to minimize the use of machine learning terminology while maintaining rigor and accuracy in the descriptions of the algorithms employed.
Underlying Technologies
Numpy: The foundational data structure for data and model parameters. Input data is provided in the form of numpy arrays, allowing seamless integration with other scientific computing Python libraries. Numpy’s view-based memory model also reduces copy overhead when bound to compiled code (Van der Walt et al., 2011). It also provides basic arithmetic operations.
Scipy: Provides efficient algorithms for linear algebra, sparse matrix representation, special functions, and basic statistical functions. Scipy binds many standard numerical computing libraries based on Fortran, such as LAPACK. This is crucial for simplifying installation and enhancing portability, as directly wrapping Fortran code into libraries can be quite tricky across different platforms.
Cython: A tool for combining C language with Python. Cython allows for achieving near-compiled language performance while retaining Python-like syntax and high-level operations. It is also used to bind compiled libraries, thus relieving the burden of writing extensive Python/C extension boilerplate code.
Code Design
Specify objects through interfaces rather than inheritance. To facilitate the use of external objects in scikit-learn, the framework does not enforce inheritance relationships but provides a consistent interface through code conventions. The core object is the estimator, which implements a fit method that takes an input data array as a parameter and optionally a label array for supervised problems. Supervised estimators (such as SVM classifiers) can implement a predict method. Some estimators (which we call transformers, such as PCA) implement a transform method to return modified input data. Estimators can also provide a score method to give a monotonic evaluation metric of goodness of fit: for example, log-likelihood or the negative of a loss function. Another important object is the cross-validation iterator, which provides index pairs for training and testing sets to split input data, such as K-fold, leave-one-out, or stratified cross-validation.
Model selection. Scikit-learn can use cross-validation to evaluate the performance of estimators or perform parameter selection, optionally distributing the computation across multiple cores. This is achieved by wrapping the estimator in an object called GridSearchCV, where “CV” stands for “cross-validated.” When calling fit, it selects parameters on a specified parameter grid to maximize a scoring metric (i.e., the score method of the underlying estimator). Subsequent calls to predict, score, or transform will be delegated to the tuned estimator. Therefore, this object can transparently be treated as any other estimator in use. For certain estimators, cross-validation can be made more efficient by leveraging their specific properties (such as warm restart or regularization paths, Friedman et al., 2010), supported by special objects like LassoCV. Finally, the Pipeline object can combine multiple transformers and an estimator into a joint estimator, for example, performing dimensionality reduction before fitting. Its behavior is the same as a standard estimator, so GridSearchCV can also tune parameters across various steps simultaneously.
High-level yet efficient: some trade-offs
Although scikit-learn emphasizes ease of use and is primarily written in high-level languages, it has also been carefully designed to maximize computational efficiency. In Table 1, we compare the computation times of several algorithms implemented in major Python machine learning toolboxes. We used the Madelon dataset (Guyon et al., 2004), which contains 4400 samples and 500 features; this dataset is large enough for most algorithms to run.
Table 1: Running times (in seconds) of various machine learning libraries provided by Python on the Madelon dataset: MLPy (Albanese et al., 2008), PyBrain (Schaul et al., 2010), pymvpa (Hanke et al., 2009), MDP (Zito et al., 2008), and Shogun (Sonnenburg et al., 2010). More benchmark results can be found at http://github.com/scikit-learn
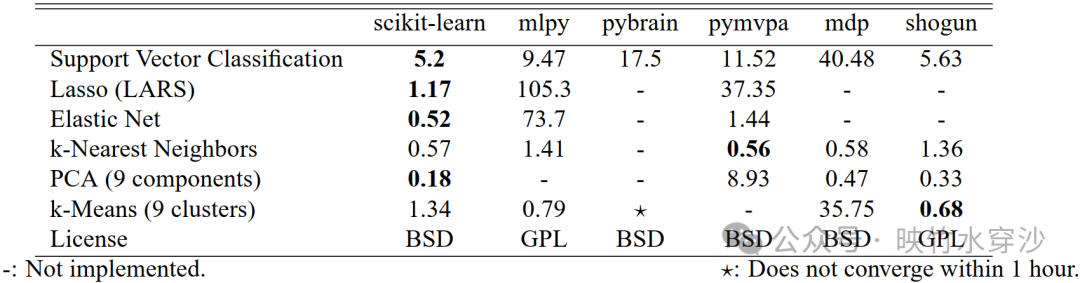
SVM. Although all packages involved in the comparison call libsvm in the background, the performance of scikit-learn can be explained by two factors. First, our binding avoids memory copies, reducing overhead by up to 40% compared to the original libsvm Python binding. Second, we patched libsvm to improve its efficiency on dense data, reduce memory usage, and better utilize modern processors’ memory alignment and pipelining capabilities. This patched version also provides certain unique features, such as setting weights for individual samples.
LARS. By iteratively updating residuals instead of recalculating them each time, we achieve a performance improvement of 2–10 times compared to the R reference implementation (Hastie and Efron, 2004). Pymvpa uses this implementation through Rpy’s R binding, but incurs a high cost in memory copies as a result.
Elastic Net. We benchmarked the coordinate descent-based Elastic Net implementation in scikit-learn. It achieves performance on medium-scale problems comparable to the highly optimized Fortran version glmnet (Friedman et al., 2010), but its performance on very large-scale problems is limited because we do not use KKT conditions to define an active set.
kNN. The implementation of the k-nearest neighbors classifier builds a ball tree (Omohundro, 1989) for samples but uses a more efficient brute-force search in high-dimensional cases.
PCA. For medium to large-scale datasets, scikit-learn provides a truncated PCA implementation based on random projection (Rokhlin et al., 2009).
k-means. The k-means algorithm in scikit-learn is entirely implemented in Python, and its performance is limited by the fact that numpy’s array operations require multiple passes over the data.
Conclusion
Scikit-learn provides a wide variety of machine learning algorithms in a consistent, task-oriented interface, including both supervised and unsupervised learning methods, making it easier to compare different methods for a given application. Because it relies on the scientific computing Python ecosystem, it can be easily integrated into applications beyond traditional statistical data analysis. Importantly, these algorithms implemented in high-level languages can serve as building blocks for methods tailored to specific use cases, such as applications in medical imaging (Michel et al., 2011). Future work includes online learning to scale to larger datasets.
Copyright belongs to the original author, and the article is for learning and communication purposes.