In the field of medical image analysis, segmentation is a crucial task that involves identifying and delineating different structures or lesion areas from medical images. The segmentation results not only assist doctors in making accurate diagnoses but also provide important references for subsequent clinical decision-making and treatment planning. To enhance the reliability of the segmentation gold standard, it is common to collect annotations from multiple experts (Figure 1[1]). However, the differences in annotations from different experts lead to what is known as the “multi-rater problem”[2,3]. Just like several people looking at the same painting, they may depict different outlines of the same object. This issue is particularly severe in areas where boundaries are ambiguous or lesions are complex. How can we effectively integrate the opinions of multiple annotators amidst the “diverse opinions” to extract the most reliable result? This is a challenge that traditional deep learning models struggle to address.
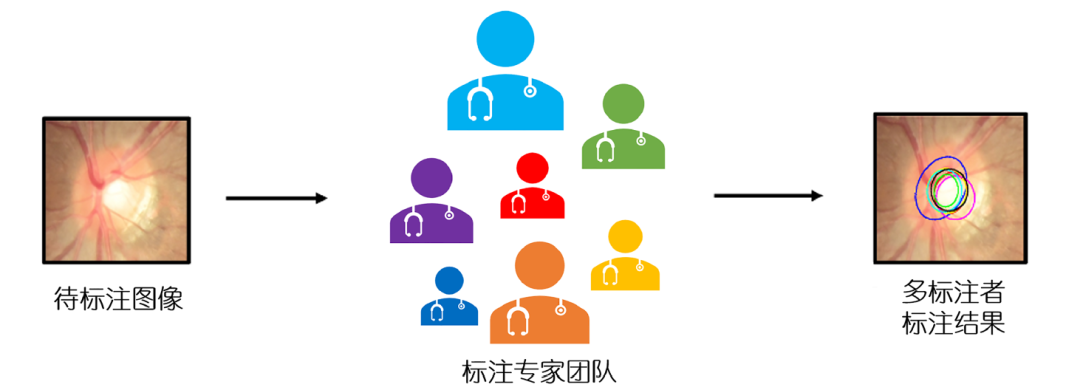
Figure 1 Multi-rater problem[1]. An example of multi-rater annotations of the optic cup in fundus photographs, showing significant internal deviations between annotations.
Previous researchers have primarily approached the “multi-rater problem” from two perspectives. The first method involves learning to calibrate segmentation results to reflect the differences in annotations among different observers, allowing the model to learn the potential consistencies or discrepancies between multiple expert annotations[4~6]. However, this method requires accurate credibility information about the annotations from different observers. The second method aims to identify potential correct true annotations from multi-rater labels, assessing the confidence of each annotator and merging labels through weighted averaging[7,8]. The limitation of this method is that it does not calibrate when learning to merge labels, which may lead to overconfidence[8,9] or ambiguous results[10,11].
This research team proposes a new multi-rater prism framework[1] (hereinafter referred to as “MrPrism”) to address the “multi-rater problem”. It combines the tasks of “calibrating segmentation” and “assessing expert credibility”, iteratively promoting both to ultimately find a result that is both accurate and reflects expert consensus. This framework employs an iterative optimization approach, integrating the allocation of multi-rater confidence and the calibration segmentation task, ultimately generating a self-calibrated segmentation result that reflects inter-observer consistency.
In the overall process, MrPrism first extracts deep feature representations of medical images through convolutional neural networks and constructs a unified feature embedding space. Based on this, it introduces multi-rater label information as dynamic variables, achieving collaborative optimization of segmentation calibration and expert credibility modeling through a dual prism structure. This process uses the predicted segmentation mask as an intermediary variable, gradually approaching the optimal solution that satisfies both image semantic consistency and multi-rater consensus. The framework continuously updates through a recursive mechanism, ultimately achieving joint convergence of segmentation results and confidence distribution.
As shown in Figure 2, the core of MrPrism lies in two complementary modules: the converging prism (ConP) and the diverging prism (DivP). These two modules work together to optimize the segmentation results.
