This article is organized from NVIDIA’s 2024 GTC lecture.
Now, let’s dive deep into our Jetson platform. These are our Jetson Orin modules, and we have seven different modules covering the entire range from entry-level to high performance. The best part is that, unlike before, we have adopted a SOC (System on Chip) architecture across the entire product line for the first time. From entry-level to high performance, all are based on the same architecture, making the products more scalable and easier to transfer from one module to another.
So what does this architecture contain? The Orin SOC includes an Ampere GPU and an Arm A78 CPU, with some modules also featuring specific accelerators. We have deep learning accelerators, programmable vision accelerators, and video image synthesizers. Don’t worry, I will detail the roles of these accelerators in the upcoming slides.
There are also two different form factors. If you look at the top of this slide, we have a larger size of 100×87 mm, as well as credit card-sized modules. Even better, from Orin Nano to Orin NX, these modules have form factor and pin compatibility, meaning you can use one carrier board to support any of these four modules. Similarly, for AGX Orin and AGX Orin Industrial, they are also form factor and pin compatible, allowing you to use one carrier board to support all four modules.
Regarding their differences, they are all based on the same SOC architecture. However, they differ in the number of GPU cores, CPU cores, some accelerators, and IO. Therefore, the smaller SoDIMM has specific IO, which I will introduce in a few slides, while the AGX Orin features ten 10 Gigabit Ethernet ports, up to 22 PCIe lanes, and some other IO, which I will describe in the upcoming content.
So how do you decide which module is suitable for your application? It actually depends on some key questions. Jetson is designed for sensor fusion and aggregation. First, what type of sensors do you need to connect to the device? Secondly, what does your workload look like? Are you trying to run some generative AI? Are you attempting some computer vision tasks? What do you plan to deploy on the device, which can actually define your computing requirements? Therefore, from the performance range of 20 to 40 TOPS of Orin Nano to the maximum of 275 TOPS of AGX Orin, any of these devices can meet your needs depending on the size of your workload.
Another common question we receive is about your size or power consumption requirements, which is why we have many different modules so you can have a solution that fits your needs. You will see that the power budget for Orin Nano is 10 to 15 watts, while AGX Orin can reach 60 watts. For example, you might have a drone application where power consumption is critical; in that case, Orin Nano or Orin NX may be beneficial considering power, weight, and size. For AGX Orin, which requires larger generative AI models, additional computing resources are available. Another point I want to emphasize is that we not only have these different modules but also have made significant performance optimizations on the software side. For those unfamiliar, we have something called MLPerf, which is a standard organization responsible for running a suite of machine learning benchmarks. From our previous generation Jetson AGX Xavier to our latest generation Jetson Orin, we have not only optimized for computation but also lead in models, enabling us to run all machine learning models on Jetson.

So what exactly does the Jetson AGX Orin series include? The Jetson AGX Orin module has a form factor of 100×87 mm. One thing I want to point out is that this chart shows the SOC on the module and some other components, but does not show the TTP, so you can see what is inside the module. However, our AGX Orin module is actually equipped with something called a thermal transfer plate. This makes it very easy for you to develop thermal solutions on it, as most of the thermal requirements are handled by that TTP. At the bottom of the module, you can see a 699-pin connector. So you will basically connect this module to a carrier board, and in our development kit, it actually comes with a carrier board plus the module and a heatsink, so you can get started right away. What’s inside the module? So as mentioned earlier, there is an Ampere GPU in Orin, and in AGX Orin, it has up to 2048 cores and up to 64 tensor cores. In terms of CPU, its core count varies from 8 to 12 in the Orin series, along with some accelerators. There is a programmable vision accelerator that can be used to run computer vision algorithms. There is a deep learning accelerator so you can run deep learning algorithms on the GPU, freeing up the GPU and CPU for more compute-intensive tasks. From a multimedia standpoint, there is an optical flow accelerator that can offload optical flow and some stereo disparity demands, along with AJPEG, and an encoder and decoder depending on your requirements for encoding and decoding some camera streams. This slide shows a lot of content, but I want to emphasize all the modules so you know what the architecture specifically contains.
