In-Depth Analysis of Linux Lock Mechanisms: From Principles to Practice
1 Overview of Linux Lock Mechanisms
In the field of concurrent programming, lock mechanisms are the cornerstone technology for ensuring data consistency and operation atomicity in multi-threaded and multi-tasking environments. As a complex modern operating system, Linux needs to manage resource sharing issues in multi-processor and multi-core environments, and its lock mechanism design and implementation reflect the essence of computer science in the field of concurrency control. When we delve into the Linux kernel, we find a diverse and hierarchical lock ecosystem, where each type of lock has its specific application scenarios and performance characteristics.
The essence of the lock mechanism is to coordinate multiple execution flows (threads, processes, CPU cores) in accessing shared resources. Without lock protection, concurrent access can lead to race conditions, where the program’s execution result depends on uncontrollable event execution order, resulting in serious issues such as data inconsistency and system crashes. The Linux kernel provides various lock primitives, from simple spinlocks to complex read-write semaphores, forming a complete concurrency control system.
In Linux kernel development, the choice of locks not only concerns correctness but also directly affects system performance. Improper use of locks can lead to performance bottlenecks, such as deadlocks, livelocks, and priority inversion. Therefore, understanding the internal principles of the Linux lock mechanism is crucial for developing high-performance and reliable kernel code and system software.
Table: Comparison of Main Lock Types in the Linux Kernel
| Lock Type | Main Features | Applicable Scenarios | Performance Characteristics |
|---|---|---|---|
| Spinlock | Busy waiting, non-sleeping | Short critical sections, interrupt context | Low overhead, but wastes CPU cycles |
| Mutex | Sleeping wait, blocking | Long critical sections, process context | High overhead, but saves CPU resources |
| Read-Write Lock | Distinguishes read and write operations | Data structures with many reads and few writes | Read parallelism, write serialization |
| Semaphore | Counting synchronization | Resource pools, producer-consumer | Flexible but relatively complex |
2 Core Principles of Linux Lock Mechanisms
2.1 Race Conditions and Critical Sections
To understand the value of locks, one must first recognize the core issue of race conditions. When multiple execution flows (threads, processes, or processors) concurrently access shared data, and at least one execution flow modifies the data, if these accesses lack appropriate synchronization measures, the final result depends on the precise execution order of the execution flows, which is a race condition.
Consider a simple example: two threads incrementing a global variable <span>a</span>. In C, an operation like <span>a = a + 1</span> appears atomic, but when compiled to assembly code, it may involve multiple instruction steps such as loading, incrementing, and storing:
// C code
a = a + 1;
// Corresponding RISC-V assembly code
lui a5, %hi(a) # Load high address of a
lw a5, %lo(a)(a5) # Load value of a from memory to register a5
addiw a5, a5, 1 # Increment register value by 1
sext.w a4, a5
lui a5, %hi(a)
sw a4, %lo(a)(a5) # Store result back to memoryDuring the execution of this assembly code, the thread may be preempted between any two instructions, allowing another thread to intervene and modify the shared variable, resulting in an unexpected final result. The code area accessing these shared resources is called a critical section, and the lock mechanism is the fundamental method to ensure that only one execution flow is in the critical section at any time.
A real-life analogy helps to understand this concept: imagine a public restroom (shared resource) that multiple people (threads) may need to use. Without a lock mechanism, it could lead to an awkward situation where multiple people enter the same restroom stall simultaneously. A lock is like a latch on the restroom door—once someone enters and latches the door (acquires the lock), others must wait outside (block) until the person inside comes out and unlocks the door (releases the lock).
2.2 Hardware Support
The implementation of lock mechanisms relies on hardware-level support, particularly atomic operation instructions. Modern processors provide a series of atomic read-modify-write instructions, which are not interrupted during execution, thus laying the foundation for building higher-level synchronization primitives.
- • Atomic Exchange: Atomically exchanges the value between a register and a memory location.
- • Test-and-Set: Checks the value at a memory location, and if it meets the condition, sets a new value, all in an atomic transaction.
- • Compare-and-Swap (CAS): Checks if the value at a memory location matches the expected value, and if so, updates it to a new value.
- • Load-Linked/Store-Conditional (LL/SC): An atomic operation paradigm used in RISC architectures, where a value is loaded, computed, and then an attempt to store is made; if the memory was modified in the meantime, the store fails.