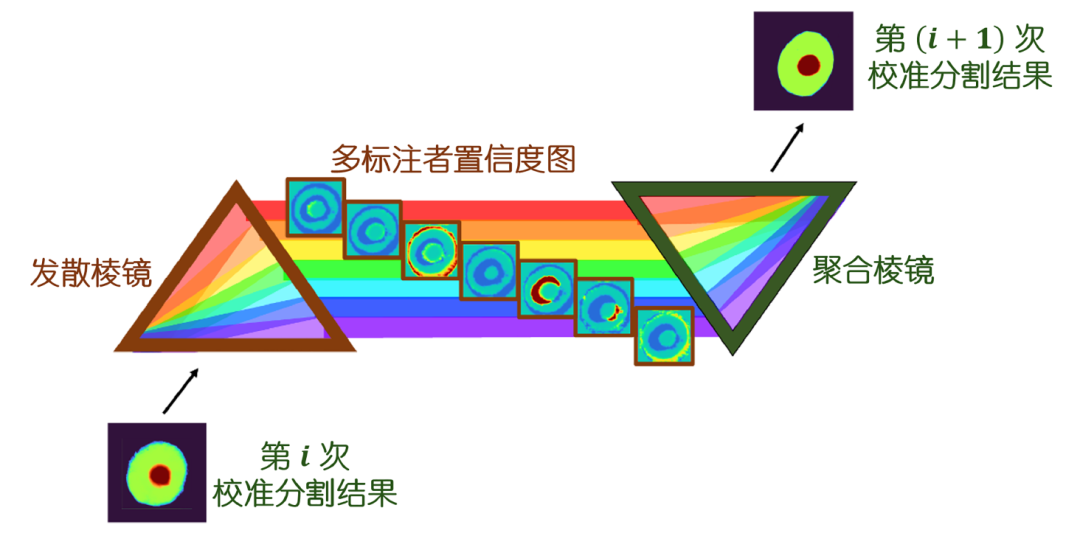
Figure 2 Multi-rater Prism framework[1]
First, the DivP module analyzes the preliminary segmentation results provided by ConP, using advanced multi-head attention mechanisms to assess the credibility of each expert’s annotations and dynamically generate weights; then, the ConP module selectively integrates the medical image features based on these weights through attention mechanisms, outputting more accurate segmentation results. This iterative optimization process is akin to repeated discussions in an expert consultation, where after several rounds of iterations, the system can automatically balance the opinions of different experts, ultimately generating a precise segmentation that conforms to both the anatomical structure of the image and reflects expert consensus.
This iterative design inspiration comes from the “semi-quadratic optimization” theory in mathematics[12]. The research team implemented these two modules using vision transformer technology[13]. ConP integrates image features and credibility information using attention mechanisms, while DivP evaluates each expert’s annotations through multi-head attention mechanisms. Experiments have shown that this “dual prism” strategy can gradually improve accuracy through multiple iterations, especially excelling in tasks with significant discrepancies among expert opinions.
To validate the effectiveness of MrPrism, the team tested it on various medical image segmentation tasks, including optic disc/cup segmentation in fundus images (REFUGE[14] and RIGA[15] datasets), brain tumor segmentation (QU-BraTS 2020[16] and QUBIQ-BrainTumor[17] datasets), prostate segmentation (QUBIQ-prostate[17] dataset), brain development segmentation (QUBIQ-BrainGrowth[17] dataset), and kidney segmentation (QUBIQ-kidney[17] dataset). These datasets cover different organs and diseases, involving various scenarios with differing degrees of inter-annotator variability, providing ample basis for assessing the adaptability and stability of MrPrism in complex annotation environments.
The segmentation results of various methods on the aforementioned tasks are shown in Figure 3. The comparative methods include AggNet[10], CL[8], CM[9], MaxMig[11], MRNet[3], and WDNet[5]. As can be seen from the figure, MrPrism performs excellently, surpassing the current state-of-the-art methods in all tasks. For instance, in the optic cup segmentation task, when there is significant disagreement among experts, traditional methods may only achieve around 85% accuracy (measured by the Dice coefficient), while MrPrism can improve accuracy to over 88% after three iterations. Similarly, in brain tumor segmentation, it significantly outperforms other strategies, especially in areas with ambiguous boundaries, accurately delineating tumor contours. More importantly, MrPrism demonstrates the ability of “self-calibration”. Experiments show that as the number of iterations increases, the segmentation results gradually stabilize, reflecting its ability to dynamically adapt to the characteristics of different tasks. When there is little disagreement among experts, it can balance opinions; when a few experts are clearly more accurate, it can identify and prioritize these opinions. This flexibility makes it more promising for practical applications.