Another point I want to discuss is that Orin has shared memory. So you can see the memory controller structure, with all the CPU and GPU using the same architecture. Now in the gray area at the bottom of the slide, you can see all the different IO; from a high-speed IO perspective, we support PCIe, ten Gigabit Ethernet, and USB 3.2 A. From a display perspective, there is HDMI and DP, with up to 16 CSI channels, and many sensor IOs like I2C, CAN, GPIO, etc.
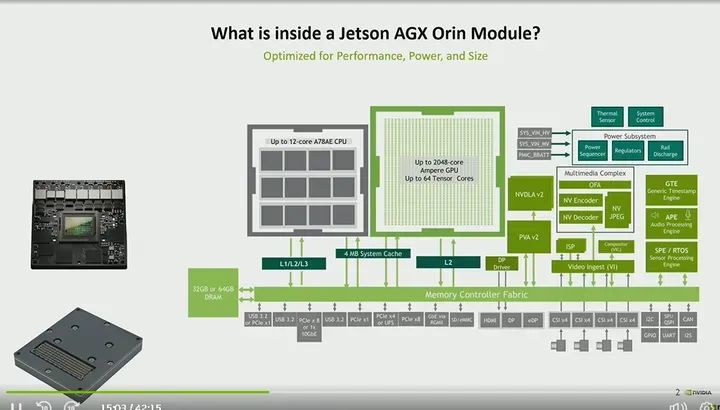
What are the internal differences between the Orin NX module and AGX Orin? The main differences lie in architecture, the number of GPU cores, CPU cores, and accelerators. Therefore, the Orin NX module is equipped with deep learning and vision accelerators, while the Orin Nano module does not. From an IO perspective, because Orin Nano uses a 260-pin SoDIMM form factor, there are some different PCIe lane counts and other IO, as you can see here. Therefore, it will continue to support PCIe, sensor IO, USB, ACSI, etc. The best part is that Orin Nano and Orin NX are compatible in form factor and pin, meaning you can use one carrier board to support all of them.
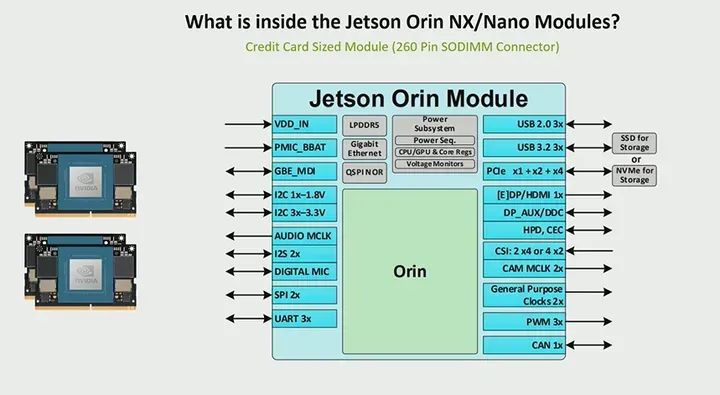
So, what are some of the accelerators I mentioned earlier? Here, you can see we have a deep learning accelerator, which is a fixed-function accelerator that can be used to run some deep learning workloads. We have various documents explaining which layers can be ported to this deep learning accelerator, which is ideal for use cases that require significant AI and want to offload it so that the GPU has more computational resources. Similarly, the programmable vision accelerator can also be utilized, and I will explain an example on the right side of the slide showing how we use some accelerators for this offloading. So, this PVA, these are bidirectional vector processing units that can support some computer vision algorithms, and then there is a video image synthesizer for certain image processing functions. An ISP was also shown in the previous chart. So what is an example of using these accelerators? This actually comes from an example of our Metropolis microservices I mentioned earlier, which is a set of APIs that help optimize various visual AI pipelines. So here, we take a very compute-intensive application and distribute it across the GPU, CPU, and accelerators. Therefore, if you look here, because we have distributed the application across different processors, you will free up the GPU and CPU, which were only using about 50% on AGX, 30% on Orin NX GPU, and 60% on CPU. This indeed leaves you with a lot of room to run other applications while also running this visual AI application on some accelerators. So what is actually running here? Basically, it runs a personnel detection model with sixteen channels and performs complex object tracking. Therefore, the output is four streams, and the input is 1080p30. So you can see that by utilizing these accelerators, you can indeed offload some computations, thereby freeing up the GPU and CPU.