These atomic instructions are the basis for constructing user-space software-level locks. For example, a simple spinlock can be implemented using the Test-and-Set instruction:
typedef struct {
volatile int lock;
} spinlock_t;
void spin_lock(spinlock_t *lock) {
while (__sync_lock_test_and_set(&lock->lock, 1)) {
while (lock->lock) {
cpu_relax(); // Hint to CPU that this is a spin loop, can optimize power consumption
}
}
}
void spin_unlock(spinlock_t *lock) {
__sync_lock_release(&lock->lock);
}However, pure software-implemented locks face challenges in symmetric multi-processor (SMP) systems, as memory consistency and cache coherence issues can lead to complex synchronization overhead. To address this, hardware provides memory barrier instructions, ensuring that memory operations before the barrier complete before operations after the barrier, preventing processor and compiler reordering optimizations from breaking lock semantics.
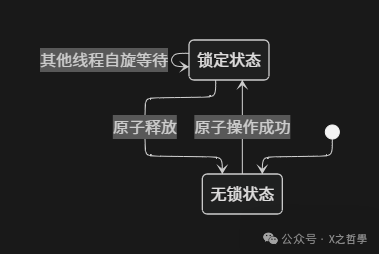
3 Analysis of Lock Implementation Mechanisms in the Linux Kernel
3.1 Mutex
The mutex (Mutual Exclusion Lock) is one of the most commonly used sleeping locks in the Linux kernel, used to protect critical sections in process context. Unlike spinlocks, when a mutex is held, subsequent attempts to acquire the lock will put the thread to sleep until the lock is released, avoiding CPU resource waste caused by busy waiting.
In the Linux kernel, mutexes are represented by <span>struct mutex</span>, defined in <span>include/linux/mutex.h</span>:
struct mutex {
atomic_long_t owner; // Lock owner marker
spinlock_t wait_lock; // Spinlock protecting the wait queue
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; // Optimistic spin MCS lock
#endif
struct list_head wait_list; // Wait queue
// ...
};<span>owner</span> field not only indicates the lock owner but also utilizes pointer alignment characteristics to store lock state information. Since the task_struct pointer is at least aligned to L1_CACHE_BYTES, the low bits can be used to store additional state (such as a flag indicating the presence of waiters).
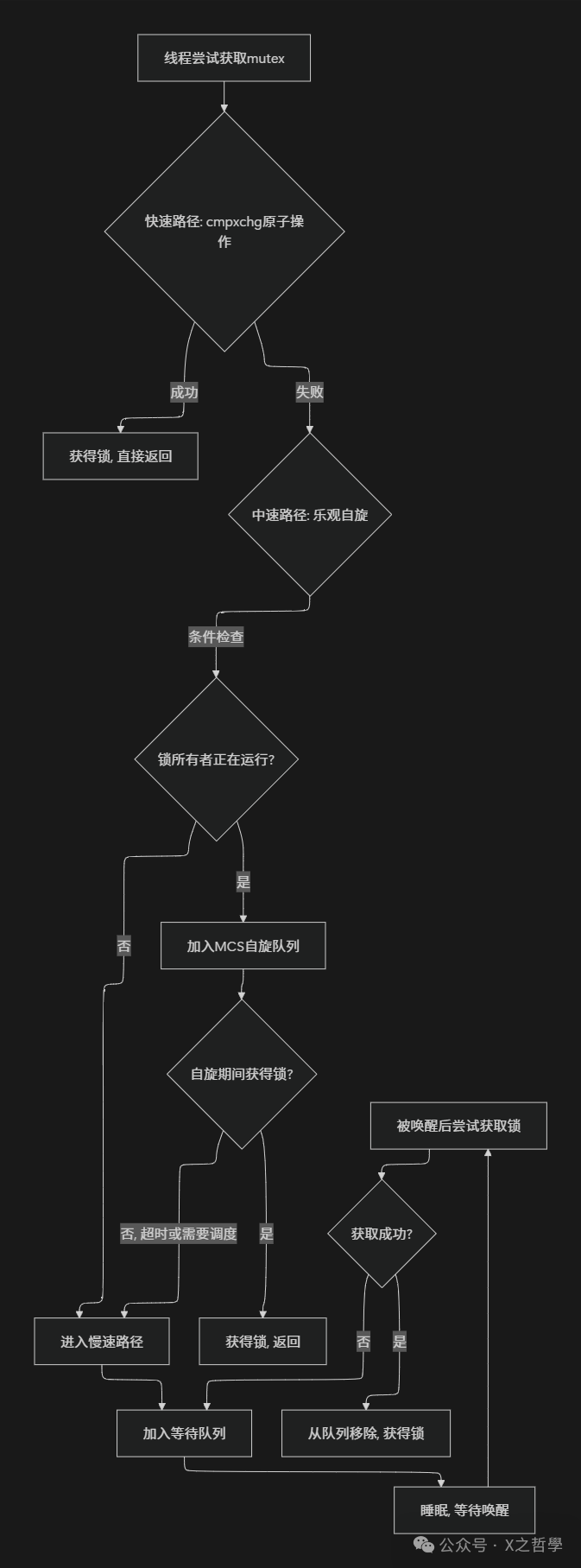
The locking and unlocking process of a mutex includes three main paths, showcasing the Linux kernel’s fine considerations for performance optimization:
3.1.1 Fast Path
The fast path is the optimal case execution path, suitable for lock acquisition scenarios without contention. The thread attempts to directly set the lock owner to the current task using the <span>cmpxchg()</span> (compare and swap) atomic instruction:
static inline bool mutex_trylock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
// Attempt to atomically set owner from NULL to current task
if (atomic_long_try_cmpxchg_acquire(&lock->owner, &curr, curr | 0x1))
return true;
return false;