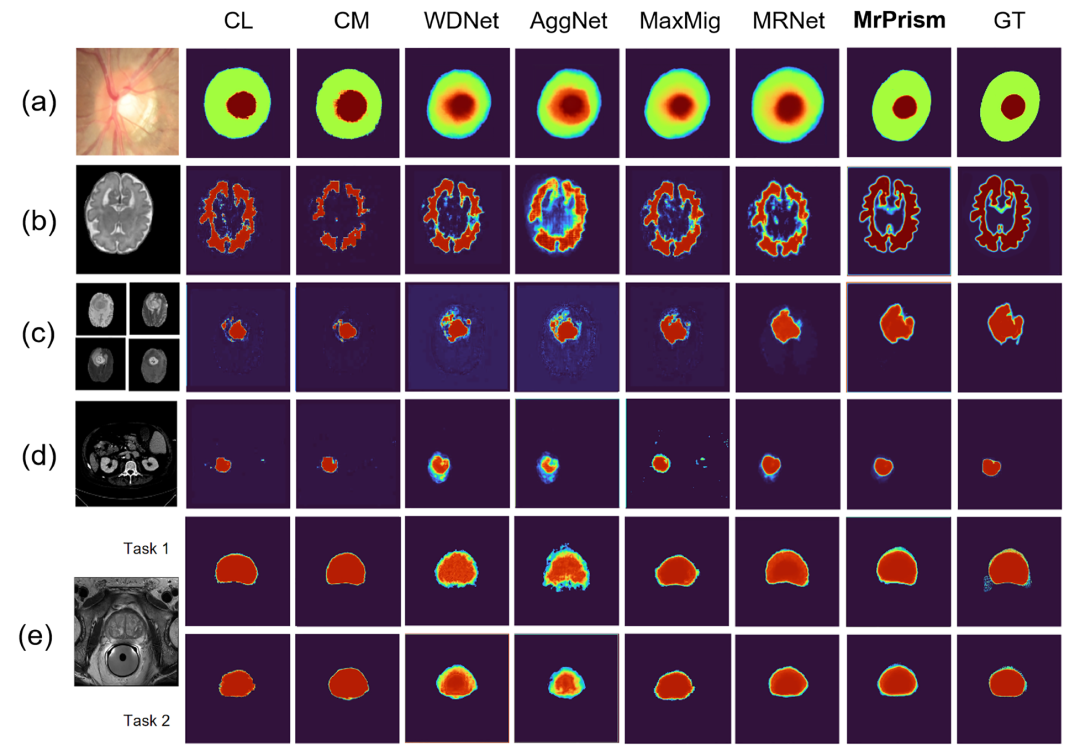
Figure 3 Comparison of segmentation results of MrPrism and comparative methods including AggNet[10], CL[8], CM[9], MaxMig[11], MRNet[3], and WDNet[5]. GT is the segmentation gold standard. (a) Optic cup and disc segmentation task in fundus photographs; (b) Brain tissue segmentation task in brain development MRI dataset; (c) Brain tumor segmentation task in brain MRI dataset; (d) Left kidney segmentation task in CT images; (e) Prostate gland segmentation task in prostate MRI data.
The introduction of the MrPrism framework provides a new perspective for medical image segmentation. It abandons the traditional pursuit of a single “standard answer” and instead seeks to obtain a more reliable consensus by modeling the discrepancies among experts; additionally, within this framework, the system can automatically assess the credibility of each expert’s annotations, avoiding the cumbersome task of manually assigning weights; most importantly, MrPrism incorporates image structural information into the learning process (through attention mechanisms), making the segmentation results more anatomically accurate. Whether screening for glaucoma or segmenting brain tumors, the MrPrism framework can help computers “understand” medical images more intelligently. For patients and doctors, this means a more reliable auxiliary diagnostic tool. The related research results have been published in Science Bulletin[1], and the code for this work has been open-sourced at https://github.com/WuJunde/MrPrism, welcoming relevant professionals to follow and use it.