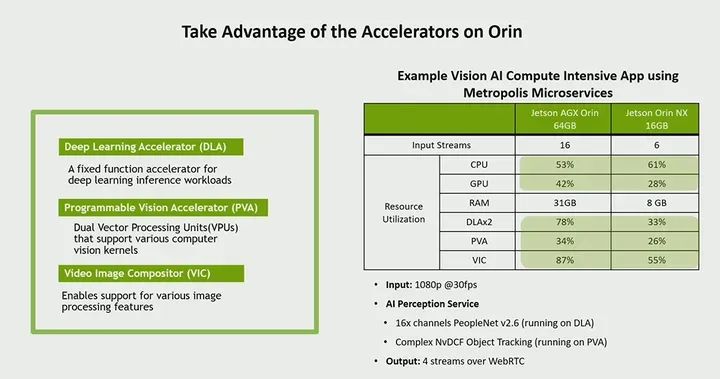
Let’s talk again about some generative AI and how to bring generative AI to the edge. Here, you can see our NVIDIA AGX Orin and some various generative AI models running on AGX Orin. Typically, generative AI models are known for their large size and the need for a lot of memory. However, through the optimizations we can perform, we are actually able to run these models at the edge, which is indeed a unique value proposition of our solution. You can see here the large language model using the common Llama2 7B, which we are able to achieve 43 tokens per second. Similarly, for some visual language models, we can achieve 42 on Llama2 7B and 22 on 13B. Moving to some visual transformer models, there are some like our Vision Transformer and Mobile Sam, Efficient VIT, etc. We are able to achieve very high throughput; you can see that Efficient VIT’s frame rate is 277 frames per second, putting it into perspective, typically 30 frames per second is real-time frame rate, so we can achieve real-time frame rates on these models, some even faster. Furthermore, from the perspective of Stable diffusion, we are also able to achieve some outstanding performance in terms of images per second.
What are some of the challenges people face and how does Jetson address these challenges? First is the difficulty in adapting models. We see that not everyone has strong deep learning expertise, so it is very important to support various types of models and be able to adjust and optimize them, which is why we focus on becoming this software-defined platform.
We support various types of models and frameworks, including Transformer models, which are very rare in edge platforms. Another issue is that sometimes people have different vertical domain needs. We talked about many of these applications, such as IVA and robotics, and besides running basic computations, there are different needs at the application layer. We have solutions, whether it is our Isaac Perceptor or our Isaac ROS, or in terms of vision, we have Metropolis microservices. You can use our solutions to run a complete end-to-end pipeline.
Another point we just discussed is that our development kits allow you to develop without having to go through sequential development cycles. You can develop in parallel. Your software team and hardware team can work together to develop solutions.
Another issue is how to get started after development is complete. This is where our partner ecosystem comes into play. They provide carrier boards, complete systems, as well as sensors and cameras, and they have done extensive development with Jetson to accelerate your time to market. Finally, custom hardware design resources. Sometimes, if you look at a complete embedded system, you will find that power architecture and memory architecture can take a lot of time from a development perspective. But it will also take up a lot of space on the board. Because we have a unique modular architecture, it eliminates this complexity. You do not have to worry about memory, and you do not have to worry about power design. All you need to do is to use this plug-and-play module to easily develop your solution.