}If successful, the thread immediately acquires the lock with almost no additional overhead. This design is based on an important observation: in most cases, locks are contention-free, and the fast path can efficiently handle these scenarios.
3.1.2 Mid Path – Optimistic Spin
When the fast path fails (the lock is held), the thread does not immediately sleep but enters the optimistic spin phase. This is a hybrid feature of Linux mutexes, combining the advantages of spinlocks and sleeping locks.
The premise of optimistic spinning is that: the lock holder is running and there are no higher-priority tasks needing scheduling. In this case, the current thread will briefly spin, expecting the lock holder to release the lock soon. To avoid cache line bouncing, the mid path uses MCS locks (proposed by Mellor-Crummey and Scott) for queuing, ensuring each spinning thread spins on local variables:
static bool mutex_optimistic_spin(struct mutex *lock)
{
// Check spin condition: lock owner is running, and current thread does not need scheduling
while (mutex_can_spin_on_owner(lock)) {
// Attempt to acquire MCS lock, join spin queue
if (mutex_try_to_acquire(lock))
return true;
cpu_relax(); // Optimize spin CPU instruction
}
return false;
}3.1.3 Slow Path
When both the fast path and mid path fail, the thread enters the slow path, which is the last resort. The thread will be added to the lock’s wait queue and then go to sleep until woken up by an unlock operation:
static noinline void __sched mutex_lock_slowpath(struct mutex *lock)
{
struct mutex_waiter waiter;
// Add current task to wait queue
list_add_tail(&waiter.list, &lock->wait_list);
waiter.task = current;
for (;;) {
// Set task state to uninterruptible sleep
set_current_state(TASK_UNINTERRUPTIBLE);
// If lock is available, attempt to acquire
if (mutex_try_to_acquire(lock))
break;
// Otherwise, schedule other tasks to run
schedule();
}
// After acquiring the lock, set task state to running
__set_current_state(TASK_RUNNING);
// Remove from wait queue
list_del(&waiter.list);
}The unlocking process of a mutex is relatively simple, mainly involving clearing the owner marker and waking up the next thread in the wait queue:
void __sched mutex_unlock(struct mutex *lock)
{
// Release lock, set owner to NULL
atomic_long_set_release(&lock->owner, 0);
// If there are waiters, wake the next one
if (!list_empty(&lock->wait_list))
__mutex_unlock_slowpath(lock);
}
3.2 Spinlocks
Spinlocks are the most basic busy-wait locks in the Linux kernel, characterized by the fact that when the lock is held, threads attempting to acquire the lock will continuously check the lock status in a tight loop until the lock becomes available. This mechanism avoids context switch overhead but consumes CPU cycles, thus only suitable for short critical sections and non-sleeping scenarios (such as interrupt handlers).