The team plans to further expand the application scope of this framework, exploring its adaptability in more medical image modalities (such as tongue images, pathological slices, and dynamic ultrasound sequences), and promoting deep integration with clinical decision systems to support end-to-end optimization of diagnostic and treatment processes. At the same time, the team also plans to design lightweight models for scenarios with insufficient medical resources, allowing this technology to benefit a wider range of medical institutions. From “diverse opinions” to “precise annotations”, MrPrism illuminates a new direction for the clinical value of medical images with the “dual prism” of AI.
References

[1] Wu J, Fang H, Zhu J, et al. Multi-rater Prism: learning self-calibrated medical image segmentation from multiple raters. Chin Sci Bull , 2025 , 69: 2906 -2919
[2] Warrens M J. Inequalities between multi-rater kappas. Adv Data Anal Classif , 2010 , 4: 271 -286
[3] Ji W, Yu S, Wu J, et al. Learning calibrated medical image segmentation via multi-rater agreement modeling. In: Proceedings of the 34th IEEE Conference on Computer Vision and Pattern Recognition, 2021. Vancouver, 2021. 12341–12351.
[4] Wu J, Fang H, Yang D. et al. Opinions vary? Diagnosis first! In: Proceedings of the 25th International Conference on Medical Image Computing and Computer-Assisted Intervention, 2022. Singapore, 2022. 604–613.
[5] Guan M Y, Gulshan V, Dai A M, et al. Who said what: modeling individual labelers improves classification. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence, 2018. New Orleans, 2018. 2668–3603.
[6] Chou H C, Lee C C. Every rating matters: joint learning of subjective labels and individual annotators for speech emotion classification. In: Proceedings of the 44th IEEE International Conference on Acoustics, Speech and Signal Processing, 2019. Brighton, 2019. 5886–5890.
[7] Warfield S K, Zou K H, Wells W M. Simultaneous truth and performance level estimation (STAPLE): an algorithm for the validation of image segmentation. IEEE Trans Med Imag , 2004 , 23: 903 -921
[8] Rodrigues F, Pereira F. Deep learning from crowds. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence, 2018. New Orleans, 2018. 1611–1618.
[9] Tanno R, Saeedi A, Sankaranarayanan S, et al. Learning from noisy labels by regularized estimation of annotator confusion. In: Proceedings of the 32nd IEEE conference on Computer Vision and Pattern Recognition, 2019. Long Beach, 2019. 11244–11253.
[10] Albarqouni S, Baur C, Achilles F, et al. AggNet: deep learning from crowds for mitosis detection in breast cancer histology images. IEEE Trans Med Imag , 2016 , 35: 1313 -1321
[11] Cao P, Xu Y, Kong Y, et al. MaxMig: an information theoretic approach for joint learning from crowds. In: Proceedings of the 7th International Conference on Learning Representations, 2019. New Orleans, 2019.
[12] Geman D, Reynolds G. Constrained restoration and the recovery of discontinuities. IEEE Trans Pattern Anal Machine Intell , 1992 , 14: 367 -383
[13] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: transformers for image recognition at scale. In: Proceedings of the 9th International Conference on Learning Representations, 2021. Vienna, 2021.
[14] Orlando J I, Fu H, Barbosa Breda J, et al. REFUGE Challenge: a unified framework for evaluating automated methods for glaucoma assessment from fundus photographs. Med Image Anal , 2020 , 59: 101570
[15] Almazroa A, Alodhayb S, Osman E, et al. Agreement among ophthalmologists in marking the optic disc and optic cup in fundus images. Int Ophthalmol , 2017 , 37: 701 -717
[16] Mehta R, Filos A, Baid U, et al. QU-BraTS: MICCAI BraTS 2020 challenge on quantifying uncertainty in brain tumor segmentation – analysis of ranking scores and benchmarking results. Melba , 2022 , 1: 1 -54
[17] Li H B, Navarro F, Ezhov I, et al. QUBIQ: uncertainty quantification for biomedical image segmentation challenge. 2024, arXiv: 2405.18435.

Welcome to share in your circle of friends
For reprints and submissions, please leave a message
Long press the QR code to follow us| Follow Science Bulletin | Understand the frontiers of science 