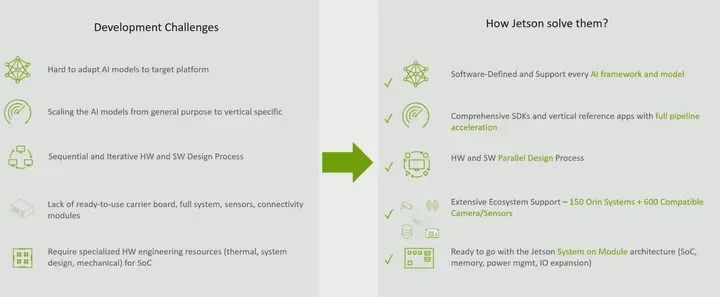
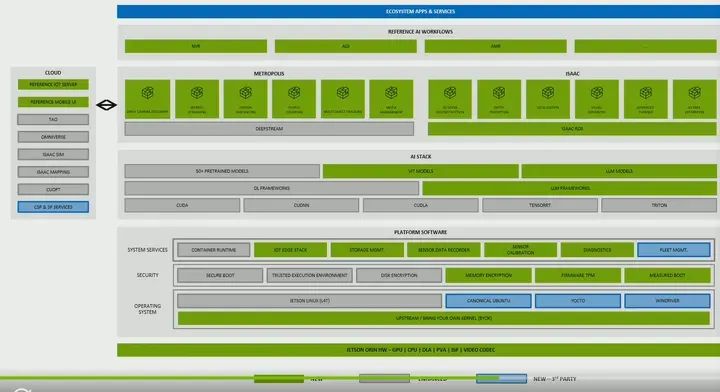
Jetson is a software-defined platform. We focus on providing you not just hardware but a complete end-to-end solution. So at the bottom of this slide, you see we showcase our hardware, and above that, we have our platform software, which includes your basic Linux operating system as well as security and some system services. On top of that, we have our AI stack, which allows you to leverage many other works NVIDIA is doing, which can now run at the edge. So whatever you are doing, you can now run it at the edge. Then on top of that, you have your vertical-specific needs, whether it’s Metropolis for intelligent video analysis or Isaac for robotics. We have various APIs to help accelerate your development.
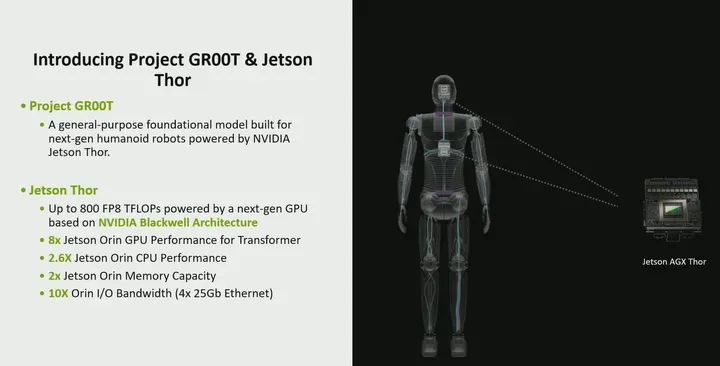
The GROOT project is a general-purpose foundational model designed for the next generation of humanoid robots. As we mentioned at the beginning, we do see a significant increase in the demand for humanoid robots. Therefore, more computing power and more customized software are needed, and you can train humanoid robots by performing actions in front of them, from the perspective of text, speech, and general movements. You can use one of these generative AI models to train the robot. Thus, we have our Jetson Thor,
Jetson Thor offers 8 times the performance of Jetson Orin, reaching up to 800 TFLOPS. How is this possible? This is because we have a new next-generation GPU architecture based on Blackwell, which also includes a Transformer engine. We not only increased from the GPU perspective but also from the CPU perspective, with CPU performance increasing by up to 2.6 times. From the memory perspective, we doubled the DRAM capacity, now reaching up to 128GB. Then from the I/O bandwidth perspective, we really see the need to balance between memory, computation, and I/O, so now with Jetson Thor, we have increased computing power, so obviously, we need to increase I/O as well. Therefore, we will bring 10 times more I/O bandwidth than now, reaching up to 4x25Gb Ethernet.
Regarding our roadmap, our Orin module components are commercial modules. They have a seven-year lifecycle, so these will be available until 2030. Our industrial modules have a ten-year lifecycle, so they will be available until 2033. You can see AGX Thor, which will be available in 2025. I want to point out that our other modules, such as Jetson AGX Xavier TX2 and Nano, will continue to be offered during their product lifecycle. But for any new designs, we really recommend you to consider our Jetson Orin, as all the software solutions I mentioned earlier, we will continue to add and enhance them, focusing on Jetson Orin.