The implementation of spinlocks in the Linux kernel has evolved over the years, from simple Test-and-Set locks to the current ticket spinlocks and queue spinlocks, addressing fairness and scalability issues.
3.2.1 Ticket Spinlock Implementation
Ticket spinlocks are similar to a queue system at a bank service window, ensuring first-come, first-served fairness. It consists of two counters: the next available ticket (next) and the current service ticket (owner).
typedef struct {
union {
u32 slock; // Complete lock value
struct __raw_tickets {
u16 owner; // Current service ticket
u16 next; // Next available ticket
} tickets;
};
} spinlock_t;
static inline void spin_lock(spinlock_t *lock)
{
// Get next ticket and increment next
u32 ticket = atomic_fetch_add(1, &lock->slock);
// Wait until current service ticket equals own ticket
while (lock->tickets.owner != ticket) {
cpu_relax(); // Optimize spin loop
}
}
static inline void spin_unlock(spinlock_t *lock)
{
// Increment owner, wake the next waiter
lock->tickets.owner++;
}Ticket spinlocks solve the fairness issue of traditional spinlocks, but still face performance challenges in large-scale NUMA systems, as all CPU cores spin on the same memory variable, leading to significant traffic from cache coherence protocols.
3.2.2 MCS Locks and Queue Spinlocks
To address scalability challenges, the Linux kernel introduced queue spinlocks based on MCS locks. Each CPU attempting to acquire the lock spins on a local node, significantly reducing cache line bouncing.
Queue spinlocks use a 32-bit field to represent lock status:
- • 0-1 bits: Lock status (unlocked, pending lock, locked)
- • 2-31 bits: Index of the tail pointer of the wait queue
// Queue spinlock data structure
typedef struct qspinlock {
atomic_t val; // Contains state and queue information
} arch_spinlock_t;
// MCS node, one for each waiting thread
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked; // Whether this thread should spin
};The implementation of queue spinlocks is quite complex, but the basic principle is that all waiting threads are linked into a queue through MCS nodes, with each thread spinning on its own <span>locked</span> field. When the lock is released, only the first thread in the queue is woken up, ensuring fairness and high performance.
3.2.3 Spinlock Debugging Support
The Linux kernel provides robust debugging capabilities for spinlocks. When <span>CONFIG_DEBUG_SPINLOCK</span> is enabled, the kernel checks for various lock misuse cases:
static void spin_bug(spinlock_t *lock, const char *msg)
{
// Print debugging information: lock address, current task, owner, etc.
printk("BUG: spinlock %s on CPU#%d, %s/%d\n",
msg, raw_smp_processor_id(), current->comm, current->pid);
printk(" lock: %p, .magic: %08x, .owner: %s/%d, .owner_cpu: %d\n",
lock, lock->magic,
owner ? owner->comm : "<none>",
owner ? owner->pid : -1,
lock->owner_cpu);
dump_stack(); // Print stack trace
}The debugging code detects the following common errors:
- • Recursive Locking: The same thread attempts to acquire the same spinlock multiple times.
- • Uninitialized Lock: Using a lock that has not been properly initialized.
- • Wrong Releaser: A non-owner thread attempts to release the lock.
3.3 Read-Write Locks
In many practical scenarios, the frequency of read operations on shared data is much higher than that of write operations. To optimize this read-heavy, write-light access pattern, the Linux kernel provides read-write locks (such as <span>rwlock_t</span> and <span>seqlock_t</span>), allowing multiple readers to enter the critical section simultaneously, but only one writer, and readers and writers cannot exist simultaneously.
3.3.1 Implementation Principles of Read-Write Locks
Traditional read-write locks use an integer to represent lock status, with high bits indicating the number of readers and low bits indicating the writer’s status. However, this method can lead to high contention among readers when there are many readers.
The modern Linux kernel adopts a more efficient implementation, similar to the ticket mechanism of spinlocks:
typedef struct {
arch_rwlock_t raw_lock; // Architecture-specific representation of read-write lock
} rwlock_t;
// Implementation for x86 architecture
struct arch_rwlock {
unsigned int lock; // High 16 bits: reader count, low 16 bits: writer marker
};
// Reader locking
static inline void read_lock(rwlock_t *lock)
{
// Atomically increase reader count, check for writers
while (atomic_add_unless(&lock->lock, 1 << 16, 0xffff)) {
cpu_relax();
}
}
// Writer locking
static inline void write_lock(rwlock_t *lock)
{
// Attempt to set writer marker
while (!atomic_try_cmpxchg(&lock->lock, 0, 1)) {
cpu_relax();
}
}3.3.2 Seqlock
For scenarios with very frequent reads and relatively few writes, the Linux kernel provides seqlocks. This lock allows readers to read while a writer is active, but may require retries.
typedef struct {
unsigned sequence; // Sequence counter
spinlock_t lock; // Lock protecting write operations
} seqlock_t;
// Read start: get current sequence number
static inline unsigned read_seqbegin(const seqlock_t *sl)
{
unsigned ret = sl->sequence;
// Memory barrier, ensure read operations do not reorder before sequence number read
smp_rmb();
return ret & ~1; // Clear the lowest bit (writer marker)
}
// Read validation: check if the sequence number has changed
static inline int read_seqretry(const seqlock_t *sl, unsigned start)
{
smp_rmb();
return unlikely(sl->sequence != start);
}
// Writer locking
static inline void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock);
sl->sequence++; // Increment sequence number, mark write operation start
smp_wmb(); // Write memory barrier
}
// Writer unlocking
static inline void write_sequnlock(seqlock_t *sl)
{
sl->sequence++; // Increment sequence number again, mark write operation end
smp_wmb();
spin_unlock(&sl->lock);
}Reader usage pattern:
do {
seq = read_seqbegin(&seqlock);
// Read shared data
} while (read_seqretry(&seqlock, seq));If a reader detects that the sequence number has changed during the read (indicating a writer has modified the data), it will retry the read operation, ensuring data consistency.
Table: Comparison of Characteristics of Various Locks in the Linux Kernel
| Characteristic | Spinlock | Mutex | Read-Write Lock | Seqlock |
|---|---|---|---|---|
| Waiting Mechanism | Busy waiting | Sleeping wait | Readers no wait, writers sleep | Readers no wait, writers spin |
| Concurrent Reads | Not supported | Not supported | Supports multiple readers | Supports multiple readers |
| Concurrent Writes | Not supported | Not supported | Not supported | Not supported |
| Applicable Scenarios | Short critical sections, interrupt context | Long critical sections, process context | Data with many reads and few writes | Very many reads and very few writes |
| Memory Overhead | Low | Medium | Medium | Low |
| Performance Characteristics | Low latency, high CPU usage | High latency, low CPU usage | High reader parallelism | Readers almost no overhead |
4 Usage and Debugging of Locks
4.1 Correct Usage Patterns of Locks
In Linux kernel development, the correct use of locks not only concerns functional correctness but also directly affects the system’s performance and maintainability. Here are some key best practices and common patterns:
4.1.1 Lock Initialization
Each type of lock needs to be properly initialized before use. The Linux kernel provides both static and dynamic initialization methods:
// Static initialization of mutex
define_mutex(my_mutex);
// Static initialization of spinlock
define_spinlock(my_spinlock);
// Dynamic initialization
struct mutex mutex;
mutex_init(&mutex);
spinlock_t spinlock;
spin_lock_init(&spinlock);4.1.2 Nesting and Order of Locks
In complex systems, it may be necessary to hold multiple locks simultaneously. In such cases, a strict lock acquisition order is key to preventing deadlocks.
// Define global lock order
enum lock_ordering {
LOCK_ORDER_NETWORK,
LOCK_ORDER_BLOCK,
LOCK_ORDER_SCHED,
LOCK_ORDER_MAX
};
// Acquire locks in fixed order
void process_multiple_resources(void)
{
mutex_lock(&network_mutex); // First order
mutex_lock(&block_mutex); // Second order
mutex_lock(&sched_mutex); // Third order
// Operate on shared resources
// Release in reverse order
mutex_unlock(&sched_mutex);
mutex_unlock(&block_mutex);
mutex_unlock(&network_mutex);
}The Linux kernel provides <span>lockdep</span> (lock dependency tracker) to dynamically detect potential lock order violations. When <span>lockdep</span> detects a violation of lock acquisition order, it outputs detailed warning information to help developers identify and fix deadlock risks.
4.1.3 Lock Usage in Interrupt Context
Locks used in interrupt handlers require special attention. If an interrupt may be triggered in code protected by a lock, and the interrupt handler also attempts to acquire the same lock, it can lead to deadlocks. To address this, Linux provides variants of locks that disable interrupts:
unsigned long flags;
// Protect data shared with interrupts in process context
spin_lock_irqsave(&shared_lock, flags);
// Access shared data
spin_unlock_irqrestore(&shared_lock, flags);
// In interrupt handler
spin_lock(&shared_lock);
// Access shared data
spin_unlock(&shared_lock);
}4.2 Lock Debugging and Performance Analysis
The Linux kernel provides rich tools and mechanisms to debug lock-related issues and analyze lock performance.
4.2.1 Lock Debugging Features
When kernel configuration options <span>CONFIG_DEBUG_SPINLOCK</span>, <span>CONFIG_DEBUG_MUTEXES</span>, and <span>CONFIG_LOCKDEP</span> are enabled, the kernel performs in-depth checks for lock correctness:
- • Lock State Validation: Checks if the lock is initialized, if it is re-initialized, and if an attempt is made to release it without holding it.
- • Deadlock Detection:
<span>lockdep</span>tracks the acquisition order of all locks, builds a lock order graph, and detects potential deadlock scenarios. - • Lock Statistics: Tracks lock contention, wait times, and other metrics to help identify performance bottlenecks.
// Mutex debugging example
void debug_mutex_lock_common(struct mutex *lock, struct mutex_waiter *waiter)
{
memset(waiter, MUTEX_DEBUG_INIT, sizeof(*waiter));
waiter->magic = waiter;
INIT_LIST_HEAD(&waiter->list);
}
void debug_mutex_add_waiter(struct mutex *lock, struct mutex_waiter *waiter,
struct task_struct *task)
{
SMP_DEBUG_LOCKS_WARN_ON(!spin_is_locked(&lock->wait_lock));
/* Mark the current thread as blocked on the lock: */
task->blocked_on = waiter;
}4.2.2 Lock Performance Analysis Tools
In actual deployment, analyzing lock performance is crucial for system tuning. Common tools include:
- • lockstat: Provides detailed lock contention statistics.
- • perf lock: Lock analysis feature in the Linux perf toolset.
- • /proc/lockdep_chains: Displays lock dependency chains detected by the kernel.
Example of using perf to analyze lock contention:
# Record lock events
perf record -e lock:lock_acquire,lock:lock_acquired,lock:lock_contended,lock:lock_release -a sleep 10
# Analyze lock statistics
perf lock report4.2.3 Common Lock Issues and Solutions
Table: Common Lock Issues and Solutions
| Issue Type | Symptoms | Debugging Methods | Solutions |
|---|---|---|---|
| Deadlock | System hangs, unresponsive | lockdep, stack trace | Unify lock acquisition order, use trylock |
| Livelock | High CPU usage but slow progress | perf, lock statistics | Introduce random backoff, adjust lock granularity |
| Priority Inversion | High-priority tasks blocked by low-priority tasks | Scheduling trace, priority inheritance trace | Use priority inheritance mechanism |
| Lock Contention | Multiple CPUs waiting for the same lock | lockstat, perf lock analysis | Reduce lock granularity, use read-write locks |
| Lock Bouncing | Lock frequently migrates between CPUs | Cache locality analysis | Use per-CPU data, adjust data layout |
5 Conclusion
The Linux lock mechanism is the cornerstone of concurrency control in operating systems, having developed and optimized over decades into a complex and efficient system. From simple atomic operations to complex queue spinlocks, from basic mutexes to refined read-write locks, the Linux kernel provides a series of synchronization primitives suitable for different scenarios.
Through this analysis, we can see several key principles in Linux lock design:
- 1. Optimize contention-free paths: Ensure minimal overhead in contention-free situations through fast paths.
- 2. Ensure fairness: Ensure waiting threads acquire locks in order through ticket mechanisms or queues.
- 3. Balance power consumption and performance: Use hybrid strategies (such as optimistic spinning) to balance response time and CPU consumption.
- 4. Provide comprehensive debugging support: Use tools like lockdep to help developers identify potential issues.